
王竹峰,去哪儿网数据库总监。擅长数据库开发、数据库管理及维护,一直致力于 MySQL 数据库源码的研究与探索,对数据库原理及实现有深刻的理解。曾就职于达梦数据库,从事多年数据库内核开发工作,是 Inception 开源项目及《MySQL运维内参》的作者,MySQL 方向的Oracle ACE 。
一、背景
最近组内同学遇到一个问题,说数据库被业务打死了,无响应,只好用 kill -9 pid 杀掉,然后重启,幸好此时的数据库角色是从库,影响不大。同学自述,在杀掉重启的时候,心里默念,千万别启不来啊,这个库的数据量有点大,快要达到 4T 了。做运维的人都知道,事情就不能念叨,一念叨,这事儿就准发生。这次也不例外,确实是出现了。现象是长时间启动不了,基本卡死状态。error log 信息如下:
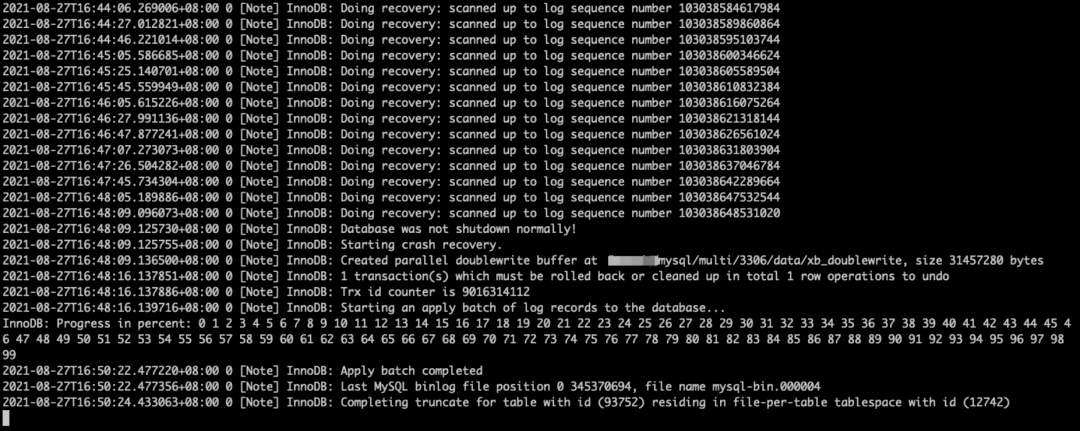
通过查看 Note 级别的启动日志发现,在报了最后一条之后,就再也没有新的日志出现了。很久也不会再动。
二、分析
首先通过 top 命令来确定一下当前实例是不是还在活动:
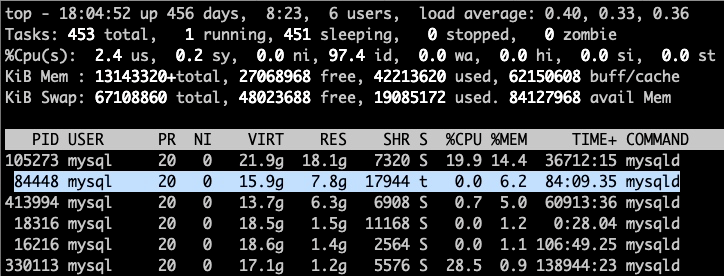
PID 为 84448 ,发现 CPU 占用率是 0 ,说明当前实例已经卡死了,没有在跑了。当然也不是死循环(因为死循环的话,CPU肯定是打满的)。
接下来就要看堆栈了,这个在查问题的时候,是一个非常好的工具。堆栈结果如下:
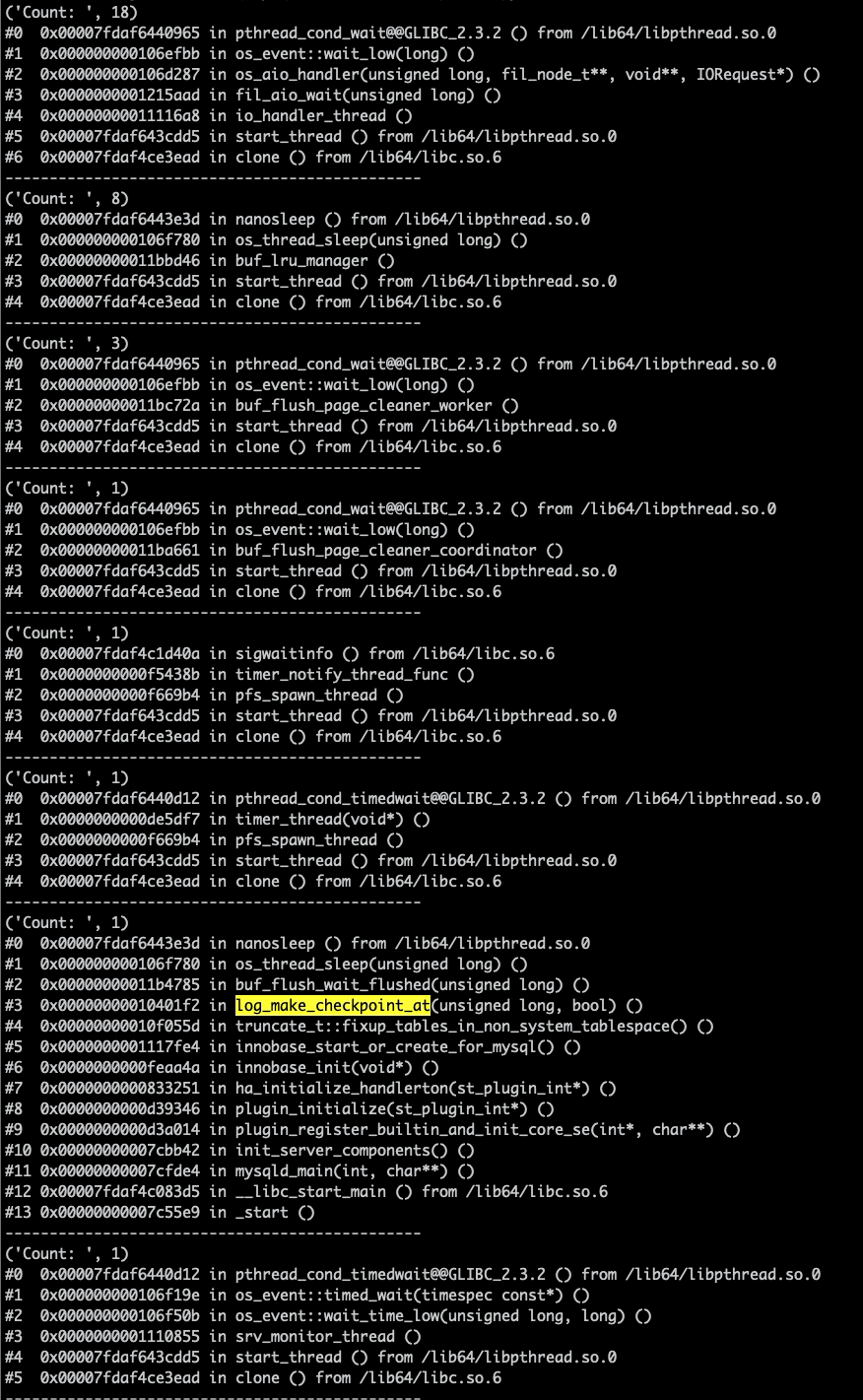
从堆栈可以看出,IO 线程完全不工作,都处于 idle 状态,启动线程,即包括 mysqld_main 函数的堆栈,也处于 nanosleep 状态,最主要的两组线程,已经说明了,当前实例啥也不做,完全是 idle 状态,与我们在上面用 TOP 来判断的结果是一样的。
三、进一步分析
从上面的现象来判断的话,很难找到具体原因,因为很难判断当前线程为什么这么死等,当然,从启动线程基本可以确定的是,是启动时想做一次检查点,但在刷盘的时候一直等不到刷完,基本只能是这样。那我们可以试想一下,等待刷盘,一直等不到,那刷盘线程在做什么呢?这个也很好确定,知道源码的同学,应该了解,刷盘线程是buf_flush_page_cleaner_coordinator,在上面堆栈截图中有,我们再来看一次。

很明显,这个线程也处于等待状态,那这样就可以大概推断,应该是 innodb 内部出现了乱子,刷盘线程认为没有东西可以刷,所以处于 idle 状态,而启动线程认为有东西需要刷的,所以一直在等,信息没有对齐,所以死等了。
那单纯从上面的这些信息,还能继续往下分析吗?也许可以再进步一点点。我们发现,上面的错误日志中,有一行这样的信息:
2021-08-27T16:50:24.433063+08:00 0 [Note] InnoDB: Completing truncate for table with id (93752) residing in file-per-table tablespace with id (12742)
这个信息比较少出现的,大概是表示某一个表在重启之前做过 truncate,而在重启的时候,需要把这个表redo一次 truncate 。而我们再反过来看启动的堆栈,发现调用buf_flush_wait_flushed的,正是truncate_t::fixup_tables_in_non_system_tablespace ,发现这也是 truncate ,好像能对得上,所以此时可以猜测,是不是与 truncate 有关系。
在咨询业务之后,发现在这个实例的生前,确实多次做过数据的 load 与 truncate ,然后知道这个业务的行为,有帮助么?试想从上面的现象,我们还能再往下分析吗?此时我认为不可以了。
那怎么办?我认为只能上源码了。
四、源码分析
我们用源码分析,首先需要解开的是,为什么信息不对称,即刷盘线程认为没有页面需要刷了,而启动线程认为需要刷盘呢?用源码分析,一个很重要的入手点,就是先编译一个相同版本的 Debug mysqld ,然后启动复现这个问题,因为这个问题是必现的,所以查找起来容易很多。
等到复现之后,我们把上面的堆栈再看一次:

有没有发现有很大的不同,信息多了很多,可以具体地看到每一个函数对应的文件,行数等等,上面展示的是刷盘线程buf_flush_page_cleaner_coordinator的状态,代码版本是Percona 5.7.26,可以看出 os_event 的等待位置是在 buf0flu.cc 的 3212 这行,我们拿到对应的代码,看看这行是在做什么。
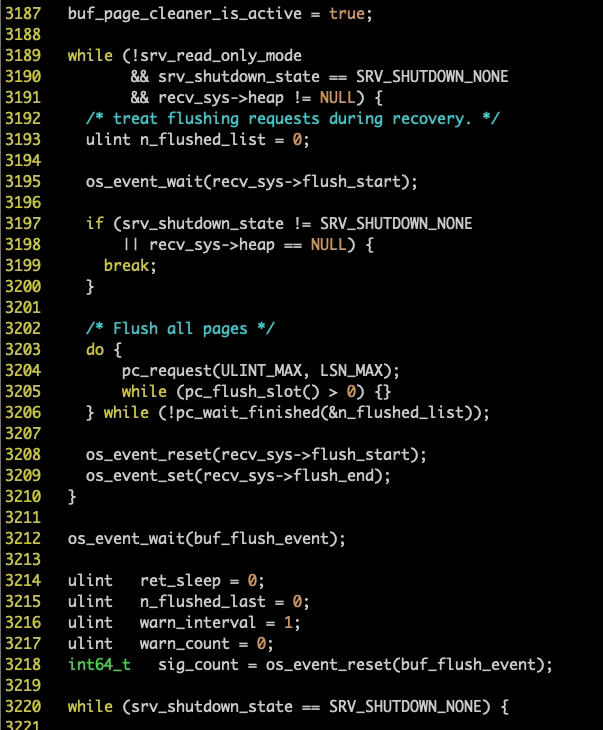
可以看到,3212 行的代码是 os_event_wait(buf_flush_event)。这行之上,是刷盘线程的开始位置,熟悉代码的同学都知道,这个位置是用来把innodb恢复过程中,REDO重放产生的脏页刷到文件中去的,而在这行之后,即从下面我们所看到的一行代码 while (srv_shutdown_state == SRV_SHUTDOWN_NONE){开始,才是真正地刷掉我们数据库正常运行过程中产生的所有脏页的,innodb 是把启动过程中和启动之后正常运行所产生的脏页分阶段刷掉的。
知道这个之后,我们就可以知道,3212 这行,是两个阶段的分界线,也就是说,刷盘线程认为数据库的 REDO 已经做完了,而还没有启动完成,所以正常的刷盘还不能开始做,所以就静静地等待在这里。
我们此时再回过头来看启动线程所处的位置,堆栈如下:
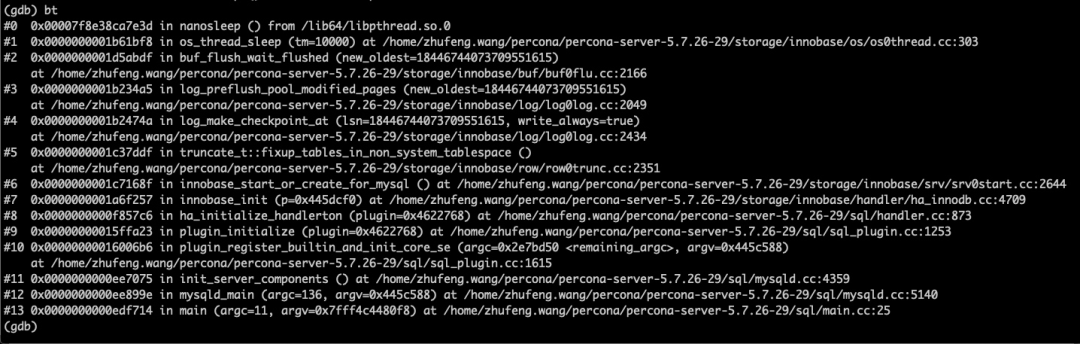
熟悉代码的同学知道,innobase_start_or_create_for_mysql是innodb启动的关键函数,在这里调用了truncate_t::fixup_tables_in_non_system_tablespace,这个函数从名字上就能推断出来是干什么的,与日志中最后一行非常相关,我们可以顺便看看日志在哪里打印出来的,代码如下:
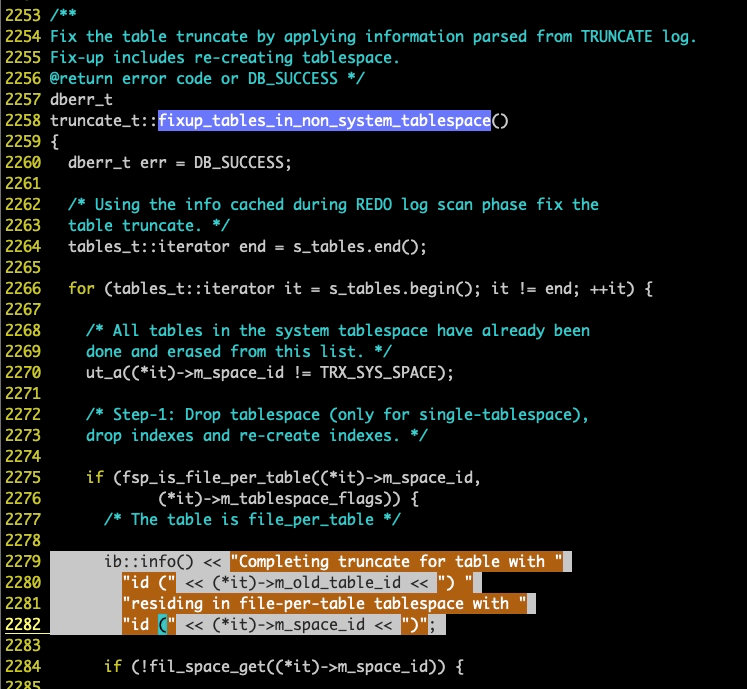
一目了然,即自从日志文件打印这行之后,这个启动就卡死在这里了。非常明确,通过代码验证了我们的推测。
那我们现在需要考虑的问题是,为什么在这个位置,innodb认为是需要刷盘的呢?我们再看代码:
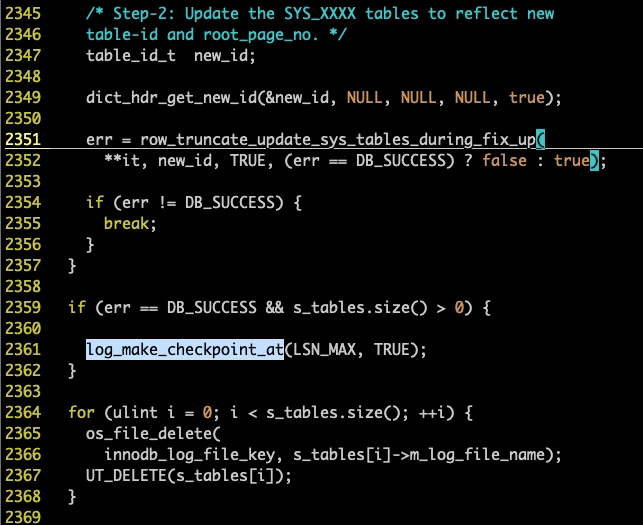
这里是函数 truncate_t::fixup_tables_in_non_system_tablespace 最后的位置,在这里我们能看到对函数 log_make_checkpoint_at 的调用,这个我们能在堆栈中看到,其实他就是卡在了里面。这里还是那个问题,为什么需要刷盘?因为在这个 fixup 过程中,做了很多修改操作,修改的内容可以参考函数 row_truncate_update_sys_tables_during_fix_up 的实现,在上图中有,里面做了大量的修改,以及 SQL 语句的执行,肯定会产生很多脏页。所以 innodb 需要将其刷盘。
但为什么刷盘线程不刷了呢?很明显,上面已经解释过了,他已经执行完了 redo 重放产生的脏页,所以已经处于 idle 状态了,他认为在数据库启动之前,他不会再刷盘了,除非 buf_flush_event 事件被 set 一次。那我们的好奇来了, buf_flush_event 正常情况下,是什么时候被 set 的呢?再看代码,总共有两个地方,先看第一个:
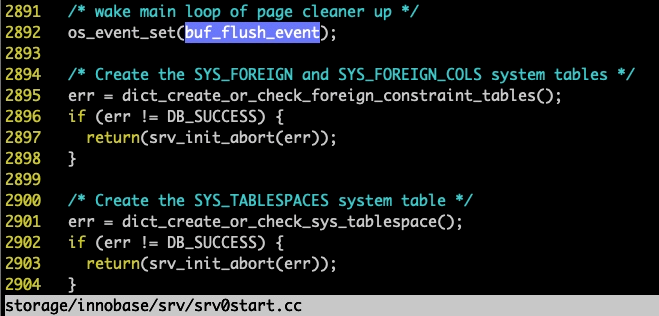
从上图可以看到,他是在 srv0start.cc 的 2892 行被 set 的,如果执行了这行,那刷盘线程就会继续向下执行了,就说明 innodb 启动完成可以正常工作了,而我们现在再看truncate_t::fixup_tables_in_non_system_tablespace()是什么时候调用的呢?从堆栈可以看出来,就是 srv0start.cc:2644 行位置,即是在 buf_flush_event 被 Set 之前的位置,也就是说,innodb 认为 fixup 执行所产生的脏页,还算做是 REDO 重放所产生的(姑且这么认为),那疑问来了,既然这样,刷盘线程怎么就提前退出了呢?我们再通过代码来看,刷盘线程针对 REDO 重放所产生的脏页刷盘工作,在什么情况下会退出:
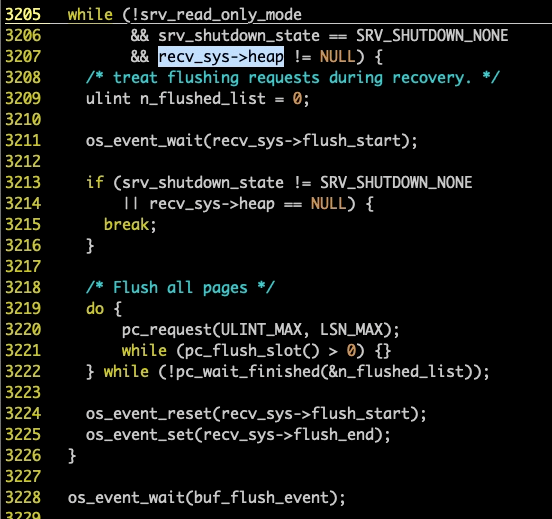
可以看到,这个循环退出条件之一,就是recv_sys->heap == NULL,也就是说,只要recv_sys->heap == NULL了,刷盘操作就退出了,我们再看recv_sys→heap是什么时候被设置为NULL的:
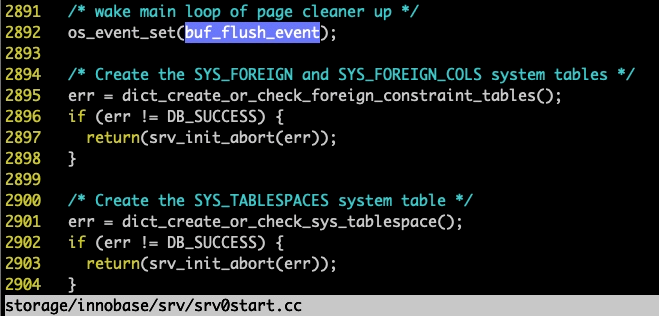
不难发现,recv_sys→heap是在recv_sys_debug_free 中设置为NULL的,那现在问题就变为 recv_recovery_from_checkpoint_finish 是在什么时候调用的了,熟悉代码的同学应该对这个很清楚,这正是完成 REDO 重放的一个重要函数,我们搜索发现:
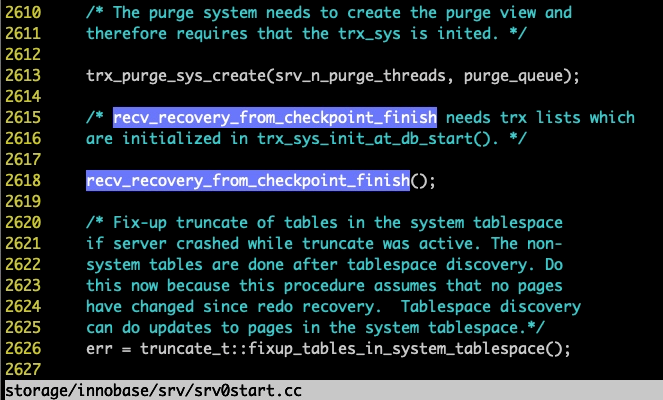
可以看到,recv_recovery_from_checkpoint_finish 的调用位置,在 2618 行,是在 fixup_tables_in_non_system_tablespace 被调用之前,细心的同学可能也会从上图中发现,还有一个相似的函数truncate_t::fixup_tables_in_system_tablespace(),从名字可以看到,这是针对系统表的。总之,不管系统表,还是 NON 系统表,都是在 recv_recovery_from_checkpoint_finish 后面被调用,因为之前分析了,只要 recv_recovery_from_checkpoint_finish 调用了,刷盘线程就认为 innodb 再产生的脏页就是正常运行的脏页了,就不负责刷盘了,就会走到等待 buf_flush_event 的位置,而启动线程不这么认为,在重放完成之后,又产生了新的脏页,同时他认为,这里所产生的脏页必须要刷完,此时 buf_flush_event 又没有被 Set ,所以启动线程只能死等了。是的,会一直等下去。
我们现在再看 buf_flush_event 被 Set 的第二个位置,即是 buf_flush_request_force ,而这个函数被调用的位置,我们就比较熟悉了,请看:
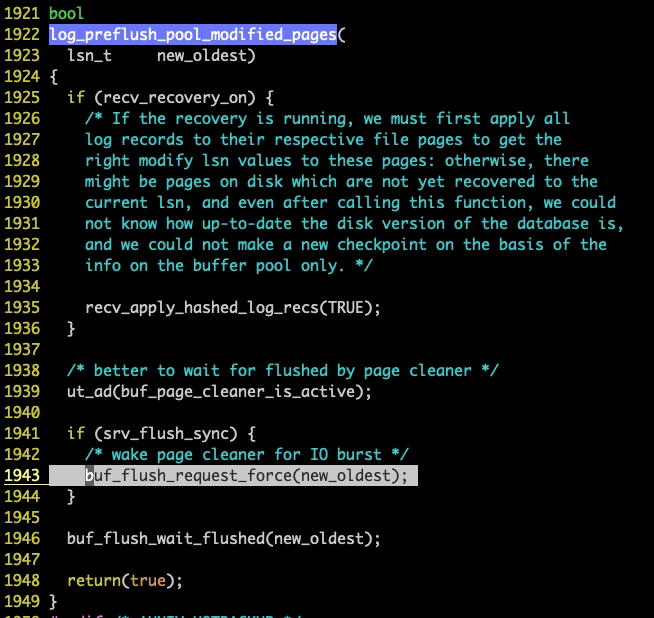
同时发现,在 buf_flush_request_force 下面,就是我们当前陷入死循环的函数,也就是说, InnoDB 也认为 fixup 产生的脏页应该由启动之后的刷盘线程来刷掉,即只有等待到事件 buf_flush_event 之后才去做刷盘。所以上面在进入等待状态 buf_flush_wait_flushed 之前,先做一次 buf_flush_event 的 Set 操作,让刷盘线程继续向下执行,进入到正常刷盘状态。
然而,当前启动线程,已经处于等待状态了,为什么刷盘线程还处于等待事件 buf_flush_event 的状态呢?细心的同学应该已经注意到了,在上图中,buf_flush_request_force 的调用是有条件的,有一个参数 srv_flush_sync ,此时我看了一下当前参数的值,他是 0 ,这样就可以解释了,正是因为这个参数,导致这个机制失效了,这里的 buf_flush_event 的 Set 失效了,就需要依靠上面第一种情况所说的 Set 了,而此时已经明白,永远不会执行到那里去了,会一直等下去。
那现在应该清楚了,本身针对这个问题,流程整体上是没有问题的,只不过有参数 srv_flush_sync ,导致逻辑上面存在了漏洞,那我们如何避免这样的问题,很显然,能用参数控制的办法避免问题,是最友好不过的了,我们只需要把参数 srv_flush_sync (其实就是 InnoDB 参数 innodb_flush_sync)设置为 ON 即可。
问题清楚之后,我们再回过头来,看看在buf_flush_wait_flushed函数死等的位置,状态是什么样子的,如下图所示:
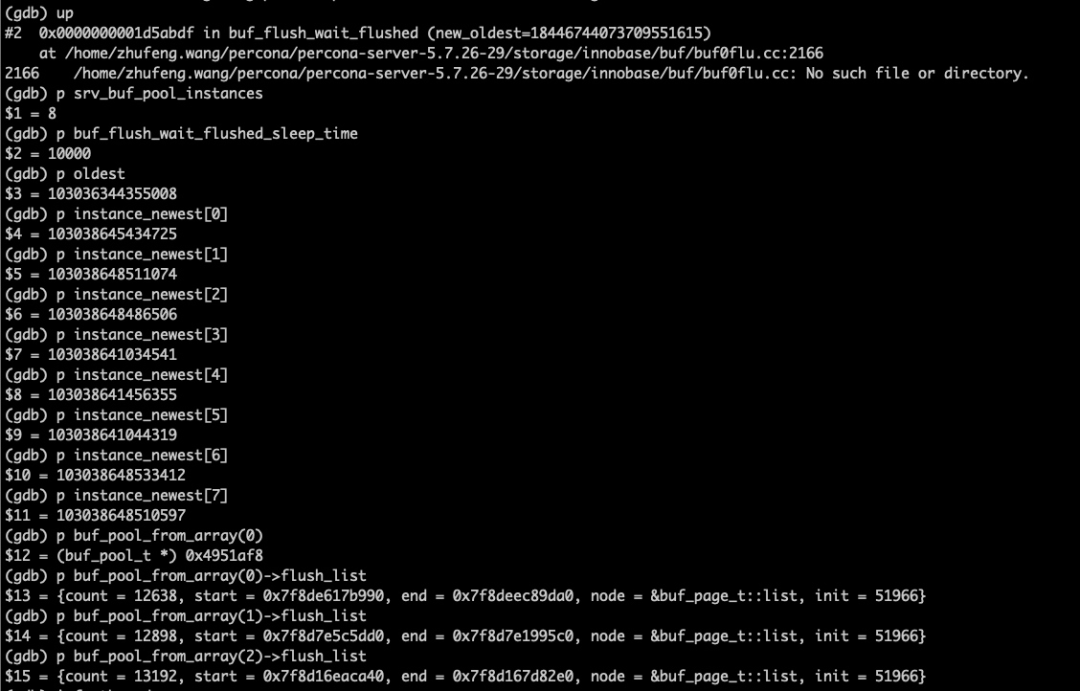
从图中可以看到有很多脏页,并且 oldest 都是小于任何一个 buffer instance 里面的 newest lsn 的,感兴趣的同学可以对照源代码看看,循环退出的条件是 oldest 要大于每一个 instance_newest ,而oldset是一直不变的,一直是 103036344355008,比每一个都小,那为什么一直等不到 oldest 的变大呢?就是因为 buf_flush_page_cleaner_coordinator 线程没有正常工作。
而这里也需要纠正在上面我的一个判断,即在 TOP 中看到 CPU 很闲,占用率是 0,所以认为不是死循环,这里是不准确的,因为我们看代码会发现,在 buf_flush_wait_flushed 函数中的等待,也是死循环,只不过有一行代码为:
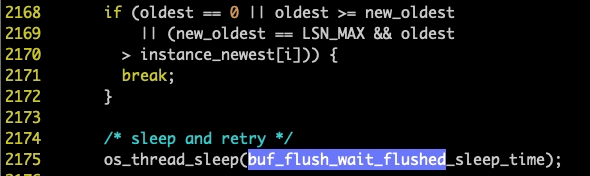
注释都说了, sleep 然后 retry ,而 buf_flush_wait_flushed_sleep_time 是多少呢?从代码中看到,是硬编码写死的,为 10000 microseconds ,那很明显,以这样的频率做死循环,确实不至于让 CPU 忙起来。
五、解决方法
问题现在已经清楚了,那如何解决呢?数据不会变,在实例生前做了 truncate ,这个改不了,一种最简单的办法就是,我们把数据重做了就好了,这确实是的,很简单,但想想,4T 的数据,这个时间成本太高了,DBA 已经很烦做这样的事情了。
那有没有更简单,快捷的办法呢?这是有的,既然我们已经编译好了一个debug版本,并且上面也看到了, buf_flush_wait_flushed 函数已经是死循环了,也知道是因为 new_oldest 参数传入的 LSN_MAX 值导致循环结束的条件不能满足,所以死循环,那我们如果可以让这个循环提前结束,条件满足了,不就可以了吗?
用 GDB 可以实现这样的功能,直接实战图:

看到这里,感觉就像是驾驶特斯拉,一踩“油门”,deng 一下就被弹出去一样,数据库瞬间快速正常运转起来,死循环一下子就破了,马上启动完成。
还有一种解决办法,就是不依赖当前这次启动过程,而是直接重启一次,重启之前将参数 innodb_flush_sync 修改为 ON ,这样启动就没有任何问题了,成功地避免了这样的问题。
具体到这个问题,如果能确定是 truncate 本身操作,而不是其它内部原因,可以将 data 目录下面,对应的 *_trunc.log 文件都删掉,这样数据库启动的时候就不会加载相关信息了,也就不会有问题了,当然,这种办法要谨慎使用,因为毕竟是在做物理上面的数据破坏的,并且有了上面能用参数控制来避免问题的办法,其它解决问题的办法就可以不屑一顾了。
本人因为选择了 gdb 的办法来解决此问题,所以其它两种办法都没有机会实践了,叹叹叹!!!
六、进一步疑问
按照上面的启动方法,数据库是可以正常启动了,但如果下次再 shutdown ,再启动,是不是问题还会出现。答案是否定的,因为正常启动之后,truncate 相关的 log 已经被清掉了,所以再启动的时候,就不会再调用 truncate_t::fixup_tables_in_non_system_tablespace 函数了,所以也就不会有问题了。
七、问题澄清
本来准备给 bugs.mysql.com 报个 bug 的,为了更准确地表明问题,找到了 MySQL 官方的代码版本,找到了函数 log_preflush_pool_modified_pages ,发现与我们上面分析的代码不太一样,如下图所示:
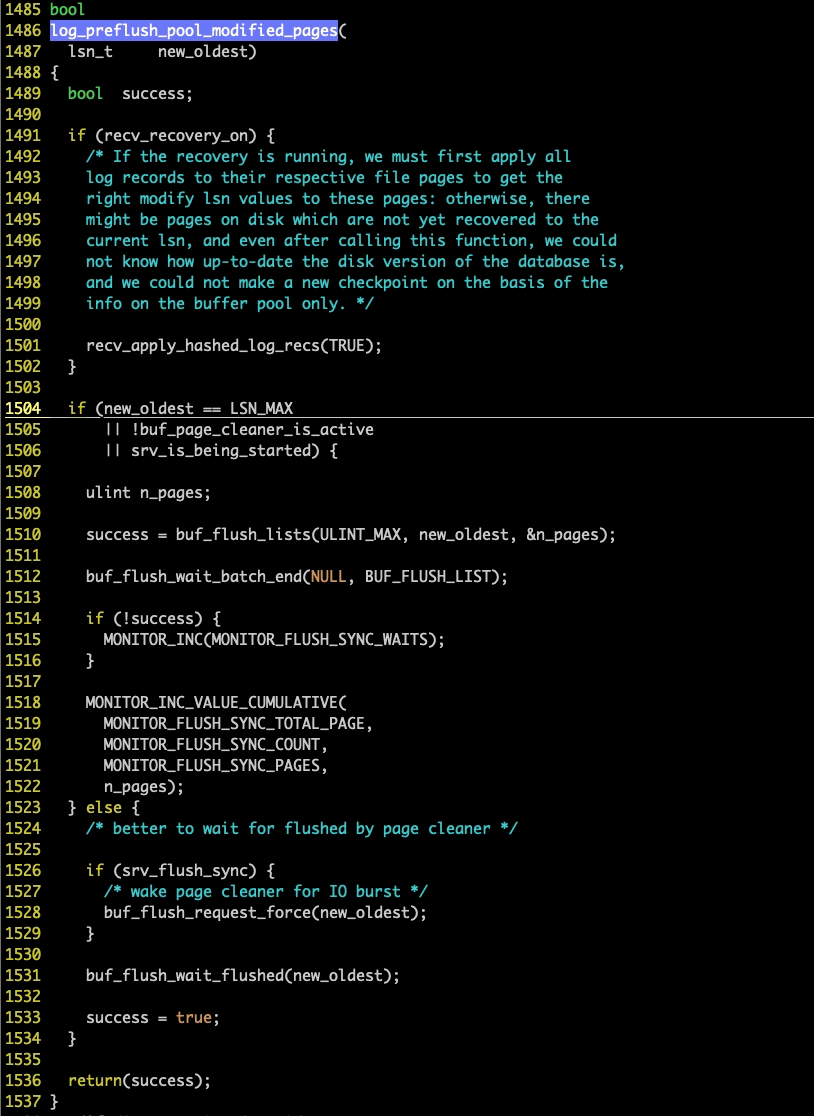
可以看出,官方版本代码是没有这个问题的,因为出问题的时候, new_oldest 是 LSN_MAX ,这种情况下会进入图中有横线的那个分支中去,这里不存在死等的问题,而只有指定刷盘到某一个具体的 LSN 值的时候,才会走到下面的分支。
可以大胆猜测一下,这个问题应该是 Percona 改出来的新的问题,并且至今没有被发现。
八、总 结
问题我们现在清楚了,很明显这个是一个 bug ,通过我们的分析,改 bug 的方式,可以把 fixup 放到 buf_flush_event 后面去做,应该就没有这个问题了,但这个还需要推动官方去修改,我们做为运维人员,只需要学会遇到问题如何去避免,就够了(当然应该去报一个 bug ),当然如果想去尝试改掉这个问题,也是可以的,只不过要维护起来,就很不简单了,如果没有相应的人力,团队,最好不要走这条路。万一改出来问题呢?这个损失可能更大了。
这个问题,遇到的人也可能比较少,所以在看了 Percona 5.7.33 最新版本,看着代码也没什么变化,说明至今没有被修改好,同时也说明,针对 truncate 这个问题,官方也没有测试充分。
另外,还需要去思考一个问题,对于这个 bug ,如果我们对源码不太了解,这个问题还能解决掉吗?能知道什么原因吗?我想可能做不到,应该是做不到的,这也从侧面说明,DBA 掌握点源码是多么的重要,这是活生生地用源码解决问题的案例啊,或者反过来讲,如果不知道源码,如何能把这个问题,与参数 innodb_flush_sync 能联系起来?MySQL 手册可不会告诉你这些。
DBA 这个职业,一直被业界很多人认为即将要被机器替代了,的确,因为云时代的出现,自动化平台的出现,很多操作,都被机器替代了,所以得出的结论是,DBA 不重要了,即将会被淘汰。我认为,这个结论很明显是错误的,云时代以及自动化平台的出现,只能是让 DBA 的入门门槛变得更高,让 DBA 的工作效率更高,让 DBA 承担起更重要的工作,有时间解决更复杂的问题,有精力构建更好的平台、架构,做更多的有价值的输出。而学习源码,就是做一个不会被淘汰的 DBA 的最好的捷径。
而更重要的是,你的职业是一个 MySQL DBA,MySQL 给了你一个学习源码的机会,让你有源码可学,这是其它数据库所不能替代的。
MYSQL is The world's most popular open source database!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721