
罗敏,从事Oracle技术研究、开发和服务工作20余年,在Oracle中国公司的10多年,分别在顾问咨询部、技术服务部担任资深技术顾问。曾参与国内银行、电信、政府等多个行业大型IT系统的建设和运维服务工作,为国内主要软件开发商和集成商进行过多场Oracle高级技术应用培训和交流活动。著有书籍《品悟性能优化》、《感悟Oracle核心技术》、《Oracle数据库技术服务案例精选》。
今天本人不妨对一条不太复杂的SQL语句在技术上进行深入剖析,与大家共同分享其中的实施经验和实施方法,更对其中折射出的一些深层次问题发表些许感悟。
这是一条来自某行业数据仓库系统的SQL语句:
SELECT /*+ PARALLEL(4) */
A.NSRZHDAH, A.SSSQQ, A.SSSQZ, A.NSRSBH
FROM J1_LDM.LDMT02_YE_SBXX A, J1_DI.DI_ZSXM B
WHERE A.SBQX >= '20160101'
AND A.SBQX <= '20160331'
AND A.GZLX_DM IN ('1', '2')
AND A.ZSXM_DM = B.ZSXM_DM
AND B.SFBZ_DM = '1'
AND (A.SBRQ > A.SBQX OR SBRQ IS NULL)),
这是该语句现有的执行计划:
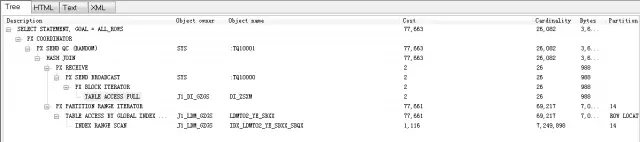
该语句现有执行时间为5分58秒,逻辑读为386750,物理读为130678 。
上述执行计划中Oracle对表LDMT02_YE_SBXX表是按SBQX字段索引进行访问,而DI_ZSXM是一个代码表,该表进行全表扫描非常正常。进一步,我发现LDMT02_YE_SBXX表按SBRQ(申报日期)字段按月进行了分区,而SBQX(申报期限)字段索引是按月进行Global Range Partition分区的分区索引。另外,对这两个表的访问Oracle均采用了并行处理技术。
该语句现有执行计划似乎很正常,也就是好像没什么优化空间。查询2006年1月1日至2016年3月31日3个月的交易数据,需要将近6分钟在业务上似乎也很正常。
尽管看似正常,但我还是想尝试优化的可能性。首先,我发现针对这种查询3个月交易数据的典型的大批量数据访问语句,开发人员强制使用并行处理的策略是非常正确的。但是,开发人员的Hint: /*+ PARALLEL(4) */ 编写方式得有点另类,那就是为什么只写并行度(DOP)为4,而不写表名呢?于是我尝试将该语句Hint修改为:/*+ PARALLEL(a,4) */。再观察执行计划,奇怪的事情发生了:
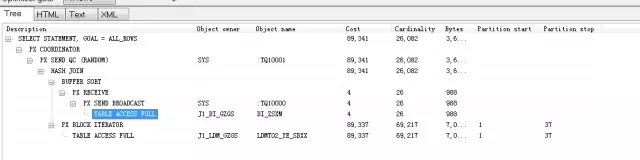
原来,Oracle优化器此时对LDMT02_YE_SBXX表的访问不再走SBQX字段索引,而改走全表扫描了!语句实际执行效果呢?执行时间为2分52秒,速度提高1倍!但是逻辑读为651387,物理读为620747。也就是说,尽管资源开销更大,但针对数据仓库应用,Oracle全表扫描速度比按索引访问更快!
尽管执行时间更快了,但针对几千万、甚至几亿条记录的交易明细表进行全表扫描总不是一种好策略,而且资源消耗的确更大了,毕竟该语句只是查询3个月的数据。
假设将该表调整为按SBQX(申报期限)字段进行月分区,Oracle将采用分区裁剪功能,也就是该语句只查询3个月的分区数据,性能一定能大幅度提升!不仅预计响应速度在1分钟之内,甚至秒级,而且逻辑读、物理读都将大幅度下降。
可惜我在现场工作时间有限,也无法在生产或测试环境进行这种调整分区策略的大动干戈的验证,但略有经验的数据库设计和开发人员都知道这种优化策略的效果是显而易见的。
当我向应用开发人员提出上述分区表改造建议时,他们也说出了他们的设计初衷:原来他们是考虑应用主要是通过SBRQ(申报日期)字段进行查询,因此就考虑按SBRQ(申报日期)字段进行分区设计了。同时,他们也对我的优化方案表示了担忧:如果改成按SBQX(申报期限)字段进行分区,那按SBRQ(申报日期)字段进行查询的SQL语句是不是就性能下降了?这就是很多数据库设计和应用开发人员的一个误区:以为SQL语句按哪个字段做条件多,就一定要按这个字段进行分区。
究其根源,设计者和开发人员还是对Oracle的分区技术,尤其是分区索引技术的了解不深入。回到该问题,尽管表按SBQX(申报期限)进行分区了,SBRQ(申报日期)字段仍然可以建成分区索引,包括Global Range Partition索引或者Local non-prefixed Partition索引,依然可以提高按SBRQ(申报日期)字段进行访问的效率。这就是这两种索引结合该案例的示意图:
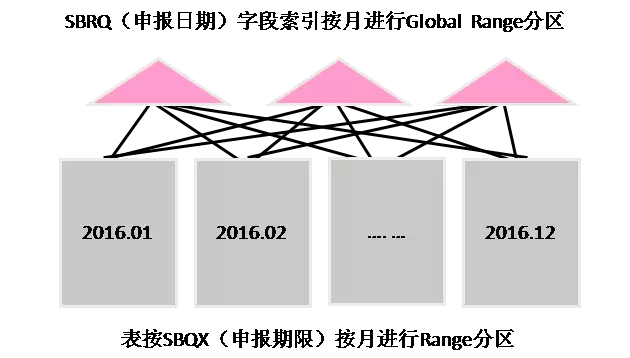

在Global Range Partition索引情况下,Oracle优化器能保证只访问一个索引子分区,访问效率仍然会有提升。但是,一旦出现分区管理操作(drop、split、merge等),将导致Global Range Partition索引失效,也就是导致业务连续性下降。
在Local non-prefixed Partition索引情况下,不会出现索引失效情况,也就是业务连续性尚可,但除非在SQL语句中增加分区字段SBQX(申报期限)的条件,否则,很可能导致该索引全扫描,性能反而会下降。
综合利弊,尤其是考虑SBQX(申报期限)和SBRQ(申报日期)两个字段本身的业务逻辑,SBQX(申报期限)保存的是月数据,是更宏观的字段,而SBRQ(申报日期)保存的是天数据,是更微观的字段。显然,将J1_LDM.LDMT02_YE_SBXX表按SBQX(申报期限)字段进行按月范围分区,更符合业务逻辑。
通过上述这个并非复杂的SQL语句的深入剖析,我想首先感悟的就是:广大应用开发人员在开发数据仓库应用时技术运用一定要有针对性,同时也要保证技术运用的合理性。
众所周知,IT系统总体上可分为联机交易系统(OLTP)和联机分析系统(OLAP)两类,OLAP系统也可称之为数据仓库系统。这两类系统无论在业务特征还是适用的技术方面都迥然不同。对OLTP应用,具有并发量大、单笔事务处理的数据量小等特点,应以系统的响应速度作为首要的优化目标。而OLAP应用则具有大批量数据处理、并发事务低特点,应该以系统整体吞吐量作为优化目标。OLAP系统在具体技术运用策略方面,应该贯彻大批量、并行处理思路,并合理运用Oracle并行处理、分区操作、HASH-JOIN、MERGE语句、数据仓库函数、外部表、位图索引、物化视图等典型技术。
索引技术其实更适合于OLTP系统中的小事务处理,而针对该案例查询3个月数据的大批量数据处理,全表或全分区扫描加并行处理则是更适合的技术策略了。回到该案例,当我告诉应用开发人员全表扫描加并行处理比索引访问更快时,令他们十分惊讶。
再者,分区技术既适合于OLTP系统,也适合于OLAP系统,但是针对这两类系统,分区技术运用策略和实现目标是不同的。我们应该深入分析应用需求特点,结合Oracle丰富的分区技术,有针对性地选择分区字段,并合理设计分区索引。例如,若只考虑性能,则将SBRQ(申报日期)设计为Global Range Partition索引是合理的。若作为数据仓库系统,未来需要按SBQX(申报期限)按月进行分区的历史数据管理操作,则SBRQ(申报日期)设计为Local non-prefixed Partition索引,将不会出现索引失效情况,也就是业务连续性将更高。同时,针对数据仓库应用具有按时间进行访问和分析的特点,尽量建议在语句中增加分区字段SBQX(申报期限)条件,这样性能也能得到保证。若这样设计就更全面、更合理了。
通过该案例,大家也一定能感悟到这一点,那就是业务与技术结合的重要性。我想这也正是国内IT行业多年来一直存在的一个痼疾:一方面,业务人员包括应用开发人员尽管非常熟悉应用逻辑,但对相关底层技术的确缺乏深入、细致的了解,在技术运用方面的确存在明显的误区和不足,例如本案例中应用开发人员就是对Oracle的各种分区技术,尤其是各种分区索引技术的原理、适用场景等缺乏全面、深入的理解。而另一方面,熟悉底层技术的人员,又不愿意去关注业务逻辑和实际需求。总之,这就是典型的业务和技术的脱节问题。
这种局面的存在导致什么后果呢?这就是IT系统普遍存在的粗糙、性能低下、资源消耗过大等问题。继续回到该案例,无论是客户,还是技术人员一定只是感受到应用响应速度慢、I/O资源消耗太大等表面现象,进而简单地认为是存储系统效率太低,甚至感觉是Oracle对海量数据仓库系统处理能力有限,需要给系统瘦身,进行历史数据迁移,从而进一步加剧整个系统架构的复杂性。设计开发人员甚至以现在流行分库设计为理由,欲将该数据仓库大卸八块,进行拆库操作,殊不知都是数据库设计和应用开发本身的问题,把库拆小了,只是缓解了问题,并没有从根本上解决问题。
业务与技术的有机结合是何等重要!
相关专题:
◆ 近期热文 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721