
Oracle InnoDB团队
Principle Software Developer
曾任达梦、Teradata高级工程师,主要负责研发数据库执行引擎和存储引擎,十年以商数据库内核开发经验。
大家好,首先非常感谢社群的引荐,让我有机会在这里跟广大的DBA群友们交流。
今天的分享主要是针对MySQL5.7中InnoDB的新特性,InnoDB大家都应该非常熟悉,作为MySQL的存储引擎,而且现在变成默认的存储引擎,它为MySQL提供了强大的存储支持。伴随着MySQL从5.6演进到5.7,InnoDB 也有了一些新的变化。今天想跟大家分享的就是InnoDB在5.7中的这些变化。
我主要从性能和功能两大方面来给大家介绍:
1、性能提升(事务优化,临时表优化等)
2、新功能(透明压缩,加密,虚拟列等)
一、性能提升
首先,是性能方面。在5.7中,我的老板(大牛)做了一个很重要的工作,就是对InnoDB的事务(transaction)进行了优化。

在这方面他做的第一件事情就是创建事务池(Transaction Pool),这样就能减少很多事务创建和释放的开销。

他做的第二件事情就是优化了事务的生命周期管理。所有事务首先都默认为是只读事务,这样这些事务就不会和其他事务冲突,只有当此事务开始一个写操作时才认为它是一个读写事务。

另外,对事务的优先级也有了一些调整。
接下来我们看看经过这些修改之后,性能有些什么变化。
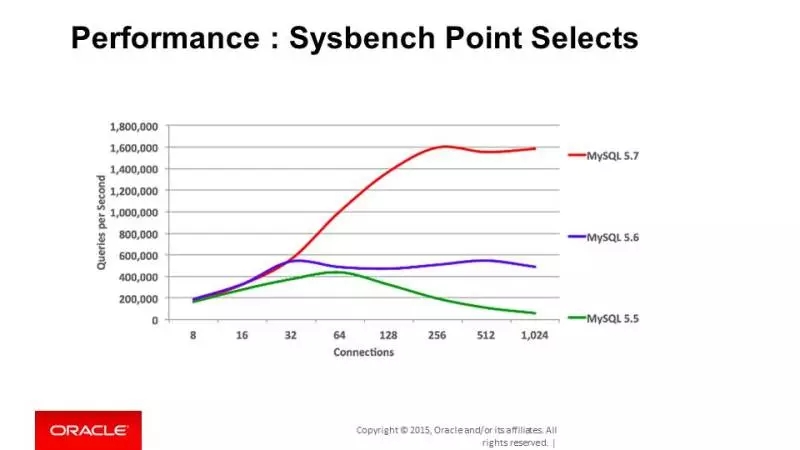
图上我们可以看到对于单点查询,sysbench oltp测试中,5.7可以达到1.6MQPS,比5.6有接近3倍的性能提升!
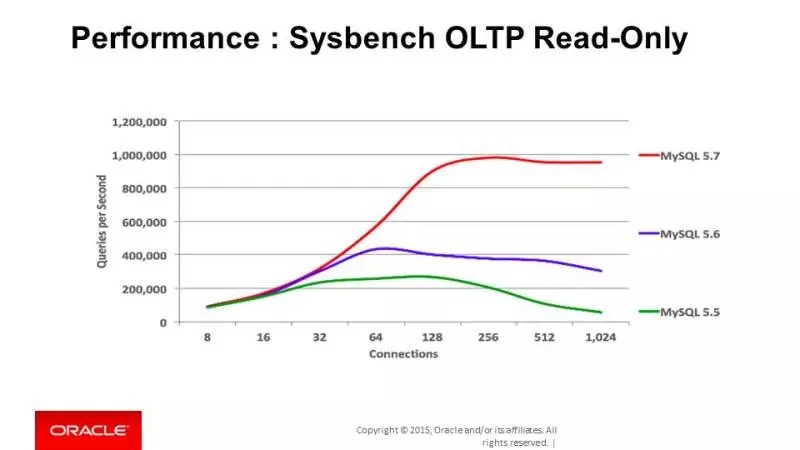
对于只读事务,我们用sysbench oltp测试下,5.7比5.6有超过一倍的性能提升!
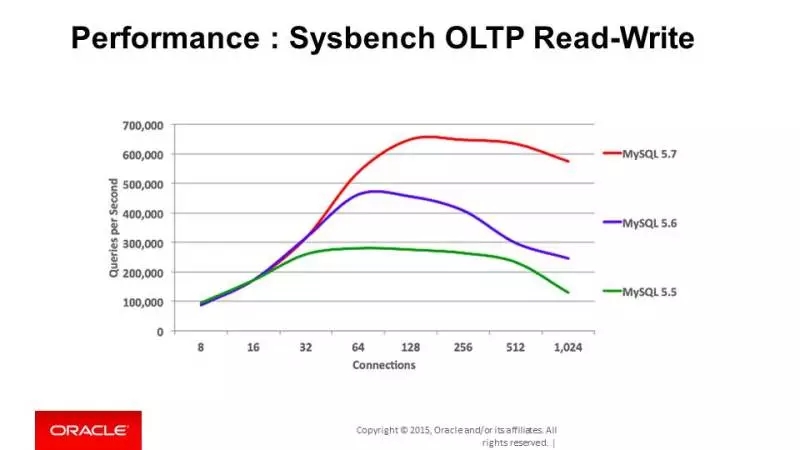
而对于读写事务,我们也有50%左右的性能提升。是不是很强劲?当然,这只是其中一项性能优化,接下来还有更精彩的。
我们在5.7中另一项重大性能优化是对临时表达优化。

在5.7中,我们将临时表从数据字典中分离出来,这样,临时表就不会跟其它正常表争抢数据字典的锁。同时,我们还将临时表的表空间跟普通表空间区别开来,以减少I/O的开销。

对于临时表的DML操作,我们只记录Undo日志,不记录Redo日志,因为,临时表不需要在Crash的时候Recovery,但是它需要rollback。这样也减少了大量的日志开销。
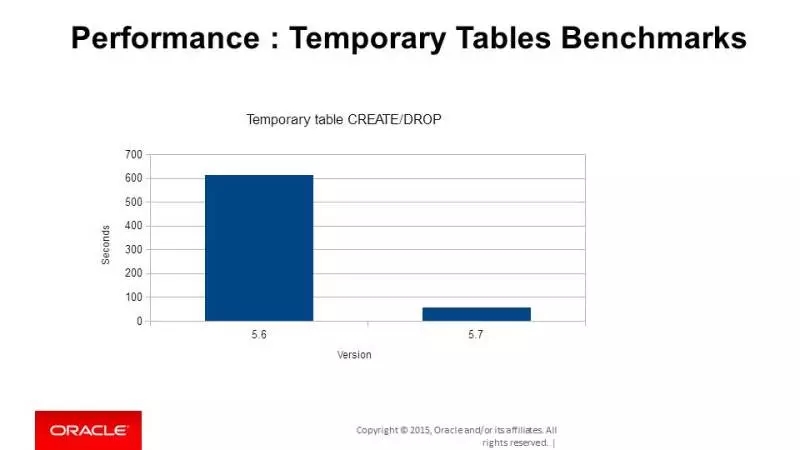
这张图显示了5.7的临时表create和drop的性能提升,这个应该是重复几万次create和drop所耗费的时间。5.7快到飞起来!
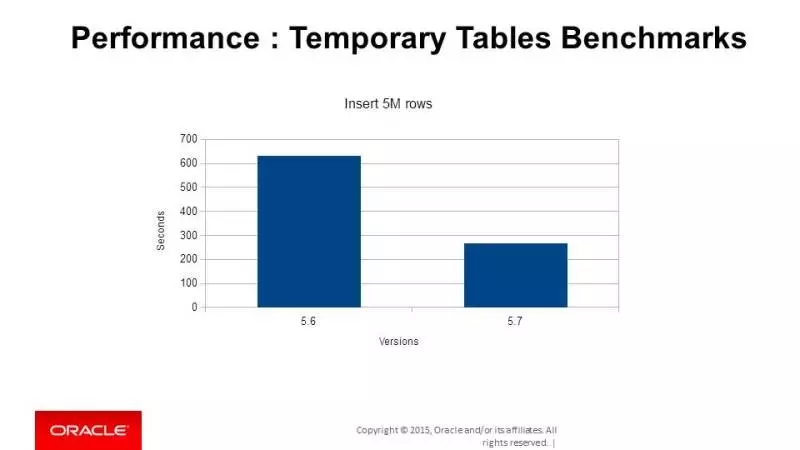
这是对临时表插入5M行当数据的测试,一倍以上的提升。
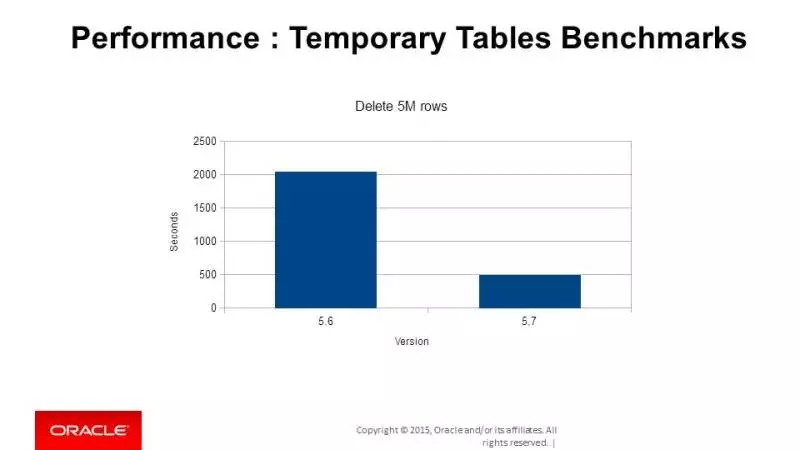
这是删除,开销减少了75%左右。
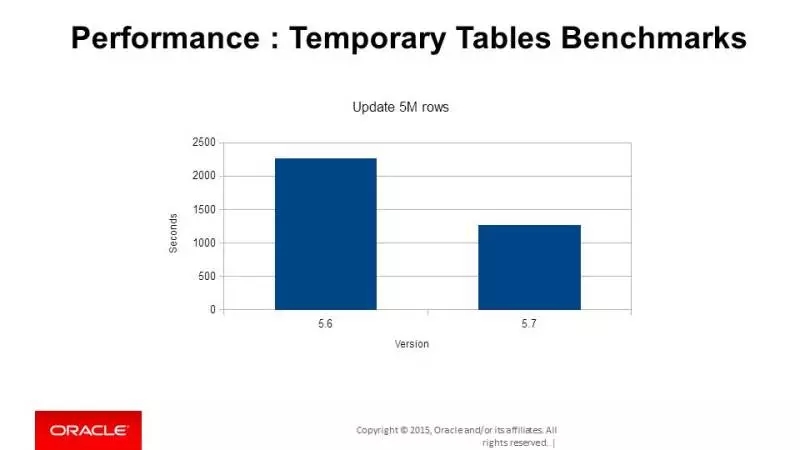
update,减少40%左右。所以,如果大家在应用中会使用InnoDB的临时表,那这个优化就能带来很大的好处。

刚才谈到的这个优化实际上不光是对InnoDB的临时表有用,还对一种大家平时看不见的表,优化器用的缓存表也有好处。之前,MySQL的优化器是用MyISAM来缓存SQL执行的中间结果集的, 现在,采用了InnoDB优化后的临时表,大家可以看图,明显快多了嘛!
好了,介绍完两个最大头的性能优化点,接下来我们浏览一下其他一些也非常重要的性能优化工作。
缓冲区

这个是对于缓冲区的优化,页的reference count采用了原子操作,可以极大的提高这个计数器的操作效率。可以看到,这个优化最重要的是解决在12核甚至更多核机器上性能问题。
同时,也对原来的刷写算法做了优化,提升了刷写效率。

缓冲区刷写采用多线程,而且可以配置线程数,同样能提高刷写效率。
Redo日志的I/O

对于Redo 日志的I/O,我们不仅解决了一些bug而且还优化了checksum以及mutex的算法。
Memcached 插件

得益于前面介绍的只读事务的优化,InnoDB的Memcached 插件也有了性能的飞跃,现在已经可以达到1.1M QPS。建议大家尝试一下,特别是对数据量很小, 但访问非常频繁的只读操作,可以采用InnoDB的Memcached插件。
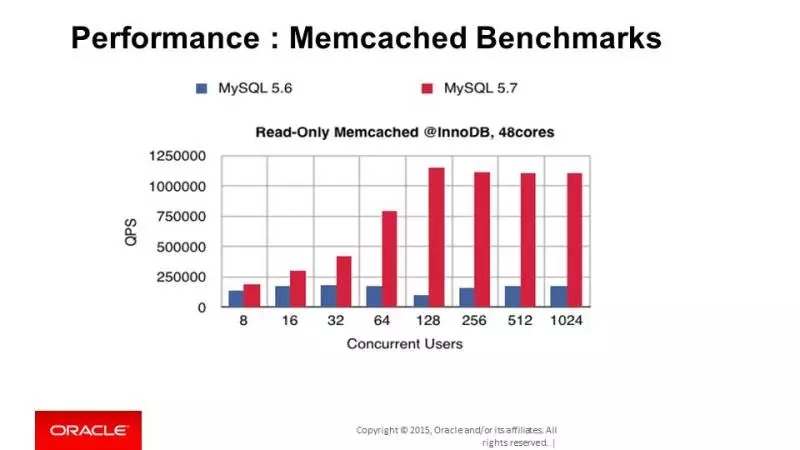
这是memcached的测试结果,性能大幅提升。
索引上的锁

这项优化是针对索引上的锁,一个非常复杂但是值得的优化。
DDL和truncate的优化

对于DDL和truncate的优化,现在truncate可以做到原子操作了,之前truncate中如果crash了,会导致出错。alter table也支持了更多新操作。

更快的DDL,这里主要指的是Alter table增加索引之类的操作。原来建索引是读一行插一行,现在是读一批,排序再批量插入。所以,性能有了170%的提升。
呵呵,这下,大家增加一个索引就快多了。
AHI

对于AHI的优化主要是将原来的哈希索引拆分成多个。
对于性能的优化这一部分就介绍到这里,总结一下,就是InnoDB在5.7中对性能做了一些非常重大的优化, 不光可以大幅加速数据的访问和存储的速度, 还能让大家节省很多日常维护的时间。
接下来,再讲讲我们在5.7中增加了哪些新功能。
二、新功能

首先是分区功能。以前,InnoDB内部是没有分区的,大家看到的都是在InnoDB外面做的分区。而现在,InnoDB原生支持了分区。
这样带来的好处是,减少了内存开销。以这样一个8k的分区的表为例,当打开十个实例的时候,可以减少90%的内存开销。


而且现在我们还可以对一个单独的分区做import/export了。

对于分区也支持了ICP和使用HANDLER来访问了。

接下来一个新功能是表空间管理。其实这个不是什么新功能,只是让大家以更为习惯的方式来管理表空间。
再接下来这个功能,我想大家肯定会喜欢,就是动态调整缓冲区的大小。

大家再也不用关数据库,改配置文件,再启动数据库来修改缓冲区的大小了,so easy!

日志管理的新功能是自动截断,这样日志文件就不会再不停的增长了。这个功能我想大家也应该挺喜欢。

支持更大的数据页。之前我们支持的是4k,8k,16k,现在可以支持32k,64k了。这样一些blob数据就可以直接存在页里,访问起来更快。

在5.7中最大头的新功能是对GIS的支持,主要由同事Jimmy和我来完成。
我们在InnoDB内部实现了基于R-tree的空间索引,这样用户就能很方便的查找地理信息数据了。

比如:查找以我为中心,周围2公里范围内的饭店之类的操作将变得异常迅速。

5.7中还有一个大头功能是虚拟列和虚拟列上的索引。也就是对于那些可以通过其他列的数据计算出来的列,大家可以创建一个虚拟列,它实际上是不存储数据的,每次读这个列都是临时在InnoDB内部计算出来。这个功能是客户要求的,但我不知道这里的同学是不是对此有需求。

为了让用户的数据更加安全,5.7中InnoDB实现了透明加密。(这个是我干的)

用户只需要在建表时加上加密选项,该表就被加密了,这样,就算你的ibd文件被偷了,别人也无法获得任何信息。

对于全文索引,5.7中开始可以支持外部解析器。

比如说n-gram。

又比如说MECAB。

对于新存储设备的支持方面,我们在5.7中支持了原子写入,在NVMFS上关掉了DW buffer。

另一个重要的新功能是新的数据压缩方法。基于页IO的压缩,也就是说,数据的压缩和解压发生在页IO的过程中。我们利用了一些文件系统的Punch Hole(文件打洞)功能来辅助实现这一新功能。
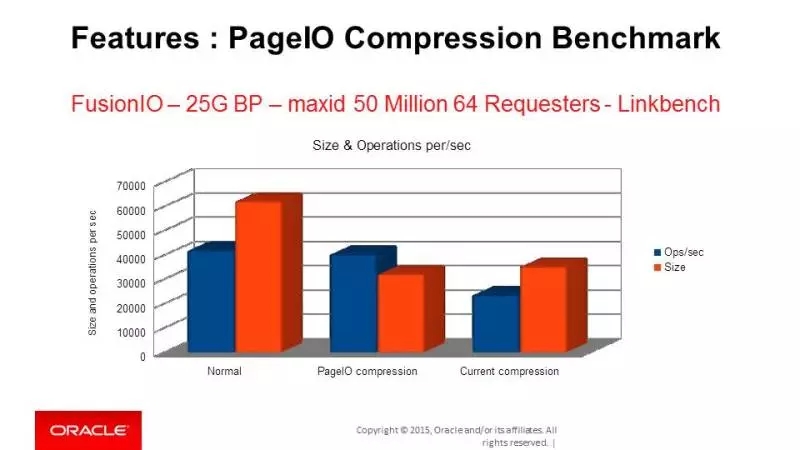
这里不详细介绍其实现方法了,总之效果就是文件更小,效率更高。
这里还有一些其他功能就不一一列举了,大家可以稍微浏览一下看看有没有自己感兴趣的,尤其是PFS这块,对于运维来说应该有帮助, 可以让DBA更多的了解当前系统的状态。




我今天要讲的内容大体就是这么多。总结一下,InnoDB在5.7中在性能和功能方面做了很多工作,非常期待大家的试用和反馈。
Q1:互联网金融企业,用MySQL 5.7的话,老师在高可用组件方面有什么推荐?
A1:我觉得对于5.7来说,高可用方面在InnoDB这部分并没有做太大的改进。所以,总体来说,5.7在高可用方面会更为可靠和高效,但是,5.7在replication方面有很多提升。至于推荐什么高可用方案,我想还是要根据实际的应用情况来定。
Q2:分区表的分区键,可以是多个列吗?
A2:可以多列。
Q3:虚拟列 都是临时在InnoDB内部计算出来 ,是否意味著会消耗更多的CPU资源?
A3:有影响,但不大。
Q4:官方版本为什么不把TokuDB带到版本里去?
A4:这个是管理层决定的事情,我想他们有自己的考虑,可能主要是基于商业目的,而非技术原因。
Q5:关于MySQL优化,和原理解压,有没有推荐的书籍?
A5:市面上关于MySQL优化的书有很多,比如《高性能MySQL》,但是,我想多看看一些相关文章,结合自己的工作实践会更有效果。
Q6:MySQL有没有什么好用的性能监控工具,类似于Oracle的AWR报告这种?
A6:目前官方是没有的,可以找找其他的监控工具。
Q7:对事务的优先级也有了一些调整。是如何调整的呀?
A7:这个主要是提高了一些事务的优先级,比如说复制的GCS事务,这些高优先级事务可以有一些特权,比如说可以跳过排队的队列,使得高优先级的事务可以优先执行。
Q8:创建表加密时可以指定只加密部分列吗?
A8:我今天说的这个表加密是在I/O层进行加密的,不能针对列进行加密,它只针对表,如果要只加密部分列,可以使用MySQL的 加密函数,在插入数据时进行加密。
Q9:数据库从5.6迁移到5.7要注意一些什么问题?
A9:升级工作正常来收不会遇到大的问题,因为我们在发布版本的时候都会有相应的升级测试,只有万一碰到什么问题,也可以具体情况具体分析,实在不行,可以告诉我,看是不是有bug需要修改。
Q10:truncate table加入了原子性,那速度是否会变慢?
A10:这个工作只是保证了truncate的操作不会导致问题。
Q11:5.7在dblink方面是否有改进?
A11:这方面的改进我没有听说。
Q12:听说sap的HANA内存数据库处理效率很高,请问MySQL(或Oracle)有无与其它产品做过对比测试(如高并发,性能等)呢?
A12:HANA 是列式存储的内存数据库,体系结构和MySQL完全不一样。因为不是同类型的产品,我们没有专门针对HANA做对比测试。
◆ 近期热文 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721