
作者介绍
曹洪伟,70后老码农,全栈工匠一枚,服务过多家世界500强,后连续创业,现任渡鸦科技CTO,致力于人工智能硬件,维护有“wireless_com ”公众号 和博客。
本文节选自《深入分布式缓存》一书,作者:于君泽、程超、邱硕、曹洪伟、刘璟宇、张开涛、何涛、宋慧庆、陈波、王晓波。
在互联网技术中有两大支点,其中一个就是缓存,而分布式缓存系统更是大型互联网应用的利器。面对不断增长的海量数据、不可预知的流量模式以及快速响应时间的需求,这正是云计算服务的动态性之关键优势。
那么,当云服务融入分布式缓存系统架构,会碰撞出怎样的火花呢?
大型互联网应用中的缓存
先回顾一下缓存在大型互联网应用的架构(如图1),网站在发展的历程中,业务量的增长是幸福的烦恼,而缓存技术就是解除烦恼的灵丹妙药,能够再次理解为什么是缓存为王。

图1 缓存在大型网站系统中的应用
实际上,这时的系统进入了无级缩放的大型网站阶段,当网站流量增加时,应对的解决方案就是不断地添加Web 服务器、数据库服务器以及缓存服务器了。如何动态的增减服务器,这正是云服务的用武之地。
云服务的优势
对企业而言,云服务有着诸多的商业优势。
首先,企业的前期基础设施投资几乎为零。如果要建立一个大型的系统,可能需要大量的投资用于于机房、硬件(机架、服务器、路由器、备用电源)、硬件管理(电源管理、散热)和运维人员。由于高昂的前期成本,该项目通常在开始之前需要多轮的管理审批和论证。而采用公有云服务,几乎没有固定成本或启动成本。
其次,云服务提供了基础设施即时性。在过去,当互联网应用开始大规模上量时,如果基础设施跟不上规模的增长,将会极大地影响应用的成功。但如果前期投入了大量资金,而应用没有得到普及,基础设施又将成为失败的牺牲品。云服务增加了灵活性,降低了风险和运营成本,可以根据用于成长的规模而按需付费。
最后,云服务可以更有效地利用资源,根据使用状况来计算成本,同时缩短产品的上市时间。
云服务的技术优势同样明显,主要的特点如下:
自动化:基础设施的脚本化可以通过充分利用API对基础设施编程,完成构建和系统部署的可重复性。
自动扩展:无需任何人工干预,就可以根据需求对应用进行双向扩展。自动缩放提高了自动化程度从而更加高效。
主动扩展:基于需求预期和流量模式的合理规划,可以对应用进行双向扩展让从而保持低成本运营。
更有效的开发周期:可以很容易将开发和测试环境复制到生产系统,不同阶段的环境可以很容易地推广到生产系统。
改进的可测性:不需要进行硬件过载的测试,注入和自动化测试能够持续于开发过程的各个阶段。
灾难恢复和业务连续性: 云服务为维护一系列应用服务器和数据存储提供了低成本选择。使用云服务,可以在几分钟内完成将某一地点的环境复制到其他地域的云环境中。
云服务的选择有很多,如阿里云、百度云、腾讯云等,但AWS作为云服务的商用鼻祖,有着很多独特的特性和广泛的应用。AWS云服务以最小的支持和管理成本,通过高度可靠和可扩展的基础设施,提供了Web应用部署的解决方案,其灵活性远高于自建的基础设施,无论这些设施是企业内部的部署环境还是在数据中心设施。
EVCache:基于云服务的分布式缓存系统
云服务不仅为软件系统的开发和部署带来了更多的敏捷性,而且提供了更多创新的可能性。AWS云服务与分布式缓存服务系统相结合就产生了一些杰出的技术方案,一个典型的案例是Netflix的EVCache。
EVCache 是一个开源、快速的分布式缓存,基于 Memcached的内存存储和 Spymemcached 客户端实现的解决方案,主要用在亚马逊弹性计算云服务 (AWS EC2)的基础设施上,为云计算做了优化,能够顺畅而高效地提供数据层服务。
EVCache 是一个缩写,包括:
Ephemeral: 数据存储是短暂的,有自身的存活时间。
Volatile: 数据可以在任何时候消失。
Cache:一个内存型的键值对存储系统。
EVCache实现的主要功能包括分布式键值对存储、AWS的跨区域数据复制以及注册和自动发现新节点或新服务。EVCache典型的应用是对上下文一致性要求不高的场景,其可扩展性已经可以处理非常大的流量,同时提供了健壮的API。
Netflix 是微服务架构领域的实践者,在系统中布署了上百个微服务,每一个微服务只专注做一件事情。这使得Netflix所提供的软件系统能够做到高度均衡和松耦合。由于状态都存储在缓存或持久存储中,所以这些微服务大多数是无状态的,易于自动扩展。
EVCache在Netflix内部是一个被广泛使用的数据缓存服务,所提供的低延迟且高可用的缓存方案可以很好地满足Netflix微服务架构需要,也用来做一般数据的存储。EVCache 能够使面向终端用户的应用,个性化算法和各种微服务都具备优良的性能。
EVCache 具有如下的特性:
分布式的键值对存储, 缓存可以跨越多个实例
数据可以跨越亚马逊云服务的可用区进行复制
通过Netflix内部的命名服务进行注册,自动发现新节点和服务
为了存储数据,键是非空字符串,值可以是非空的字节数组、基本类型或者序列化对象,且小于 1 MB
作为通用的缓存集群被各种应用使用,支持可选的缓存名称,以命名空间避免主键冲突
一般的缓存命中率在 99%以上
与Netflix 驻留数据框架能够良好协作,典型的访问次序: 内存 ->EVCache -> Cassandra/SimpleDB/S3
EVCache客户端是一个Java的客户端,用于发现EVCache服务器并管理所有的增删改查(CRUD)操作,由客户端处理在集群中添加/删除服务器。基于亚马逊云服务可用区,客户端在执行创建、更新和删除操作的时候复制数据。
另一方面,客户端的读操作直接从同一可用区的服务器读取数据。图2展示了EVCache 的典型部署结构和单节点客户端实例与服务器的关系。
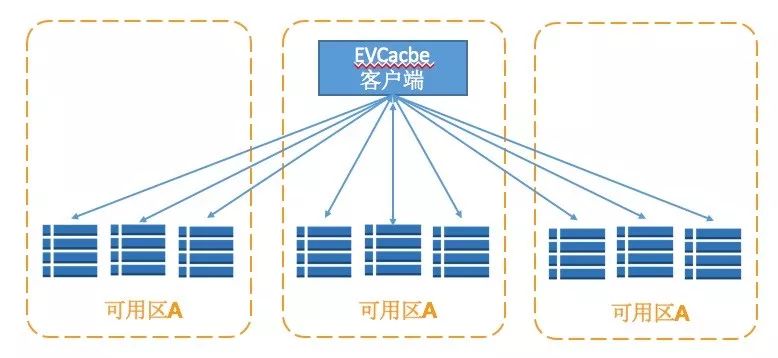
图2 EVCache单节点客户端实例与服务器的关系
一个EVCache客户端连接了多个EVCache的服务器集群。 在一个区域内,Netflix有多个全数据集的拷贝,由亚马逊云服务的可用区隔离开来。虚线框描述了区域内的副本,每个拥有数据的全量镜像,作为AWS的自动伸缩组来管理这些镜像。某些缓存在一个区域内有两个镜像,有的拥有更多。这种高层架构长期来看是有效的,不会改变,每个客户端连接自己区域内所有可用区的所有服务器。写操作被发往所有实例,读操作优先选择离读请求近的服务器。
Netflix的全球云服务遍布AWS各个服务区域,例如北弗吉尼亚、俄勒冈州和爱尔兰,为这些地区的会员提高就近服务,但网络流量会因为各种原因改变,比如关键基础设施出了问题故障,或者地区之间进行失败恢复的练习等,因此Netflix采用无态应用服务器服务于来自任何地区的会员。
这些数据如果从持久层存储获得将会非常昂贵(造成频繁的数据库访问),Netflix需要将这种数据写入到本地缓存,而且必须复制到所有地区的缓存中,以便服务于各个地区的用户请求。
微服务是依赖于缓存的,必须快速可靠地访问多种类型的数据,比如会员的观影历史、排行榜和个性化推荐等,这些数据的更新与改变都必须复制到全世界各个地区,以便这些地区的用户能够快速可靠地访问。
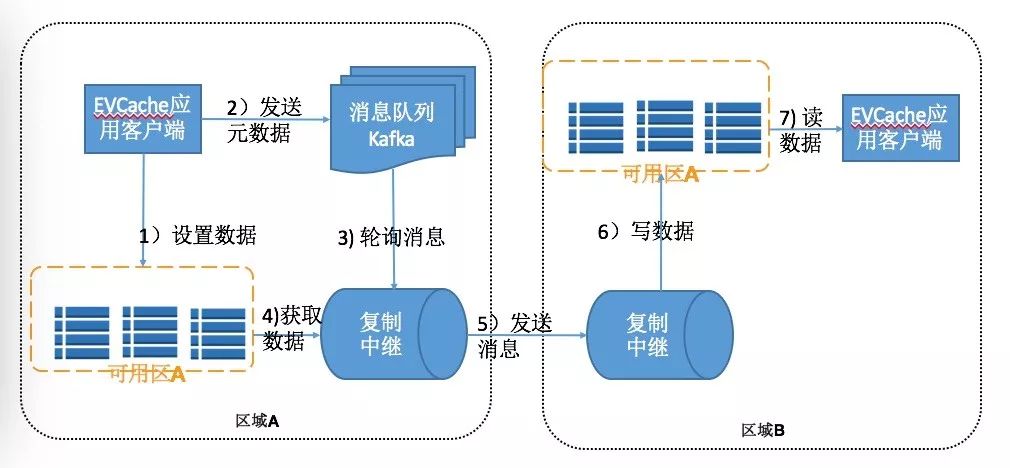
图3 EVCache 跨地域的数据复制
这张图说明复制操作是在SET操作以后实现,应用程序调用EVCache客户端库的set方法,之后复制路径对于调用者是透明的:
EVCache客户端库发送SET到缓存系统的本地地区的一个实例服务器中
EVCache客户端库同时也将写入元数据(包括key,但不包括要缓存的数据本身)到复制消息队列(Kafka)
本地区的复制中继服务将会从这个消息队列中读取消息
中继服务会从本地缓存中抓取符合key的数据
中继服务会发送一个SET请求到另一个地域的复制中继服务
在另一个区域中,复制中继服务会接受请求,然后执行SET操作到它的本地缓存,完成复制
在接受地区的本地应用当通过GET操作以后会在本地缓存上看到这个已经更新的数据值
这是一个简单描述,需要注意的是,它只会对SET操作有效,对于其它DELETE TOUCH或批mutation等操作不会复制,DELETE和TOUCH是非常类似的,只有一点不同:它们不从本地缓存中读取已经存在的值。
跨区域复制主要是通过消息队列进行,一个地区的EVCache客户端不会注意到其它地区的复制情况,读写都是只使用本区域缓存,不会和其它地区缓存耦合,通过消息系统来解耦合。
AWS的每个区域一般由多个可用区(AZ)组成,而可用区一般是由多个数据中心组成。AWS引入可用区设计主要是为了提升用户应用程序的高可用性。因为可用区与可用区之间在设计上是相互独立的,也就是说它们会有独立的供电、独立的网络等,这样假如一个可用区出现问题时也不会影响另外的可用区。在一个区域内,可用区与可用区之间是通过高速网络连接,从而保证很低的延时。
EVCache实例通过将Amazon EC2放到多个可用区, 能够预防应用的单点故障。无论在相同的物理区域内还是在不同的物理区域之间,在多个AZ上运行独立的应用都是非常重要的。如果一个可用区失效了,在其它可用区上的应用可以继续运行,从而实现高可用性。
由于跨越了多个亚马逊云服务可用区,EVCache集群是不会挂掉的。当其中的实例偶然挂掉时,通过一致性哈希跨集群分片来使缓存的影响降到最低。
在保持高可用性的同时,操作EVCache集群的总体成本很低,因为缓存没有命中时访问亚马逊云服务服务的成本较高,如访问SimpleDB、AWS S3、EC2上的Cassandra等等。EVCache 集群的总体成本在高稳定,线性扩展的条件下还是令人满意的。
隐藏在需求后面的是数据或状态所需要的每个请求服务,必须是跨地区可用的。高可靠性数据库和高性能缓存是支持分布式架构的基础设施,一个典型场景是将缓存架构于数据库前面或其它持久存储前面。如果没有缓存的全局复制,一个地区的的会员切换到另外一个地区时,会在新的地区缓存中没有原地区的数据,这种情况称为冷缓存。处理这种缓存数据丢失的办法只有重新从数据库加载,但是这种方式会延长响应时间并对数据库形成巨大冲击,EVCache 除了跨可用区复制之外,还提供了跨区域复制,对基于AWS的高可用性进行了增强。
Netflix的用户体验重度依赖于大容量、低时延、全球可用的缓存数据层。例如,用户坐在沙发上看电影或者电视节目,在用户的每一次交互中都有缓存的身影,从会话存储到视频历史,到用户状态,都得益于EVCache的稳定和高容错性。
这里介绍一个典型的用例——向用户推荐与已看历史中节目类似的电影或者电视节目。图4 介绍了推荐相似性内容的服务流程以及EVCache在其中的作用。

图4 使用EVCache推荐相似内容的典型用例
内容相似性推荐服务给出了与已看历史中节目类似的电影或者电视节目的相似性列表。一旦计算出了相似性,就存储在SimpleDB/S3 中,前端使用EVCache。当任何应用或者算法需要这些数据的时候,可以从 EVCache提取数据,并返回结果。具体过程如下:
一个客户向Web应用发了一个页面请求,处理这一请求需要得到一个电影或电视节目的相似性列表
Web应用查询 EVCache 来得到这些数据,这样场景的典型缓存命中率高于99.9%
如果缓存没有命中, Web应用将调用相似性计算服务来计算这些数据
如果已经计算过的数据也没有命中的话, 相似性计算服务将从 SimpleDB中读取数据。如果在SimpleDB 没有,相似性计算服务根据给出的电影或电视节目重新计算相似性
相似性计算服务在计算出电影或电视节目的数据后,将数据写入到 EVCache中
最后,相似性计算服务生成客户端所需要的响应并返回给客户端
EVCache 是线性扩展的,通过容量监控,可以在一分钟内扩容,在几分钟内完成重新均衡和数据预热。







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721