
作者介绍
杨建荣,DBAplus社群联合发起人。现就职于搜狐畅游,Oracle ACE、YEP成员,超7年数据库开发和运维经验,擅长电信数据业务、数据库迁移和性能调优。持Oracle 10G OCP,OCM,MySQL OCP认证,《Oracle DBA工作笔记》作者。
有句话说得好,世上只有两种工具,一种是被人骂的,另一种是没人用的。被骂得越多,侧面反映出关注度越高,使用率越高,越用越成熟,这一点上, MySQL就是一个很不错的例子。而MySQL可支持的存储引擎很多,目前以InnoDB最佳,算为上品。
自MySQL 5.5.5开始,InnoDB是作为默认的存储引擎,而之前MyISAM存储引擎其实也占有一席之地,但MySQL开发团队自宣布MySQL 8.0.0开发里程碑版本DMR开始,就把MySQL版本一下子从5.x跳跃到了8.0。其中的一个亮点就是事务性数据字典,完全脱离MyISAM存储引擎,所以InnoDB宝刀不老,是我们学习MySQL重点需要了解的存储引擎。而其中InnoDB的double write特性很有意思,也是我们今天讨论的重点内容。
其实在MySQL和Oracle都会面临这类问题,不过各自有着不同的解决方案。我也看到网上有很多DBA在这个地方纠结、争论。相比而言,Oracle这边更沉默一些。我看了他们的讨论,但目前为止还没有看到一个把两方面都照顾到的解读。所以我决定做这个事情,以此来对比MySQL和Oracle中的一些实现和差别。很多都是个人之言,所以有些说法不一定对,算是一次尝试,希望引起一些思考和讨论。
InnoDB中的double write
首先我们来说说InnoDB和double write。
InnoDB有三大闪亮特性:insert buffer、double write和自适应哈希,其实还有几个比如异步IO、Flush neighbour Page(刷新邻接页),这个和系统层面关联性较高,所以三大亮点还是有普适性的。
首先我们来简单了解一下double write为什么要这么设计、解决了什么样的问题。对此我画了一个相对简陋的图,还有很多细节没有照顾到,但是能够说明意思。
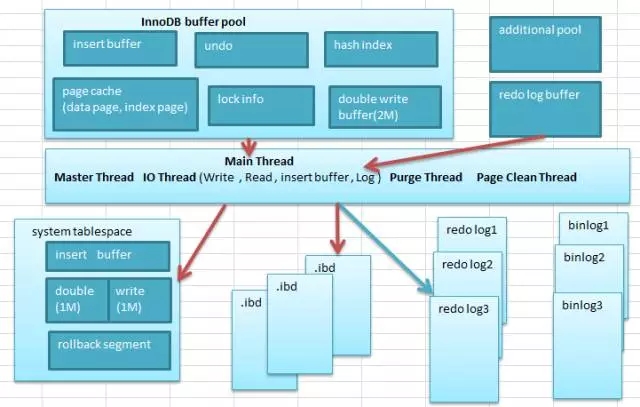
总体来说,double write buffer就是一种缓冲缓存技术,主要的目的就是为了防止数据在系统断电,异常crash情况下丢失数据。里面有几个点需要注意的就是,数据在buffer pool中修改后成了脏页,这个过程会产生Binglog记录和redo记录,当然缓存数据写入数据文件是一个异步的工作。如果细看,在共享表空间(system tablespace)中会存在一个2M的空间,分为2个单元,一共128个页,其中120个用于批量刷脏数据,另外8个用于Single Page Flush。
根据阿里翟卫祥同学分析,之所以这样做是因为批量刷脏是后台线程做的,这样不影响前台线程。而Single Page Flush是用户线程发起的,需要尽快地刷脏并替换出一个空闲页出来。所以不是一个严格的64+64的拆分,最后也给出了这篇文章的链接。(https://yq.aliyun.com/articles/50627)
而数据刷新过程,是先使用memcopy把脏数据复制到内存中的double write buffer,分两次写完,每次写1MB到共享表空间,然后就是调用fsync来同步到磁盘。这里有一点需要注意的是,这个刷新到共享表空间的过程,虽然是两次,但是是顺序写,所以开销不会很大,也就不会像大家想象的那样,觉得double write性能可能很差。根据Percona的测试,大概也就是5%左右的差别,数据重要还是性能更重要,这是一个基本的命题。当然后续会再写入对应的表空间文件中,这个过程就是随机写,性能开销就会大一些。所以早些时候试用SSD时很多人也带有如此的顾虑,顺序写还是随机写,这个顾虑在这篇文章中也会有一些解释。
当然double write这么设计就是为了恢复而用,要不这么大张旗鼓就不值得了。对于文件校验来说,一个中心词就是checksum。如果出现了partial write的时候,比如断电,那么两次写的过程中,很可能page是不一致的,这样checksum校验就很可能出现问题。而出现问题时,因为有了前期写入共享表空间的页信息,所以就可以重构出页的信息重新写入。
double write其实还有一个特点,就是将数据从double write buffer写到真正的segment中时,系统会自动合并连接空间刷新的方式,这样一来每次就可以刷新多个pages,从而提高效率。
比如下面的环境,我们可以根据show status的结果来得到一个合并页的情况。
> show status like'%dbl%';
+----------------------------+----------+
|Variable_name | Value |
+----------------------------+----------+
| Innodb_dblwr_pages_written | 23196544 |
| Innodb_dblwr_writes | 4639373 |
+----------------------------+----------+
通过InnoDB_dblwr_pages_written/InnoDB_dblwr_writes
或者通过指标也可基本看明白,这个例子中比例是5:1,证明数据变更频率很低。
当然对于double write,在Percona中也在持续改进,在Percona 5.7版本中做了一个改进,你可以看到一个新参数,innodb_parallel_doublewrite_path。
|innodb_parallel_doublewrite_path | xb_doublewrite |
在系统层面,也会存在一个30M的文件对应。
-rw-r----- 1 mysql mysql31457280Mar28 17:54 xb_doublewrite
这就是并行double write,实现了并行刷脏。关于这个特性的详细描述和测试,可以参考以下链接:
https://www.percona.com/blog/2016/05/09/percona-server-5-7-parallel-doublewrite/?utm_source=tuicool&utm_medium=referral
里面提供了很多详细的测试对比和分析。当然MariaDB、Facebook、Aurora在这方面也有一些自己的实现方式和考虑。MariaDB是定制了新的参数innodb_use_atomic_writes来控制原子写。当在启动时检查到支持atomic write时,即使开启了innodb_doublewrite,也会关闭掉。
Facebook则是提供了一个选项,写page之前,只将对应的page number写到dblwr中(不是写全page),崩溃恢复读出记录在dblwr中的page号,间接恢复。
Aurora则是采用了存储和数据库服务器分离的方式来实现,无须开启double write,有兴趣的同学可以看一看。
到此为止,MySQL 层面double write的解释就差不多了。但我们肯定有一些疑问,因为partial write的问题是很多数据库设计中都需要考虑到这么一个临界点的问题。MySQL中的页是16k,数据的校验是按照这个为单位进行的,而操作系统层面的数据单位肯定达不到16k(比如是4k),那么一旦发生断电时,只保留了部分写入,如果是Oracle DBA一般对此都会很淡定,说用redo来恢复嘛。但可能我们被屏蔽了一些细节,MySQL在恢复的过程中一个基准是检查page的checksum,也就是page的最后事务号,发生这种partial page write 的问题时,因为page已经损坏,所以就无法定位到page中的事务号,这个时候redo就无法直接恢复。
由此引申一点,partial write的问题在Oracle中肯定也会存在,只是Oracle替我们把这个过程平滑做好了。其中有设计的差异,还有恢复技术的差别。但无论如何这个问题都不会绕过去,还是得解决。所以在此我需要和Oracle结合起来,来对比哪里好,哪里不好,这是一个很好的习惯和学习方法,为此我们引出两个问题。
Oracle里面怎么做?
要回答这个问题,就需要从以下两个方面来解读。
Oracle中是否存在partial write?
Oracle是怎么解决partial write的?
我们得把MySQL和Oracle放在一起,像拿着两个玩具一般,左看右比,不光从外向对比还要看内部实现。有的同学说有些Internal的东西又用不着,看了也没用,而且学起来很耗时间和精力。这个得辩证地看,很多东西掌握到了一定程度,就需要突破自己,深入理解总是没坏处,这个过程是个潜移默化的过程。毛主席说:理论联系实际、密切联系群众(在这里就是我们的DBA和用户)、批评与自我批评,很值得借鉴。
Oracle是否存在partial write
我们先来看看一种很类似的说法,很多Oracle DBA和MySQL DBA总是在纠结这个地方。
Oracle里面有一种备份方式是热备份(hot backup),就是在数据库open状态可以直接拷贝数据文件做备份,备份开始使用begin backup声明,备份结束使用end backup结束。这个过程中很可能出现拷贝的文件发生数据变化,导致不一致的情况,被称为split block。这一类数据块也叫fractured block,在官方文档11g中是这么解释的,而在10g的官方文档描述是错误的。
fractured block
简单来说就是在数据块头部和尾部的SCN不一致导致。在用户管理方式的备份中,操作系统工具(比如cp命令)在DBWR正在更新文件的同时备份数据文件。
操作系统工具可能以一种半更新的状态读取块,结果上半部分更新复制到了备份介质的块,而下半部分仍包含较旧的数据。在这种情况下,这个块就是断裂的。
对于非RMAN备份的方式,ALTER TABLESPACE ... BEGIN BACKUP或ALTER DATABASE BEGIN BACKUP命令是断裂块问题的解决方案。当表空间处于热备模式,并且对数据块进行更改时,数据库将在更改之前记录整个块镜像的副本,以便数据库可以在介质恢复发现该块被破坏时重建该块。
在10g中是被描述如下,注意下面标红的“每次”,这是文档里的一个错误描述。
当表空间处于热备模式,并且每次对数据块进行更改时,数据库将在更改之前记录整个块镜像的副本,以便数据库可以在介质恢复发现该块被破坏时重建该块。
Jonathan Lewis这位大师对此做了进一步的阐释,把话说得更明确了。
简单翻译一下就是:
官方文档如果这么说就错了,在检查点完成之后,将块加载到缓存之后的第一次变更(或者缓存中任意块的第一次更改),当前版本的块信息会全量写入redo,而数据块在缓冲区中后续的变更不会重复写。
文档描述问题在10g文档存在,在11g中做了修正。而实际应用中使用cp命令进行拷贝是因为写入磁盘的是操作会使用文件系统块大小作为最小IO,但是RMAN写入磁盘的时候使用Oracle block size作为最小IO,所以不会出现split block。
为此我们来提一提Oracle中的数据块。Oracle中block的大小大体有这几类,分别是数据块、重做日志数据块和控制文件数据块。
数据块data block,是读写数据文件的最小单位,默认是8KB,可以查询select file#,name,block_size from v$datafile;
重做日志数据块叫作redo block,大小一般等于操作系统块的大小,可以查询select lebsz from x$kccle;
控制文件数据块叫作control file block,可以查询select block_size from v$controlfile。
由此我们扩展一个概念,在11g中redo添加了一个新的属性blocksize。这个blocksize的值是在数据库的源代码中固定的,与操作系统相关,默认的值为512,在不同的操作系统中会有所不同。
查看blocksize的配置,可以使用基表x$kccle从Oracle的内部视图中获得:
SQL> select max(lebsz) from x$kccle;
MAX(LEBSZ)
----------
512
以上可以看出通过redo重构数据库来恢复是没有问题的,但是就涉及到一个很重要的概念,检查点。
Oracle可以很自信地确认,如果数据做了commit而且成功返回,那么下一秒断电后数据是肯定能恢复的。光有自信不行,我们得有理论的支持说明,如何通过redo进行数据恢复。
Oracle如何通过redo进行恢复
我们假设redo写的时候也是存在问题,即partial write。
在MySQL中有这样的一个梗:因为page已经损坏,所以就无法定位到page中的事务号,所以这个时候redo就无法直接恢复。
Oracle怎么做呢?看看下面的图,其实细看有一个文件很有意思,那就是控制文件。Oracle是有控制文件来做数据的检查点,对控制文件描述得更形象一些,它就是数据库的大脑,由此可见它的地位,尽管它的功能相对会比较单一,但是很重要。
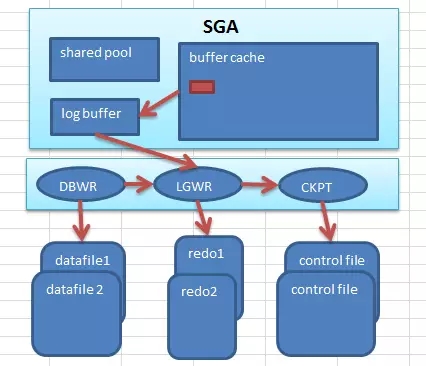
用户提交数据的变更之后,在Oracle写入到数据文件中,这是一个异步的过程,但是同时从数据安全性方面又需要保证数据不会丢失,在数据变更后会在redo log buffer中构造重做数据条目(redo entry),描述了修改前和修改后的数据变化。Lgwr会把重做条目刷入redo日志,当然这个过程还要细分一下,分为后台写和同步写。
后台写的触发条件会多一些,比如3秒的间隔;或者数据还没有刷新到redo日志时,DBWR会触发LGWR去写,直至写完;或者是达到日志缓冲区1/3时触发LGWR;或者是达到1M时触发,还有其它更多的细节,可以移步官方文档看看。
同步写的触发条件相对简单,就是用户commit时触发LGWR去写,所以说如果出现over commit的情况时,总是会有很明显的log file sync的等待事件。
这个过程和CKPT有什么关系呢?简单来说,Oracle不断地定位这个起点,这样在不可预期的实例崩溃中能够有效地保护并恢复数据,这也是CKPT的使命所在。这个起点如果太靠近日志文件头部就意味着要处理很多redo条目,恢复效率会很差;其次,这个起点不能太靠近日志文件尾部,太靠近日志文件尾部则说明只有很少的脏数据块没有写入数据,也就需要DBWR频繁去刷数据。所以Oracle中会存在检查点队列的概念,就是一个LRU链表,上面都是数据块头(buffer header),同时如果一个数据块被修改了多次的话,在该链表上也只出现一次,和Jonathan Lewis的解读如出一辙。
而在MySQL中也是LRU的方式,控制方式更加清晰,可以通过参数innodb_lru_scan_depth控制LRU列表中可用页数量,通过参数innodb_max_dirty_pages_pact来控制刷脏页的频率(默认是75,谷歌的压测推荐是80)。
小结一下:就是CKPT是一个关键,会有检查点队列和增量检查点来提高数据恢复的效率和减少DBWR频繁刷盘。而这个所谓检查点不光在redo、数据文件、数据文件头,关键的是控制文件中也还会持续跟踪记录。这个就是我们数据恢复的基石SCN,在MySQL里面叫做LSN。
所以数据恢复时,从控制文件中发现数据文件的检查点为空,意味着这是异常宕机,就会启动crash recovery。这个检查点在控制文件中会抓取到最近的,然后就是应用redo,达到一个奔溃前的状态,就是常说的前滚,然后为了保证事务一致性,回滚那些未提交的事务,所以控制文件的设计就很有意义。以上就是一个较为粗略的恢复过程。
反问1: 批判与自我批判
好了,到翻盘的时候了,我相信很多MySQL DBA看到这里会有更多疑问,我自我批判一下,应该是两个问题。
MySQL虽然数据单位是页16k,但是写入redo log到文件的时候是以512字节为单位来写的,这个你怎么解释
你说的Checkpoint技术MySQL也有。
这个理解完全没错,我来解释一下。
MySQL InnoDB中也有检查点LSN,会随着log buffer的增长而增长。innodb_os_log_written是随着redo log文件的写入量而增长,可以通过show global status like '%Innodb_os_log_written%' 看到一个累计值,增量的差值即为512的倍数,所以单纯看这里我们看不出差异,尽管他们有不同粒度的细分。
MySQL InnoDB的检查点技术很丰富,主要分为两类,Sharp checkpoint和fuzzy checkpoint。
Sharp checkpoint是全量检查点,通过参数innodb_fast_shutdown=1来设置,有点类似Oracle中的alter system checkpoint;而fuzzy checkpoint就丰富多了,总体来说是部分页刷新,刷新的场景会有一些复杂。
Master Thread Checkpoint
FLUSH_LUR_LIST Checkpoint
Async/Sync Flush Checkpoint
Dirty Page too much Checkpoint
而回到问题的本质,那就是这些都是InnoDB层面去做的检查点,所以就会出现我们开始所说的情况。
因为page已经损坏,所以就无法定位到page中的事务号,所以这个时候redo就无法直接恢复。
而Oracle有控制文件这一层级,数据恢复都是在mount状态下,挂载控制文件后开始的。
这个时候我们Oracle DBA再来反问一下MySQL DBA。
Binlog是MySQL Server范畴的。记录的是数据的变更操作,支持多种存储引擎。也就是说无论是MyISAM、InnoDB等存储引擎,Binlog都会记录,所以数据恢复和搭建slave经常会用到。另外根据二阶段提交的场景,崩溃恢复也会用到Binlog。
而redo是InnoDB引擎范畴的,记录的是记录物理页的修改,是做崩溃恢复所用。
总体来说,MySQL为了兼容其它事务引擎,在Server层引入了Binlog,这样就能够保证对所有的引擎启用复制。同时一个事务提交会写Binlog和redo,Binlog和redo的一致性也需要协调,主要是通过二阶段提交来解决。
而Oracle是只有redo,相当于把Binlog和redo的功能做了整合,因为Oracle不是插件式数据库,不支持其它第三方的存储引擎。所以这些都是从体系结构里都统一了的。
所以对这个问题的总结就是:不要手里拿着锤子,眼里看到的都是钉子,技术架构不同使然。
InnoDB是插件式存储引擎。事务支持是存储引擎层面来做,如果再多说一句,外键这种实现本来就不应该是存储引擎做的,但是这是一个特例,因为Server层不支持,最后还是由InnoDB来实现了。简单来说存储引擎是面向表的,而不是数据库,明白了这一点很重要,也对InnoDB的定位会更加清晰。
但我们看待问题也不能孤立的看,不应该仅仅从数据库层面、系统层面考虑,还需要考虑存储层面,也需要听听存储界的观点。
存储和double write的关系
存储层面来说,我会引用社群三位专家的分享内容来说明。
首先是社群的一篇文章干货分享——《基于PCIe闪存卡的Oracle Online Redo Log优化》,里面这样说道:
上一代存储多采用512 bytes的扇区,现在的存储则采用4k的扇区,扇区即每次最小IO的大小。4k 扇区有两种工作模式:native mode 和emulation mode。
Native mode,即4k模式,物理和逻辑的block大小一样,都是4096bytes。Native mode 的缺点是需要操作系统和软件(如DB)的支持。Oracle 从11gR2 开始支持4k IO操作。Linux 内核在2.6.32 之后也开始支持4k IO操作。
emulation mode:物理块是4k,但逻辑块是512bytes。在该模式下,IO操作时底层物理还是4k进行操作,所以就会导致Partial I/O 和4k 对齐的问题。
在emulation mode下,每次IO操作大小是512 bytes,但存储底层的IO操作大小必须是4k,如果要读512 bytes的数据,实际需要读4k,是原来的8倍,就是partial IO。而在写时,也是先读4k 的物理block,然后更新其中的512 bytes的数据,再把4k 写回去。所以在emulation mode下,增加的工作会增加延时,降低性能。
对于SSD来说,double write会带来两个问题,性能惩罚和对SSD的磨损增加,这部分内容引用自社群之前的一次分享《闪存存储特性以及数据库相关优化思路》。
炫辉老师他们按照下面的场景在闪存卡上进行了测试。
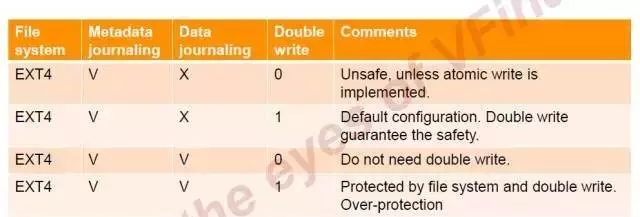
在安全性层面,只要Metadata Journal+DW或Metadata Journal+Data Journal(即上图中的第2行和第3行数据),都可以保护数据库数据的安全,也就是意外掉电数据不会损坏,数据库可以正常启动,数据不丢失。
但是在CPU bound(计算密集型) 的情况下,前个组合的性能衰减(8%)要小于后面的保护组合(10%)。
如果是在IO bound(I/O密集型)的情况下,前个组合的性能衰减(10%)要小于后面的保护组合(34%)。但是DW下的数据写入量会比后者增加23%,也就是会增加SSD的磨损。这个是我们在应用时需要注意的。
而在文件系统层面,我们还需要注意这些地方,以下内容摘自社群之前的分享《数据库与存储系统》。
绝大多数文件系统支持4k,(除了vxfs和zfs)。vxfs支持最大64k,可以设置成512byte,1k,2k,4k,8k,16k,32k,64k。
ZFS是一个特殊的怪物;数据块是动态的,也就是说写入多少数据,ZFS上那块存放数据的块就有那么大。传统上是支持动态的512byte到128k。
所以说ZFS本身就提供了部分写失效防范机制,在这种情况下,就可以不开启double write。
小结
MySQL和Oracle有时候想想真是有意思,一个开源,一个商业,一个最流行,一个最有范,看起来势不两立,但命运把他们又连接在一起。而我们学习起来多质疑,多思考,多尝试一定会有所收获。
参考资料:








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721