
作者介绍
梁敬彬,福富研究院副理事长、公司唯一四星级内训师,国内一线知名数据库专家,在数据库优化和培训领域有着丰富的经验。多次应邀担任国内外数据库大会的演讲嘉宾,在业界有着广泛的影响力。著有多本畅销书籍,代表作有《收获,不止SQL优化》等。
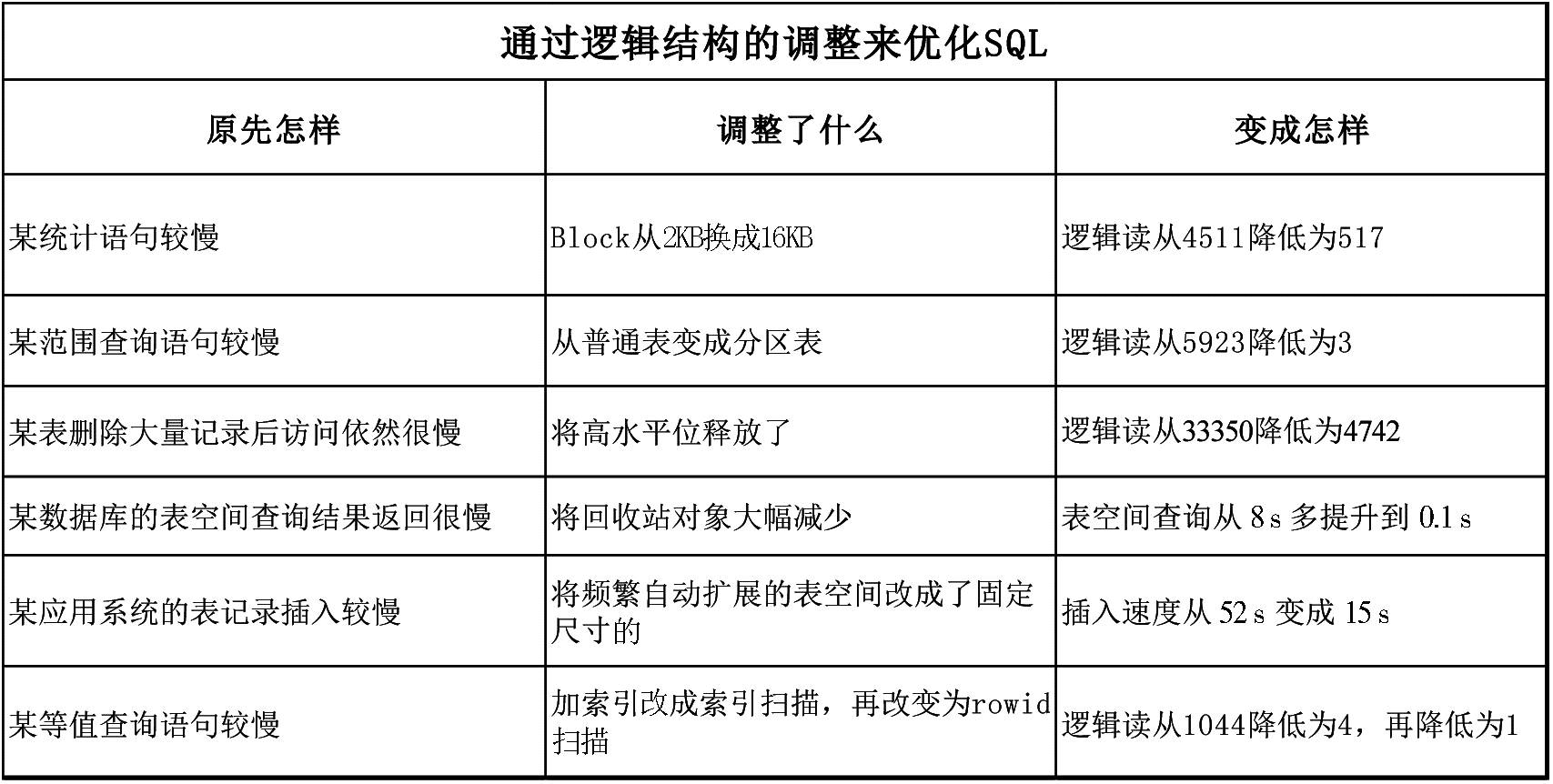
逻辑结构与SQL优化之间的关系是大部分人容易忽略的,本章我们先从简单的逻辑结构知识开始介绍,接下来对所有可能和SQL优化有关的逻辑结构的细节做进一步的描述。
随后就是案例剖析环节,在该环节让读者真真切切感知到逻辑结构在影响着工作中的各种场景。最后是思考回顾。本章总体学习思路如下图所示:

Oracle的逻辑结构是一种层次结构。主要由表空间、段、区和数据块等概念组成。逻辑结构是面向用户的,用户使用Oracle开发应用程序使用的就是逻辑结构。数据库存储层次结构及其构成关系,结构对象也从数据块到表空间形成了不同层次的粒度关系。如下图所示:

数据库(DATABASE)由若干表空间(TABLESPACE)组成, 表空间(TABLESPACE)由若干段(SEGMENT)组成,段(SEGMENT)由若干区(EXTENT)组成,区(EXTENT)又由Oracle的最小单元块(BLOCK)组成。
逻辑体系结构和SQL优化是息息相关的,下面我们从块、段、表空间、rowid等维度来进行阐述,具体如下图所示:
 Block最多能装多少行
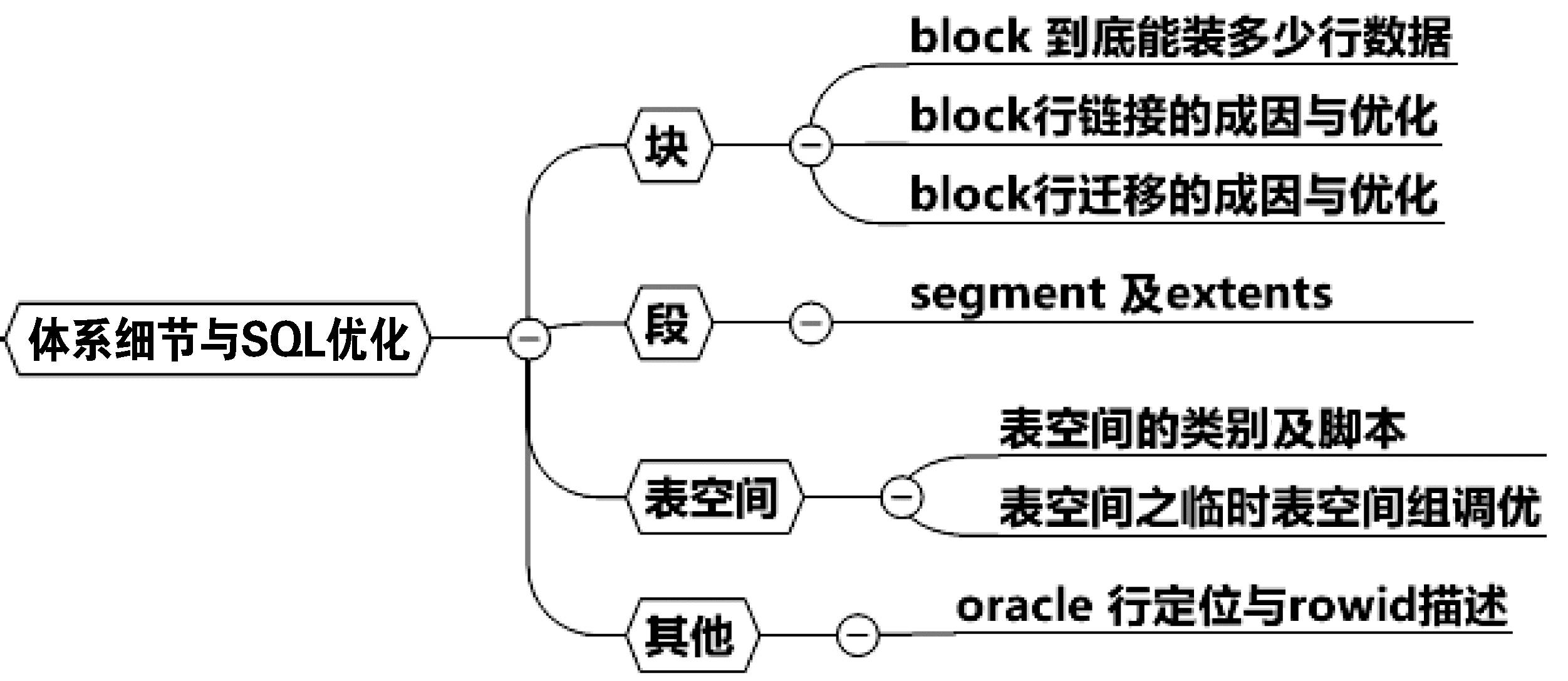
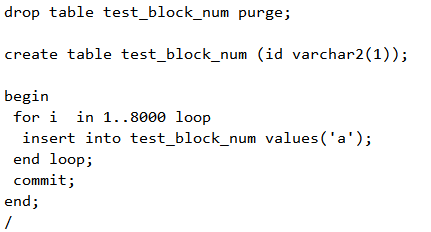
Block最多能装多少行一个8KB的块其最大可用空间有8096字节,如果一个字节装一行的数据,能否插入8000行呢?我们做些试验看看。首先是构造环境,如下:
接下来我们通过调用dbms_rowid包来研究块到底能装下多少行数据。
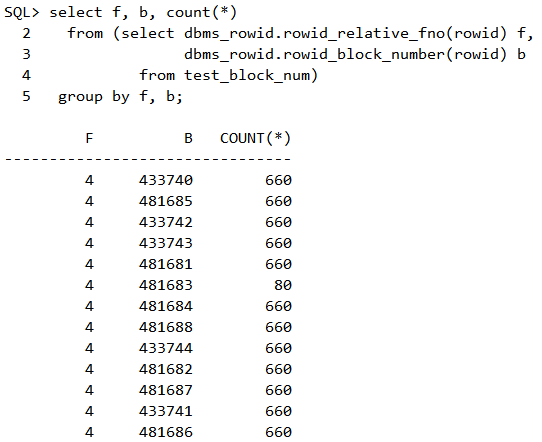
脚本1 研究块究竟能装多少行数据
试验结论:各种开销导致每行的最小长度大致为11字节,一个8KB的块理论上最多存储不超过(8096/11=736)行。果然上述都没有超过这个736。
 Block行迁移的成因与优化
Block行迁移的成因与优化行迁移优化前,看看如下语句逻辑读情况:
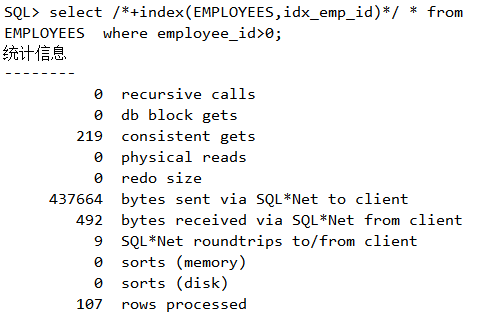
行迁移优化后,再看看如下语句逻辑读情况:

逻辑读从原来的219下降到116,性能明显提升。
具体试验步骤如下:

脚本2 行迁移优化前后的测试脚本
 Block行链接的成因与优化
Block行链接的成因与优化行链接一般来说无法避免,要通过增大数据块的方式消除(请注意脚本中的TBS_LJB_16K是一个BLOCK为16KB的表空间),试验如下:

脚本3 行链接消除的试验
建一个T表就产生了表段、T段(SEGMENT),请观察区(EXTENT)及块(BLOCK)的个数。建一个索引IDX_OBJ_ID就产生了索引段,IDX_OBJ_ID段(SEGMENT)和表的情况类似,试验如下:
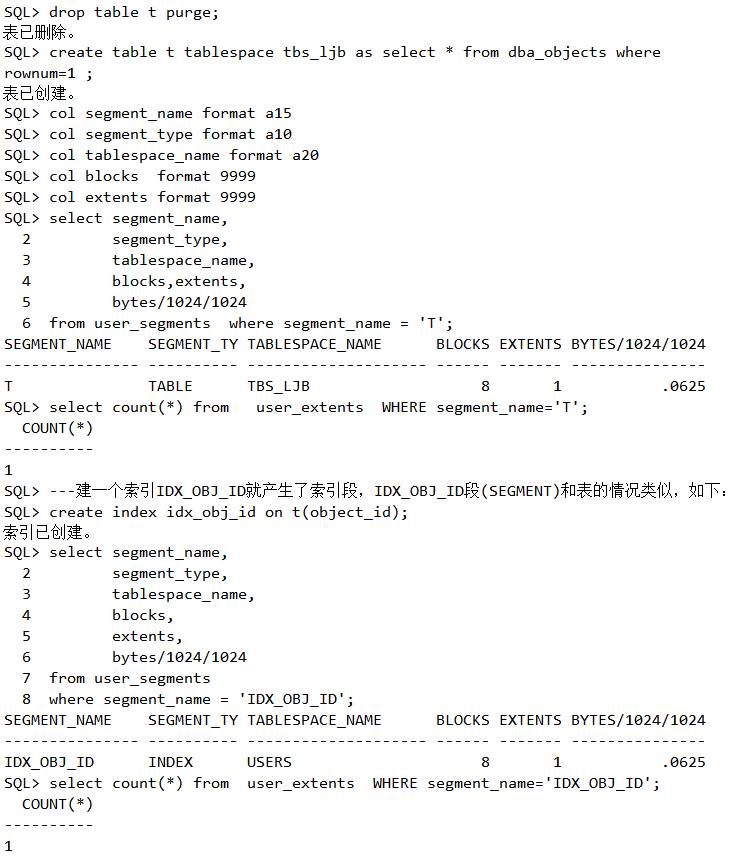
脚本4 体会segment与extent的试验
随着表记录的增加,表对应的Extents及Blocks的个数也不断增多。随着Idx_obj_id不断增大,索引对应的Extents及Blocks的个数也不断增多。如下:

脚本5 体会Extents及Blocks的增多
查看表空间的总体情况:

脚本6 查看表空间大小
rowid一般由18位组成,如OOOOOOFFFBBBBBBRRR,O是对象ID,F是文件ID,B是块ID,R是行ID。(注:Oracle 8以上)。
rowid为一行的物理地址,当一行插入数据库块后,rowid就唯一了,除非行物理移动,否则不变。
rowid不真正存在表数据块中,但是会存在索引中,方便根据索引中的rowid找到表数据。

脚本7 对rowid的体会与实践
前面大家对逻辑结构有了一些直观的认识,接下来,我们来看看在现实应用中,如何巧妙地利用逻辑结构的块、段、表空间的一些知识和业务场景来进行SQL优化,让SQL跑得更快。如下图所示:
环境准备(分别构造出BLOCK为2KB、4KB、8KB、16KB的4个表空间):

脚本8 构造4个BLOCK大小不同的表空间
结果利用4个不同的表空间执行相同数据量的相同SQL语句,发现性能有差异,首先是2KB的表空间情况:

脚本9 BLOCK为2KB的SQL性能
4KB的表空间情况:

脚本10 BLOCK为4KB的SQL性能
8KB的表空间情况:

脚本11 BLOCK为8KB的SQL性能
16KB的表空间情况:

脚本12 BLOCK为16KB的SQL性能
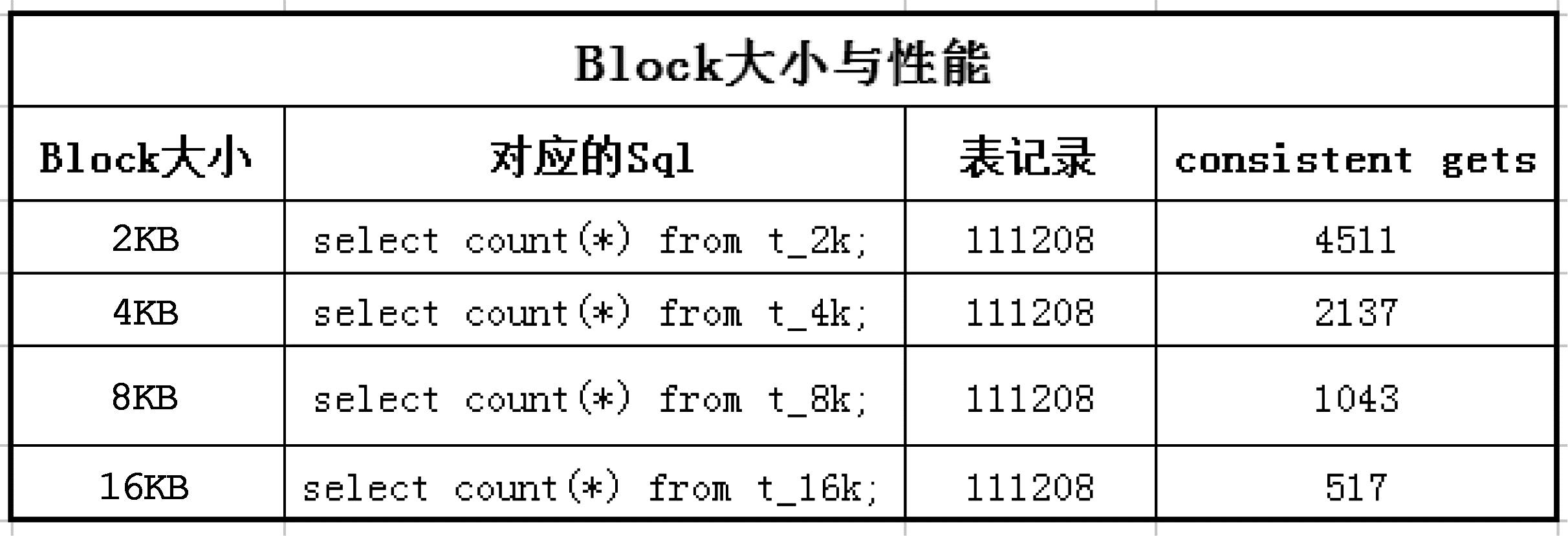
不过要切记,实际情况并非BLOCK越大越好,因为BLOCK越大,不同的人访问不同的数据落在同一个BLOCK的概率就大大增加,这就容易产生热点块竞争,因此在OLTP系统里BLOCK过大是不适合的,但是在OLAP系统里,BLOCK大还是比较有用的!
 segment之分区表的化整为零优化
segment之分区表的化整为零优化
普通表由单个段组成。可以将分区表理解为人们想把这个单个段切割成多个小段,如果访问能落到具体的某个小段里,则不要去理会别的小段,这样访问路径大幅度减少了,性能自然就增强了。请看下面的分段情况:
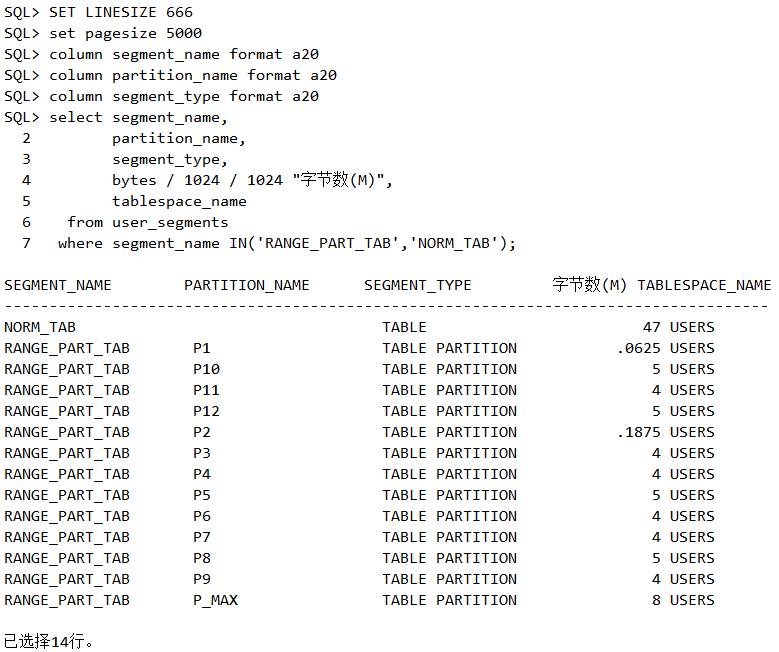
脚本13 分区表的分段
接下来具体地查询通过range_part_tab 表访问的执行计划,发现出现Pstart 和Pstop,由此我们就看得一清二楚了,访问只落在了第9个段里,也就是第9个分区中。
普通表全扫描
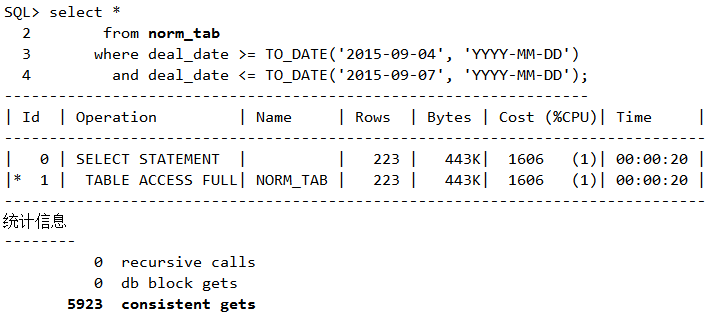
脚本14 普通表的全表扫描
分区表局部扫描
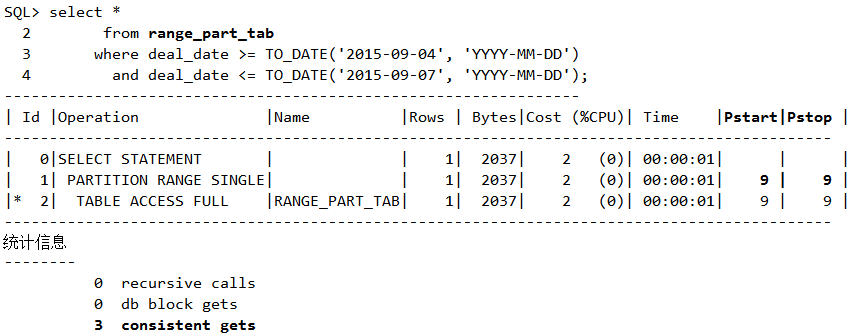
脚本15 分区表的局部分区扫描
数据量相同,SQL语句相同,就是表结构不一样,逻辑读从5923迅速下降到3,性能大幅度提升。
 segment之高水平位相关排查优化案例
segment之高水平位相关排查优化案例

未删表记录前逻辑读巨大

脚本16 未删除表记录前逻辑读巨大、
删大量记录后逻辑读不变
接下来删除大量数据,发现SEGMENT未见减少,依然是264,关键是,表记录少了这么多,逻辑读依然不变,还是33350,如下:

脚本17 删大量记录后逻辑读不变
释放高水平位后性能飞跃
这就是高水平位的问题,用move重组数据后,高水平位释放,情况即将发生大变:

脚本18 释放高水平位后性能飞跃
逻辑读从原先的33350降低为4742,性能大幅度提升!
 segment之高水平位情况监控
segment之高水平位情况监控
接上面的问题,你在优化SQL的时候,你是如何知道系统中存在大表记录删除后,高水平位依然没释放的问题呢?
num_rows和blocks的正常比例
我们来构造一组试验,看看正常情况下从user_tab_statistics获取到的num_rows和blocks的正常比例,如下:
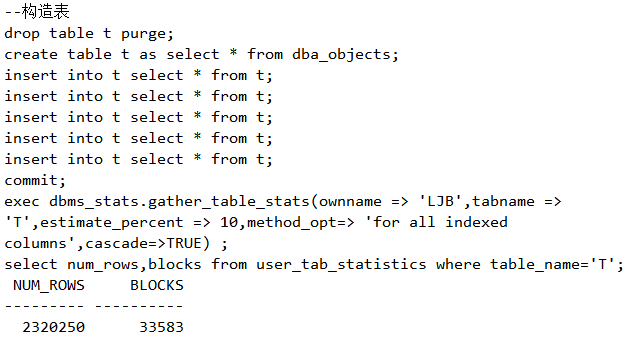
脚本19 num_rows和blocks的正常比例
这里看出,num_rows是2320250,而blocks是33583。2320250/33583大致为70左右,表示70行装一个块,还算合理。
num_rows和blocks的异常比例
当删除了大量数据之后,情况又是如何呢?请继续看试验,如下:

脚本20 num_rows和blocks的异常比例
现在num_rows是32780,而blocks是33583,大致一行装一个块,这显然是不太可能的!
3、表空间的案例
 表空间查询慢与回收站关系
表空间查询慢与回收站关系
有一个案例,查询表空间语句非常慢,后来被查是由于回收站对象过多却没有释放的原因。这其实是Oracle执行计划中的一些Bug,在Oracle 查询表空间时,基表的查询主要是通过NL连接,对象过多则导致性能缓慢。具体细节就不说了,我们构造一个试验,让有兴趣的读者自行去体会。
首先是先建1000张表,如下:

脚本21 构建1000张表
接下来通过执行exec p_create_tab完成建表1000张,并执行查询表空间语句,发现速度非常快,仅0.12s,如下:

脚本22 查询表空间速度很快
但是再执行exec p_drop_tab;drop这1000张表后,速度一下子就慢了(因为回收站里有太多对象了),花了8s多,如下:

脚本23 drop大量表后,查询表空间速度变慢
 表空间频繁扩展与插入性能
表空间频繁扩展与插入性能
环境搭建:分别建2个表空间,一个是固定尺寸的,另一个是自动扩展的,再分别在两个表空间上建相同结构的表,如下:

脚本24 分别建固定尺寸和自动扩展的表空间及对应表
开始试验,分别往这两个表中插入数据:

脚本25 分别往两表插入相同量的数据
我们惊奇地发现,往固定尺寸的表空间的表中插入数据花了15s,而往自动扩展的表空间的表中插入数据居然花了52s!其本质原因就在于表空间初始分配的空间很小,而且每次新增的尺寸也很小。导致系统不断分配空间,自动扩展,多做事了。通过接下来的查询也可以一目了然地看出这一点,如下:

脚本26 两表的extent数量差异显著
T_A表申请空间分配有3610次之多,而T_B表仅100次,性能差异能不大吗?
 rowid
rowid
环境搭建,比较三种扫描方式的性能差异。

方法1(全表扫描)
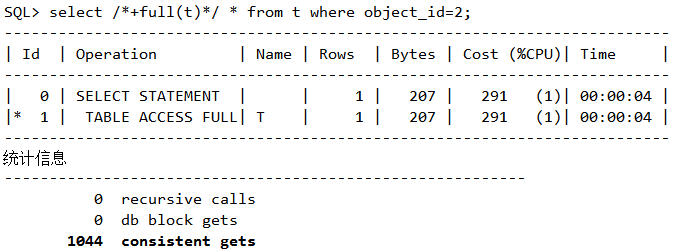
脚本27 三种扫描方式之全表扫描
方法2(索引扫描)
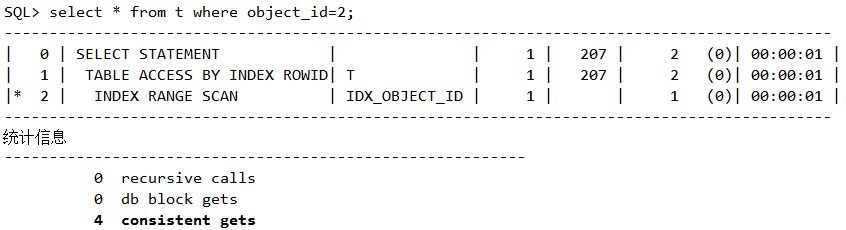
脚本28 三种扫描方式之索引扫描
方法3(rowid扫描)

脚本29 三种扫描方式之rowid扫描
 小结
小结








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721