
这个元旦不太平,刚刚发生了全球几百套MongoDB数据库数据被人删除,讨要比特币做赎金的事件,这就又发生了一件诡异、罕见的事。
你也许从来没想过,居然有一天,你的数据库会创建不了对象,是因为42亿个对象编号用到极限!而我居然真的遇到了!
是的,甭论是要创建全局临时表,或者是序列,或者索引,都通通报错!
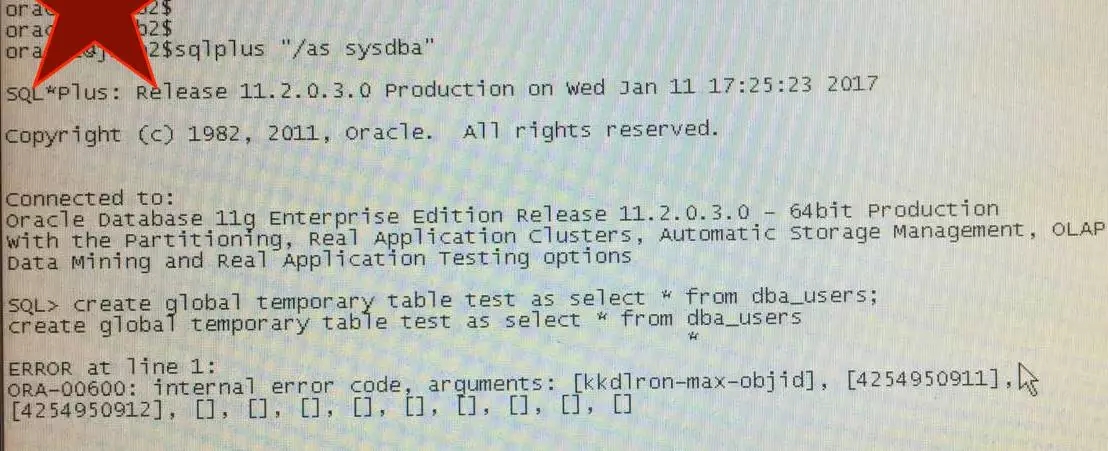
是的,甭说是你,就是全球,也没几个人遇到过,看看MOS文章就知道了:

唯一的一篇文章,告诉你遇到了一个bug,文章里对这个bug的简单描述是这样:
如果你遇到ORA-600 [kkdlron-max-objid]错误,说明新建对象的对象编号(Object ID)超过数据库限制了!从MOS文章和我们创建对象遇到的错误看,这个数据库限制的最大对象编号是4254950911!这个bug在某些操作系统平台的某些版本上是有补丁支持的,但是,但是,但是,重要的事情说三遍!这个所谓的补丁,也只不过是把这个数据库限制的最大编号增大了一点儿而已,让你好重建数据库,然后在逻辑导入所有表,这些表会重新获得新的对象编号。
那你肯定会关心,额滴神啊,我十几个TB的数据,逻辑导入是一个小工程啊,要申请停机时间啊,这要老命了!
这么个幺蛾子的情况,为什么偏偏就被我遇到了呢?
是的,这种情况极为少见,但不是不会发生,墨菲定律大家都懂的,莫非,莫非,莫非就偏偏碰见了你!
有大量分区表或索引,对象会很频繁drop然后又create的数据库系统,就容易中招了!
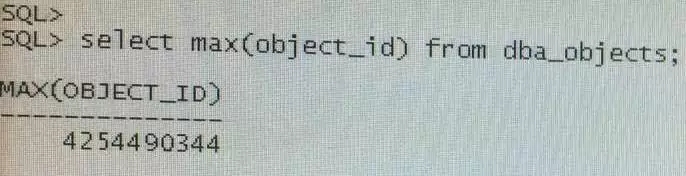
首先来看看我们中招的数据库,数据库对象的最大编号是多少:
慢着!
报错信息说的啥?那个编号是4254950911,比当前数据库系统中最大编号大460567, 难道是每个数据库对象编号不是顺序来的,而是中间要隔40多万!
我们将数据库最新创建的对象按时间倒序排列,可以看到相连两个对象编号差别最大是1447773(WRH对象和SP对象),最小是1。这说明一个问题,对象创建时,编号还是顺序连续来的。
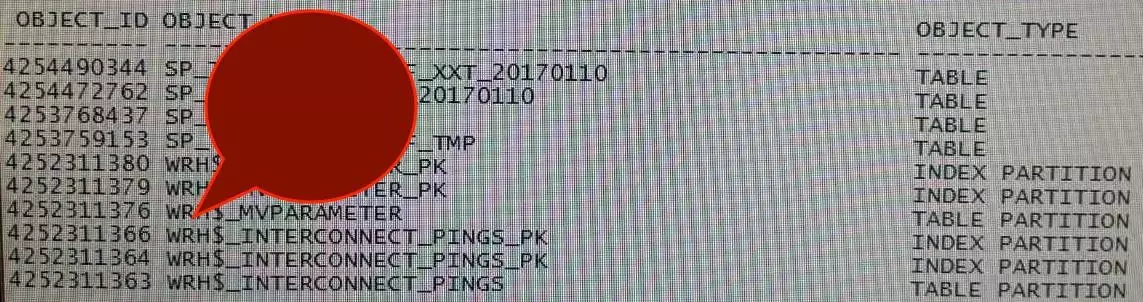
事实上,这个对象编号它就是一个数据库“序列”。(题外话,你有没有想过序列重置?思考下到底行还是不行?)
SQL> SELECT dataobj# FROM sys.obj$ where name='_NEXT_OBJECT';
DATAOBJ#
----------
4254950908
SQL> select max(object_id),max(DATA_OBJECT_ID) from dba_objects ;
MAX(OBJECT_ID) MAX(DATA_OBJECT_ID)
-------------- -------------------
4254909633 4254950794
从中我们可以看出,它申请的下一个序列值是4254950908,与创建对象报错的值4254950911仅仅只相差3而已。说明我们数据库中目前还存在的最大对象编号之后,还是创建过几十万次对象的。
那接下来我们看看最近几天创建的数据库对象,每天的最大ID是多大呢,也就是说数据库编号每天增幅大概多少?
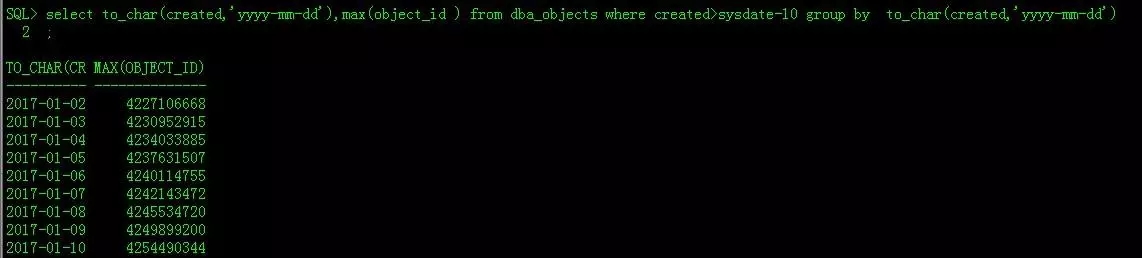
我们可以看到,最近10天,每天数据库对象编号增长,最小是202万,最大是459万。
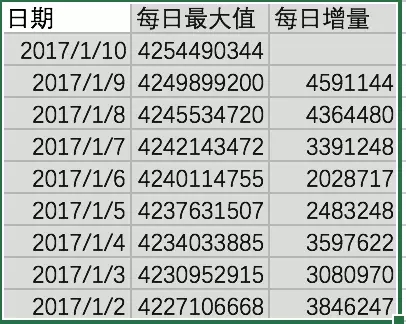
这个数据库是2013年创建的。
如果按照每日最大增幅算,4年时间最大的对象编号应该是:
4*365*4591144=6703070240
如果按照上图显示的最小增幅算,最大的对象编号应该是:
4*365*2028717=2961926820
而当前最大数据库对象编号是4254490344,在这两个数之间。也就是说,一句话,每天的数据库对象编号增幅达百万级。啥意思?每天有百万次创建数据库对象的命令?按每天最大增量算,平均每秒钟要执行53次创建命令。
4591144/24/60/60=53.13824074
这显然不太可能!
进一步研究看看,做一把日志挖掘?
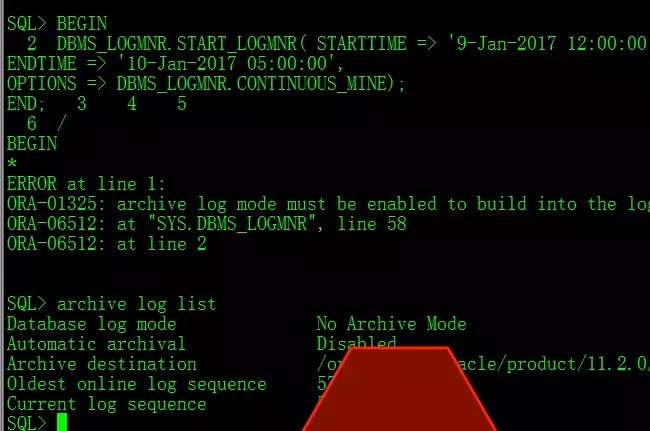
考虑到数据日志产生量太大,没有启用归档模式。
所以,无法查询到真实的DDL语句执行情况,也无从较真了。
但是,长远来看,从应用层降低数据库对象的drop/create频率是必须的,从数据库维护层监控对象编号也是必须的。
从短期来看,是否具有临时解决方案(参数、或者补丁,因为应用侧到此已经彻底死掉了)可以绕过这个问题。
没有参数,也没有灵丹妙药,但是看起来补丁还不少:
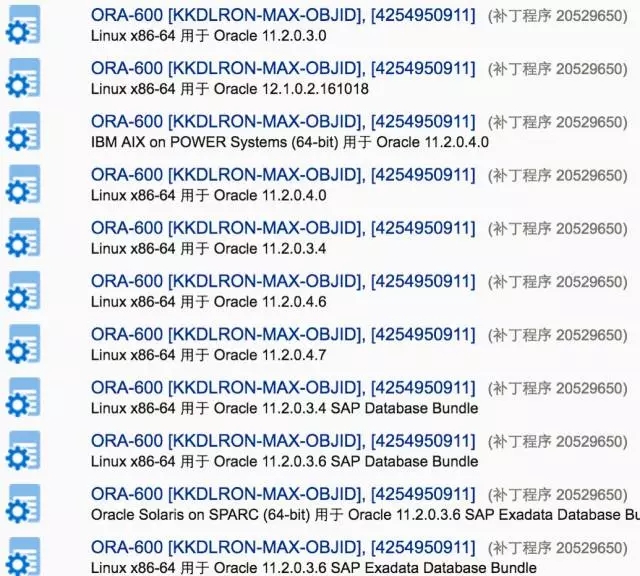
不过,当前这个数据库版本11.2.0.3支持的平台很少,只有Oracle自家的才被支持:
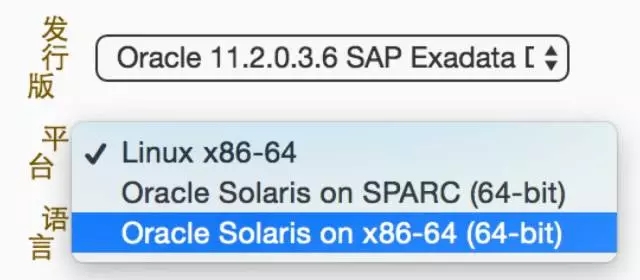
而故障数据库的平台不在此列。也就是说,苟延残喘的机会也破灭了!
撸起袖子干吧!建新库,逻辑导出,逻辑导入(impdp)!十几个TB的数据要耗时多久呢?

解释一下,Oracle支持的最大对象编号是多少?
下面这段内容来自伟翔同学:
“从Oracle 8开始ROWID改成由data_object_id#、 rfile#、 block# 、row#组成,它使用Base64位编码的18个字符显示,其实rowid的存储方式是:10 个字节即80位存储,其中数据对象编号需要32 位,相关文件编号需要10 位,块编号需要22,位行编号需要16 位,由此,我们可以得出,32位的对象编号,支持的最大编号为:”

报错显示的值是4254950911,与理论最大值相差4000万,也就是说,如果打了补丁,按照这个增速,也就是可以再蹦跶10天而已。
那怎么办呢?
我们对于危机的恐惧不在于到底有多艰难,而在于危机发生的不确定性。
所以,通过我们的苦难,写这篇文章,给你们大家一个预警。
增加一个监控告警,最高级别,每天最大对象编号增长超过10万,就告警。
做运维就是这样,经验和能力是通过一个又一个苦难堆积出来的。
数据库运维哪家强?比拼的是团队十年如一日的运维经验总结积累。
运维靠的不是花裙秀腿,运维靠的是简单实用,一招制敌!
介绍下几个我们常用的数据库配置、检查的建议项,你一定用得着(每项都至少发生过一次生产上血淋淋的故障,但我们相信你可能只做了一两个):
Oracle RAC环境,禁用DRM;
Oracle RAC环境,所有应用sequence缓存默认设置为500(特殊的可以更高,或者是0);
所有数据库,AUDSESS$这个sequence缓存设置为1000;
新应用上线,禁止使用DB Link;
所有新数据库安装,必须部署OSW(RAC库开启PRVNET);
一个表空间最多不要超过1000个数据文件;
……今天是不是应该增加一条应用每天新增的数据库对象不超过10000个??这个数据库总的数据库对象也才20000个哦~
关于运维变更和监控的几点规范:
关于涉及应用的变更(创建、删除、修改数据库对象结构,新增SQL语句),必须提前2天提交,SQL审核(可以通过人工,我们也做了自动的Oracle SQL审核工具)通过后允许上线,否则必须经过一定级别领导的特批。
关于系统级的普通变更,不允许生产时间执行。
关于数据库的监控,相信你可能已经设置了不少,每天都烦不胜烦了。但是以下这些,如果你还没有部署,建议尽快实施:
SCN天花板监控
Sequence最大值监控
……
以及我们今天学到的,对象最大编号增量监控
如果说大型系统的开发人员无法保证自己不编写有bug的代码,那么专业的运维人员同样无法保证自己不遇到故障(不要奇怪,比如HPUX平台cp命令都是可能引发故障的,比如密集的ping命令也是,等等)。差别只在于专业的运维团队踩过足够多的坑之后,可以帮助后来者规避掉这些坑而已,就像柯洁比聂卫平更年轻成为围棋第一人这样。至于Master轻松战胜柯洁,那是另一个玩法,很重要,也是运维人的新目标。
如果你还有补充,欢迎文末评论留言,让还没有Master帮助的更多运维兄弟不走你走过的坑!
看到这里,是不是觉得还是有点意犹未尽?我们也一样,所以我们自己做了些测试。
基于12cR1的环境,我们直接把数据库对象的最大编号修改了(声明:我们只是测试,不要在生产上干!干了出问题你自己负责!)。
命令:
update obj$ set dataobj#=4254950905where name='_NEXT_OBJECT';
然后往数据库里面再创建几个新表,立马就故障重现了。
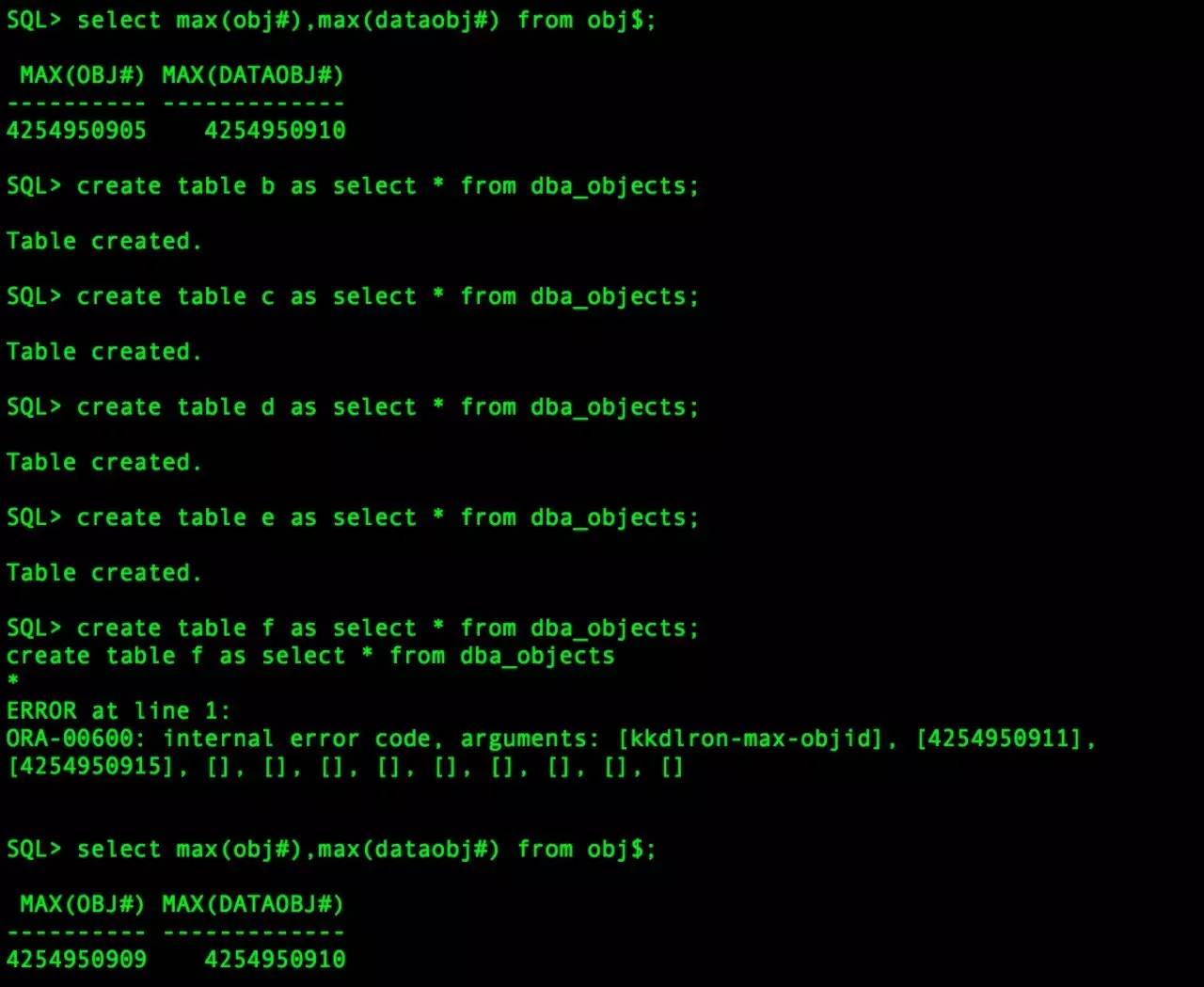
相同的ORA-600错误。
在这个版本,Oracle是提供了补丁的,赶紧下载下来,打上去。
再看看,是不是突破限制了。
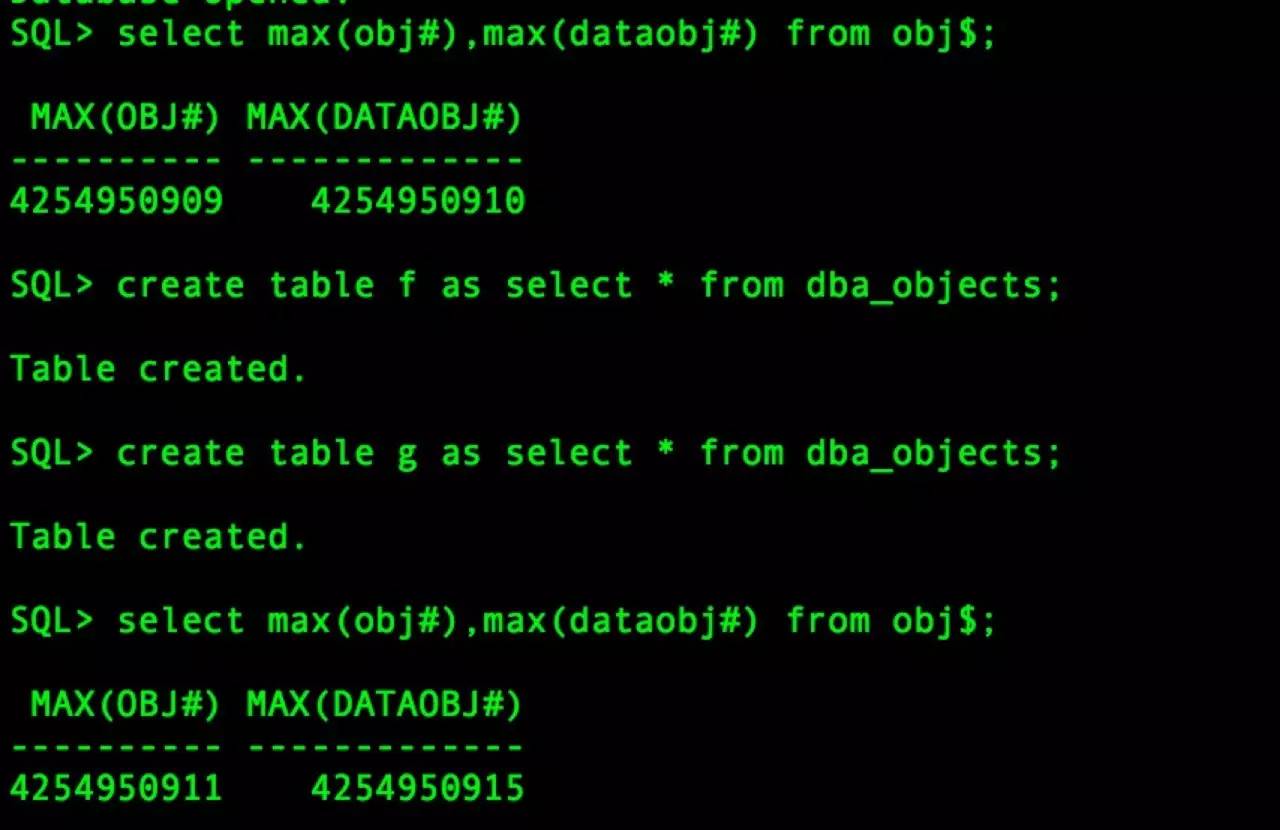
非常好, 至少是可以苟延残喘了嘛!
我们再看看OBJECT_ID最大可以到多少。
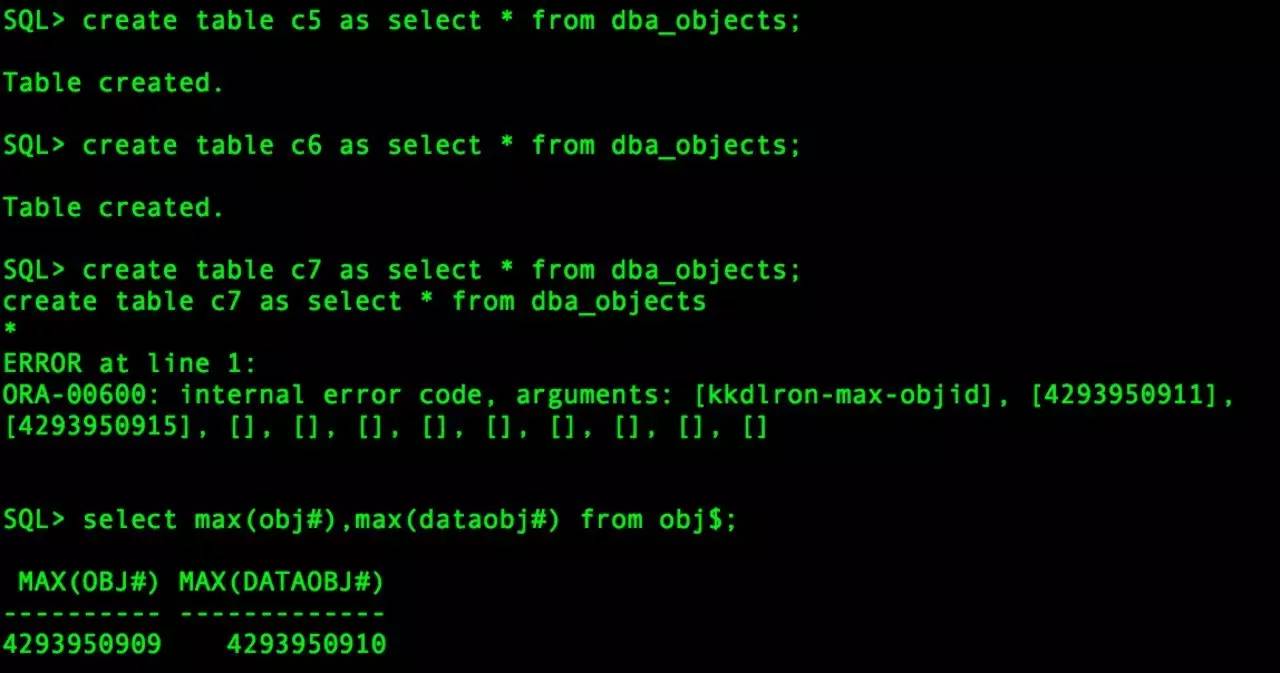
结论:不打补丁只能4254950910 ,打了补丁可以到4293950910,这个是最大能到的OBJECT_ID了,虽然你的数据库可能永远也用不到这个数。
比较幸运的是,发生故障的数据库是一个与历史数据关系不紧密的数据库。所以很快在新的环境里搭建了同版本的数据库,导入对象逻辑结构后,业务就恢复了。
导入:
先做逻辑结构的导入;
再做数据的导入。
使用impdp+network方式,差不多每小时100GB的样子。根据表类型分成不同的通道可以节省一些总时间。
新环境的OBJECT_ID变化分析:
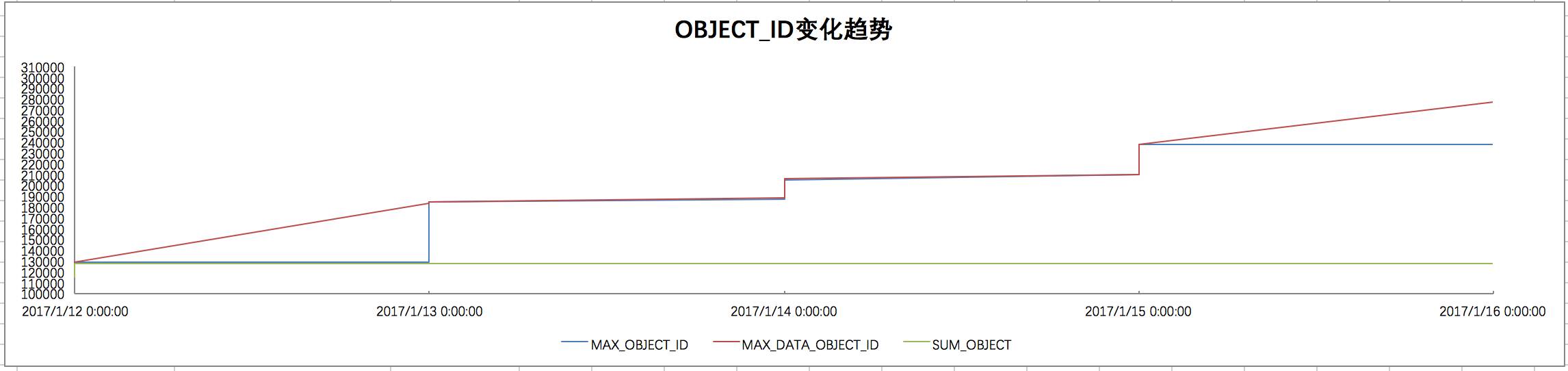
我们可以看到,四天增长了接近18万,平均每天4万左右。
图中没有显示得特别好的是,每天的Data_Object_id比Object_id要快,但是新的Object_ID是基于Max(Data_object_id)的。
从这里可以简单看出,虽然新库的OBJECT_ID没有像老库临死前几天那样每天几百万的增量,但每天几万仍然是一个不小的数字了。
这从另一个侧面来说,频繁Truncate或Drop/Create 表是这类故障发起的诱因,尽管确实罕见。
这个神奇的数字,我们从MOS文章ID 76746.1:SCRIPT: ForBug:970640 to check if Target Database has been corrupted文章中找到一些信息:
LIMIT number:=2147483648; /* Highest sensible object id */
MAXOBJ number:=4294950911;/* Max ever object id */
next_id number; /* Current NEXT object_id*/
high_id number; /*Current Highest object_id */
best_id number; /*Current Highest Object_id below LIMIT */
badcnt number:=0; /*Number of objects with ID above LIMIT */
dups boolean:=false; /*True if duplicate dataobj# */
*/
4294950911是Oracle软件程序设定的最大允许Object_id。这个文章中主要是一个检查对象编号健康度的脚本,虽然是针对8i写的,但有助于大家了解数据库的对象编号问题,可以前往查看。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721