
林伟壕,网易游戏资深运维工程师。现任职于网易游戏,从事游戏运维相关工作;曾就职于中国电信,负责数据网络维护、网络安全防御等工作。深入研究Linux运维、虚拟化等,现致力于企业级网络安全防护自动化体系构建。
相对物理环境,虚拟化环境更加错综复杂。之前弄KVM虚拟化时经常遇到好多次莫名其妙的网络故障,查出来的原因要么是操作系统内核bug,要么是KVM与操作系统内核版本不兼容,最后是通过升级操作系统内核或者KVM版本修复了。没想到,转型到Docker后,又重蹈覆辙了。
本文将介绍一个困扰笔者近半年的虚拟化环境下的疑难故障,最后排查出来的故障原因和修复手段也让人啼笑皆非。并非因为这个过程有多复杂,而是分享一个心理历程,思考在遇到故障时如何兼顾业务和技术,如何正确使用搜索引擎。
我们有一套高性能代理集群,之前内测阶段运行稳定,结果等正式上线后不到半个月,提供代理服务的宿主突然接二连三死机,导致宿主上的所有服务全部中断。
故障时宿主直接死机,无法远程登录,机房现场敲键盘业务反应。由于宿主syslog已接入ELK,所以我们采集了当时死机前后的各种syslog。
通过查看死机宿主的syslog发现机器死机前有以下kernel报错:
Nov 12 15:06:31 hello-worldkernel: [6373724.634681] BUG: unable to handle kernel NULL pointer dereferenceat 0000000000000078
Nov 12 15:06:31 hello-world kernel: [6373724.634718] IP: []pick_next_task_fair+0x6b8/0x820
Nov 12 15:06:31 hello-world kernel: [6373724.634749] PGD 10561e4067 PUDffdb46067 PMD 0
Nov 12 15:06:31 hello-world kernel: [6373724.634780] Oops: 0000 [#1] SMP
显示访问了内核空指针后触发系统bug,然后引起一系列调用栈报错,最后死机。
为进一步分析故障现象,首先需要理解这套高性能代理集群的架构。
架构介绍
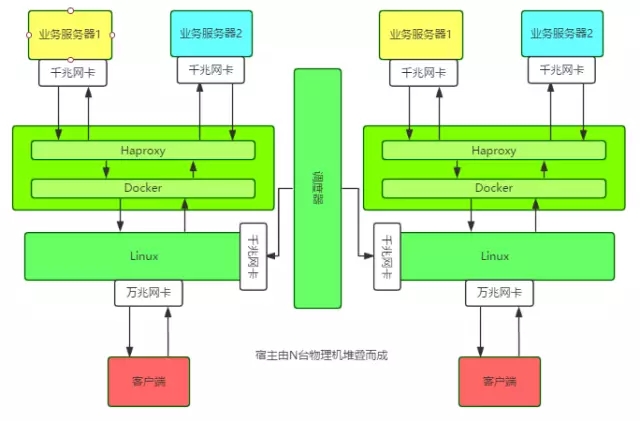
单个节点,是在万兆网卡的宿主机上跑Docker容器,然后在容器中跑Haproxy实例,每个节点、实例的配置信息、业务信息都托管在调度器上。
特别之处在于:宿主使用Linux Bridge直接给Docker容器配置IP地址,所有对外服务的IP,包括宿主自己的外网IP都绑在Linux Bridge上。
每台宿主的操作系统、硬件、Docker版本全部一致,其中操作系统和Docker版本如下:
[操作系统]
System : Linux
Kernel : 3.16.0-4-amd64
Version : 8.5
Arch : x86_64
[Docker版本]
Docker version 1.12.1, build 6b644ec
该集群的宿主配置一致,故障现象也一致,疑点有三个:
1、Docker版本与宿主内核版本不兼容
三台宿主的环境本来一致,但1台稳定跑服务2个月才死机,1台跑服务1个月后死机,另外1台上线跑服务一周便会死机。
发现每台宿主除了死机的异常日志,平时也有相同报错日志:
time="2016-09-07T20:22:19.450573015+08:00"level=warning msg="Your kernel does not support cgroup memory limit"
time="2016-09-07T20:22:19.450618295+08:00" level=warningmsg="Your kernel does not support cgroup cfs period"
time="2016-09-07T20:22:19.450640785+08:00" level=warningmsg="Your kernel does not support cgroup cfs quotas"
time="2016-09-07T20:22:19.450769672+08:00" level=warningmsg="mountpoint for pids not found"
根据上面提示,应该是操作系统内核版本对该版本的Docker不支持某些功能所导致。不过在搜索引擎上搜索这并不影响Docker的功能,更不加影响系统稳定性。
比如:
time="2017-01-19T18:16:30+08:00"level=error msg="containerd: notify OOM events" error="openmemory.oom_control: no such file or directory"
time="2017-01-19T18:22:41.368392532+08:00"level=error msg="Handler for POST /v1.23/containers/338016c68da6/stopreturned error: No such container:
338016c68da6"
是Docker 1.9以来就有的问题,1.12.3修复了。参考https://github.com/docker/docker/ issues/24211
比如Github上有人回复:
“I have been update my docker from 1.11.2 to 1.12.3, This issue is fixed.
BTW, this error message can be ignored, it should really just be a warning.”
但这里所说的都只是v1.12.2版本就能修复的问题,我们升级Docker版本后发现死机依旧。
于是,我们接着通过各种Google确认了很多与我们存在相同故障现象的问题,初步确认故障与Docker的相关性:
又根据以下官方issue初步确认Docker版本与系统内核版本不兼容可引发宕机的关联性:
接着,通过官方的changelog和issue确认宿主所使用Docker版本与系统内核版本不兼容问题:
出于尝试心理,我们把Docker版本升级到1.12.2后,未出意外仍出现死机。
2.使用Linux bridge方式改造宿主网卡可能触发bug
找了那台宿主跑服务一周就会死机的宿主,停止运行Docker,只改造网络,稳定跑了一周未发现异常。
3.使用pipework给Docker容器配置IP可能触发bug
由于给容器分配IP时我们采用了开源的pipework脚本,因此怀疑pipework的工作原理存在bug,所以尝试不使用pipework分配IP地址,发现宿主仍出现死机。
于是初步排查陷入困境,眼看着宿主每月至少死机一次,非常郁闷。
因为还有线上业务在跑,所以没有贸然升级所有宿主内核,而是期望能通过升级Docker或者其它热更新的方式修复问题。但是不断的尝试并没有带来理想中的效果。
直到有一天,在跟一位对Linux内核颇有研究的老司机聊起这个问题时,他三下五除二,Google到了几篇文章,然后提醒我们如果是这个 bug,那是在 Linux 3.18 内核才能修复的。
参考:
原因:
从sched: Fix race between task_group and sched_task_group的解析来看,就是parent 进程改变了它的task_group,还没调用cgroup_post_fork()去同步给child,然后child还去访问原来的cgroup就会null。
不过这个问题发生在比较低版本的Docker,基本是Docker 1.9以下,而我们用的是Docker1.11.1/1.12.1。所以尽管报错现象比较相似,但我们还是没有100%把握。
但是,这个提醒却给我们打开了思路:去看内核代码,实在不行就下掉所有业务,然后全部升级操作系统内核,保持一个月观察期。
于是,我们开始啃Linux内核代码之路。先查看操作系统本地是否有源码,没有的话需要去Linux kernel官方网站搜索。
```
apt-cache search linux-image-3.16.0-4-amd64
apt-get source linux-image-3.16.0-4-amd64
```
下载了源码包后,根据报错syslog的内容进行关键字匹配,发现了以下内容。由于我们的机器是x86_64架构,所以那些avr32/m32r之类的可以跳过不看。结果看下来,完全没有可用信息。
/kernel/linux-3.16.39#grep -nri "unable to handle kernel NULL pointer dereference" *
arch/tile/mm/fault.c:530: pr_alert("Unable to handlekernel NULL pointer dereference\n");
arch/sparc/kernel/unaligned_32.c:221: printk(KERN_ALERT "Unable to handle kernel NULL pointerdereference in mna handler");
arch/sparc/mm/fault_32.c:44: "Unable to handle kernel NULL pointer dereference\n");
arch/m68k/mm/fault.c:47: pr_alert("Unable tohandle kernel NULL pointer dereference");
arch/ia64/mm/fault.c:292: printk(KERN_ALERT "Unable tohandle kernel NULL pointer dereference (address %016lx)\n", address);
debian/patches/bugfix/all/mpi-fix-null-ptr-dereference-in-mpi_powm-ver-3.patch:20:BUG:unable to handle kernel NULL pointer dereference at (null)
最后,我们还是下线了所有业务,将操作系统内核和Docker版本全部升级到最新版。这个过程有些艰难,当初推广这个系统时拉的广告历历在目,现在下线业务,回炉重造,挺考验勇气和决心的。
下面是整个故障处理过程中,我们进行的一些操作。
对于Docker 1.11.1与内核4.9不兼容的问题,可以删除原有的Docker配置,然后使用官方脚本重新安装最新版本Docker
```
/proxy/bin#ls /var/lib/dpkg/info/docker-engine.
docker-engine.conffiles docker-engine.md5sums docker-engine.postrm docker-engine.prerm
docker-engine.list docker-engine.postinst docker-engine.preinst
#Getthe latest Docker package.
$curl -fsSL https://get.docker.com/ | sh
#启动
nohupdocker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock-s=devicemapper&
```
这里需要注意的是,Docker安装方式在不同操作系统版本上不尽相同,甚至相同发行版上也有不同,比如原来我们使用以下方式安装Docker:
```
apt-get install docker-engine
```
然后在早些时候,还有使用下面的安装方式:
```
apt-get install lxc-docker
```
可能是基于原来安装方式的千奇百怪导致问题丛出,所以Docker官方提供了一个脚本用于适配不同系统、不同发行版本Docker安装的问题,这也是一个比较奇怪的地方,所以Docker生态还是蛮乱的。
16:44:15 up 28 days, 23:41, 2 users, load average: 0.10, 0.13, 0.15
docker 30320 1 0 Jan11 ? 00:49:56 /usr/bin/docker daemon -p/var/run/docker.pid
Docker内核升级到1.19,Linux内核升级到3.19后,保持运行至今已经2个月多了,都是ok的。
这个故障的处理时间跨度很大,都快半年了,想起今年除夕夜收到服务器死机报警的情景,心里像打破五味瓶一样五味杂陈。期间问过不少研究Docker和操作系统内核的同事,往操作系统内核版本等各个方向进行了测试,但总与正确答案背道而驰或差那么一点点。最后发现原来是处理得不够彻底,比如升级不彻底,环境被污染;比如升级的版本不够新,填的坑不够厚。回顾了整个故障处理过程,总结下来大概如下:
回归运维的本质
运维要具有预见性、长期规划,而不能仅仅满足于眼前:
应急预案:针对可能系统上线后可能发生的故障类型进行总结,并提供应急预案。
抢通业务:优先抢通业务,再处理故障。
应用版本选择等技术选型问题:在环境部署和应用选型时需要特别注意各种版本,最好采用社区通用或者公司其他同学已经测试或验证可行的版本。
操作系统内核:要合理升级内核,只有定位到确定版本存在的问题,才能有针对性的升级内核版本,不然一切徒劳。
在我们原来的设计中,不同用户调度器针对同一个容器同时操作没有加锁机制,也没有按照对源判断原则,也曾出现过迁移失败的情况。迁移时判断迁往的目的地址是否就是本地地址,如果是本地地址应该拒绝操作的。这个问题不知你是否觉得眼熟。我倒是发现,很多人程序开发过程中,就经常不对输入源或者操作的源状态进行判断,结果出现了各种bug。
Google的能力
在处理这个故障的过程中,会发现不同人使用Google搜出来的东西并不一样,为什么呢?我觉得这就是搜索引擎槽点满满,或者说灵活之处。像这次的故障,我用Linux Docker Unable to handle kernel NULL pointer dereference去搜索,与别人用”Unable to handle kernel NULL pointer dereference”结果就不同。原因在于增加了””之后,搜索更加精确了。关于Google的正确打开方式,建议参考:








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721