
作者介绍
梁铭图,新炬网络首席架构师,十多年数据库运维、数据库设计、数据治理以及系统规划建设经验,拥有Oracle OCM、Togaf企业架构师(鉴定级)、IBM CATE等认证,曾获dbaplus年度MVP以及华为云MVP等荣誉,并参与数据资产管理国家标准的编写工作。在数据库运维管理和架构设计、运维体系规划、数据资产管理方面有深入研究。
Innodb cluster是oracle官方提供集群方案,前期我们管理的其中一个集群出过一次故障,导致集群无法正常使用,经过分析主要是由于集群内多个数据库之间的GTID不一致造成的。本次主要是针对搭建的环境进行日常的工作中可以出现情况进行故障维护,具体故障模拟如下:集群未启动时,手工对单节点中的数据进行增加或删除。再次尝试启动集群,由于集群中数据不一致,会导致集群启动失败。修复的措施则是需要对比集群中的所有节点GTID事务信息,手工执行已经缺失的事务,以正常启动集群。
一、测试体系架构

测试环境如下
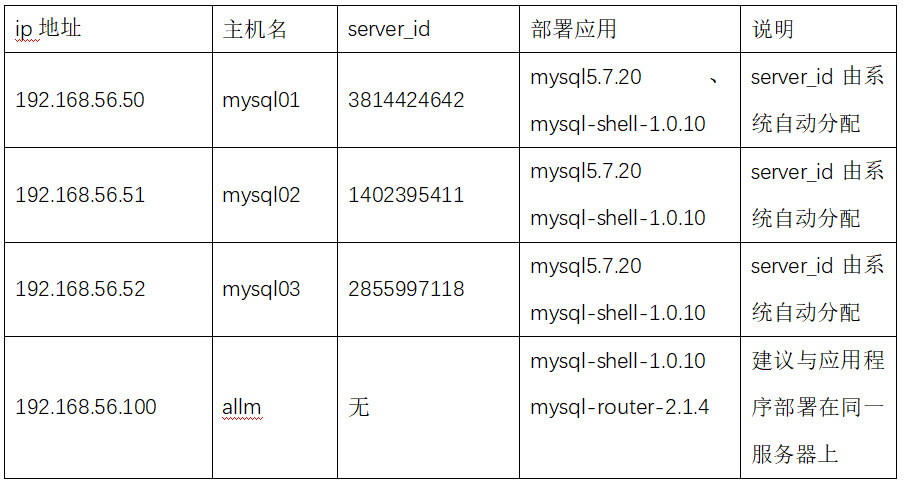
Innodb cluster包含single-primary和multi-primary两种,single-primary只有一个节点提供读写操作,其他节点提供只读操作,在主节点出现故障的情况下,第二个节点自动转化为主节点,对外提供读写操作。而multi-primary的所有节点都提供读写操作,但是存在诸多限制(这些限制在后续纠结介绍),需要根据集群特点进行合理的规避,以免触发限制。本次的维护是针对multi-primary。
二、故障模拟
mysql,即第一节中的三个节点的mysql数据库。
mysql-router,即第一节中的管理节点,allm服务器。
mysql-shell,每一台服务器上都安装有此组件。
systemctl start mysqld
在mysql02上新建一个测试库,并在此库上新建一张测试表:
create database allm;
create table test (id int primary key,name varchar(20));
启动allm服务器的mysql-router服务
mysqlrouter -c /opt/mysqlrt/mysqlrouter.conf &
使用mysqlsh连接到mysql01进行集群的启动
连接至mysql01
mysqlsh --uri root@192.168.56.50:3306
dba.rebootClusterFromCompleteOutage();
输出结果如下:
mysql-js> dba.rebootClusterFromCompleteOutage();
Reconfiguring the default cluster from complete outage...
The instance '192.168.56.51:3306' was part of the cluster configuration.
Would you like to rejoin it to the cluster? [y|N]: y
The instance '192.168.56.52:3306' was part of the cluster configuration.
Would you like to rejoin it to the cluster? [y|N]: y
Dba.rebootClusterFromCompleteOutage: Dba.rebootClusterFromCompleteOutage: The active session instance isn't the most updated in comparison with the ONLINE instances of the Cluster's metadata. Please use the most up to date instance: '192.168.56.51:3306'. (RuntimeError)
集群启动失败,原因是其中一个节点数据不一至导致启动集群失败。
三、故障修复

从以上查询到的信息可以得出,本地的GTID事务信息为:
3f7c00d3-0017-11e8-97ea-080027f0bb96:1-14
3f478a5e-001a-11e8-80d7-080027f0bb96:1-22。
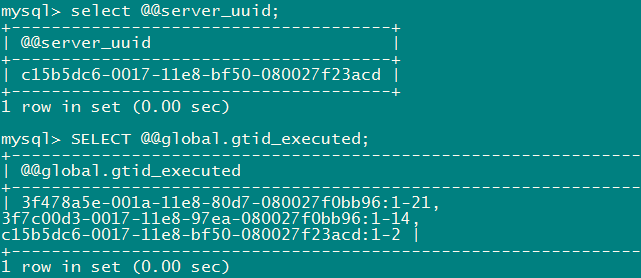
从以上查询到的信息可以得出,本地的GTID事务信息为:
3f478a5e-001a-11e8-80d7-080027f0bb96:1-21
3f7c00d3-0017-11e8-97ea-080027f0bb96:1-14
c15b5dc6-0017-11e8-bf50-080027f23acd:1-2
对比节点1的GTID事务信息,需要在节点mysql01执行c15b5dc6-0017-11e8-bf50-080027f23acd:1-2的事务,节点mysql02需要执行3f478a5e-001a-11e8-80d7-080027f0bb96:22的GTID事务。
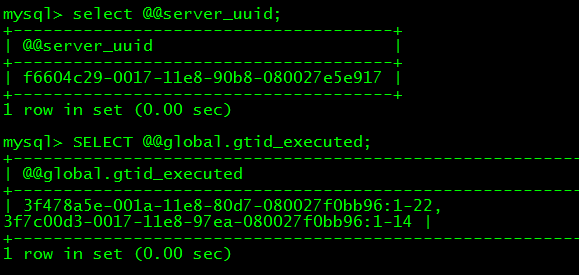
从以上查询到的信息可以得出,本地的GTID事务信息为:
3f478a5e-001a-11e8-80d7-080027f0bb96:1-22
3f7c00d3-0017-11e8-97ea-080027f0bb96:1-14
对比mysql01和mysql02的GTID事务信息,需要在节点mysql03执行c15b5dc6-0017-11e8-bf50-080027f23acd:1-2的事务。
此示例需要在另外两个节点创建allm数据库,并创建test表。
节点mysql01执行:
SET GTID_NEXT="c15b5dc6-0017-11e8-bf50-080027f23acd:1";BEGIN; COMMIT;
SET GTID_NEXT="c15b5dc6-0017-11e8-bf50-080027f23acd:2";BEGIN; COMMIT;
节点mysql02执行:
SET GTID_NEXT="3f478a5e-001a-11e8-80d7-080027f0bb96:22";BEGIN; COMMIT;
节点mysql03执行:
SET GTID_NEXT="c15b5dc6-0017-11e8-bf50-080027f23acd:1";BEGIN; COMMIT;
SET GTID_NEXT="c15b5dc6-0017-11e8-bf50-080027f23acd:2";BEGIN; COMMIT;
在allm管理节点上执行:/opt/mysqlsh/bin/mysqlsh --uri root@192.168.56.50:3306。
mysql-js> dba.rebootClusterFromCompleteOutage();
Reconfiguring the default cluster from complete outage...
The instance '192.168.56.50:3306' was part of the cluster configuration.
Would you like to rejoin it to the cluster? [y|N]: y
The instance '192.168.56.51:3306' was part of the cluster configuration.
Would you like to rejoin it to the cluster? [y|N]: y
The cluster was successfully rebooted.
查看集群状态:
mysql-js> cluster.status()
{
"clusterName": "myCluster",
"defaultReplicaSet": {
"name": "default",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"192.168.56.50:3306": {
"address": "192.168.56.50:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"192.168.56.51:3306": {
"address": "192.168.56.51:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"192.168.56.52:3306": {
"address": "192.168.56.52:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
}
}
}
}
通过修复缺失的GTID事务信息,集群已经可以完全正常启动。
四、小结
1、需要充分了解GTID的事务机制,当出现事务缺失时,可以快速的进行集群的修复。
2、innodb cluster目前的,需要对其集群体系架构有充分的了解,并且需要对集群的日常维护进行实践,当出现故障时,可以针对不同的故障现象进行维护。
3、需要充分的了解multi-primary当前的限制,当需要使用此种集群作为生产系统时,充分考虑风险以及制定针对性的方案规。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721