
作者介绍
黄浩:从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
中国的古典哲学起源于道:一阴一阳即为道,而传统的太极拳就是从阴阳互动中演变而来。汲取了道之精华的太极拳讲究的是刚柔相济、强弱相成,其中四两拨千斤的招数就是对道的衣钵传承。那么,四两拨千斤与我们的SQL性能优化有什么关系呢?
首先我们来看一个优化案例
某日,难得清闲,于是乎也附庸风雅,找来一本关于Oracle的电子书,正在“千万章节”中挑选目录时,托盘上的espace弹出了消息,斜目一瞥,立马ALT+Z提取了消息,因为消息中的“select”关键字太扎眼了:又得优化而不得闲了。
SQL如下:

初步印象
如果把SQL比作MM的话,这个SQL就是典型的“水桶圆柱”型MM:面如月盘(SELECT的字段部分长且宽)、体态丰盈(FROM的对象达12个之多)、腿短脚粗(几乎没有WHERE条件过滤)。毫无婀娜之姿,尽显臃肿之态。观之无好感,近之有憎意。
在与SQL提供者在ESPACE简短的沟通后,得到如下信息:
SQL执行耗时需要5S以上,即便是只查询15条数据;
性能瓶颈是ORDER BY,因为如果将ORDER BY注释掉的话,速度非常快;
希望将SQL优化到2S内。
世间充满了矛盾
看来在此之前,他们也是有过优化,并且已经成功地定位到性能瓶颈:ORDER BY。而由于任何不以ORDER BY为依据的分页都是流氓行为,所以ORDER BY是必须的。这就形成了一个死结:要想保证分页的严谨性,就无法保证性能;要想达到性能需求,就必须要牺牲掉分页的严谨性。这真是SQL优化版的鱼与熊掌不可兼得,愁死个宝宝了。
给ORDER BY翻案
我首先能想到的是结果集过大,触发了ORDER BY的性能瓶颈:一方面,正常情况下,ORDER BY之前,需要获取所有的数据,如果数据量过大,CPU及IO的开销肯定大;另一方面,ORDER BY自身的性能对数据量也是非常敏感的,数据量越大,ORDER BY的性能就越低。
基于这个猜想,我COUNT了下数据量,结果显示是169613,这个数据量也不算多,至少不至于让一个ORDER BY产生如此性能问题。
由此可见,在这个性能问题中,ORDER BY是背了黑锅的。ORDER BY只是一个表象而已。
再看执行计划,更是让人意外:
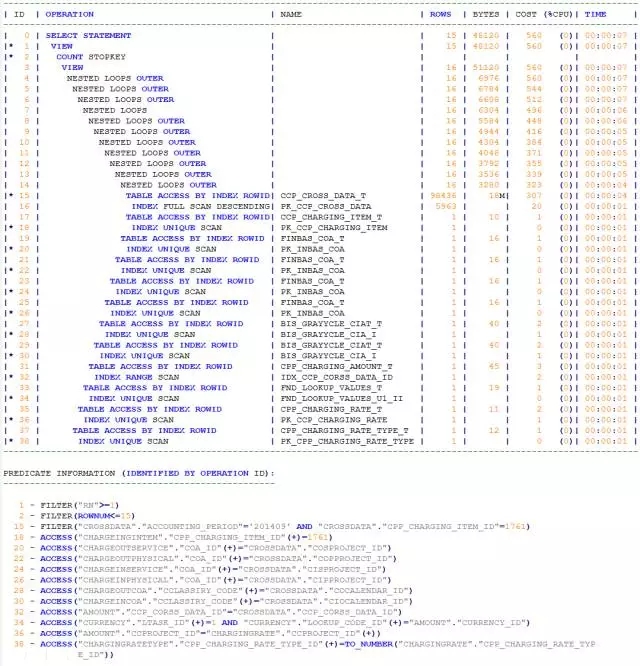
我惊奇地发现:
整个执行计划的COST并不高;
纵观整个执行计划,并没有出现SORT操作。那么ORDER BY又是怎么实现的呢?
在执行计划中,有如下一个操作:
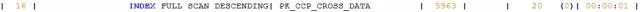
INDEX FULL SCAN DESCENDING的对象是PK_CCP_CROSS_DATA,我赶紧查看了下这个对象:

这个UNIQUE INDEX的字段对象是CCP_CORSS_DATA_ID,而该字段就是ORDER BY的字段对象。我又查看了下该表的数据量,接近4000万。
此时,我全理解了,在分页ORDER BY时出现INDEX FULL SCAN DESCENDING的操作,这与在《SQL分页查询之巧夺天工》如出一撤,在此就不再累赘。
通常而言,除非紧急情况下,我一般都不采用HINT的方式来解决性能问题,而是更倾向于SQL的等价改写。
因为时间充裕,我也悠哉悠哉开始了SQL等价改写。
话分两头
分页查询的最大特性就是结果集非常小,以该案例为例,每次执行SQL,返回的数据量永远是小于等于15条。
最为常规的算法是:先获取出所有的记录,再排序,然后获取15条数据,如下图:
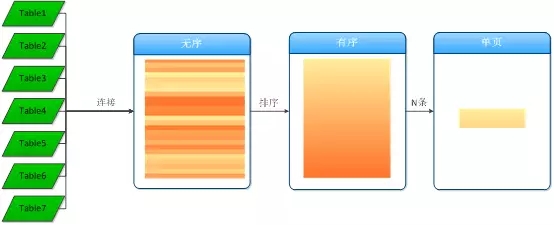
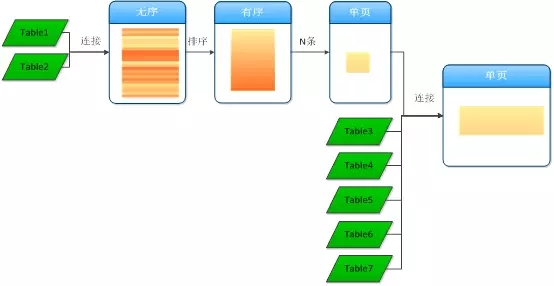
上述算法也可以进行优化,如下图所示:
再回到这个SQL,其表之间的关联逻辑如下图所示:
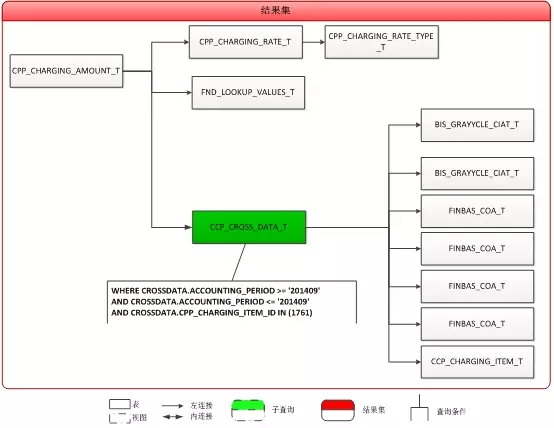
以看出:
SQL中的主表是CPP_CHARGING_AMOUNT_T,其他表都之间或间接LEFT JOIN,但是由于WHERE条件过滤都是CCP_CROSS_DATA_T表,所以,CPP_CHARGING_AMOUNT_T LEFT JOIN CCP_CROSS_DATA_T等价于CPP_CHARGING_AMOUNT_T INNER JOIN CCP_CROSS_DATA_T;
如下图所示:
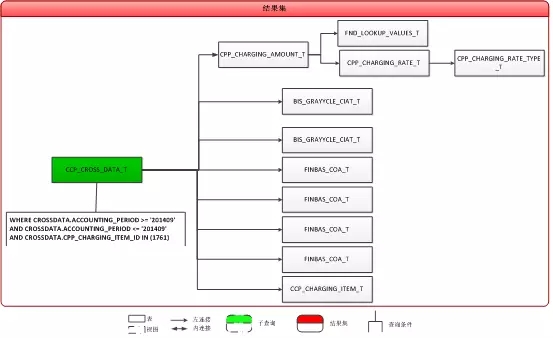
再通过SQL语句及模型结构,进一步发现:
分页排序的字段为CCP_CORSS_DATA_ID,来源于主表CCP_CROSS_DATA_T;
所有LEFT JOIN的关联条件字段都是RIGHT表的unique index,也就是说在整个SQL中,CCP_CORSS_DATA_ID为最细粒度对象,LEFT JOIN其他表后不会对数据集的大小产生影响
结合前面对分页算法的优化思路,在逻辑算法上可以做如下优化:
首先将CCP_CROSS_DATA_T表与表CPP_CHARGING_AMOUNT_T关联,并通过过滤条件得到满足条件的全部的CCP_CORSS_DATA_ID;
将1中的结果集排序,并获取15条记录;
用2中的15条记录的CCP_CORSS_DATA_ID为驱动,LEFT JOIN其他的表
等价改写后的SQL如下:
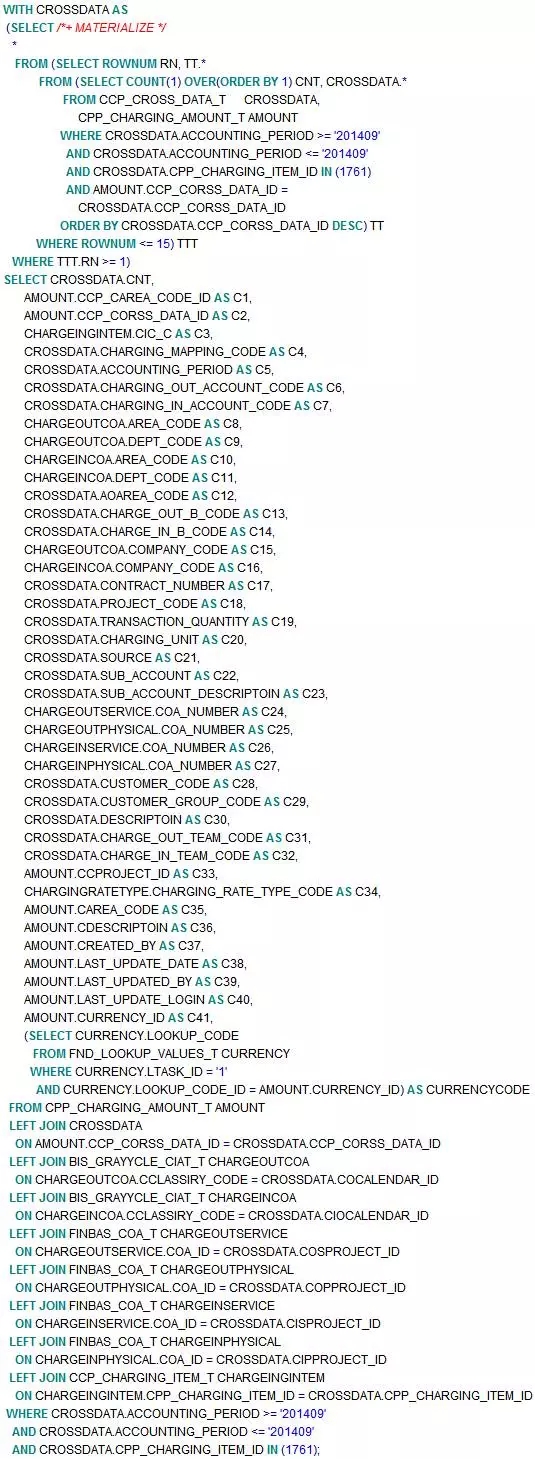
华丽转身
我用with实现了“获取15条CCP_CORSS_DATA_ID”的需求。而这个放在原SQL顶部的WITH子查询,如同一顶璀璨如明珠的皇冠。马因鞍而骏,人因冠而美。这位“水桶”MM因为这顶皇冠而华丽转身:唐朝贵妃,一时间雍容华贵富态尽显。
再看执行计划:

成本果然有下降,从之前的560变成了249,超过了一半。
降低成本仅仅是优化的手段,优化的目的是让SQL跑得更快,所以真正考验SQL等价改写效果的是SQL的执行效率。
我将改写后的SQL在数据库中执行:0.7s,简直是快得不要不要的。
至此,案例已经完成优化,而通过该案例,我们能获得什么启发呢?尤其是对分页查询的性能有什么借鉴意义呢?
“SQL执行耗时需要5s以上,即便是只查询15条数据”还记得这句吗?是的,这就是开发人员的牢骚,同时这也是大多数业务用户的困扰:我只要求查看15条记录,为何都这么慢?其实,这里大家都混淆了一个基本问题:分页查询解决的是数据传输和页面加载的性能问题,并非SQL的性能问题;而恰恰相反,很多SQL是因为做了分页处理而引发了性能问题。而其罪魁祸首就是ORDER BY,比如该案例,将order by注释掉,性能是非常高的。
在案例《SQL分页查询之巧夺天工》中,我们巧用索引解决了ORDER BY的性能瓶颈,很显然,“巧夺天工”无法应用在这个案例上。但是该案例的SQL也有自身的特点:
SQL中有明确的主体表,比如CCP_CROSS_DATA_T是主表;
主表与其它表的(间接)关联方式都是LEFT JOIN;如果存在INNER JOIN或者LEFT JOIN后出现过滤条件,则需要将主表和这些有过滤作用的表一起作为主表;比如该案例中在with子查询中就是CCP_CROSS_DATA_T INNER JOIN CPP_CHARGING_AMOUNT_T 。
主表与其它表是通过主外键关联,即主表与其它表(间接)关联后,不会影响最终的数据量。比如在没有关联其它表的情况下,数据量为100万;而关联其它表后,数据量仍然是100万。
如果我们将主表比作是月亮的话,那么其它表就是星星,所以我们把这种结构的SQL叫做“众星拱月”,专业一点就是“星型模型”查询。
这样,我们自然就可以先从“月亮”那里获取15条数据,然后拿着这15条数据再从“星星”那里关联到响应的信息。这样做的收益是:
因为只有“月亮”,没有众多“星星”的掺合,ORDER BY就变得轻松多了。这就好比在高速公路上的汽车,如果只有一辆车,即便是单车道,也能畅行无堵;而如果车辆宛如长龙,即便是有十个八个车道,也只能慢如蜗牛;
其次,由于只有15条数据,又是主外键关联,即便“星星”再多再大,也能达到非常好的性能。
因此,“众星拱月”型分页查询性能优化的关键在于:识别星星月亮。
越是民族的,越是世界的。世界是相通的。
最后,我们回到本篇最开始的问题:四两拨千斤与我们的SQL性能优化有什么关系呢?很显然,在这里,15条数据就是四两,而总记录数17万就是千斤。我们用15条记录,轻而易举地拨动了17万数据。对于Oracle优化器而言,这叫小表驱动大表。中国古老的哲学与西方现代技术理念不谋而合,或喜或悲?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721