
随着IT技术的飞速发展,各行各业都已在广泛尝试使用大数据技术提供更稳健和优质的服务。目前,医疗IT系统收集了大量极具价值的数据,但这些历史医疗数据并没有发挥出其应有的价值。为此,本文拟利用医院现有的历史数据,挖掘出有价值的基于统计学的医学规则、知识,并基于这些信息构建专业的临床知识库,提供诊断、处方、用药推荐功能,基于强大的关联推荐能力,极大地提高医疗服务质量,减轻医疗人员的工作强度。
目前大数据处理领域的框架有很多。
从计算的角度上看,主要有MapReduce框架(属于Hadoop生态系统)和Spark框架。其中Spark是近两年出现的新一代计算框架,基于内存的特性使它在计算效率上大大优于MapReduce框架;从存储角度来看,当前主要还是在用Hadoop生态环境中的HDFS框架。HDFS的一系列特性使得它非常适合大数据环境下的存储。
Hadoop不是一个软件,而是一个分布式系统基础架构,是由Apache基金会主持开发的一个开源项目。Hadoop可以使用户在不了解分布式底层实现的情况下,开发分布式程序,从而充分利用电脑集群的威力,实现高速运算和大规模数据存储。Hadoop主要有HDFS、MapReduce、Hbase等子项目组成。
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且使用可靠、高效、可伸缩的方式进行数据处理。Hadoop假设数据处理和存储会失败,因此系统维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop通过并行工作,提高数据处理速度。Hadoop能够处理PB级数据,这是常规数据服务器所不能实现的。此外,Hadoop依赖于开源社区,任何问题都可以及时得到解决,这也是Hadoop的一大优势。Hadoop建立在Linux 集群上,因此成本低,并且任何人都可以使用。它主要具有以下优点:
高可靠性。Hadoop系统中数据默认有三个备份,并且Hadoop有系统的数据检查维护机制,因而提供了高可靠性的数据存储。
扩展性强。Hadoop在普通PC服务器集群上分配数据,通过并行运算完成计算任务,可以很方便的为集群扩展更多的节点。
高效性。Hadoop能够在集群的不同节点之间动态的转移数据。并且保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够保存数据的多个副本,这样就能够保证失败时,数据能够重新分配。
Hadoop总体架构如下图所示,Hadoop架构中核心的是MapReduce和HDFS两大组件。
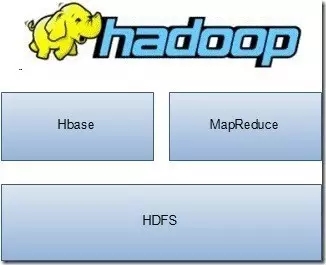
Google曾发表论文《Google File System》,系统阐述了Google的分布式文件系统的设计实现,Apache针对GFS,进行开源开发,发布了Hadoop的分布式文件系统:Hadoop Distributed File System,缩写为HDFS。MapReduce的核心思想也由Google的一篇论文《MapReduce:Simplified Data Processing on Large Clusters》 提出,简单解释MapReduce的核心思想就是:任务分解执行,执行结果汇总。
Spark是UC Berkeley大学AMP实验室开源的类似MapReduce的计算框架,它是一个基于内存的集群计算系统,最初的目标是解决MapReduce磁盘读写的开销问题,当前最新的版本是1.5.0。Spark—经推出,就以它的高性能和易用性吸引着很多大数据研究人员,在众多爱好者的努力下,Spark逐渐形成了自己的生态系统( Spark为基础,上层包括Spark SQL,MLib,Spark Streaming和GraphX),并成为Apache的顶级项目。
Spark的核心概念是弹性分布式存储(Resilient Distributed Datasets, RDD)间,它是Spark对分布式内存进行的抽象,使用者可以像操作本地数据集一样操作RDD,从而可以将精力集中于业务处理。在Spark程序中,数据的操作都是基于RDD的,例如经典的WordCount程序,其在Spark编程模型下的操作方式如下图所示:
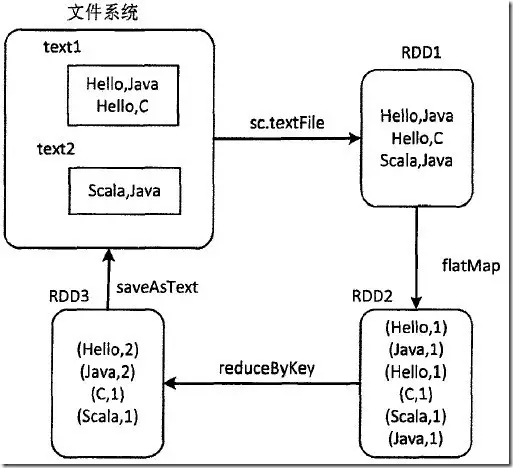
可以看到Spark先从文件系统抽象出RDD1,然后由RDD1经过flatMap算子转换得到RDD2,RDD2再经过reduceByKey算子得到RDD3,最后RDD3中的数据重新写回文件系统,一切操作都是基于RDD的。
经过多方面的思考,最终决定基于Spark技术进行构建和实现医院临床知识库系统,采用MongoDB/Sequoiadb构建大数据仓库,做为大数据的存储中心,采用Hadoop+Spark1构建大数据分析平台,基于AgileEAS.NET SOA中间件构建ETL数据抽取转换工具(后期部分换用了Pentaho Kettle),基于AgileEAS.NET SOA中间件构建知识库的服务门户,通过WCF/WebService与HIS系统进行业务整合集成,使用AgileEAS.NET SOA+FineUI构建基础字典管理以后分析结构的图像化展示功能。
最初我们选择了SequoiaDB做为大数据存储中心,为此我还特意的为SequoiaDB完成了C#驱动,参考本人为巨杉数据库(开源NoSQL)写的C#驱动,支持Linq,全部开源,已提交Github一文,但是一方面熟悉SequoiaDB的技术人员太少了,维护是个问题,最后,在差不多8多个月这后我们换用了MongoDB 3.0做为大数据存储中心。
最初我们选择了Hadoop2.0+Spark1.3.1版本之上使用scala2.10开发完成了医院临床知识库系统,请参考centos+scala2.11.4+Hadoop2.3+Spark1.3.1环境搭建,但是在后期替换Sequoiadb为MongoDB的同时,我们把计算框架也由Hadoop2.0+Spark1.3.1升级到了Hadoop2.6+Spark1.6.2。
考虑到Spark都部署在Linux的情况,对于Spark分析的结果输出存储在MySQL5.6数据库之中,系统所使用的各种字典信息也存储在MySQL之中。
Spark数据分析部分的代码使用IntelliJ IDEA 14.1.4工具进行编写,其他部分的代码使用VS2010进行编写。
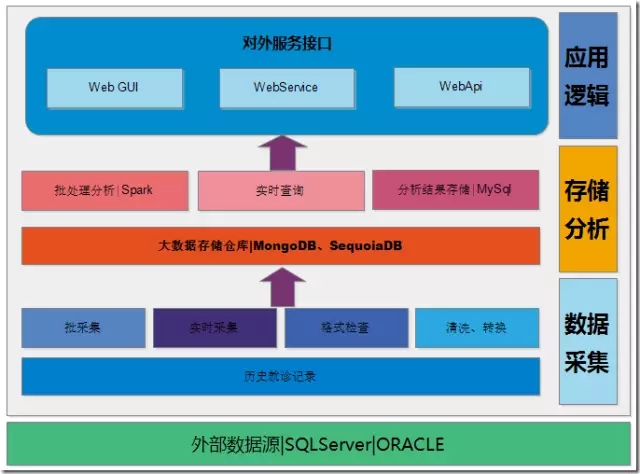
整个系统由数据采集层、存储分析层和应用逻辑层三大部分以及本系统所选所以来的外部数据源。
本系统的外部数据源目前主要是医院信息系统所产生的临床数据,目前主要集中在HIS系统之中,后期将采依赖于EMR、LIS、PACS系统。
数据采集层主要负责从临床业务系统采集海量历史临床数据同,历史记录采集方式分为批采集和实时采集,在数据采集过程之中对原始数据进行格工检查,并对原始数据进行清洗和转换,并将处理后的数据存储在大数据仓库之中。
存储分析层主要负责数据存储以及数据分析两大部分业务,经过清洗转换的合理有效数据被存储在大数据集群之中,使用JSON格式,大数据存储引用使用SequoiaDB数据库,数据分析部分由Hadoop/Spark集群来完成,大数据存储经由Spark导入并进行分析,分析结果写入临床知识数据库,临床知识数据库使用MySQL数据库进行存储。
应用逻辑层主要负责人机交互以及分析结构回馈临床系统的渠道,通过WebUI的方式向临床医生、业务管理人员提供列表式、图像化的知识展示,也为临床系统的业务辅助、推荐功能提供调用的集成API,目前API主要通过WebService、WebAPI两种方式提供。
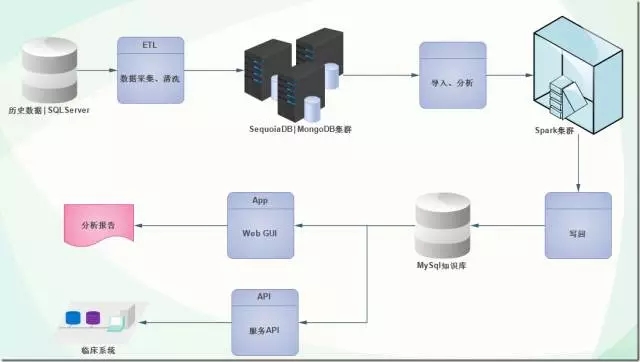
整个系统经由数据源数据采集,写入大数据存储SequoiaDB集群,然后由Spark进行分析计算,分析生成的临床知识写入MySQL知识库,经由WebUI以及标准的API交由临床使用。
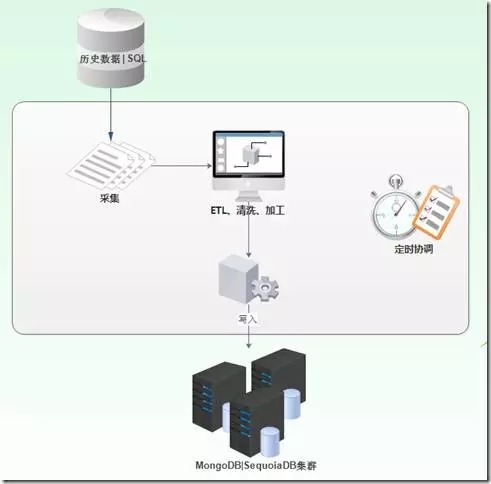
历史数据的采集导入使用初期使用AgileEAS.NET SOA 的计划任务配何C#脚本进行实现,由计划任务进行协调定时执行,具体的数据导入代码根据不同的临床业务系统不同进行脚本代码的调整,也可以使用Pentaho Kettle进行实现,通过Pentaho Kettle可配置的实现数据的导入。
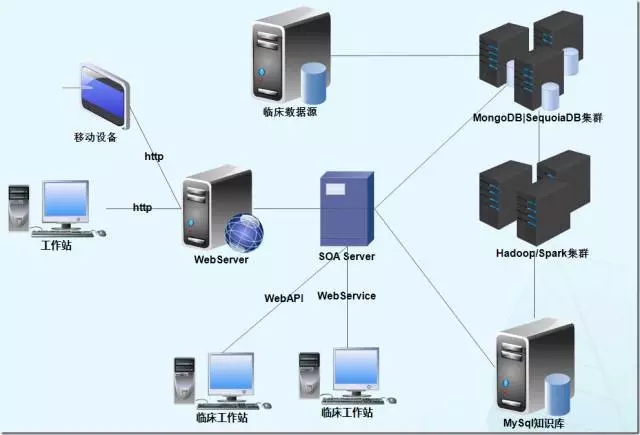
临床数据源为本系统进行分析的数据来源,源自于临床HIS、EMR,目前医院的HIS使用SQL Server 2008 R2数据库,EMR使用ORACLE 11G数据库,运行于Windows2008操作系统之上。
SequoiaDB集群为大数据存储数制库集群,目前使用SequoiaDB v2.0,运行于Centos6.5操作系统之上,根据业务来规模使用2-16节点集群,其用于存储经过清洗转换处理的海量历史临床数据,供Spark集群进行分析,以及供应SOA服务器进行历史数据查询和历史相关推荐使用。
Hadoop/Spark集群为本系统的分析计算核心节点,用于对SequoiaDB集群之中的历史数据进行分析,生成辅助临床医生使用的医学知识,本集群根据业务来规模使用2-16节点集群,使用Centos6.5操作系统,安装JAVA1.7.79运行环境、scala2.11.4语言,使用Hadoop2.3,Spark1.3.1分析框架。
MySQL知识库为本系统的知识库存储数据库,Hadoop/Spark集群所生产的分析结构写入本数据库,经由SOA服务器和Web服务处理供临床系统集成使用和WebGUI展现,目前使用MySQL5.6版本,安装于Windows2008/Centos6操作系统之上。
SOA Server为本系统的对外接口应用服务器,向临床业务系统和Web Server提供业务运算逻辑,以及向临床业务系统提供服务API,目前运行于Windows2008操作系统,部署有.NET Framework 4.0环境,运行AgileEAS.NET SOA 中间件的SOA服务,由AgileEAS.NET SOA 中间件SOA服务向外部系统提供标准的WebService以及WebAPI。
Web Server为系统提供基于标准的B/S浏览器用户接口,供业务人员通过B/S网页对系统进行管理,查询使用知识库之中的医学知识,目前运行于Windows2008操作系统,部署有.NET Framework 4.0环境,运行于IIS7.0之中。
临床工作站系统运行HIS、EMR系统,两系统均使用C#语言SOA架构思路进行开发,与本系统集成改造后,使用标准WebService接口本系统,使用本系统所提供的API为临床提供诊疗辅助。
目前系统跑在虚拟化环境之中,其中三台Centos6组成大数据存储、计算集群,每台分配16CPU(核)16G内存2T硬盘,3台共48核48G,这三台机器每台都安装了Java1.8.25+scala2.10+Hadoop2.6,Spark1.62,MongoDB3.0组合3节点的集群,Spark采用Standalone Cluster模式,单一master节点,为每台机器分配其中12核12G用于Worker,其余CPU内存留给MongoDB集群使用,运行截图如下:

一台Win2008做为SOA|应用服务器,分配32核64G内存,部署了MySQL5.6,IIS,AgileEAS.NET SOA 服务,整个系统的SOA服务和Web管理界面由本服务器进行承载,一方面提供Web方式的管理和查询,另一方面以webservice、webAPI为临床系统提供服务。
具体环境的安装过程由于篇幅的原因在此就不在一一细说,我将会单独写一篇文章为大家进行详细的介绍。
第一次使用Spark,又没有多少资料可参考,所以在开发过程之中遇到不少的坑,特别是初期的时间,搭建环境就费了一周,写代码过程之中坑也是一直发现一直填坑,有点坑也填不了,直好换思路绕了,记得在Spark sql的udf自定义函数上,并不是所有函数都有坑,偶尔自己写的udf函数怎么都是过不去,找不到原因,看Spark的源代码也没看出个所以然,最后不得改写代码,换思路搞。
感觉特别有爱的就是scala语言了,我觉得使用.net 4.0(C#)的朋友们,特别是用熟Linq的兄弟们,scala语言太方便了,我感觉他基本上就是和linq一样方便,更没有节操的是,在函数之中可以定义类,不过,真的是很方便,我不是很喜欢Java,但是我喜欢scala。

门诊诊断排名是门诊诊断知识的图形化界面展示显示,用于展示全院或者指定专科的TopN位常用诊断,也为每一个诊断与性别、年龄等人群相关性以及与节气相关性图表展示。
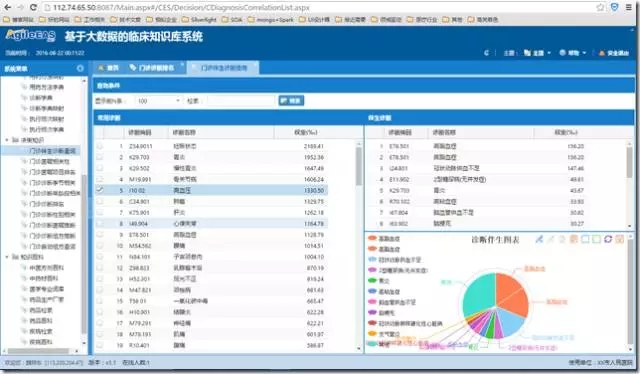
门诊伴生诊断排名是门诊诊断并发症的知识展示界面,用于展示得某一种疾病另其他疾病的可能性。
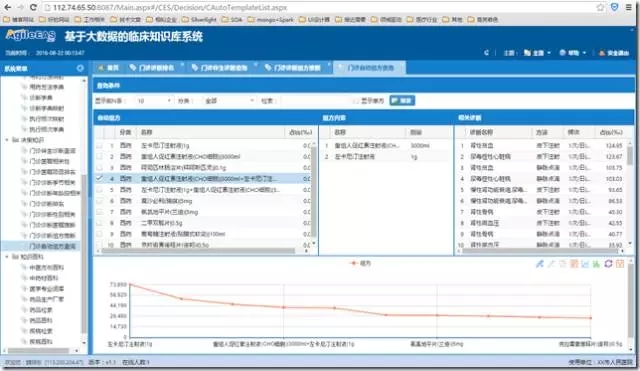
门诊自动组方查询,用于展示临床最常用的用药、治疗自动组方知识,即比如最常用的0.9%氯化钠注射液100ml配注射用头孢硫咪1g,常适用于扁桃体发炎、喘息性之气管炎、上呼吸道感染等疾病,给以静脉点滴方式每日一次使用。
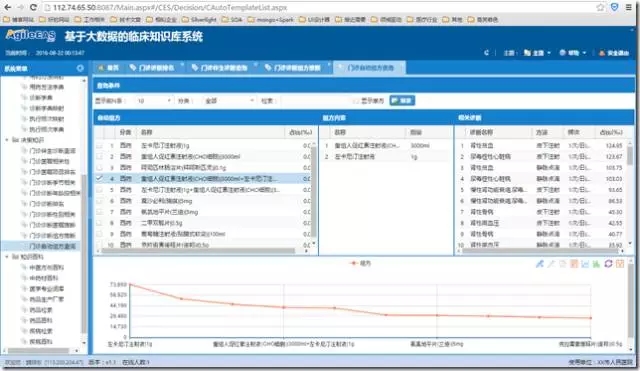
门诊诊断组方推断,用于展示临床疾病诊断与常用药品、治疗给合方案的相关性关联,即如上图展示上呼吸道感染常使用氨酚麻美干混悬剂1包、四季抗病毒合剂、0.9%氯化钠注射液100ml+注射用头孢硫咪1g、灭菌注射用水2ml+注射用重组人干扰素a1b 10ug等这样的组合治疗方案。
为了实现来源于临床系统,并且服务于临床系统的总体系统,我们联动了本院的HIS系统之中的门诊医生站,与本系统进行基于WebService的整合,如下图所示的整合界面:

临床医生在完成基本的门诊病历之后,系统会自动为其体检待选的门诊疾病诊断,80%-90%的情况可以直接选择,在少数情况下没有推荐合适的时候大夫才会录入,省去大夫录入诊断的麻烦,也减少因大夫录入的不规范而导致的数据的混乱。
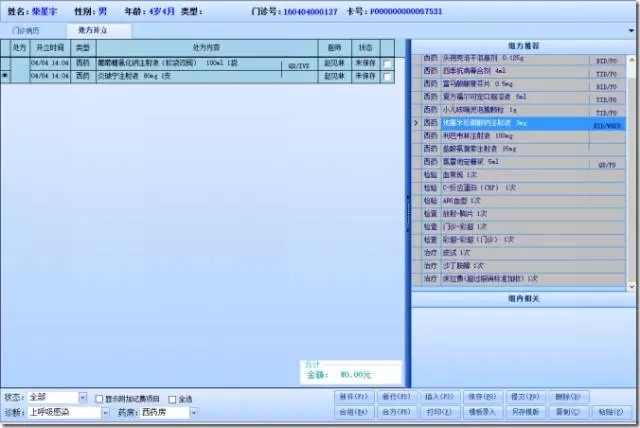
在临床医生写完门诊病历,进行开立检验、检查、用药、治疗的时间,系统会根据当有的诊断信息推荐合适的治疗方案选择,临床医生只需求在右边的推荐组方上双击即可实现快速的处方开方,大大的方便的临床医生的工作。
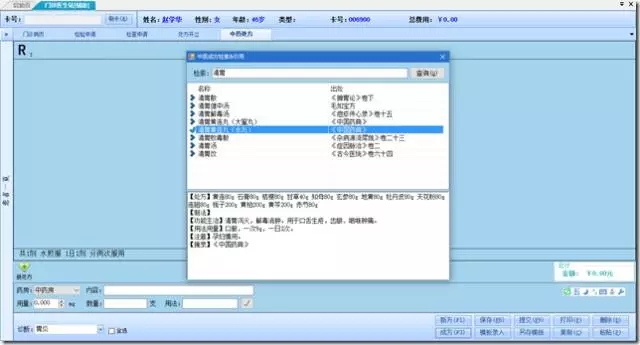
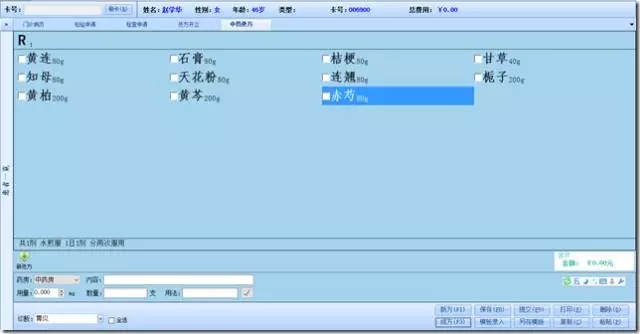
针对中医院,系统集成了3W多个经典成方,根据历史数据与成方字典的组合分析对比,极大的方便中医大夫日常工作:
对于大数据技术,以及大数据技术在医疗化信息行业的实践,以及实现之中的思路和细节,不是短短这么一点篇幅就能介绍完成的,此文也是在我实现需求,实践之后所写,所以总觉得东西都比较简单,我只期望本文能达到抛转引用的作用,能对同行做相关工作的朋友们有所参考,思路可以得到借鉴,然本文也实在没有讲清楚所有的细节。
接下来,我还会专门写一篇与本文使用的技术环境相匹配的一篇环境搭建、配置细节的文章,还请期待。
作者介绍 魏琼东
系统分析师/架构师、高级项目经理。13年开发和管理经验,为医疗、保险、教育、农业、房地产、电子政务等行业开发软件。
有丰富的理论知识及资深的行业软件经验,擅长企业软件过程改进、系统分析与架构设计、.NET平台架构技术、SQLServer/Oracle数据库技术、分布式架构体系及高性能并行计算,尤其对中小软件企业的软件研发管理体系有着深入的研究与应用。
经作者同意授权转载
来源:博客园









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒