
本文根据韩锋老师在〖3月11日北京数据库技术沙龙〗现场演讲内容整理而成。点击文末链接还能下载PPT哦~
韩锋
宜信技术研发中心数据库架构师
精通多种关系型数据库,曾任职于当当网、TOM在线等公司,曾任多家公司首席DBA、数据库架构师等职,多年一线数据库架构、设计、开发经验。
著有《SQL优化最佳实践》一书。
演讲大纲:
1、面临的挑战
2、审核平台选型
3、审核平台实践
今天我将从三个方面进行分享:首先我们看一下为什么我们想要开发这个平台,最初我们想做一个什么样的选型,怎么样来设计的,后面会讲一下平台实现过程,包括实现的一些基本原理、方法和一些功能介绍,最后会谈一下平台不足的地方,以及未来的发展。
目前这个项目已开源,欢迎大家参与到这个项目里面去,不断地完善它,发展它。
一、面临的挑战
1、运维规模及种类

我相信,这也是很多公司、很多DBA正在面临或未来都会面临的一些问题。正是存在问题,促使我们考虑引入数据库审核平台。
首先是运维规模与人力资源之间的矛盾。从我们的情况来看,运维了包括Oracle、MySQL、MongoDB、Redis四类数据库,数据库规模几十套,支持公司千余名开发人员及上百套业务系统。也许有的朋友会问,从运维规模上看,并不是很大。
的确,与很多互联网公司相比,数据库数十套的估摸并不是太大;但与互联网类公司不同,类似宜信这类金融类公司对数据库的依赖性更大,大量的应用是重数据库类的,且其使用复杂程度也远比互联网类的复杂。DBA除了日常运维(这部分我们也在通过自研平台提升运维效率)外,还需要有大量精力应对数据库设计、开发、优化类的工作。当面对大量的开发团队需要服务时,这个矛盾就更加凸显出来。
2、案例
结构设计
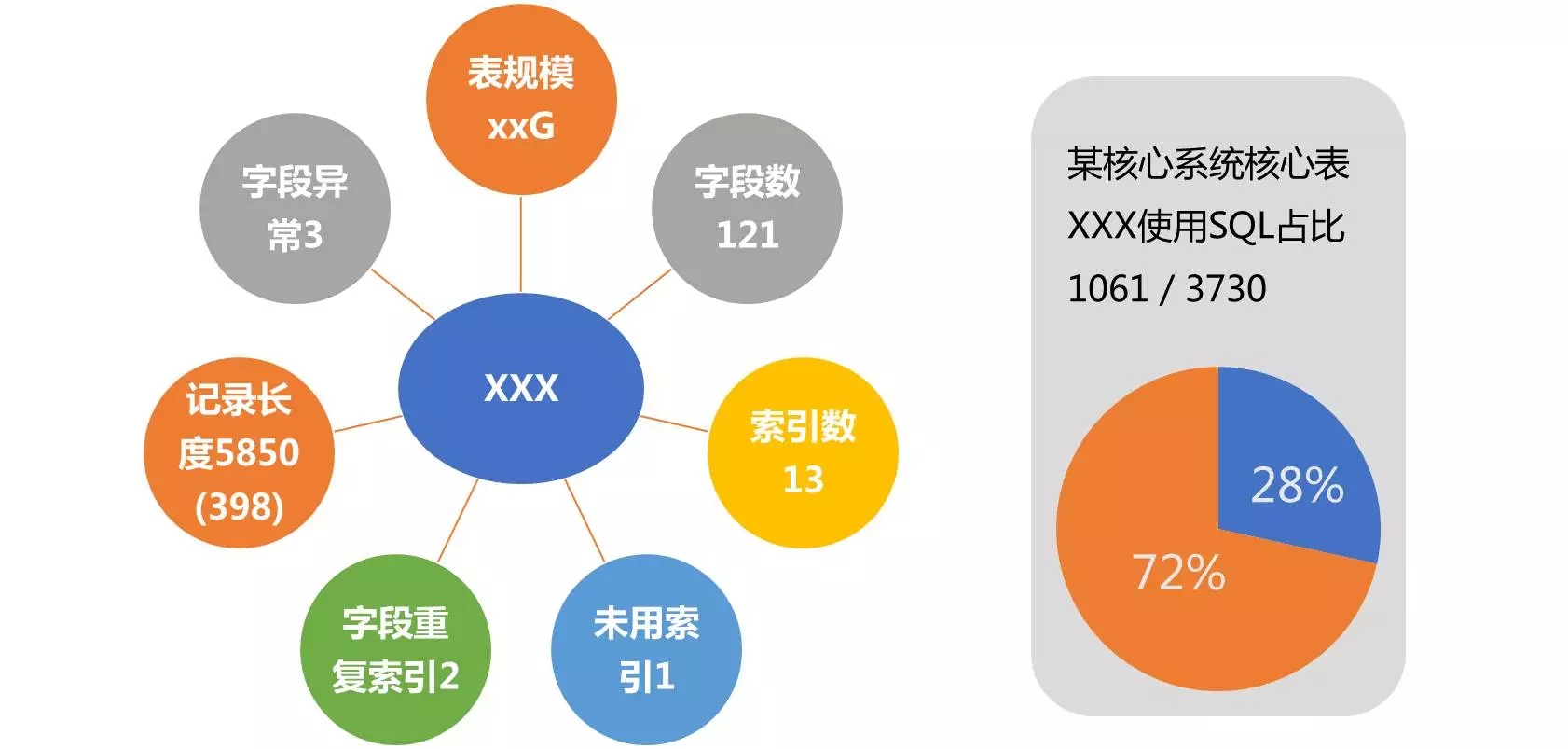
第二个挑战,是数据库设计、开发质量参差不齐的问题。这页就展示了一个结构设计问题。某核心系统的核心表,在这个系统运行的SQL中,28%都是跟这个对象有关的。当我们分析其结构时,发现了很多的问题:
表的规模很大,从设计之初就没有考虑到拆分逻辑(例如分库、分表、分区设计),也没有必要的数据库清理、归档策略。
表存在100多个字段,字段数很多且不同字段使用特征也不一致,没有考虑到必要拆表设计。
表有13个索引,数目过多。表的索引过度,势必会影响其DML效率。
还存在一个索引,在持续监控中发现,其从未被使用过。显然这是一个“多余”的索引。
还有两个字段存在重复索引的现象,这也说明在建立索引之初是比较随意的。
单个记录定义长度为5800多个字节,但实际其平均保存长度只有不到400字节,最大长度也不长。
分析其字段内容,还发现有3个字段类型定义异常。即没有使用应有的类型保存数据,例如使用数字类型保存日期。
综上所述,这个表设计的问题还有很多,而且这个表非常重要,大量语句访问和其相关。
SQL语句
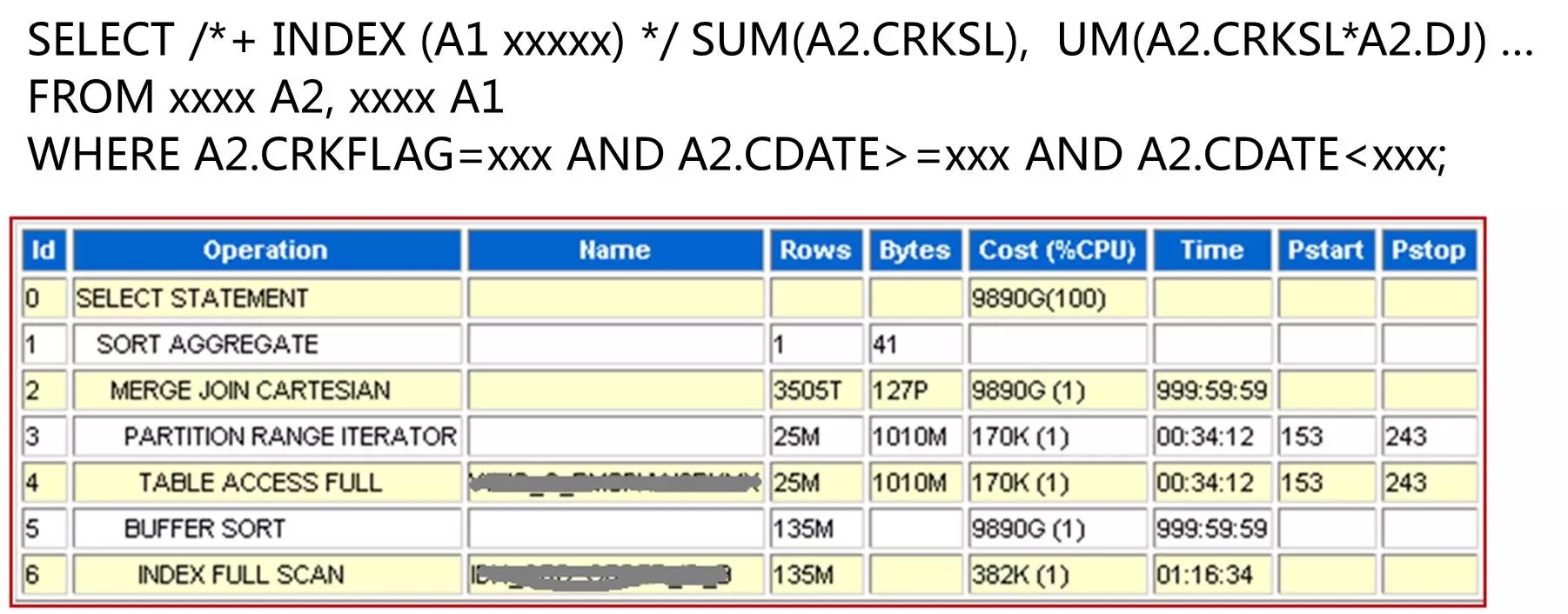
这页展示的是一个语句运行效率的问题。从字面可见,两个表做关联查询,但在指定条件时没有指定关联条件。在下面的执行计划中可见,数据库采用了笛卡尔积的方式运行。从后面的成本、估算时间等可见,这是一个多么“巨大”的SQL。其在线上运行的影响,可想而知。
也许有的朋友会说,这是一个人为失误,一般不会发生。但我要说的是,第一,人为失误无法避免,谁也不能保证写出SQL的运行质量;第二,开发人员对数据库的理解不同,很难保证写出的SQL都是高效的;第三,开发人员面临大量业务需求,经常处理赶工状态,很难有更多的精力放在优化上面。这因为有这些问题,线上语句执行质量就成了DBA经常面临的挑战之一。
3、重心转移
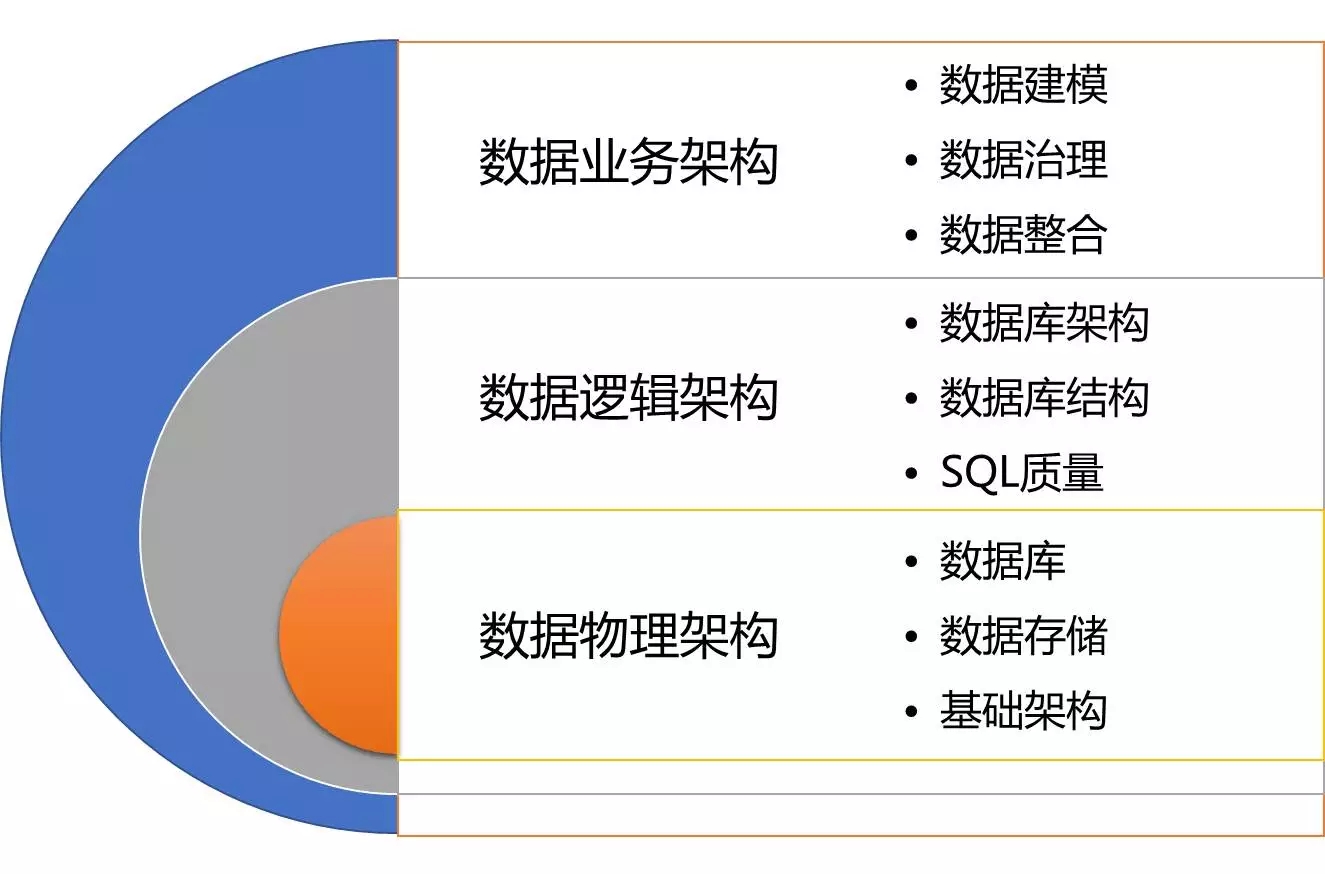
这是一张很经典的图,它描述了和数据库相关工作的职能划分。作为DBA,除了面临以上挑战外,从数据库工作发展阶段及自身发展需求来看,也面临一个重心的转移:原有传统DBA的运维职能逐步被弱化,大量的工具、平台的涌现及数据库自我运维能力的提升,简化DBA的工作;紧随而来的数据库架构、结构设计、SQL质量优化逐步成为重点;再往上层的数据治理、建模等工作也越来越受到一些公司的重视。由此可见,DBA未来工作的中心也逐步上移。对中间数据逻辑结构部分,也需要一些工具、平台更好地支撑DBA的工作。
除上述情况外,我司还存在几种的不平衡。

从DBA日常工作来看,传统运维工作还是占了较大的比重,而架构优化类则相对较少。通过引入这一平台,可以帮助DBA更方便地开展架构、优化类工作。
公司使用了较多的商业产品,而开源则使用较少。从公司长远战略来看,开源产品的使用会越来越多。从功能角度来看,商业产品相较于开源产品是有优势的。基于开源产品的软件开发,对开发者自身技术技能要求更高。希望通过引入这一产品,可以更容易完成这一转型过程。
没有平台之前,DBA还是大量通过手工方式设计、优化数据库,其效率十分低下。特别是面对众多产品线、众多开发团队时,往往感觉力不从心。
公司自有团队人员上,还是以初中级为主,中高级人员相对较少。如何快速提升整体设计、优化能力,保证统一的优化效果成为摆在面前的问题。
正是有了上述多种的不平衡,促使我们考虑引入工具、平台去解决数据库质量问题。
我刚来到公司时,看到公司的这些问题,也曾考虑通过制度、规范的形式进行解决。一开始就着手制定了很多的规范,然后在各个部门去培训、宣讲。这种方式运行一段时间后,暴露出一些问题:
整体效果改善并不明显。实施效果取决于各个部门的重视程度及员工的个人能力。
规范落地效果无法度量,也很难做到量化分析。往往只能通过上线运行结果来直观感知。
缺乏长期有效的跟踪机制。无法对具体某个系统长期跟踪其运行质量。
从DBA的角度来看,面对大量的系统,很难依据每个规范,详细审核其结构设计、SQL运行质量。
面临上述这些挑战、现存的各种问题,该如何解决?
经过讨论,最后大家一致认为,引入数据库审核平台,可以帮助解决上面所述问题。
二、平台的选型
1、业内做法
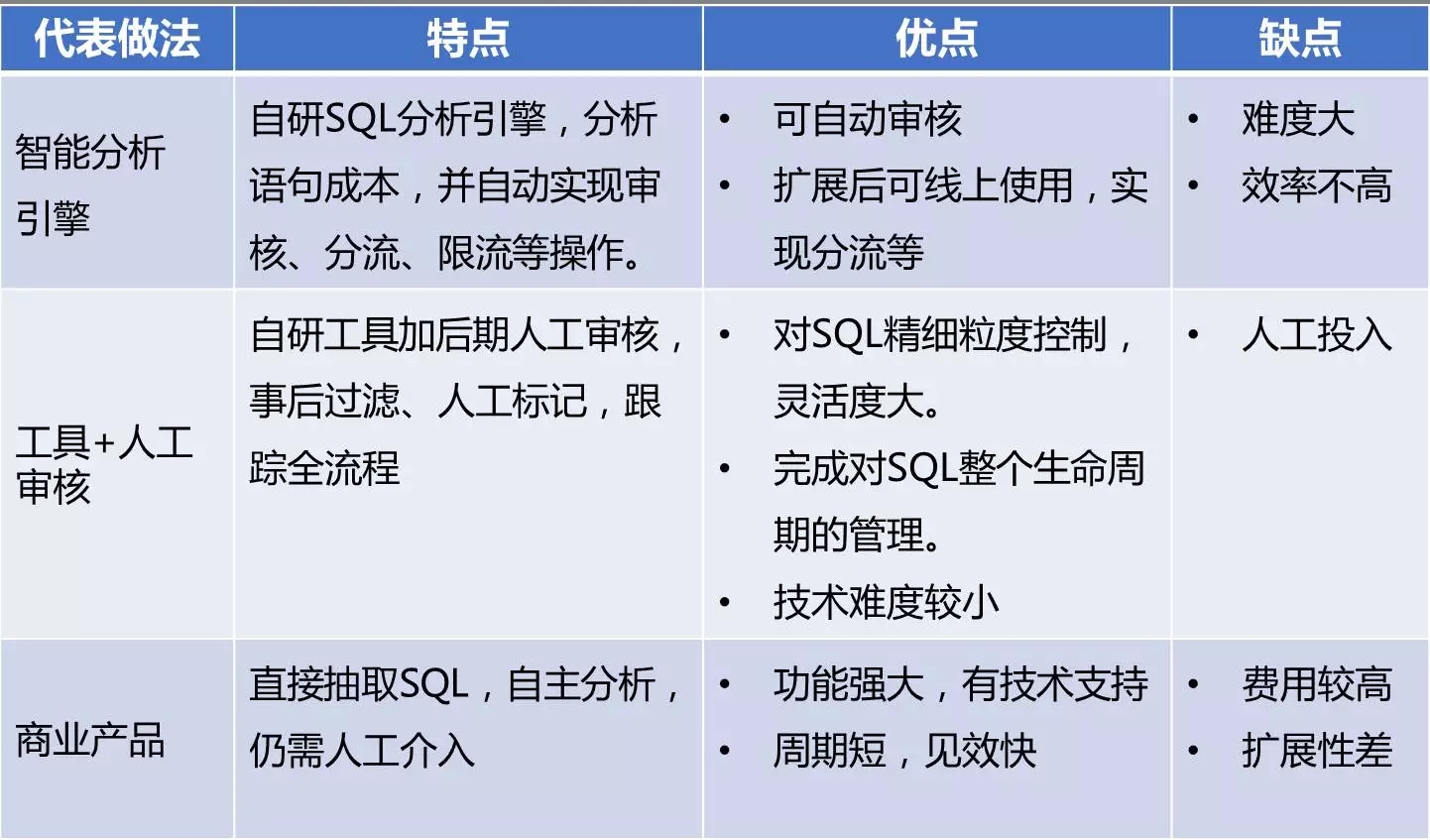
在项目之初,我考察了业内其它企业是如何数据库审核的,大致可分为三个思路:
第一类,是以BAT公司为代表的互联网类公司。它们通过自研的SQL引擎,可实现成本分析、自动审核、访问分流、限流等,可做到事前审核、自动审核。但技术难度较大,公司现有技术能力明显不足。
第二类,是通过自研工具收集DB运行情况,根据事前定义规则进行审核,结合人工操作来完成整个审核流程。这种方案只能做到事后审核,但技术难度较小,灵活度很大。其核心就是规则集的制定,可根据情况灵活扩展。
第三类,是一些商业产品,实现思路类似第二类,但是加上一些自主分析能力,功能更为强大,但仍需人工介入处理且需要不小资金投入。而且考察几款商业产品,没有能完全满足所需功能的。
综合上面几类做法,最终确定我们采用“工具+人工审核”的方式,自研自己的审核平台。
2、我们的选择——自研

在启动研发这一平台之初,我们就在团队内部达成了一些共识。
DBA需要扭转传统运维的思想,每个人都参与到平台开发过程中。
过去我们积累的一些内容(例如前期制定的规范)可以作为知识库沉淀下来,并标准化,这些为后期规则的制定做好了铺垫。
在平台推进中,从最简单的部分入手,开发好的就上线实施,观察效果;根据实施效果,不断修正后面的工作。
结合我们自身的特点,定制目标;对于有些较复杂的部分,可果断延后甚至放弃。
参考其它公司或商业产品的设计思想,大胆引入。
三、审核平台实践
下面来看看,审核平台的基本功能及实现原理及方法,这部分是本次分享的重点。
1、平台定位

在项目之初,我们就平台的定位做了描述:
平台的核心能力是快速发现数据库设计、SQL质量问题。
平台只做事后审核,自主优化部分放在二期实现。当然在项目设计阶段引入这个,也可以起到一部分事前审核的功能。
通过Web界面完成全部工作,主要使用者是DBA和有一定数据库基础的研发人员。
可针对某个用户审核,可审核包括数据结构、SQL文本、SQL执行特征、SQL执行计划等多个维度。
审核结果通过Web页面或导出文件的形式提供。
平台需支持公司主流的Oracle、MySQL,其它数据库放在二期实现。
尽量提供灵活定制的能力,便于日后扩展功能。
2、平台使用者
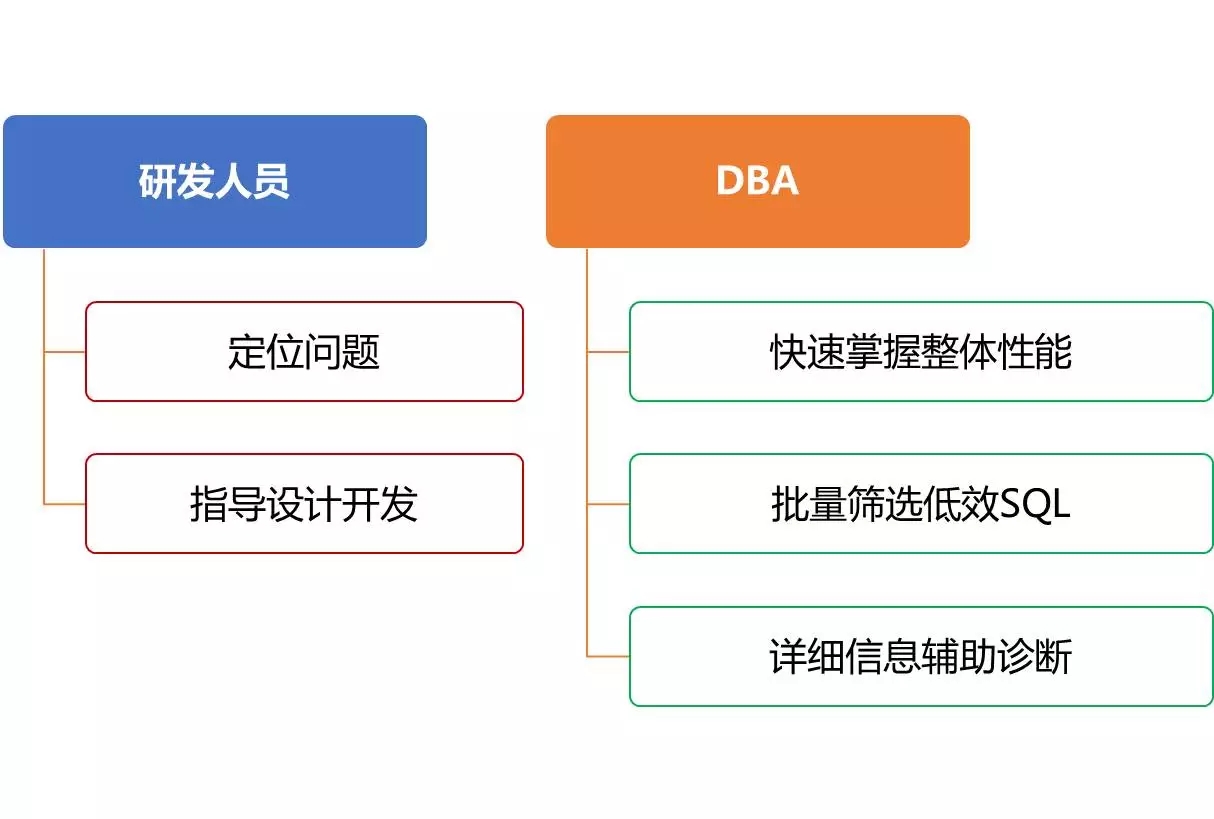 作为平台的两类主要使用方,研发人员和DBA都可以从平台中受益。
作为平台的两类主要使用方,研发人员和DBA都可以从平台中受益。
对于研发人员而言,只用这平台可方便定位问题,及时进行修改;此外通过对规则的掌握,也可以指导他们设计开发工作。
对于DBA而言,可快速掌握多个系统的整体情况,批量筛选出低效SQL,并可通过平台提供的信息快速诊断一般性问题。
3、实现原理
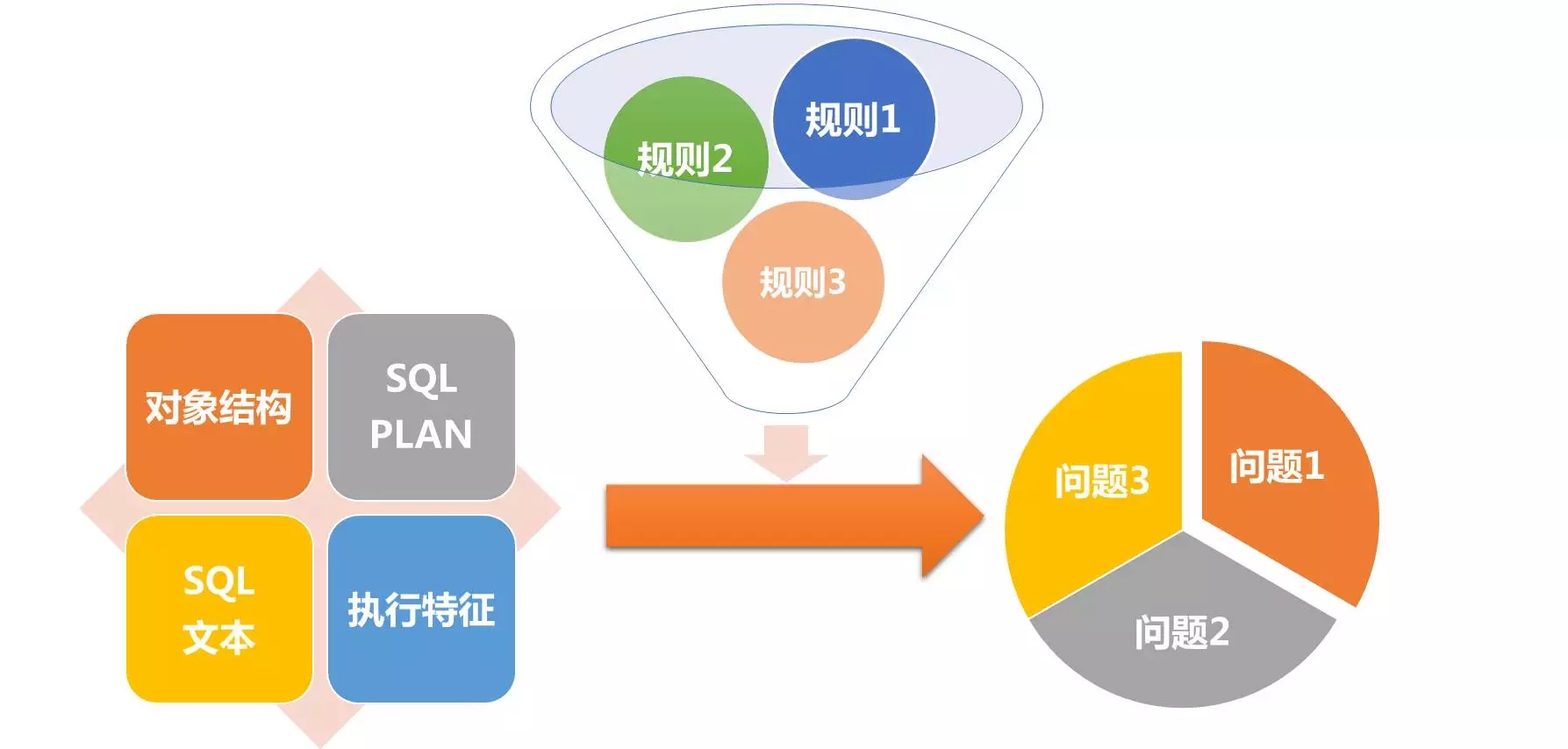
整个平台的基本实现原理很简单,就是将我们的审核对象(目前支持四种),通过规则集进行筛选。符合规则的审核对象,都是疑似有问题的。平台会将这些问题及关联信息提供出来,供人工甄别使用。由此可见,平台的功能强大与否,主要取决于规则集的丰富程度。平台也提供了部分扩展能力,方便扩展规则集。
4、平台设计
审核对象
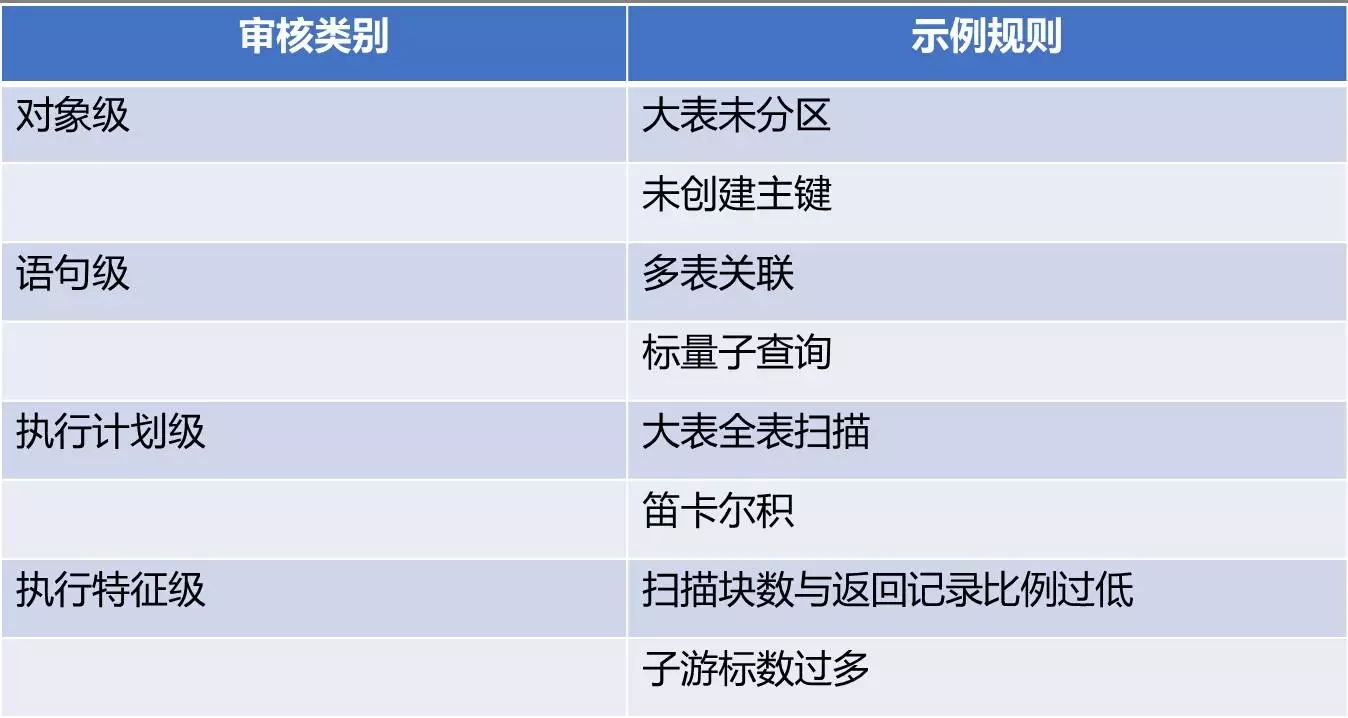
在开始介绍平台实现之前,再来熟悉下“审核对象”这个概念。目前我们支持的有四类对象,分别说明一下。
对象级。这里所说的对象就是指数据库对象,常见的表、分区、索引、视图、触发器等等。典型规则,例如大表未分区等。
语句级。这里所说的语句级,实际是指SQL语句文本本身。典型规则,例如多表关联。
执行计划级。这里是指数据库中SQL的执行计划。典型规则,例如大表全表扫描。
执行特征级。这里是指语句在数据库上的真实执行情况。典型规则,例如扫描块数与返回记录比例过低。
需要说明一下,这四类审核对象中,后三种必须在系统上线运行后才会抓取到,第一种可以在只有数据结构的情况下运行(个别规则还需要有数据)。
此外,上述规则中,除了第二类为通用规则外,其他都与具体数据库相关。即每种的数据库,都有自己不同的规则。
架构简图
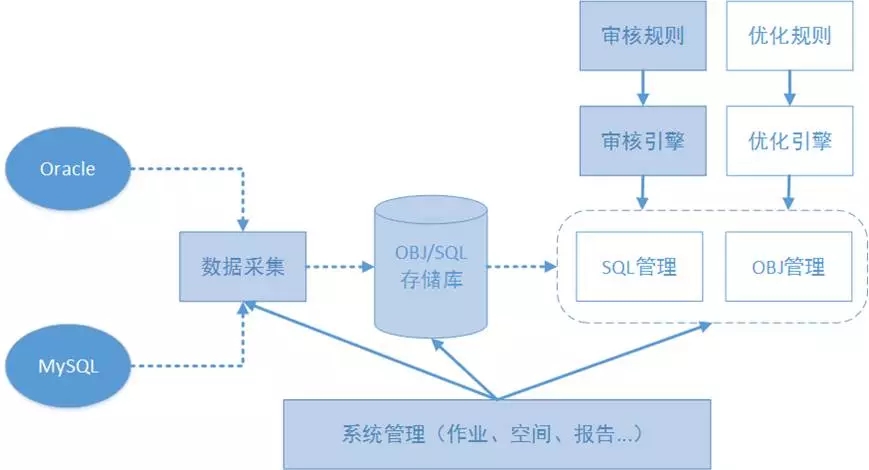
这里画出是系统架构框架简图,我简单说明一下。
图中的方框部分,为平台的主要模块。底色不同的模块,表示当前的进度状态不同。虚线代表数据流,实线代表控制流。其核心为这几个模块:
数据采集模块。它是负责从数据源抓取审核需要的基础数据。目前支持从Oracle、MySQL抓取。
OBJ/SQL存储库。这是系统的共同存储部分,采集的数据和处理过程中的中间数据、结果数据都保存在这里。其核心数据分为对象类和SQL类。物理是采用的MongoDB。
核心管理模块。图中右侧虚线部分包含的两个模块:SQL管理和OBJ管理就是这部分。它主要是完成对象的全生命周期管理。目前只做了简单的对象过滤功能,因此还是白色底色,核心的功能尚未完成。
审核规则和审核引擎模块。这部分是平台一期的核心组件。审核规则模块是完成规则的定义、配置工作。审核引擎模块是完成具体规则的审核执行部分。
优化规则和优化引擎模块。这部分是平台二期的核心组件。目前尚未开发,因此为白色底色。
系统管理模块。这部分是完成平台基础功能,例如任务调度、空间管理、审核报告生成、导出等功能。
流程图
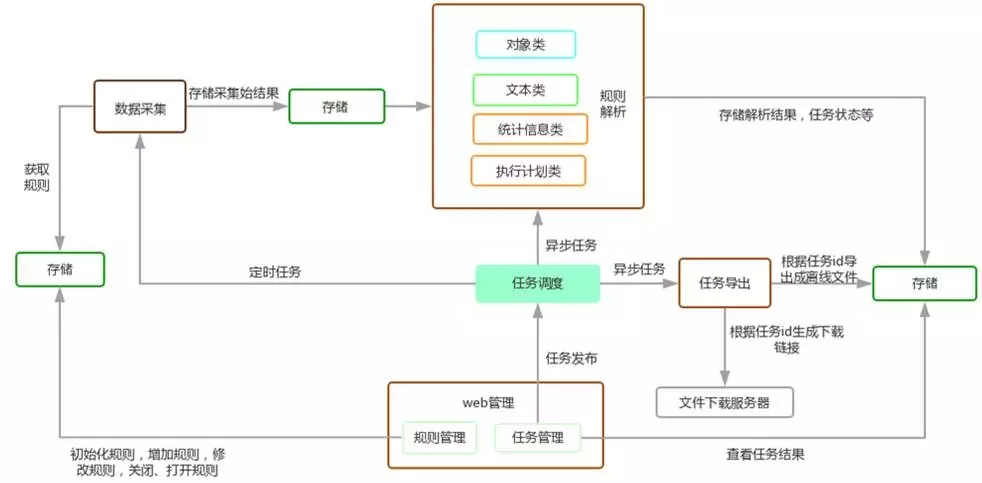
让我们从处理流程的角度,看看平台的整体处理过程。
“规则管理”部分,这部分主要完成以下一些功能。
初始化规则。平台本身内置了很多规则,在这一过程中到导入到配置库中。
新增规则。平台本身提供了一定的扩展能力,可以依据规范新增一条规则。
修改规则。可以根据自身情况开启或关闭规则。对于每条规则,还内置了一些参数,也可在此处修改。此外,针对违反规则的情况,还可以设置扣分方法(例如违反一次扣几分、最多可扣几分)等。
* 规则本身及相关参数、配置信息等都会存储在配置库中。
2.“任务管理”部分,这是后台管理的一个部分,主要完成与任务相关的工作。系统中的大多数交互都是通过作业异步完成的。其后台是通过celery+flower实现的。
3.“数据采集”部分,这部分是通过任务调度定时出发采集作业完成,也有少量部分是实时查询线上库完成的。采集的结果保存在数据库中,供后续分析部分调用。
4.“规则解析”部分,这部分是由用户通过界面触发,任务调度模块会启动一个后台异步任务完成解析工作。之所以设计为异步完成,主要是审核工作可能时间较长(特别是选择审核类别较多、审核对象很多、开启的审核规则较多)的情况。审核结果会保存在数据库中。
5.“任务查看、导出”部分,在用户发起审核任务后,可在此部分查看进度(处于审核中、还是审核完成)。当审核完成后,可选择审核任务,浏览审核结果或选择导出均可。如果是选择导出的话,会生成异步后台作业生成文件,放置在下载服务器上。
以上就是整个审核的大体流程。后续将看到各部分的详细信息。
模块划分
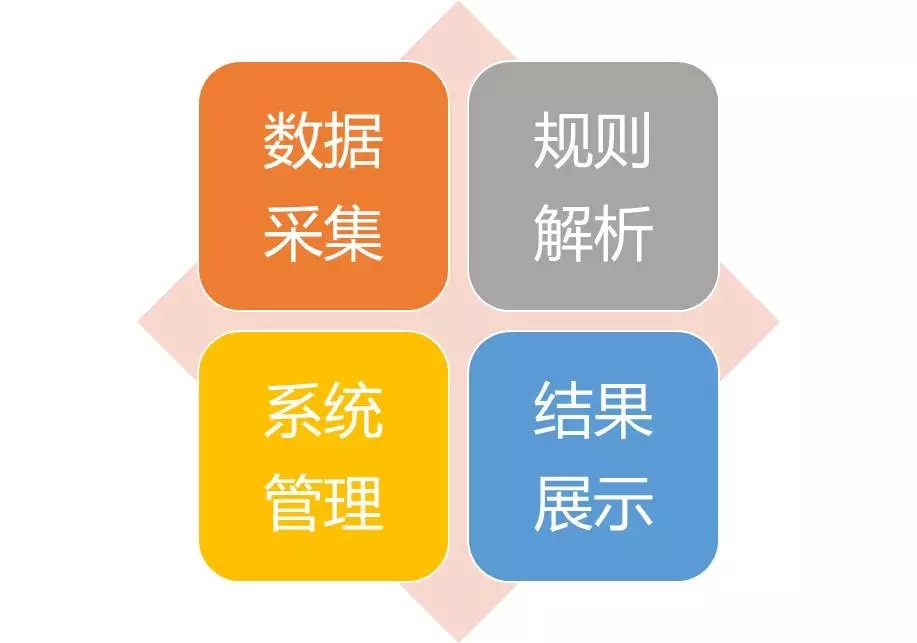
总结一下,平台主要是由上述四个模块组成:数据采集、规则解析、系统管理、结果展示。后面将针对不同模块的实现,进行详细说明。
5、数据采集
采集内容
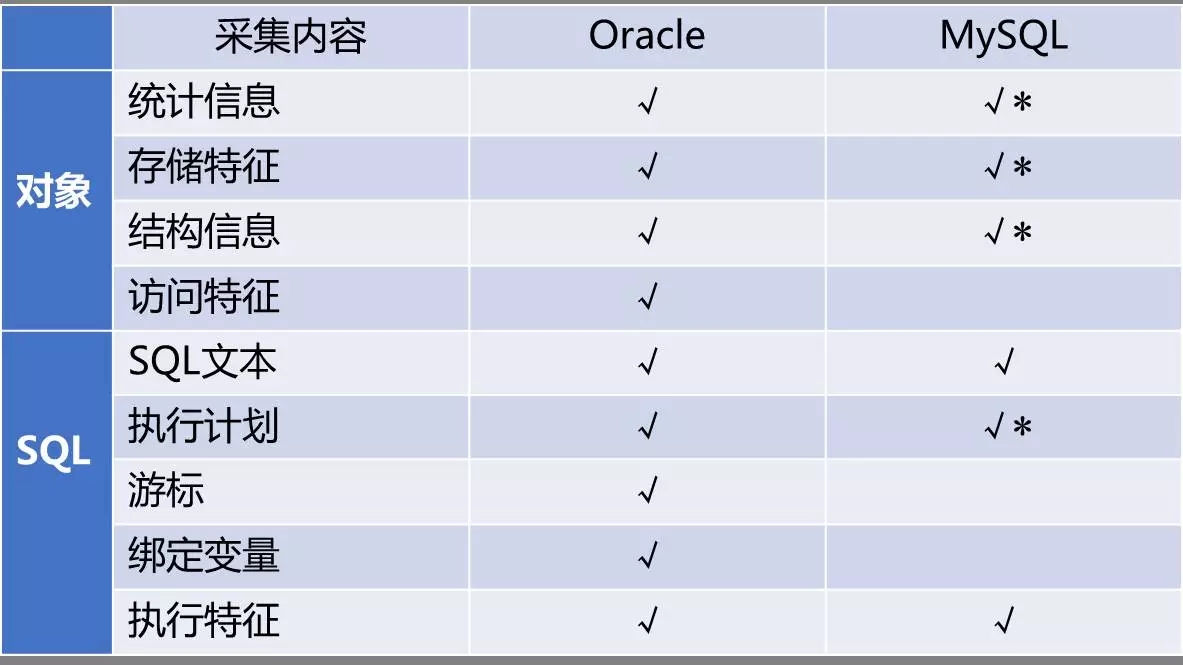
先来看看数据采集模块。从表格可见,两种类型数据库的采集内容不同。
Oracle提供了较为丰富的信息,需要的基本都可采集到;MySQL功能相对能采集到的信息较少。
表格中的“对号+星号”,表示非定时作业完成,而是后面实时回库抓取的。下面简单说下,各部分的采集内容。
对象级,采集了对象统计信息、存储特征、结构信息、访问特征。
SQL级,采集了SQL文本,执行计划、缓存游标、绑定变量、执行特征等。
这些信息都将作为后面审核的依据。
采集原理
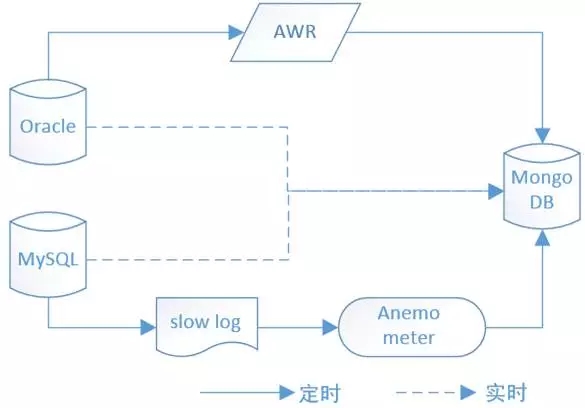
下面简单介绍下采集的与原理:
Oracle部分,是通过定时作业采集的AWR数据,然后转储到一套MongoDB中。这里跟有些类似产品不同,没有直接采集内存中的数据,而是取自离线的数据。其目的是尽量减少对线上运行的影响。Oracle提供的功能比较丰富,通过对AWR及数据字典的访问,基本就可以获得全部的数据。
MySQL部分,情况就要复杂一些,原因是其功能没有那么丰富。多类数据是通过不同源来获取。SQL文本类及执行特征类的,是通过pt工具分析慢查询日志定时入到Anemometer平台库,然后从此库传入MongoDB。其它类信息(包括数据字典类、执行计划类等)是在需要时通过实时回库查询的。为了防止影响主库,一般是通过路由到从库上执行获得的。
6、规则解析
概要说明
下面介绍整个系统最为核心的部分—规则解析模块,它所完成的功能是依据定义规则,审核采集的数据,筛选出违反规则的数据。对筛选出的数据进行计分,并记录下来供后续生成审核报告使用。同时还会记录附加信息,用于辅助进行一些判断工作。
这里有个核心的概念—“规则”。后面可以看到一个内置规则的定义,大家就会比较清楚了。从分类来看,可大致分为以下几种。
从数据库类型角度来区分,规则可分为Oracle、MySQL。不是所有规则都区分数据库,文本类的规则就不区分。
从复杂程度来区分,规则可分为简单规则和复杂规则。这里所说的简单和复杂,实际是指规则审核的实现部分。简单规则是可以描述为MongoDB或关系数据库的一组查询语句;而复杂规则是需要在外部通过程序体实现的。
从审核对象角度来区分,规则可分为对象类、文本类、执行计划类和执行特征类。下面会针对每类审核对象,分别做说明。
规则定义
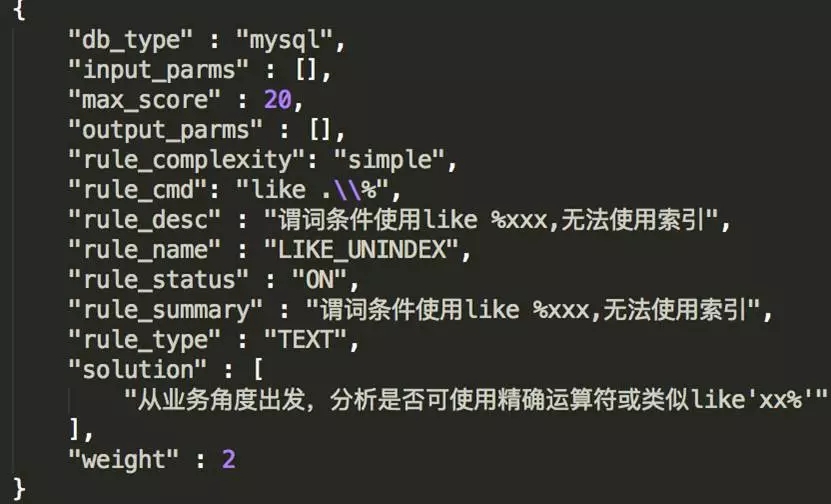
这是一个规则体的声明对象,我说明一下各字段含义,大家也可对规则有个清晰的认识。
db_type:规则的数据库类别,支持Oracle、MySQL。
input_parms:输入参数。规则是可以定义多个输出参数,这是一个参数列表,每个参数自身又是一个字典类,描述参数各种信息。
output_parms:输出参数。类似上面的输入参数,也是一个字典对象列表。描述了根据规则返回信息结构。
rule_complexity:规则是复杂规则还是简单规则。如果是简单规则,则直接取rule_cmd内容作为规则审核的实现。如果是复杂规则,则是从外部定义的rule_name命令脚本中获得规则实现。
rule_cmd:规则的实现部分。规则可能是mongodb的查询语句、可能是一个正则表达式,具体取决于rule_type。
rule_desc:规则描述,仅供显示。
rule_name:规则名称。是规则的唯一标识,全局唯一。
rule_status:规则状态,ON或是OFF。对于关闭的规则,在审核时会忽略它。
rule_summary:一个待废弃的字段,意义同rule_desc。
rule_text:规则类型,分为对象、文本、执行计划、执行特征四类。图中的示例标识一个文本类型的规则,rule_cmd是正则表达式。
solution:触发此规则的优化建议。
weight:权重,即单次违反规则的扣分制。
max_score:扣分上限,为了避免违反一个规则,产生过大影响,设置此参数。
规则定义(对象级)

先来看第一类规则—对象规则。这是针对数据库对象设置的一组规则。上面表格,显示了一些示例。常见的对象,诸如表、分区、索引、字段、函数、存储过程、触发器、约束、序列等都是审核的对象。以表为例,内置了很多规则。
例如:第一个的“大表过多”。表示一个数据库中的大表个数超过规则定义阀值。这里的大表又是通过规则输入参数来确定,参数包括表记录数、表物理尺寸。整体描述这个规则就是“数据库中超过指定尺寸或指定记录数的表的个数超过规定阀值,则触发审核规则”。其它对象的规则也类似。
规则实现(对象级)

对象规则的实现部分,比较简单。除个别规则外,基本都是对数据字典信息进行查询,然后依据规则定义进行判断。上面示例就是对索引的一个规则实现中,查询数据字典信息。
规则定义(执行计划级)

第二类规则是执行计划类的规则,它也划分为若干类别。例如访问路径类、表间关联类、类型转换类、绑定变量类等。
以最为常见的的访问路径类为例,进行说明下。如最为常见的一个规则“大表扫描”。它表示的是SQL语句的执行中,执行了对大表的访问,并且访问的路径是采用全表扫描的方式。这个规则的输入参数,包含了对大表的定义(物理大小或记录数);输出部分则包括了表名、表大小及附加信息(包括整个执行计划、指定大表的统计信息等内容)。
这类规则针对的数据源,是从线上数据库中抓取的。Oracle部分是直接从AWR中按时间段提取的,MySQL部分是使用explain命令返查数据库得到的。
信息存储格式

在这里特别说明一下,在保存执行计划的时候,使用了MongoDB这种文档性数据库。目的就是利用其schemaless特性,方便兼容不同数据库、不同版本执行计划的差异。都可以保存在一个集合中,后续的规则审核也是利用的mongo中的查询语句实现的。这也是最初引入mongo的初衷,后续也将其它类信息放入库中。现在整个审核平台,除了pt工具接入的部分使用MySQL外,其余都在MongoDB中。此外,MySQL库可以直接输出json格式的执行计划,很方便就入库了;Oracle部分也组成json格式入库。
规则实现(执行计划)

左边就是一个Oracle的执行计划保存在MongoDB中的样子。其实就是将sqlplan字典数据插入到mongo中。右侧就是一个规则实现的样例,就是基于mongo的查询语句。后面我们会可看到一个详细的示例。
7、平台实现
规则实现
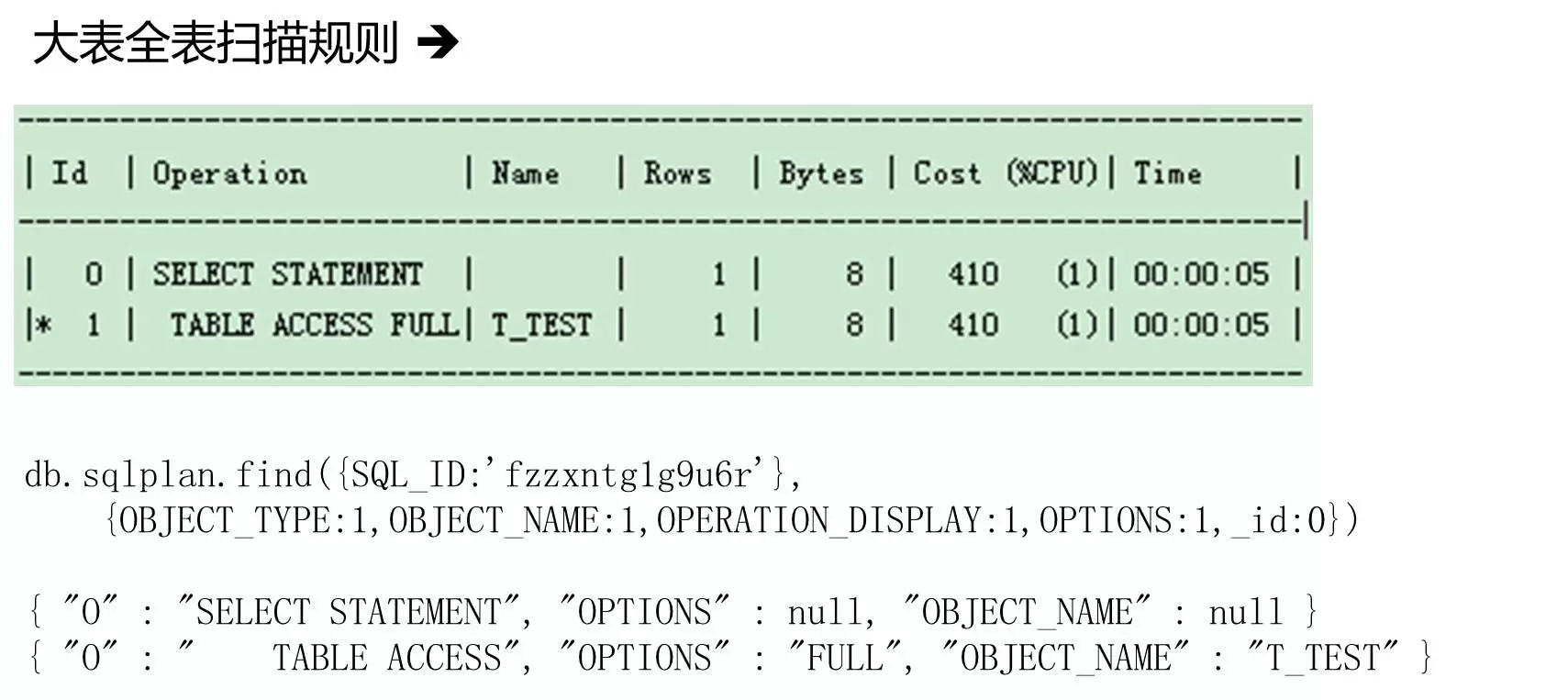
这里以“大表全表扫描”规则为例,进行说明。上面是在Oracle中的数据字典保存的执行计划,下面是存在Mongo中的。可见,就是完全复制下来的。
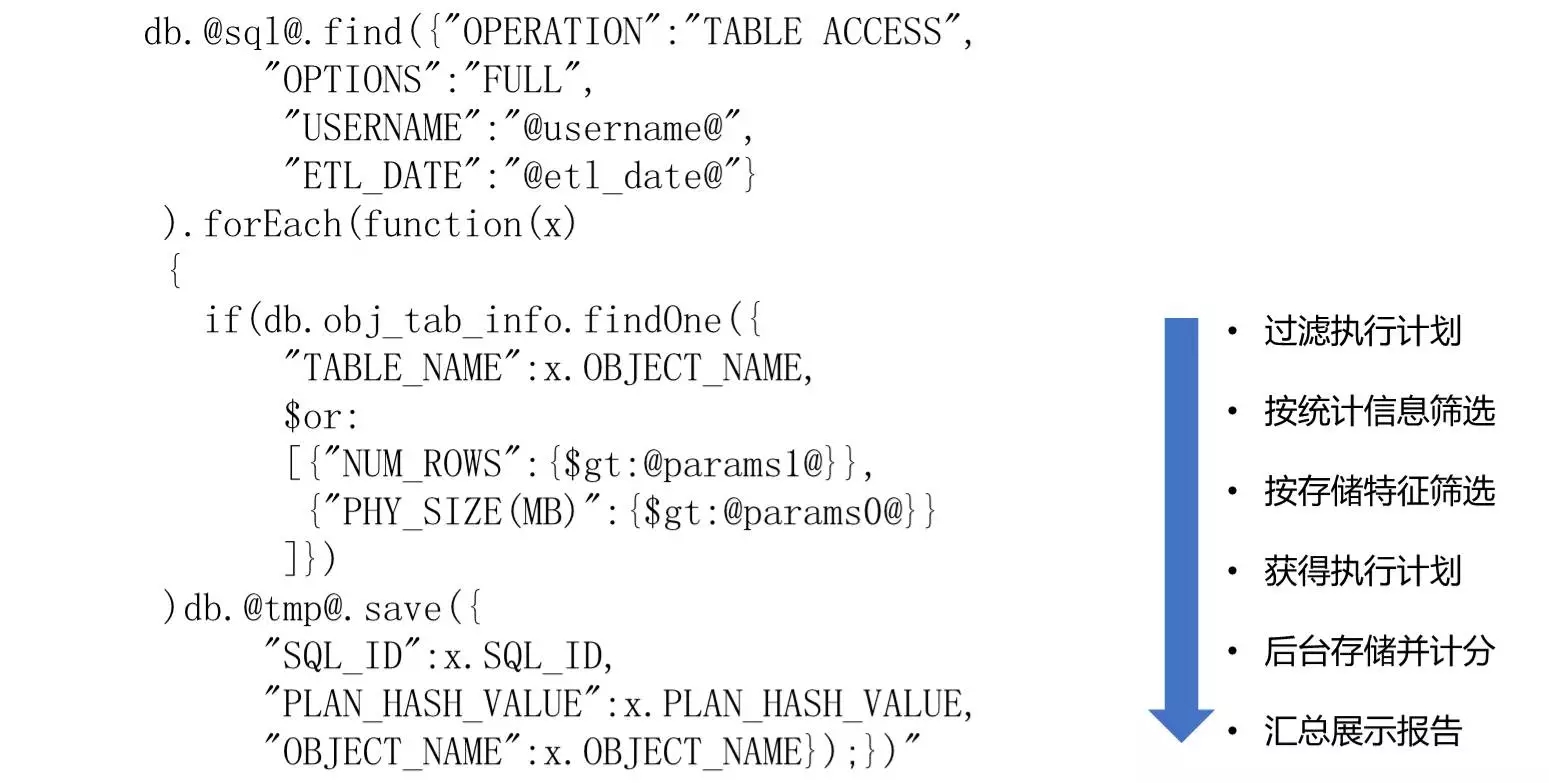
基于这样的结构,如何实现规则过滤呢?其实就是通过mongo中的find语句实现的。下面具体解读下这个语句的执行步骤。
最上面的find()部分,是用来过滤执行计划的。将满足指定用户、时间范围、访问路径(“TABLE ACCESS”+”FULL”)的执行计划筛选出来。
筛选出的部分,会关联对象数据,将符合“大表”条件的部分筛选出来。大表规则是记录数大于指定参数或者物理大小大于指定参数的。
取得的结果,将保存期sql_id、plan_hash_value、object_name信息返回。这三个信息将分别用于后续提取SQL语句信息、执行计划信息、关联对象信息使用。
取得的全部结果集,将按照先前设定的扣分原则,统计扣分。
提取到的三部分信息+扣分信息,将作为结果返回,并在前端展示。
规则实现(执行计划)
这部分是MySQL中实现层次结果存储的一个实例。

第一个图展示的是原始的执行计划。
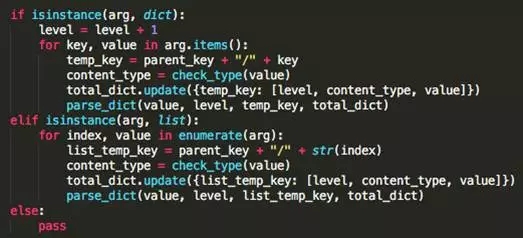
第二个图是代码实现的摘要。

第三个图是真正保存在库中的样子。核心部分就是对item_level的生成。
规则定义(文本级)
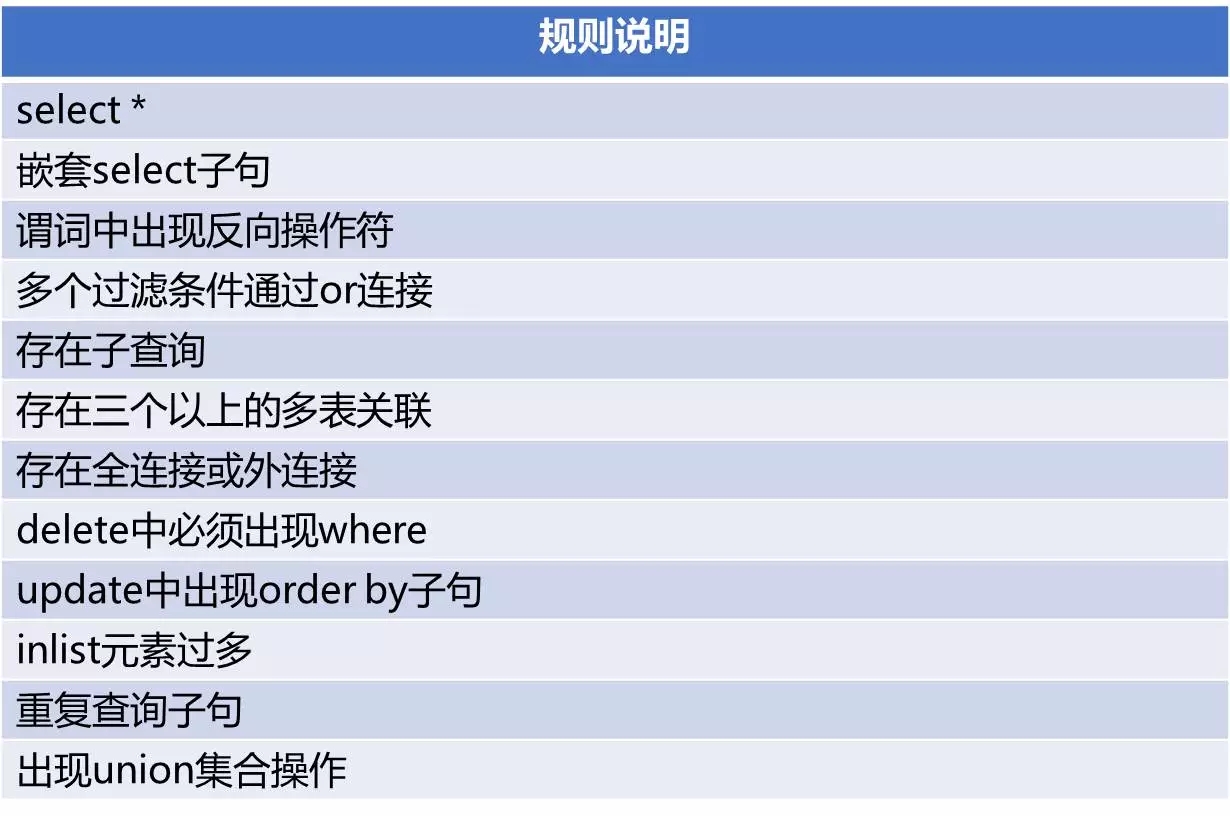
第三类规则是文本类的规则,这是一类与数据库种类无关、描述SQL语句文本特征的规则。在实现上是采用文本正则匹配或程序方式进行处理的。它的主要目的是规范开发人员的SQL写法,避免复杂的、性能较差的、不规范的SQL写法。
规则实现(文本级)

这部分描述的是文本规则的实现方式。第一个示例bad_join,是一种简单规则,通过正则文本匹配实现。第二个示例sub_query,是通过程序判断括号嵌套来完成对子查询(或多级子查询)的判断。
规则定义(执行特征级)

最后一类规则是执行特征类的。这部分是与数据库紧密关联的,将符合一定执行特征的语句筛选出来。这些语句不一定是低效的,可能只是未来考虑优化的重点,或者说优化效益最高的一些语句。这里面主要都是一些对资源的消耗情况等。
8、系统管理
规则管理

后面通过一些界面展示,介绍下平台的功能。
第一部分系统管理模块中规则管理的部分。在这部分,可完成新增自有规则。其核心是规则实现部分,通过SQL语句、Mongo查询语句、自定义Python文件的形式定义规则实现体。自定义规则的依据是现有抓取的数据源,定义者需要熟悉现有数据结构及含义。目前尚不支持自定义抓取数据源。
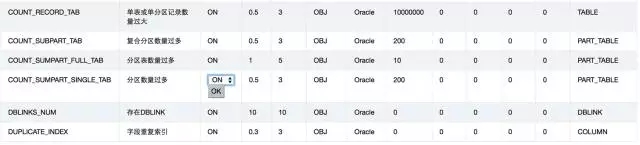
对定义好的规则,可在此处完成规则修改。主要是对规则状态、阀值、扣分项等进行配置。
任务管理

在配置好规则后,可在此处完成任务发布的工作。
上面是规则任务发布的界面,在选择数据源(ip、port、schema)后,选择审核类型及审核日期。目前审核数据源的定时策略还是以天为单位,因此日期不能选择当天。
当任务发布后,可在任务结果查看界面观察执行情况。根据审核类型、数据源对象多少、语句多少等,审核的时长不定,一般是在5分钟以内。当审核作业状态为“成功”时,代表审核作业完成,可以查看或导出审核结果了。
9、结果展示
对象审核结果概览
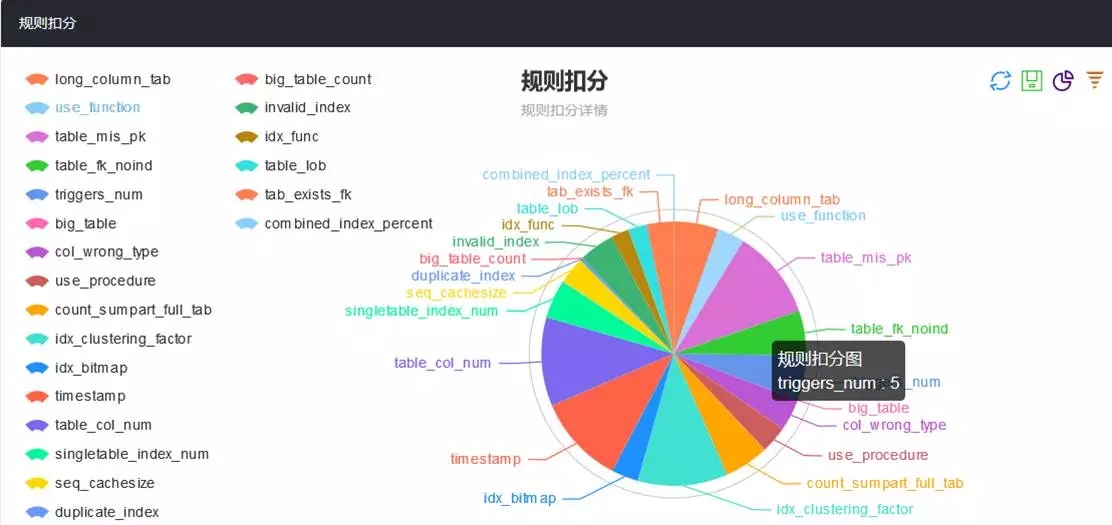
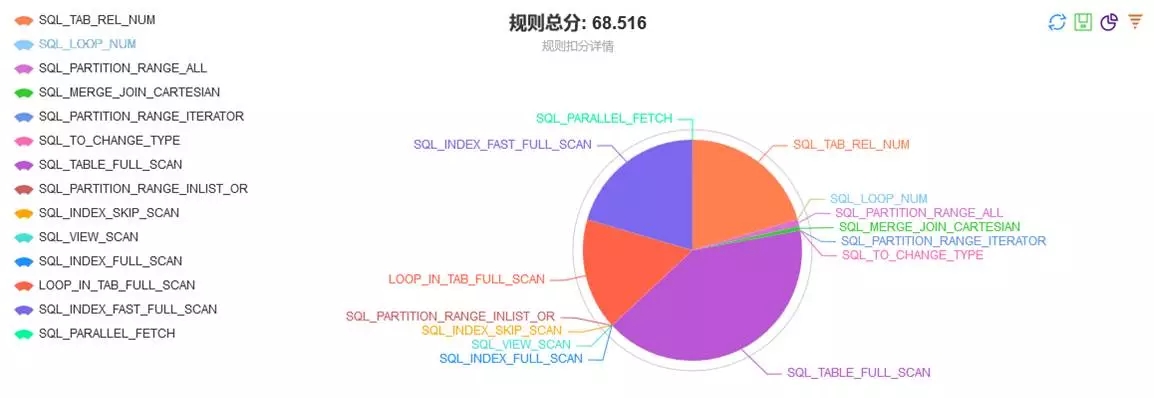
上图是一个对象审核报告的示例。在报告的开头部分,是一个概览页面。它集中展示审核报告中各类规则及扣分情况;并通过一个饼图展示其占比情况。这便于我们集中精力先处理核心问题。
在最上面,还可以观察到有一个规则总分的显示。这是我们将规则扣分按照百分制,折算后得到的一个分数。分值越高,代表违反的情况越少,审核对象的质量越高。引入“规则总分”这一项,在设计之初是有些争议的,担心有了这个指标会比较打击开发人员的积极性,不利于平台的推广使用。这里有几点,我说明一下。
引入规则总分,是为了数据化数据库设计、开发、运行质量。以往在很多优化中,很难去量化优化前后的效果。这里提供了一种手段去做前后对比。可能这个方式不是太科学的,但是毕竟提供一种可量化的手段。
各业务系统差异较大,没有必要做横向对比。A系统60分,B系统50分,不代表A的质量就比B的质量高。
单一系统可多做纵向对比,即对比改造优化前后的规则总分。可在一定程度上反映出系统质量的变化。
规则总分,跟规则配置关系很大。如关闭规则或将违反规则的阀值调低,都会提高分数。这要根据系统自身情况来确定。同一规则,对不同系统使用,其阀值是可以不同的。举例而言,数据仓库类的应用,大表全部扫描就是一个比较正常的行为,可考虑关闭此规则或将单次违反阀值、总扣分上限降低。
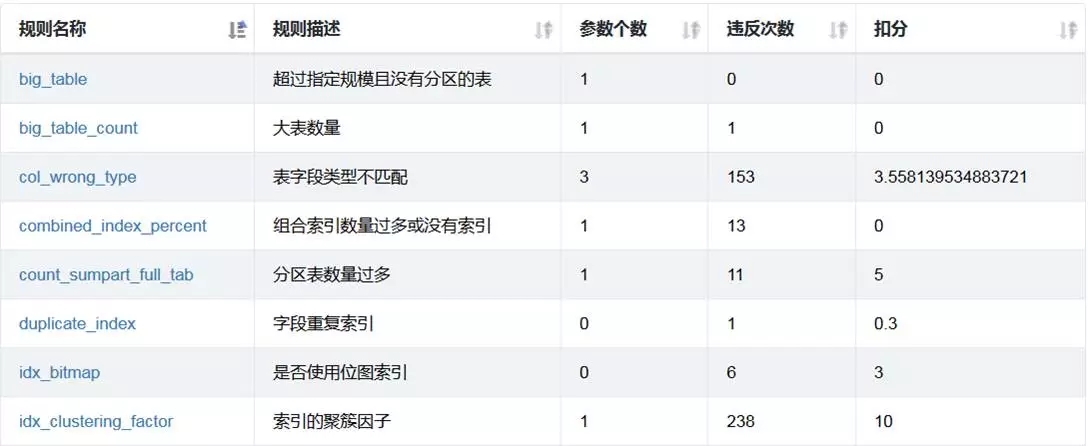
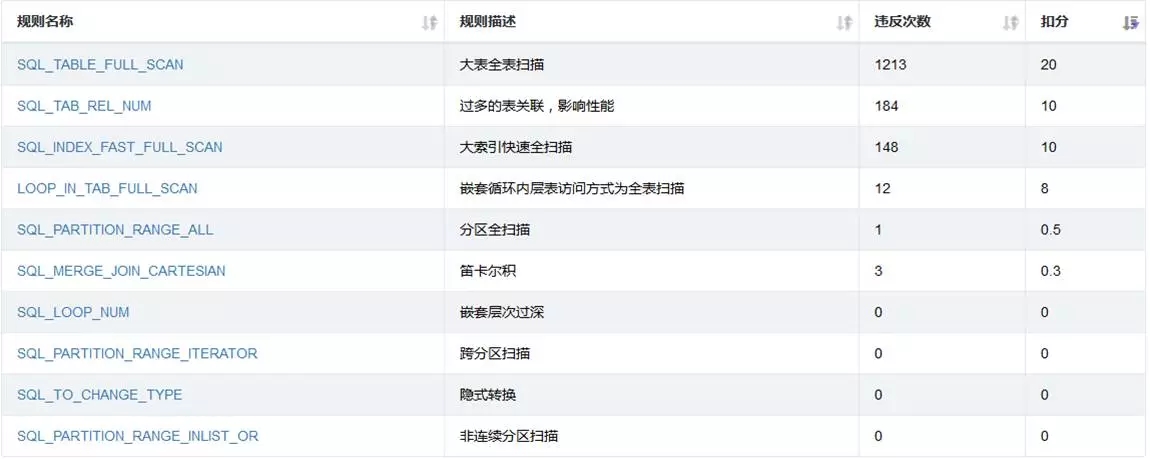
对象审核结果明细
这部分是对象审核的明细部分,对应每个规则其详细情况,可在左侧链接中进一步查看对象信息。篇幅所限,不做展示了。
执行计划审核结果概览
这部分执行计划的概览展示,跟对象的情况类似。也是每种规则的扣分情况。
执行计划审核结果明细
这部分是执行计划的明细部分。
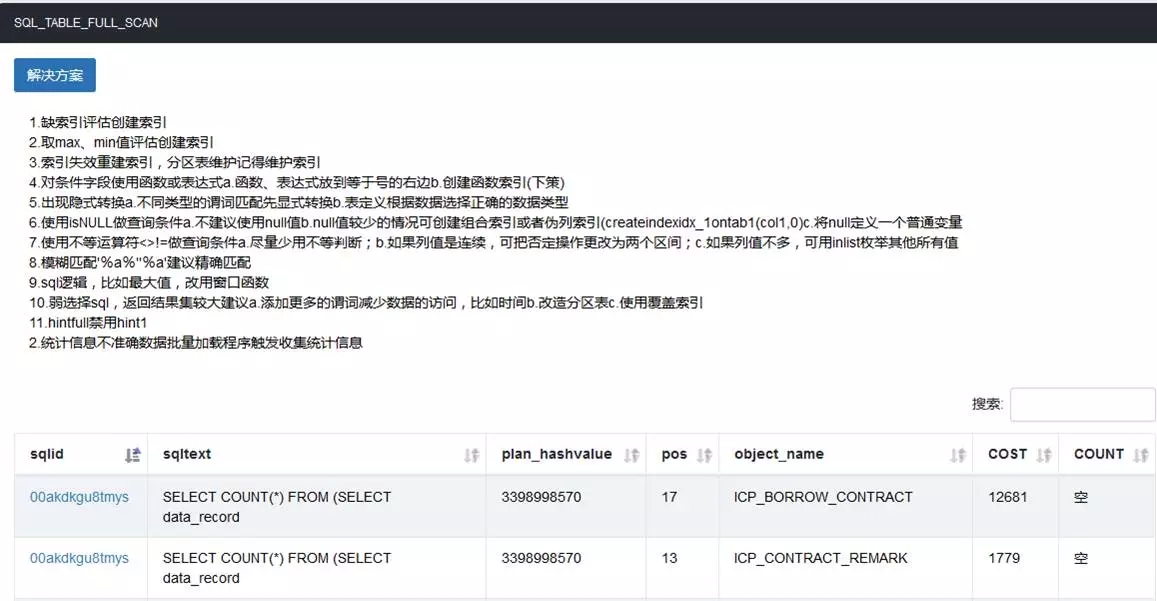
展开之后,可以看到违反每种规则的明细。上图就是违反全表扫描的规则的明细部分。
在上面是一些通用的解决方案说明。这里将可能触发此类规则的情况及解决方案进行了说明。相当于一个小知识库,便于开发人员优化。后面在平台二期,会做更为精准的优化引擎部分,这部分还会展开。
下面是每条违反的语句情况,我们可以看到语句文本、执行计划、关联信息(例如此规则的大表名称)等。还可以进一步点开语句,展开信息。


这部分是针对每条SQL的信息,包括语句文本、执行计划、执行特征、关联对象统计信息等。DBA可从这些信息就可以做一些初步的优化判断工作。
此外,平台也提供了导出功能。可导出为excel文件,供用户下载查看。这里就展示了。
10、我们遇到的坑
在实际开发过程中,碰到了很多问题。我们这里简单介绍两个,例如:
MySQL在解析json格式执行计划中暴露出的问题…
【会话进入sleep状态,假死】
解决方法:执行会话之前设置wait_timtout=3,这个时间根据实际情况进行调整。
【数据量过大,长时间没有结果】
会话处于query状态,但是数据量很大或因为数据库对format=json支持不是很好,长时间解析不出来,会影响其他会话。
解决方法:使用pt-kill工具杀掉会话。为了防止误杀,可打个标识“eXplAin format=json”,然后使用pt-kill识别eXplAin关键字。
11、推进流程

此平台在宜信公司已运行了半年有余,为很多系统提供了审核报告,大大加快了数据库结构、SQL优化的速度,减轻了DBA的日常工作压力。在工作实施过程中,我们也摸索了一套推行方法。后续平台开源后,如有朋友使用,也可参考实施。
收集信息阶段
海量收集公司的数据库系统的运行情况,掌握第一手资料。快速了解各业务系统的质量,做好试点选择工作。
人工分析阶段
重点系统,人工介入分析。根据规则审核中暴露出的核心问题,“以点带面”,有针对性的给出分析及优化报告。
交流培训阶段
主动上门,跟开发团队沟通交流报告情况。借分析报告的机会,可对开发团队进行必要的培训工作,结合他们身边的案例,更具有说服作用。
反馈改进阶段
落实交流的成果,督促其改进。通过审核平台定期反馈改进质量。有一定基础的团队,可开发平台,供开发人员自己使用。使SQL质量问题,不再仅仅是DBA的问题,而和项目中的每个人都有关系。
Q1:您刚才说的把规则,字段类型不匹配,得到一个规则以后反馈过来,怎么就知道它必须是那个类型呢?
A1:我们首先会从数据表里面分析你这个字段里面想保存什么数据,比如说你这里面存的都是0到9,我就会分析这里面是不是应该保存一个数字,你拿文本存的,我就考虑为什么,我在排除了不是邮编,不是手机号,不是银行帐号各种排除之后,我觉得还不符合,那我就要考虑你定义它的初衷是什么。我认为你这个类型存的,但你实际上按另外一个类型存的,我就要考虑为什么这样做的,我可能就会扣一个分。
所谓类型不匹配是由于我们之前的功能引出来的,因为我们是金融公司,有很多数据是有敏感信息的,所以我们开始做了一个敏感信息的识别,我们会自动看你这个字段是不是敏感字段,进而我们发现可以拿一些数据特征的,演变过来就变成这个规则,就是所谓字段类型不匹配,当然这个可能会有一定的误判,有人认为文本类型,比如说数字类型效率差不多,我认为合理也OK,只要你给自己一个理由。
我有时候会把研发人员叫过来说你,这么设计可以,但你要给我一个理由。我不希望看到除了第一个字段以外,剩下所有字段都是一个长度的,这个就不太合理。我们希望这个维度可以反映出来一些问题。
Q2:意思就是通过一定的算法?
A2:没有什么算法,表多大,10兆以下的,我们会根据不同大小拆成片,比如说这个表是多大表我们就多拆几片,每一片里面会根据阀值来做,我们会得到一个汇总的结果集,我们会评估你的这些数据是什么样的,在排除那些特例情况之后,我认为它是不是违反规则,没有什么算法,其实就是一个政策匹配,我们目前线上基本上每一片采一千个数据。
Q3:我刚才听到老师的演讲里面,就是说让一些技术人员跟一些业务部门或者别部门进行沟通和交流,我自己学数据库的时候,我前后总共有4个老师,我对4个老师讲的数据库不是特别感兴趣,实际工作当中,我发现在谈公司决策的时候没有数据参考的,甚至国内或者国际咨询公司也缺失了很多数据,我从个人和企业诉求来说,有一部分数据是理性的,还有一部分数据在网络公司很分散的,这样的局面下,它的用户量很大,怎么把数据进行统一的汇总起来?或者通过手机端让客户得到想要的数据,这个跟宜信之间也有直接关联,发公司有月头月底,这个之间也是产生关联的,也就是说我们现在在做决策的时候,有一部分数据是没有的,没有数据的情况下还要做决策,这样的数据架构怎么来做?
刚才听就了这么一个重点,就是我们现在做决策的时候有一些数据是没有的,这个情况下在数据库里面应该怎么设计?或者跟他做一个运营。
A3:坦白说,我没太听懂你的问题,我理解你的意思是说如果公司缺乏一些数据支撑的情况下,怎么样做业务的决策是吗?
(接上问)
Q4:中国的企业很多决策是老板拍脑袋。
A4:还有一个问题就是技术人员怎么和业务人员沟通。
我们原来公司DBA确实大家都在幕后做工作,跟前台业务开发联系也不多,出了问题大家一起看,2016年初我们小伙伴们提了一些建议,我们在企业里面要发挥你的价值,作为传统运维来说,你的价值是你的数据库是可外的,除此之外要和研发人员有更好的一些互动。我现在要求这些人员要跟项目在一起,要跟它的产品聊,跟研发人员聊,这样才能更好的理解这些项目,理解这些业务,进而才有可能帮助他们做一些辅助设计。
最简单的,这个存什么样的数据,这个数据怎么使用的,保存有什么样的特征,我们目标用户是什么样的,这些东西你是需要了解的,只有这样前提下我们才有可能把工作做到前面去,我们做一些数据库的架构设计、结构设计,这样的语句合理还是不合理,这个时候才有可能做这个事。这个就要求项目同事,我说你们要主动推出去,而不是坐在后面,说这个出问题了我看一眼,我们看过这种事情,优化了一个月,最后我说了两句之后个东可以砍掉的,他的目的是解决这个问题,你要充分了理解它的诉求之后,你帮助他解决问题,这个问题可能是数据库的结构调整,可能是一个优化,也有可能其他方面解决问题,比如说这个功能可以更好实现。有的业务我就告诉他,这个东西放在数据库里运行不合适的,我可以你更好的方式实现它,成本更低,效率更好。
至于你说的第一个问题,如果说一个公司没有数据支撑的话,怎么样做业务决策,这个我也不知道。我只能说比如说我们公司现在的运营数据会通过自有的平台,这个平台之前在社区做过一些分享,把这个数据实时的抽过来,基于我们规则做一些分析。通过它做一些运营知识,当然宜信这方面做的并不是太突出,只是刚刚起步做一些这方面的尝试。
更多的可能像您说的会有一些认为决策的过程,当然我希望后面通过像我,包括我们同事,包括我们所有的不一定数据库团队,而是数据团队帮助公司更好做整体业务模型,数据类的一些架构,帮助弥补看我们公司哪一些数据领域没有这些数据支撑的,把它的短板需要补充,当然这个需要从更高层面看一些问题。
Q5:请问韩老师从研究、规划到落地,用了多长时间,几个人天,难在什么地方。有没有结合SQL语句对系统开销的贡献选择top,还是一视同仁?
A5:程序开发是由一名专职开发+两名DBA,在日常工作之外,用了大概半年左右完成的。难点,主要是个别规则实现,整体还好。在执行特征审核中,会考虑对系统开销的影响。
PPT下载链接:http://pan.baidu.com/s/1bQauxK









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721