
作者介绍
房晓乐(葱头巴巴),PingCAP 资深解决方案架构师,前美团数据库专家、美团云 CDS 架构师、前搜狗、百度资深 DBA,擅长研究各种数据库架构,NewSQL 布道者。
本文系作者原创投稿,未经 DBAplus社群 允许,不得擅自转载和使用。
一、分库分表的背景
在谈论数据库架构演变和优化时,我们经常会听到分片、分库分表(Sharding)这样的关键词,在很长一段时间内,在各个公司、各中技术论坛里都很热衷谈论各种分片方案,尤其是互联网非常普及的 MySQL 数据库。但对笔者来说,分片、分库分表并不是一门创新技术,也不是一个好方案,它只是由于数据体系结构的限制而做的无奈之举,所以后来在听到这些词时,对笔者来说,更大意义在于感觉到朋友的公司业务量在快速增长,而对这个方案本身,其实有非常多问题。
二、分表的根本原因
以 MySQL 为例,分库分表从阶段应该拆分为分表、分库,一般来说是先进行分表,分表的原动力在于 MySQL 单表性能问题,相信大家都听说过类似这样的话,据说 MySQL 单表数据量超过 N 千万、或者表 Size 大于 N十G 性能就不行了。这个说法背后的逻辑是数据量超过一定大小,B+Tree 索引的高度就会增加,而每增加一层高度,整个索引扫描就会多一次 IO 。整个逻辑有一定道理,而从笔者的经验来看,其实更关键在于应用本身的使用,如果多数是索引命中率很高的点查或者小范围查,其实这个上限还很高,我们维护的系统里超过10亿级的表很常见。但正是由于业务的不可控,所以大家往往采取比较保守的策略,这就是分表的原因。
三、分库+分表的根本原因
分库主要由于 MySQL 容量上,MySQL 的写入是很昂贵的操作,它本身有很多优化技术,即使如此,写入也存在放大很多倍的现象。同时 MySQL M-S 的架构虽然天然地支持读流量扩展,但由于 MySQL 从库复制默认采用单线程的 SQL thread 进行 Binlog 顺序重放,这种单线程的从库写入极大地限制整个集群的写入能力,(除非不在意数据延迟,而数据延迟与否直接影响了读流量的可用性)。MySQL 基于组提交的并行复制从某种程度上缓解了这个问题,但本质上写入上限还是非常容易达到(实际业务也就 小几千 的 TPS ) 。说到这,目前有一些云 RDS 通过计算与存储分离、log is database 的理念来很大程度解决了写入扩大的问题,但在这之前,更为普遍的解决方案就是把一个集群拆分成 N 个集群,即分库分表(sharding)。为了规避热点问题,绝大多数采用的方法就是 hash 切分,也有极少的范围、或者基于 Mapping 的查询切分。
四、Sharding + Proxy
既然做了分表,那数据的分发、路由就需要进行处理,自下而上分为三层,分别 DB 层、中间层、应用层。DB 层实现,简单来说就是把路由信息加入到某个 Metedata 节点,同时加上一些诸如读写分离、HA 整合成一个 DB 服务或者产品,但这种方案实现复杂度非常高,有的逐步演变成了一种新的数据库,更为常见的是在中间层实现,而中间层又根据偏向 DB 还是偏向应用分为 DB proxy 和 JDBC proxy。
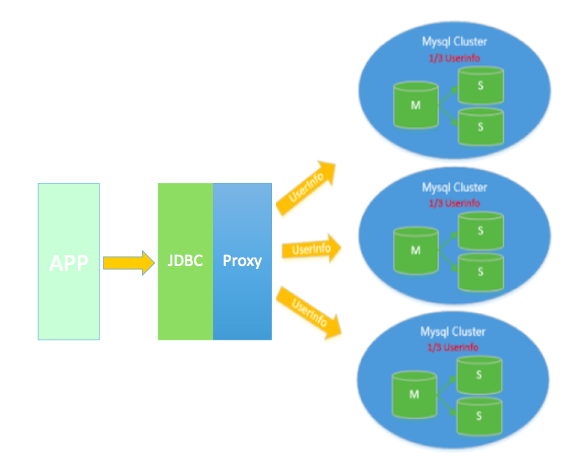
图:Sharding + Proxy
五、DB proxy or JDBC proxy
DB proxy、JDBC proxy 业内有很多种,很多都是开源的,我们简单汇总了常见的一些产品,如下图表。下面我们各找一些进行下对比,只讨论两种方案的优缺点,为了不必要的麻烦,本文不具体讨论哪个产品的优缺点。
| 实现方案 | 业界组件 | 原厂 | 功能特性 | 备注 |
| DB proxy-based 多语言支持 | Atlas | 360 | 读写分离、静态分表 | |
| Meituan Atlas | 美团 | 读写分离、单库分表 | 目前已经在原厂逐步下架。 | |
| Cobar | 阿里(B2B) | Cobar 中间件以 Proxy 的形式位于前台应用和实际数据库之间,对前台的开放的接口是 MySQL 通信协议 | 开源版本中数据库只支持 MySQL,并且不支持读写分离。 | |
| MyCAT | 阿里 | 是一个实现了 MySQL 协议的服务器,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用MySQL 原生协议与多个 MySQL 服务器通信 | MyCAT 基于阿里开源的 Cobar 产品而研发 | |
| Heisenberg | 百度 | 热重启配置、可水平扩容、遵守 MySQL 原生协议、无语言限制。 | ||
| Kingshard | Kingshard | 由 Go 开发高性能 MySQL Proxy 项目,在满足基本的读写分离的功能上,Kingshard 的性能是直连 MySQL 性能的80%以上。 | ||
| JDBC - based 支持多 ORM 框架,一般有语言限制。 | TDDL | 阿里淘宝 | 动态数据源、读写分离、分库分表 | TDDL 分为两个版本, 一个是带中间件的版本, 一个是直接 JAVA library 的版本。 |
| Zebra | 美团点评 | 实现动态数据源、读写分离、分库分表、CAT监控 | 功能齐全且有监控,接入复杂、限制多。 | |
| MTDDL | 美团点评 | 动态数据源、读写分离、分布式唯一主键生成器、分库分表、连接池及SQL监控 | ||
| DB - based 解决方案 | Vitess | 谷歌、Youtube | 集群基于ZooKeeper管理,通过RPC方式进行数据处理,总体分为,server,command line,gui监控 3部分 | Youtube 大量应用 |
| DRDS | 阿里 | DRDS(Distributed Relational Database Service)专注于解决单机关系型数据库扩展性问题,具备轻量(无状态)、灵活、稳定、高效等特性,是阿里巴巴集团自主研发的中间件产品。 | 逐渐下沉为DB服务 |
图:常见的Proxy
DB proxy
DBproxy 高度依赖网络组件,它需要诸如 LVS/F5 等 VIP 来实现流量的负载均衡,如果跨 IDC,还依赖诸如 DNS 进行IDC 分发。同时部分 DBproxy 对 Prepare 这类操作支持不友好,所以它的问题概括来说:
链路过长,每层都会增加响应时间
网络单点,并且往往是整个公司层面的单点
部分产品对Prepare 应用不友好,需要绑定 connection 信息
JDBC proxy
JDBC Proxy 最大的问题是违背了 DB 透明的原则,它需要对不同的语言编写 Driver,概括来说:
语言限制,总会遭到一批 RD 同学的吐槽 “世界上最好的语言竟然不支持!”
接入繁琐
DB 不透明
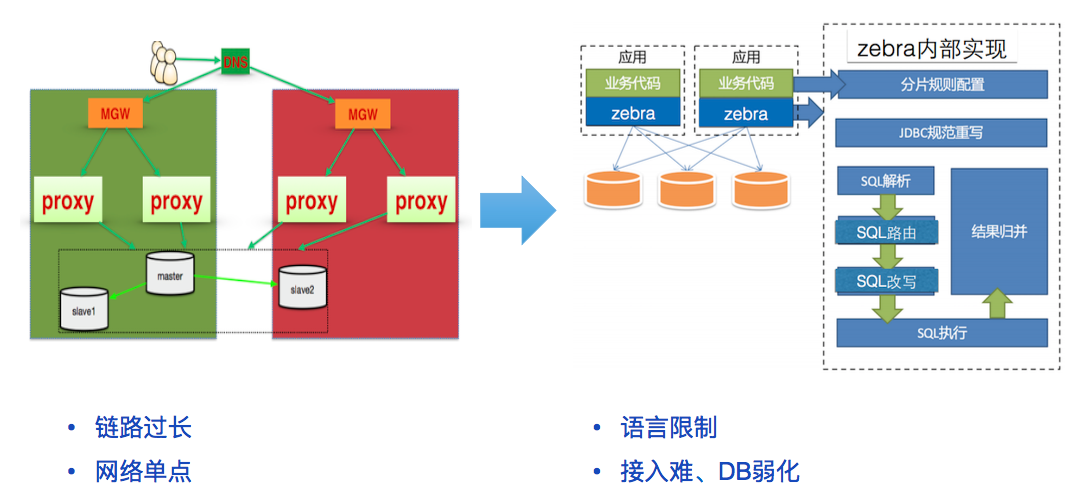
图:DB proxy VS JDBC proxy
六、Sharding+Proxy成本汇总
Sharding + Proxy 本质上只解决了一个问题,那就是单机数据容量问题,但它有哪些成本呢?前面提了每种 proxy 都有比较大的硬伤,我们再把分库分表拉上,一起整理这个方案的成本。
1、应用限制
Sharding 后对应用和 SQL 的侵入都很大,需要 SQL 足够简单,这种简单的应用导致 DB 弱化为存储。
SQL 不能跨维度 join、聚合、子查询等。
每个分片只能实现 Local index,不能实现诸如唯一键、外键等全局约束。
2、Sharding 业务维度选择
有些业务没有天然的业务维度,本身选择一个维度就是个问题。
大部分业务需要多维度的支持,多维度的情况下。
哪个业务维度为主?
其它业务维度产生了数据冗余,如果没有全局事务的话,很难保证一致性,全局事务本身实现很难,并且响应时间大幅度下降,业务相互依赖存在重大隐患,于是经常发生“风控把支付给阻塞了”的问题。
多维度实现方式,数据库同步还是异步?同步依赖应用端实现双写,异步存在实效性问题,对业务有限制,会发生“先让订单飞一会的问题”。
多维度数据关系表(mapping)维护。
3、Sharding key 选择(非业务维度选择)
非业务维度选择,会存在“我要的数据到底在那个集群上”的问题。
业务维度列如何选择 Sharding key ?
热点如何均摊,数据分布可能有长尾效应。
4、Sharding 算法选择
Hash 算法可以比较好的分散的热点数据,但对范围查询需要访问多个分片。反之 Range 算法又存在热点问题。所以要求在设计之初就要清楚自己的业务常用读写类型。
转换算法成本很高。
5、高可用问题
高可用的扩散问题(一个集群不可用,整个业务“不可用”)。
如何应对脑裂的情况?
MGR 多主模式数据冲突解决方案不成熟,基本上还没公司接入生产系统。
PXC 未解决写入容量,存在木桶原则,降低了写入容量。
第三方依赖,MHA(判断主库真死、新路由信息广播都需要一定的时间成本) 最快也需要 15s。
虽然有 GTID,仍然需要手工恢复。
6、数据一致性(其实这个严格上不属于分库分表的问题,但这个太重要了,不得不说)
MySQL 双一方案( redo、binlog 提交持久化) 严重影响了写入性能。
即使双一方案,主库硬盘挂了,由于异步复制,数据还是会丢。
强一致场景需求,比如金融行业,MySQL 目前只能做到双一+半同步复制,既然是半同步,随时可能延迟为异步复制,还是会丢数据。
MGR ?上面说过,多写模式问题很多,距离接入生产系统还很远。
InnoDB Cluster ?先搞出来再说吧。
7、DB Proxy
依赖网络层(LVS)实现负载均衡,跨 IDC 依赖 DNS,DNS + LVS + DBproxy + MySQL 网络链路过长,延迟增加、最重要的是存在全公司层面网络单点。
部分产品对 Prepare 不友好,需要绑定 connection。
8、JDBC Proxy
语言限制,需要单独对某语言写 Driver,应用不友好。
并未实现 DB 层的透明使用。
9、全局 ID
很简单的应用变成了很复杂的实现。
采用 MySQL 自增 ID,写入扩大,单机容量有限。
利用数据库集群并设置相应的步长,绝对埋坑的方案。
依赖第三方组件,Redis Sequence、Twitter Snowflake ,复杂度增加,还引入了单点。
Guid、Random 算法,说好的连续性呢?还有一定比例冲突。
业务属性字段 + 时间戳 + 随机数,冲突比例很高,依赖 NTP 等时间一致服务。
10、Double resource for AP
同样的数据需要双倍的人力和产品。
产品的重复,Hadoop、Hive、Hbase、Phoenix。
人力的重复。
数据迁移的复杂实现,Canal、databus、puma、dataX ?
实时查询?普遍 T+1 查询。
TP 业务表变更导致 AP 业务统计失败,“老板问为啥报表显示昨天订单下降这么多,因为做个了 DDL。”
11、运维友好度 (DDL、扩容等)
运维的复杂性是随着机器数量指数级增长的,Google 在 F1 之前维护了一个 100 多个节点的 MySQL sharding 就痛得不行了,不惜重新写了一个 Spanner 和 F1 搞定这个问题。
传统 RDBMS 上 DDL 锁表的问题,对于数据量较大的业务来说,锁定的时间会很长,如果使用 pt-osc、gh-ost 这样第三方工具来实现非阻塞 DDL,额外的空间开销会比较大,另外仍然需要人工的介入确保数据的一致性,最后切换的过程系统可能会有抖动,pt-osc 还需要两次获取 metalock,虽然这个操作本事很轻量,可糟糕的是如果它被诸如 DDL的锁阻塞,它会阻塞所有的 DML,于是悲剧了。
12、与原有业务的兼容性
时间成本,如果业务一开始设计时没有考虑分库分表或者中间件这类的方案,在应对数据量暴增的情况下匆忙重构是很麻烦的事情。
技术成本,如果没有强有力和有经验的架构师,很难在业务早期做出良好的设计,另外对于大多数非互联网行业的开发者来说更是不熟悉。
13、Sharding 容量管理
拆分不足,需要再次拆分的问题,工作量巨大。
拆分充足,大部分业务增长往往比预期低很多,经常发生“又被 PM 妹纸骗了,说好的百万级流量呢”的问题,即时业务增长得比较好,往往需要一个很长的周期,机器资源浪费严重。
14、运维成本,人力成本
不解释,SRE、DBA 兄弟们懂的。

图:sharding 成本汇总
七、总结
分库分表为了解决一个问题,引入了很多成本,从长久看这种方案会逐步被新的解决方案替代。目前看来,解决的思路主要分为两个方向:
第一个思路既然分库的原动力主要是单实例的写入容量限制,那么我们可以最大程度地提升整个写入容量,云计算的发展为这种思路提供了新的可能,以 AWS Aurora 为代表 RDS ,它以 Log is database 为理念,将复杂的随机写入简化为顺序写的 Log,并通过将计算与存储分离,把复杂的数据持久化、一致性、数据合并都扔给一个高可用的共享存储系统来完成,进而打开写入的天花板,将昂贵的写入容量提升一个量级;
第二种思路承认分片的必要性,将这种分片的策略集成到一套整体的分布式数据库体系中,同时通过 Paxos/Raft 复制协议加上多实例节点来实现数据强一致的高可用,其中代表产品有 Google 的 Spanner & F1、TiDB(https://github.com/pingcap/tidb)、CockRoachDB(https://github.com/cockroachdb/cockroach) 等,是比较理想的 Sharding + Proxy 的替代方案。







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721