

(点击底部链接获取汪洋演讲完整PPT)
讲师介绍
汪洋,从事Oracle相关开发运维工作20年。现任平安科技数据库技术部总监,负责数据库技术引入,数据库产品选型、架构设计、规范制定,开发、测试、生产环境运维等工作。近年,对开源数据库技术以及DBaaS产生浓厚兴趣,一直致力于相关的研究和引入工作。
本次分享大纲:
我们的困境和挑战
选择比努力更重要
十月磨一剑
最终的决战时刻
今天给大家带来的分享为《平安产险核心DB升级记》,为什么选择“数据库升级”这个主题来分享呢?首先,一方面我是做数据库出身的,另一方面,我认为数据库的升级是一个相对复杂的系统化工程。在这中间,它几乎要运用到数据库领域的所有知识,包括管理、备份恢复、容灾、监控等,而且这个过程中,该怎么做升级的准备,如何保证真正的实施方案的顺利进行,实施之后如何对它进行监控,以及万一有预想不到的风险,怎么去顺利回退等等。不单单这样,它还包括主机的一些存储、配置,整个流程的东西都需要考虑。这是我选择这个主题的第一个原因。
第二个原因,为什么是“平安产险”这个数据库?因为这个9i版本的数据库在当时可以说是全世界最大的,它有达100多TB的数据容量。它不光是产险最核心的数据库,并且几乎产险之外的所有子系统也都在这个数据库里面。综合以上这些因素,构成了这个系统的复杂性。
第三个原因,就是五年前我们曾经失败过一次,所以这个数据库一直是我们心中的一根刺,心口上永远的痛,我们一直想把它拔掉。
最后,它是从9i升级到11g,可能大家会觉得这是个老生常谈的问题,都谈了很多年了,而且它也不是升级到最新的版本12c。但它是我从业以来最复杂的一次数据库升级,里面用到的一些思想和方法能够提炼出来,用到不光是Oracle数据库,也可以用到其他数据库,甚至不单是数据库里面的,也可以运用到其他领域。所以借此机会分享出来,希望能够给大家一些借鉴。
一、我们的困境和挑战
1、业务系统特点介绍

正如前面提到的,它是全球最大的Oracle 9i OLTP数据库,甚至连原厂的工程师都不敢碰它,觉得这个任务似乎不可能完成。刚刚也说了,五年前我们曾经失败过一次,那时它才只有10个TB,五年之后,业务数据量变成了110个TB,现在每个月仍在以3TB的速度往上增长,而且是9i版本。众所周知,9i是个非常老的产品,它可能在设计的时候就没想过去运行这么大的一个在线数据库。
我们看到,它的业务数据量有110TB+,每秒的事务量是2000+,大家可能觉得这事务量不是很高,因为现在都是一万或十几万事务量,但我想告诉大家的是,保险不同于其他行业,它的每个事务都需要涉及到非常复杂的计算后才能提交,所以不同系统的TPS事务量代表的意义是不一样的。对于产险数据库来说,它已有的数据量已经是非常高的了,五年前只是现在的1/7,五年后翻了7倍。此外,它每天处理的SQL量有50多万,基本上支撑着平安产险95%以上的业务。如果万一发生问题,造成的影响与损失可想而知。
2、当前面临的问题

获得Oracle产品的Premier Support支持
首先,Oracle 9i版本的延展服务在2011年的7月已经到期了,所以出了问题会怎样?如果大家用Oracle的话,出了问题,还是可以通过请求GCS (Oracle 全球技术支持)来帮你解决,但如果是新Bug的话,它是不会让O染成了研发介入开发新patch的,它只能有一些Workaround去帮你规避。如果连Workaround都没有,那你就只能像踩着钢丝一样,天天担心自己会不会遇到这些新的Bug。假如真的遇到了,也得自己想办法如何去规避。其实运行这么多年,我们也通过一些已知的办法去规避,但这始终不是长久之计。基于这些原因,必须要去升级。
解决硬件扩展的瓶颈
第二个是硬件扩展的瓶颈。它不光是数据库本身厂商的不支持, 更是强调一个生产圈的不支持,包括它的主机、操作系统都不再服务支持。如现在我们这个新购的主机上只能运行Solaris 11,而Solaris 11 又只认证Oralce 11g以后版本的数据库,所以不及时升级的话,新采购回来的硬件只能认证比它高的版本,你仍继续用9i,发生问题时,厂商是没有办法解决的,甚至你要冒风险去运行在一个不被认证的操作系统上。还有就是刚才提到的硬件的存储,我们的数据库有110TB,而数据量每个月仍在以3T的速度往上增长,而旧的整个存储最大的容量也就130TB,很快就会达到它的瓶颈。
缓解DB性能不稳定的风险
我们在2013-2014年出现了三次UIOC(ugency incident office center),相当于一个作战史,一共发生了三次,而且每次都与latch: cache buffers chains等待事件相关。其实在9i里面我们感觉已经没有一个很有效的办法可以解决这个问题了,而在更早之前,从2009-2014年间更出现了12次重大事件,其中5次与执行计划突变有关,这些都是我们用9i时遇到过的问题,急需把它升级为11g。
提升技术人力的价值投入
维护9i所投入的人力成本是非常大的。为什么这么说呢?因为9i是一个比较旧的技术,很多时候我们的解决手段都必须在更高的版本上去实现,而在9i上做一个技术的变更非常复杂,你要考虑得非常细致,很多变更不能通过在线操作。如果升级到11g,不光可以释放一部分的人力,还能把这部分的人力投入到更有价值的事情上去。
3、系统变更要求

我们平时数据库升级一般遵循的都是一次只做一个变更,但这次情况不同,就像前面提到的受限于硬件、存储等多个瓶颈,我们一次做了四个变动,这也是为什么这次升级如此复杂的原因之一。其中,操作系统是从Solaris 10升级到了Solaris 11,DB版本从9.2.0.5升级到了11.2.0.4,主机硬件从M9000升级到T5-4,存储硬件是从高端SAN变更成了闪存。现在闪存是未来存储的趋势。
以上这些都是我们在做方案时提出的挑战和要求。
二、选择比努力更重要
如果一开始的选择就是错的,即使后面你do things right,最后的结果也不一定是对的。因此在升级之前,我们要做出正确的选择。
1、实施过程设计
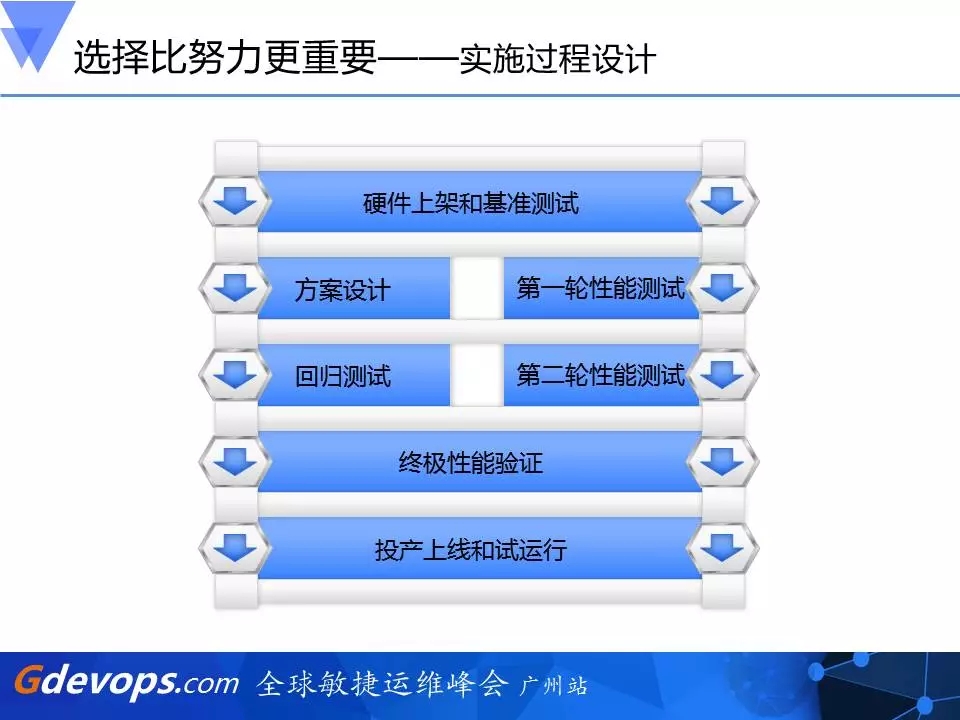
这是方案大致的流程。首先要走基础的硬件上架和基准的测试,比如说,存储的IO能力能不能达到我的要求,虽然理论上闪存是要比以前高端SAN要强很多,但没有经过实际测试过,也是无法确定的,所以需要自己做一遍测试。主机呢,我们也是把真正的生产系统切换到新的主机上进行试运行一次,看T5-4到底是不是要比M9000要好,避免发生我们预期不到的事情。经过这样一轮测试,我们才有信心、郑重地做硬件架构升级后的生产运行平台。接下来,一方面是做性能测试,一方面是要做功能方面的回归测试,最后还要联调再做一次终极的性能验证。做完之后,用户接受、开发接受,然后再做系统真实的投产上线和运行。
首先我们碰到的第一个难题就是DB Replay,用过Oracle的都知道,它是RAT (Oracle Real Application Testing)的一个组件,它可以把一个数据库的负载在做一些变更之后,在另外一个的数据库或平台上去负载重演,看这负载在你升级前后或者硬件更换前后有什么差别。在这里,第一个难题就是DB Replay是11g的一个新特性,而目前我们的库版本为9i的,所以需要打上一个patch,因此我们要求Oracle全球研发帮我们出一个9i版本的patch,经分析这个patch跟我们目前数据库补丁有冲突,所以我们花了很长时间去做这种补丁冲突的分析,一层层的抽丝剥茧,最终找到那些产生冲突的patch,把这些不重要的冲突patch拿走。
2、软件补丁方案设计
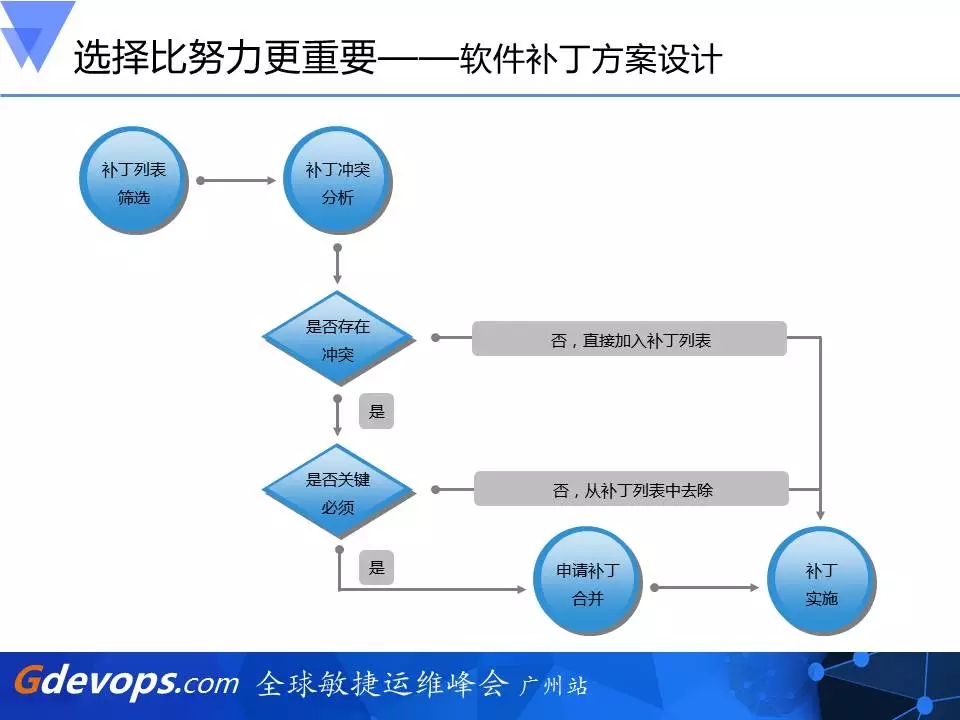
第二个难题就是我们要在新的11g版本上去安装patch,这又是另一套原则。大家可以看到,我们先是做了一个补丁列表的筛选,是Oracle发布的Patch Set Update(PSU),还有一些Critical Patch Update(CPU),都作为我们的待选。待选patch的会和已有的、已打的patch做一些补丁冲突分析,如果有冲突的话,那就看它是否关键。两个相比较,看到底哪一个更关键一些,我们会留下更为关键的一个。如果没有冲突,直接加入到我们的补丁列表,做成一整套补丁实施方案,这样我们就能知道未来的系统是什么样的数据库版本以及需要打上什么样的补丁集信息。
3、功能测试方案设计
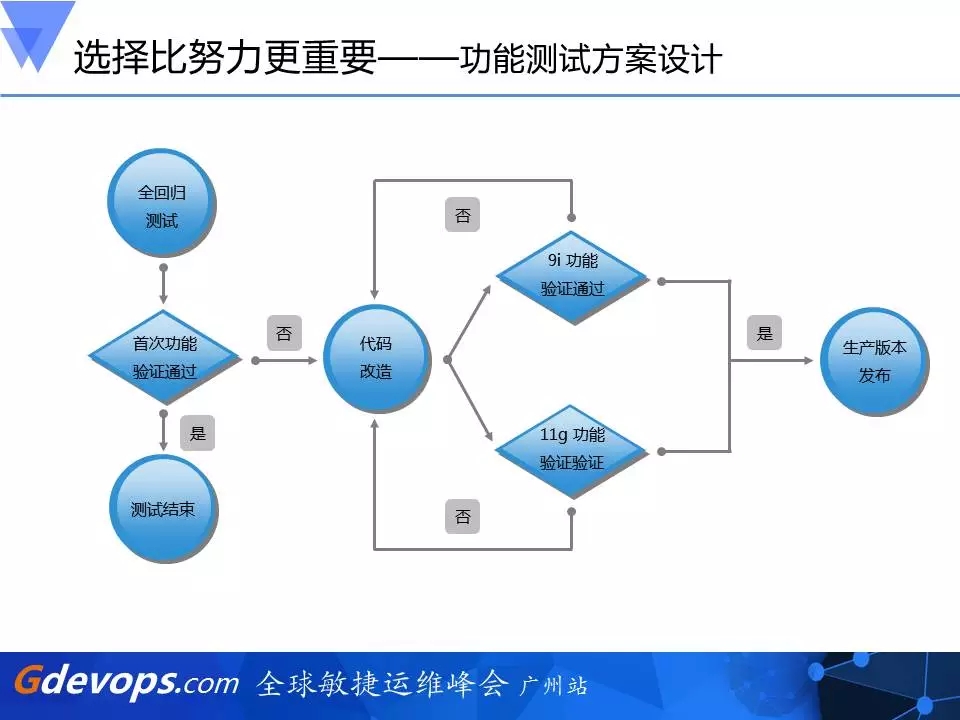
第二个选择比努力更重要的是功能测试。系统每一次的功能版本变更都有一个定型期,因为我们这个事情差不多进行了半年,定型期里面,每发一次版本变更都要同时在9i和11g的平台上功能验证通过,我们才能去发布,这是为了保证整个升级运行期软件版本的一致性,也是为了让它升级以后不会出问题。
4、性能测试方案设计
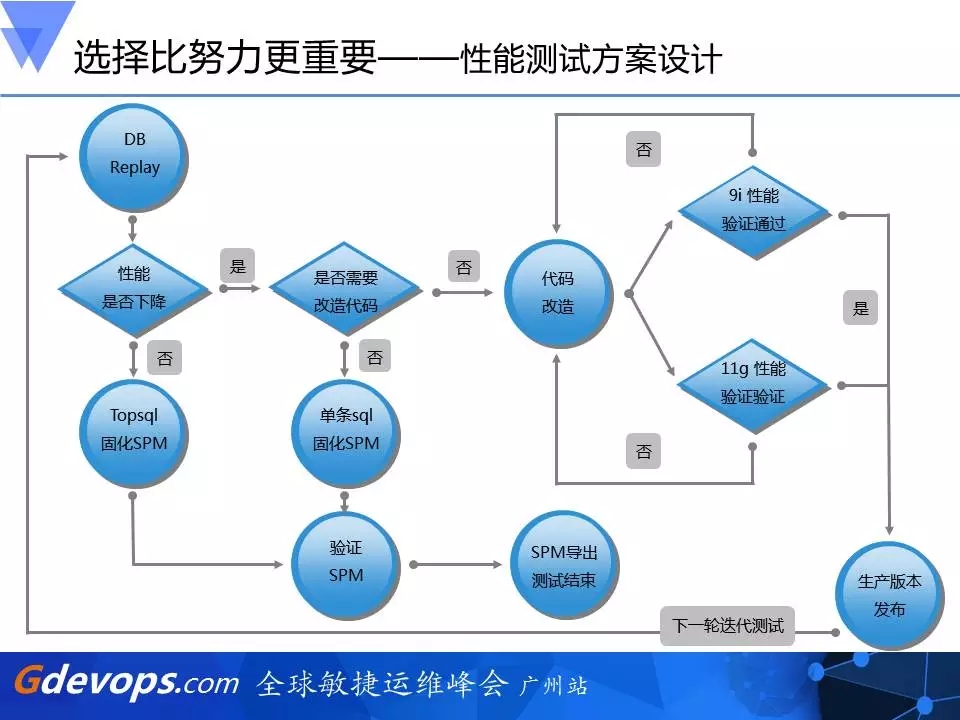
第三个就是性能测试,这是最复杂的地方。我们利用DB Replay抓取9i的负载在11g的环境去重现,那性能的好坏怎么判断呢?我们先在11g的环境里面去回放这个负载,看它的性能是否下降,如果没有下降,我们就会把这些Top SQL抓起来,用11g的另外一个新特性,叫SQL plan management(简称SPM),去把它的执行计划固化下来。
固化之后,我们会将这些SQL的执行计划导入到11g的生产环境中,保证在系统升级前后生产计划是没有改变的。如果是性能下降,假如不需要通过代码改变就可以进行优化的,我们会通过DBA、开发人员等人工优化,把它也用SPM固化下来,同样导入到生产环境。对于那些没有办法简单地加Hint或通过改变关键字次序等进行调优的代码,就需要开发参与进行代码的改造。当开发修改代码时,也是要两边调度,同时在9i和11g的版本上进行性能验证,两边都验证通过之后才能导入生产。
5、投产上线架构设计
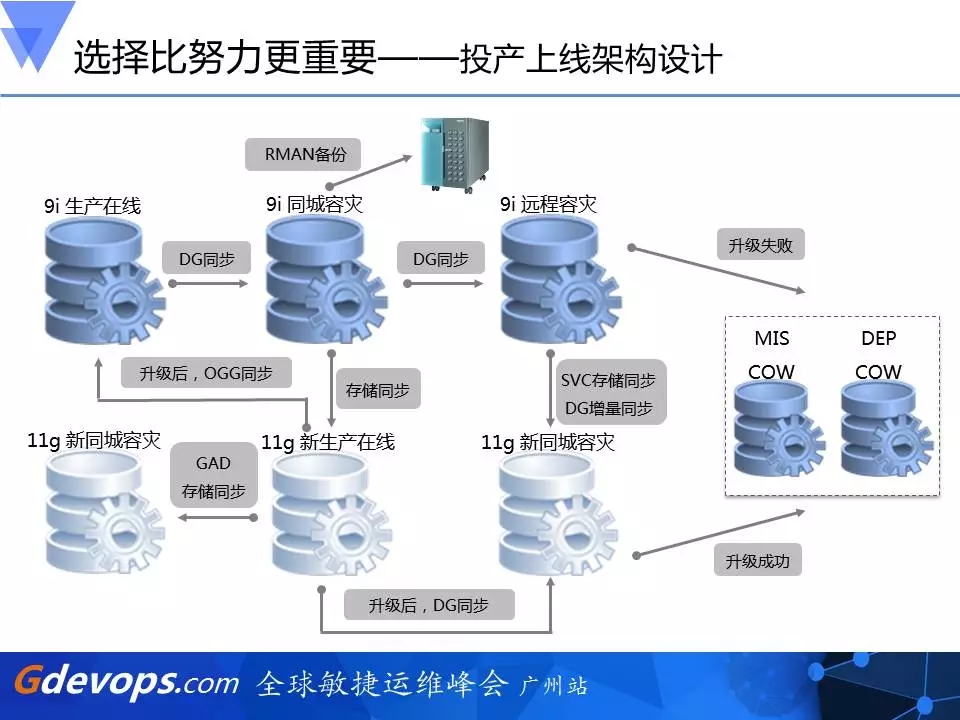
这是整个投产方案的架构设计,看起来比较复杂。我们提用了两套完全一样的架构,9i里面有同城的DG,也有远程的DG,因为这个数据库太核心,太重要了。同样的,在升级过程中,我们不允许出一点差错,所以在11g的投产环境中也有完整的一套11g的预投产、预生产环境,它的同城DG、远程DG是完全一样的。
这里面用了三种不同的存储技术。第一种存储技术就是11g新生产环境是和原来9i的同城容灾是做存储层面的同步,即存储LUN级别的同步;第二种存储技术是利用HDS的一种GAD存储同步技术,使11g新生产和11g新同城容灾不断地在做数据同步,第三种存储技术是9i远程容灾与11g新同城容灾之间通过SVC实现存储同步,而这11g新同城容灾也就是用于将来的11g的远程容灾环境。
我们还有MIS COW以及DEP COW的补充,用于获取一些数据采集产生一些报表,所以这里面用了很多种技术,目的就是不去在一个完整的环境中去做升级,也就是说我们不会先去升生产再去搭建一套同城容灾、远程容灾,因为这样的过程中产生的一些RPO、RTO和风险是无法规避的。
6、投产实现方案设计
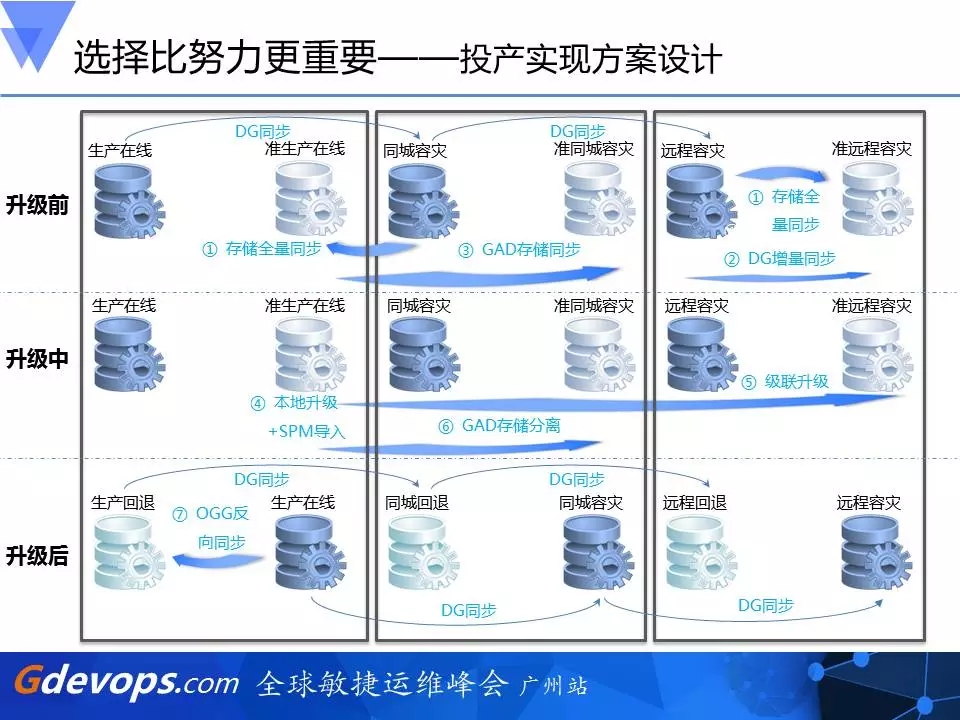
我们刚开始就已经在做存储全量同步,然后也用了HDS GAD在做存储同步,远程容灾用了SVC存储同步,升级中我们会把它进行一个存储的分离,然后本地升级,把刚才提到的一些SPM去导入,然后远程容灾是通过级联升级,这样我就会在升级以后出来两套,一套是9i的环境,一套是11g的环境。升级后我们会把11g产生的数据改变通过OGG同步到9i,所以在任何情况下都可以去回退,而且是完整环境的回退。
三、十月磨一剑
1、性能分析迭代
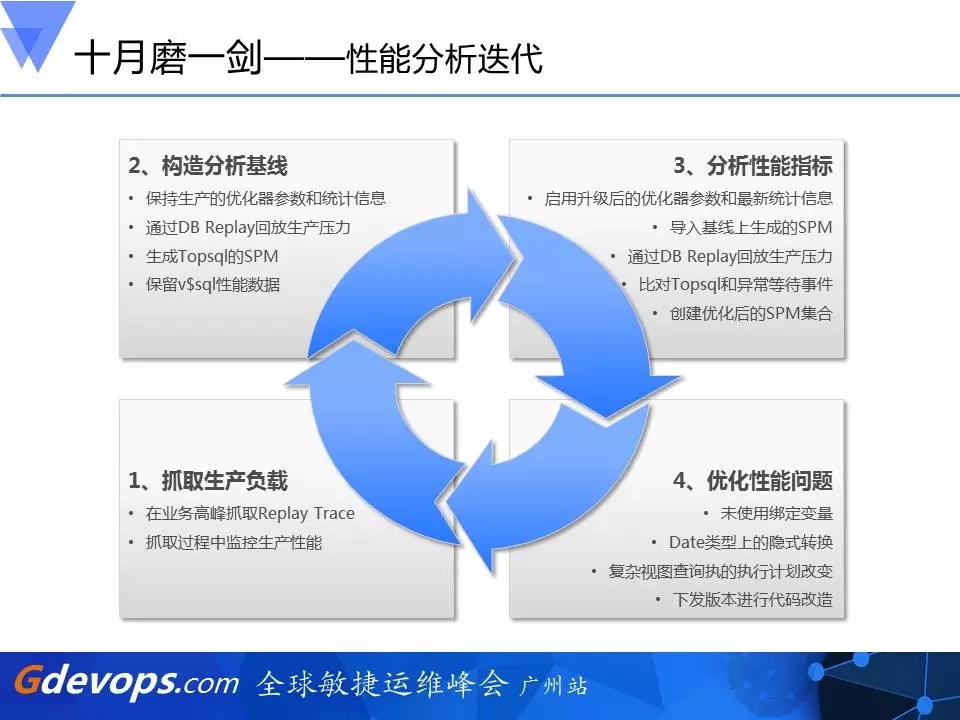
这个过程中,我们用了半年,在这半年的时间里,我们首先要构造分析基线,也就是刚才提到的——用DB Replay去回放生产压力。第一步,我们是在11g的环境里把它的优化器参数和统计信息仍然保留9i的,那么SQL相当于在运行在9i的环境中产生执行计划及执行情况(因为这是跟当前运行9i的生产环境最接近的),我们会抓取一个基线,并会把它的Top SQL拿下来。
接下来,我们会把11g环境里面的优化器参数和统计信息修改成11g的,再去回放一次负载,比较两方面的差异,也把它的Top SQL抓取下来,我们这时候也用到SPA,即Oracle RAT中的一个组件SPA(sql performance analyze),DB Replay在整个过程中的作用是回放整个负载,可以观察数据库有没有异常的等待事件,有没异常消耗高的SQL等,让你从整体上去判断。而SPA,是帮你逐条分析SQL,执行计划有没有改变,如果有改变,它的buffer gets是升高还是降低,CPU TIMES是升高还是降低等。如果它的性能下降了,是由于什么原因,这些就需要你做进一步深入分析,也就是说Oracle RAT的两个组件SPA和DB Replay在这期间发挥着不一样的功能。
在抓取了这些SQL之后,我们就要逐条、逐条地去看,包括一些去重,因为数据量太大了,最初抓取过来的有50多万条SQL,去重后还有14万条,后面我们把这14万条再去分类,该给开发的就给开发,该给DBA的就给DBA去优化,一层一层的优化,才能保证最后上线投产的顺利进行。当我们非常有把握或者性能非常稳定的时候,才会去投产。也就是说,我们总共分析了14万条。
2、绑定变量改造

关于SQL语句呢,我不细讲,这里提几个点和例子。首先是绑定变量,就像刚刚提到的固化执行计划是需要已使用绑定变量的,否则它每条SQL语句都不一样,这些SQL也就无法共用固化过执行计划,在这过程中我们发现很多这类的SQL语句。尤其在in里面非常多,要么就是跟个数不一样,要么就是值输入不一样,两种情况都可能导致固化过的执行计划发挥不了作用,而这类SQL无法简单地改造成绑定变量,所以我们进行了改写,以保证我们通过SPM固化执行计划达到固化的效果,第一是改写成绑定变量,第二是将IN写法改写成union all这种写法。通过这两种手段,来去优化它的SQL语句。
3、隐式转换改造

第二个例子是隐式转换。这是因为ibatis有个类型Timestamp与数据库中的字段类型不一样导致的,我们也是进行了一些优化。通过在应用代码中增加cast函数来降低数据精度,并在长期方案中,针对date类型,应用必须传入string格式,并在XML中使用to_date()函数进行转换。
4、复杂视图改造

第三个例子是复杂视图。在9i的时候, filter条件可以先在VIEW上过滤再和其他表关联,但11g必须先实例化VIEW,再进行filter条件过滤,对此,我们在v$sql中查询VIEW相关的代码,同时将VIEW拆开,分别和VIEW之外的表进行关联查询,最后再合并结果集。
这是几个比较典型的案例。
四、最终的决战时刻
1、投产组织工作

做了这么多,耗时6个月,最终的决战时刻终于到来!这中间涉及到很严密的组织架构。有总指挥,然后运营团队和业务团队怎么去配合,运营团队怎么做好深度监控、怎么通知业务团队准备好升级后的验证,如果发生问题,应该怎样去做回退决策,都有哪些人员当时投产、包括投产后要到场值守,这些都要做好。还有要事先做好升级的序列和决策点,哪些点是必须要决策回退,以及性能监控的指标和频率的提前制定。
2、投产人员架构
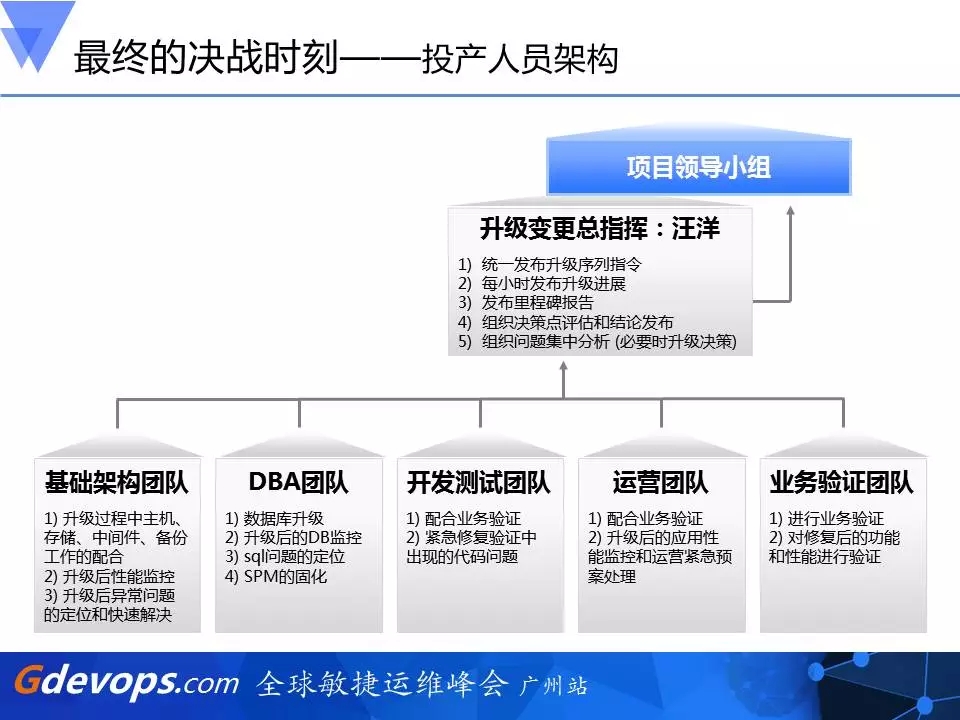
本次升级变更的总指挥就是我,当时从最早的解决问题到最终的投产成功,我有60个小时没有睡觉。基础架构团队,像刚才提到的,有主机和存储的配合。还有DBA团队、开发测试团队、运营团队、业务验证团队,大家都是“拧住一股绳,心往一处使”,才能让这个“只许成功,不许失败”的项目务必成功。我们只能接受一次失败,不能接受第二次失败。
3、投产前小插曲

然而,即便我们考虑得非常周密,在投产前还是出了小小的插曲。在投产前的72小时,本来我们是想跟生产环境做存储同步的,即11g新环境是跟9i生产环境同步的,并且存储技术已跟厂商确认过没有问题,而且我们还怕影响白天的业务,专门计划存储层数据同步在第一天先做一半,等到第二天过了白天业务的高峰后,晚上再拉起来,用两个晚上完成存储同步,这也和厂商确认过,他们也觉得没问题,但还是发生了问题。后来临时改变方案,我觉得这也是敏捷运维的一个思想,改为从同城容灾进行存储全量数据同步,这样就对生产环境没有影响,但我们的方案就变得更加复杂。这是第一个小插曲。
另外一个是在投产前的32小时,发生了一个大的事务在运行。没有人能评估出这个事务还有多少时间可以结束,那怎么办?只能当机立断去kill这个事务。这个事务当时产生了很多的回滚,回滚是需要时间的,根据当时的速度需要98个小时,但离升级还只有32小时,根本来不及。我们整个准备了半年的升级一年就只有这么一次,如果错过了,就相当于今年的升级就要告吹了,而以后也仍按照3T的速度来增长,也不太可能再做这个升级。这也是我为什么60个小时不睡觉的原因。升级部门到了总部,告诉我,必须等到事务回滚完才能升级,因为采用的是本地升级。他没给出什么方法,我这边无论是调回滚的定期发布,还是调一次回滚的安全数,在别的数据库里面都是有效的,但对这个数据库完全没效。
最后我发现它主要的问题出在db file sequential read上,怎么办?发现它在回滚的过程中有一个materialized view log,而这个materialized view log所有数据文件只在一个存储卷里。在这一个卷上我想到用FLASH闪存去替换这一个存储卷,但这需要冒很大风险,和第一个我刚刚提到的存储同步故障是有关联的,第一个已引发了生产故障,然后这个又要在这个生产环境上去做存储同步,这甚至是冒着被炒鱿鱼的风险,我没有告诉其他人,自己做的这个决策。我觉得做领导就该这样,你只要勇敢做,并敢于承担。
所以,将物化视图所在的文件卷替换成Flash闪存,加快db file sequential read的效率后,最终发现回滚速率提升了5倍。同时连夜把一些存储的同事从凌晨三点钟叫到公司,启用存储Cache预热功能,将物化视图和物化视图log缓存到内存中,发现回滚速率又提升了3倍。终于赶在升级前的6个小时,回滚完毕,来得及去做升级这个动作。
4、投产运行分析

最终在投产后,所幸实施过程是非常顺利的。在投产后,高峰期业务吞吐量整整提升了大概25%,批量作业效率提升了5-25倍不等,系统前端响应时间平均提升30%以上,单个SQL效率提升5-9000倍不等。主机的CPU运行从升级前的60%,有时业务高峰甚至达到70-80% ,现在升级后CPU运行在20-30%左右。整个效果看起来还是非常好的。
小结
通过本次升级我想说的是,这里面用到的一些思想和方法,其中包括一些敏捷运维的思想,是可以借鉴到以后同类数据库产品的升级,也可以用到其他的如主机、存储等领域的变更或更新换代。这就是我全部的分享,希望能对大家有所启发。
PPT下载链接:http://pan.baidu.com/s/1hrW91bu
看完本文意犹未尽?










如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721