
作者介绍
吴昌,网易北京研发中心资深工程师,负责网易北京电商系统大数据基础平台的运维和开发,对HDFS、Yarn、Kafka等大数据生态系统组件有深入研究。
个人博客:http://blog.csdn.net/zhanyuanlin?ref=toolbar。
Kakfa MirrorMaker是Kafka 官方提供的跨数据中心的流数据同步方案,其实现原理是通过从Source Cluster消费消息,然后将消息生产到Target Cluster,即普通的消息生产和消费。用户只要通过简单的consumer配置和producer配置,启动Mirror,就可以实现准实时的数据同步。
Kafka Mirror的基本特性有:
在Target Cluster没有对应Topic时,Kafka MirrorMaker会自动为我们在Target Cluster上创建一个一模一样(Topic Name、分区数量、副本数量)的topic。如果Target Cluster存在相同的Topic则不进行创建,并且MirrorMaker运行Source Cluster和Target Cluster的Topic的分区数量和副本数量不同。
同我们使用Kafka API创建KafkaConsumer一样,Kafka MirrorMaker允许我们指定多个Topic。比如TopicA|TopicB|TopicC,在这里,|其实是正则匹配符,MirrorMaker也兼容使用逗号进行分隔。
多线程支持。MirrorMaker会在每一个线程上创建一个Consumer对象,如果性能允许,建议多创建一些线程。
多进程任意横向扩展,前提是这些进程的consumerGroup相同。无论是多进程还是多线程,都是由Kafka ConsumerGroup的设计带来的任意横向扩展性,具体的分区分派,即具体的TopicPartition会分派给Group中的哪个Topic负责,是Kafka自动完成的,Consumer无需关心。
我们使用Kafka MirrorMaker完成远程的AWS(Source Cluster)上的Kafka信息同步到公司的计算集群(Target Cluster)。由于我们的大数据集群只有一个统一的出口IP,因此,Kafka MirrorMaker部署在本地(Target Cluster),它负责从远程的Source Cluster上的AWS Kafka 上拉取数据,然后生产到本地的Kafka。
Kafka MirrorMaker的官方文档一直没有更新,因此新版Kafka为MirrorMaker增加的一些参数、特性等在文档上往往找不到,需要看Kafka MirrorMaker的源码。Kafka MirrorMaker的主类位于kafka.tools.MirrorMaker,尤其是一些参数的解析逻辑和主要的执行流程,会比较有助于我们理解和运维Kafka MirrorMaker。
从Kafka 0.9版本开始引入了new consumer API。相比于普通的old consumer API,new Conumser API有以下主要改变:
统一了旧版本的High-Level和Low-Level Consumer API;-
new consumer API消除了对ZooKeeper的依赖,修改了ConsumerGroup的管理等等协议
new Consumer API完全使用Java实现,不再依赖Scala环境
更好了安全认证只在new consumer中实现,在old consumer中没有。
Kakfa MirrorMaker同时提供了对新旧版本的Consumer API的支持。
默认是旧版API,当添加–new.consumer,MirrorMaker将使用新的Consumer进行消息消费:

这是我启动Kakfa MirrorMaker 的命令:
mirror-consumer.properties配置文件如下:
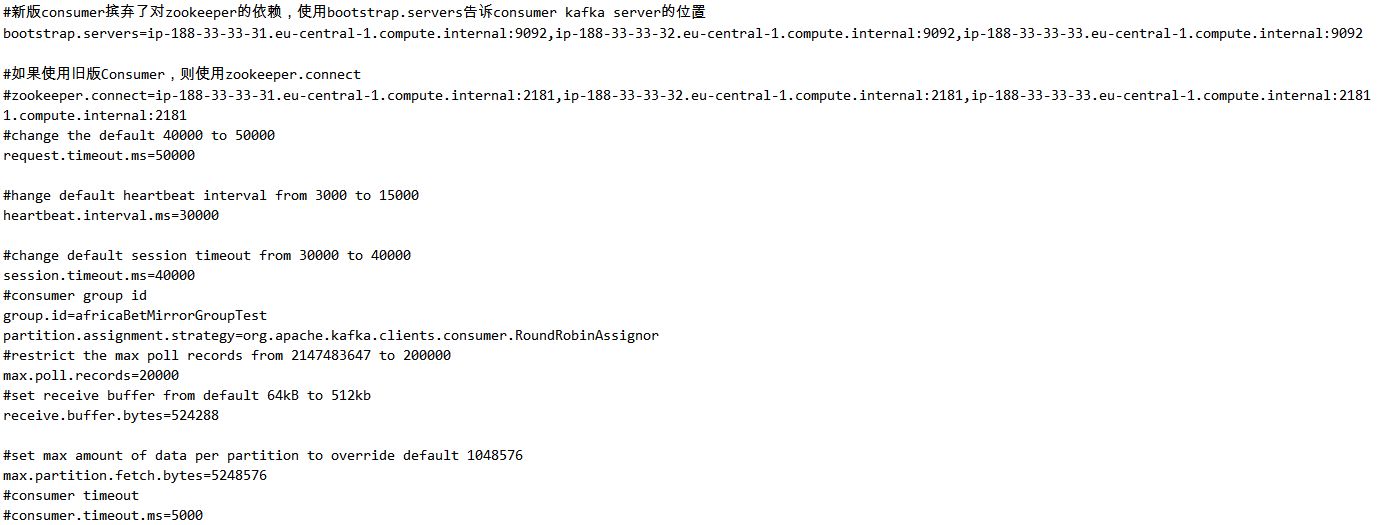
mirror-producer.properties的配置文件如下:
同时,我使用kafka-consumer-groups.sh循环监控消费延迟:
当我们使用new KafkaConsumer进行消息消费,要想通过kafka-consumer-groups.sh获取整个group的offset、lag延迟信息,也必须加上–new-consumer,告知kafka-consumer-groups.sh,这个group的消费者使用的是new kafka consumer,即group中所有consumer的信息保存在了Kafka上一个名字叫做__consumer_offsets的特殊topic上,而不是保存在ZooKeeper上。我在使用kafka-consumer-groups.sh时就不知道还需要添加–new-consumer,结果我启动了MirrorMaker以后,感觉消息在消费,但就是在ZooKeeper的/consumer/ids/上找不到group的任何信息。后来在stack overflow上问了别人才知道。
Kafka内置的分区分派策略有:RangeAssignor和RoundRobinAssignor。由于RangeAssignor是早期版本的Kafka的唯一的分区分派策略,因此,默认不配置的情况下,Kafka使用RangeAssignor进行分区分派,但在MirrorMaker的使用场景下,RoundRobinAssignor更有利于均匀的分区分派。甚至在KAFKA-3831(https://issues.apache.org/jira/browse/KAFKA-3831)中有人建议直接将MirrorMaker的默认分区分派策略改为RoundRobinAssignor。
那么,它们到底有什么区别呢?我们先来看两种策略下的分区分派结果。
在我的实验场景下,有6个Topic:ABTestMsg|AppColdStartMsg|BackPayMsg|WebMsg|GoldOpenMsg|BoCaiMsg,每个topic有两个分区。由于MirrorMaker所在的服务器性能良好,我设置--num.streams 40,即单台MirrorMaker会用40个线程,创建40个独立的Consumer进行消息消费,两个MirrorMaker加起来80个线程,80个并行Consumer。由于总共只有6 * 2=12个TopicPartition,因此最多也只有12个Consumer会被分派到分区,其余Consumer空闲。
我们来看基于RangeAssignor分派策略的kafka-consumer-groups.sh 的结果:

当没有在mirror-consumer.properties 中配置分区分派策略,即使用默认的RangeAssignor时,我们发现,尽管每一个MirrorMaker有40个Consumer,整个Group中有80个Consumer,但一共6 * 2 = 12个TopicPartition竟然全部聚集在2-3个Consumer上,显然,这完全浪费了并行特性,被分配到一个consumer上的多个TopicPartition只能串行消费。
因此,通过partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor显式指定分区分派策略为RoundRobinAssignor,重启MirrorMaker,重新通过kafka-consumer-groups.sh观察分区分派和消费延迟结果:
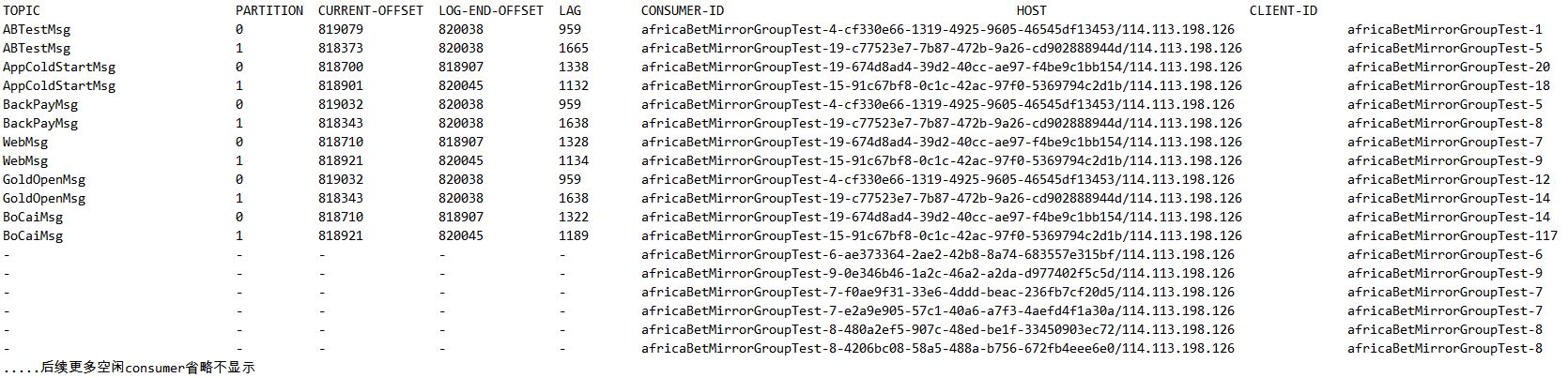
对比RangeAssingor,消息延迟明显减轻,而且12个TopicPartition被均匀分配到了不同的consumer上,即单个Consumer只负责一个TopicPartition的消息消费,不同的TopicPartition之间实现了完全并行。
之所以出现上述不同,原因在于两个分区分派方式的策略不同:
RangeAssingor:先对所有Consumer进行排序,然后逐个Topic一一进行分区分派。用以上Topic为例:
对所有的Consumer进行排序,排序后的结果为Consumer-0,Consumer-1,Consumer-2 ....Consumer-79
对ABTestMsg进行分区分派:
ABTestMsg-0分配给Consumer-0
ABTestMsg-1分配各Consumer-1
对AppColdStartMsg进行分区分派:
AppColdStartMsg-0分配各Consumer-0
AppColdStartMsg-1分配各Consumer-1
#后续TopicParition的分派以此类推
可见,RangeAssingor 会导致多个TopicPartition被分派在少量分区上面。
RoundRobinAssignor:与RangeAssignor最大的区别,是不再逐个Topic进行分区分派,而是先将Group中的所有TopicPartition平铺展开,再一次性对他们进行一轮分区分派。
将Group中的所有TopicPartition展开,展开结果为:
ABTestMsg-0,ABTestMsg-1,AppColdStartMsg-0,AppColdStartMsg-1,BackPayMsg-0,BackPayMsg-1,WebMsg-0,WebMsg-1,GoldOpenMsg-0,GoldOpenMsg-1,BoCaiMsg-0,BoCaiMsg-1
对所有的Consumer进行排序,排序后的结果为Consumer-0,Consumer-1,Consumer-2 ....Consumer-79
开始讲平铺的TopicPartition进行分区分派:
ABTestMsg-0分配给Consumer-0
ABTestMsg-1分配给Consumer-1
AppColdStartMsg-0分配给Consumer-2
AppColdStartMsg-1分配给Consumer-3
BackPayMsg-0分配给Consumer-4
BackPayMsg-1分配给Consumer-5
#后续TopicParition的分派以此类推
由此可见,RoundRobinAssignor平铺式的分区分派算法是让我们的Kafka MirrorMaker能够无重叠地将TopicParition分派给Consumer的原因。
网络带宽本身也会限制Kafka Mirror的吞吐量。进行压测时,我分别在我们的在线环境和测试环境分别运行Kafka MirrorMaker,均选择两台服务器运行MirrorMaker,但在线环境是实体机环境,单台机器通过SCP方式拷贝Source Cluster上的大文件,平均吞吐量是600KB-1.5MB之间,但测试环境的机器是同一个host主机上的多台虚拟机,SCP吞吐量是100KB以下。
经过测试,测试环境消息积压会逐渐增多,在线环境持续积压,但积压一直保持稳定。这种稳定积压是由于每次poll()的间隙新产生的消息量,属于正常现象。
适当配置单次poll的消息总量
和单次poll()的消息大小
通过Kafka MirrorMaker运行时指定的consumer配置文件(在我的环境中为$MIRROR_HOME/config/mirror-consumer.properties)来配置consumer。其中,通过以下配置,可以控制单次poll()的消息体量(数量和总体大小)
max.poll.records:单次poll()操作最多消费的消息总量,这里说的poll是单个consumer而言的。无论过大过小,都会发生问题:
如果设置得过小,则消息传输率降低,大量的头信息会占用较大的网络带宽;
如果设置得过大,则会产生一个非常难以判断原因、同时又会影响整个group中所有消息的消费的重要问题:rebalance。看过Kafka代码的话可以看到,每次poll()请求都会顺带向远程server发送心跳信息,远程GroupCoordinator会根据这个心跳信息判断consumer的活性。如果超过指定时间(heartbeat.interval.ms)没有收到对应Consumer的心跳,则GroupCoordinator会判定这个Server已经挂掉,因此将这个Consumer负责的partition分派给其它Consumer,即触发rebalance。rebalance操作的影响范围是整个Group,即Group中所有的Consumer全部暂停消费直到Rebalance完成。而且,TopicPartition越长,这个过程会越长。
其实,一个正常消费的环境,应该是任何时候都不应该发生rebalance的(一个新的Consumer的正常加入也会引起Rebalance,这种情况除外)。虽然Kafka本身是非常稳定的,但还是应该尽量避免rebalance的发生。在某些极端情况下触发一些bug(),rebalance可能永远停不下来了……如果单次max.poll.records消费太多消息,这些消息produce到Target Cluster的时间可能会较长,从而可能触发Rebalance。
在不稳定的网络环境下,应该增加部分超时时间配置,如request.timeout.ms或者session.timeout.ms,一方面可以避免频繁的超时导致大量不必要的重试操作,同时,通过增加如上文所讲,通过增加heartbeat.interval.ms时间,可以避免不必要的rebalance操作。当然,在网络环境良好的情况下,上述配置可以适当减小以增加Kafka Server对MirrorMaker出现异常情况下更加及时的响应。
总之,Kafka MirrorMaker作为跨数据中心的Kafka数据同步方案,绝对无法允许数据丢失以及数据的传输速度低于生产速度导致数据越积累越多。因此,唯有进行充分的压测和精准的性能调优,才能综合网络环境、服务器性能,将Kafka MirrorMaker的性能发挥到最大。









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒