
对于Oracle运维中的那些事儿,我的最终目的:不是比谁更惨,而是能够从中吸取经验和教训。
从我的理解来看,我会从下面的几个方面来进行说明DBA运维中的一些事儿。
每个部分都是非常关键的,缺一不可,而且每一部分都有很多的东西可以细化,我会逐一展开来说。
首先来说说环境篇。
DBA的角色及分工
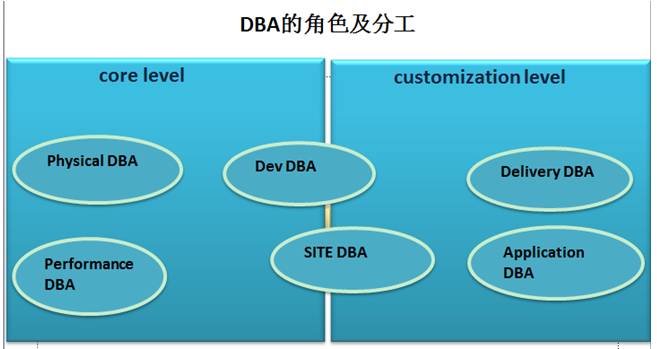
对于DBA的分工,以前的公司对于DBA角色划分粒度还是很细的。
大体是按照核心和客户化定制层来划分的,核心层主要负责产品化,客户化层面主要负责定制。属于不同的产品线但又彼此紧密关联。
Physical DBA更多负责环境部署,搭建和数据恢复,补丁升级等,对于系统,存储网络等更为拿手。
Performance DBA一般都是从各个产品线逐渐衍生出来的高手,对于产品理解很深,当然工作重点是在性能调优上。一般都是产品级的优化,全球所有项目都会通用。
Dev DBA也有一个团队,负责运维产品的开发,其实内部的很多自动化的工具都是他们做出来的,当然开发功底要求也很了得。
Delivery DBA主要负责数据交付,一般的UT,UAT,PROD的数据交付,有的时候涉及的环境成百套,对于这些数据的交付管理非常重要,补丁管理,数据变更的基线管理,数据的同步,复制,业务环境搭建都会涉及。
Application DBA 主要和业务相关,一般和开发的联系较为紧密,一线的数据支持,对于系统的架构,业务情况要很熟悉。
最后是site DBA,所有产品,业务的事情都要考虑,最终的方案和实施落地。
然后来说说行业环境,以我为例,我也是从传统行业到了互联网行业,当然也需要作出一些改变。
从角色上是从乙方到甲方,很多的事情都需要考虑,对于技术方案和硬件选型,不仅仅是纯技术上的考量,需要更多的因素。这是一个全面的过程。
当然和传统行业来比,传统行业更为保守,稳定压倒一切。
以之前的电信客户为例,测试情况极为苛刻,UAT测试做了差不多一年。
对于产品和数据库的版本搭配,公司也有严格的认证制度,哪个产品适用的数据库子版本(比如11.2.0.2.x)都有要求,因为这些是实实在在做足了测试。
很多客户对于RAC的使用也是保守的active/passive方式,当然自11g的ADG之后,也在默默的开始替换BCV的方式。
从数据库的角度来看,为了保守,很多特性都会禁用。
禁用直方图
产品化极为彻底,很少有创建索引优化sql的场景
禁用回收站
禁用skip scan
……
监控篇中和大家说说一下几个方面。一个是监控工具。
一般的选择都会是商业或者开源,或者两者兼有。

两者没有严格的优劣之分,这是一种平衡和理性的选择过程。
Gc,em12c本身原生支持Oracle,还可以扩展支持其它的数据库,系统层面也做得不错。管理功能非常强大。
而在开源领域,zabbix负责系统级,搭配插件orabbix监控数据库实例,其实也不错。
再说说监控盲点,对于下面的语句:
select ‘Oracle is alive’ from dual; 如果监控实例是否open,是否合理?
其实dual表比较特殊,在nomount,mount,open阶段都可以访问。严格来说是不太合理的。
11g中备库的v$flash_recovery_area_usage的自动归档删除策略
11g备库在mount阶段,比较浪费。
1、Asm使用空间的监控
硬件监控
当然还有很多,就不展开了。我想多说说硬件监控的重要性。
这是一个故障类型的占比图。
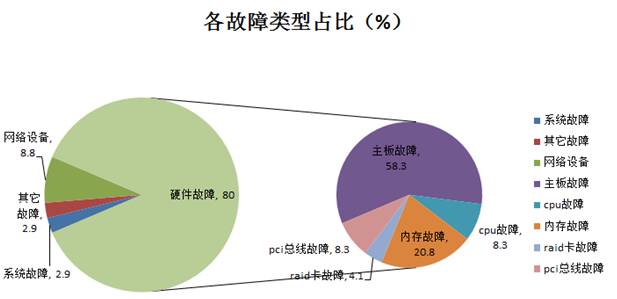
可以看到硬件故障出现的概率还是非常大的。其实在很多的故障中都是一个很头疼的问题,对于硬件故障来说,主板故障,内存故障又占有很高的比例。
这是故障影响累计时长的占比图:
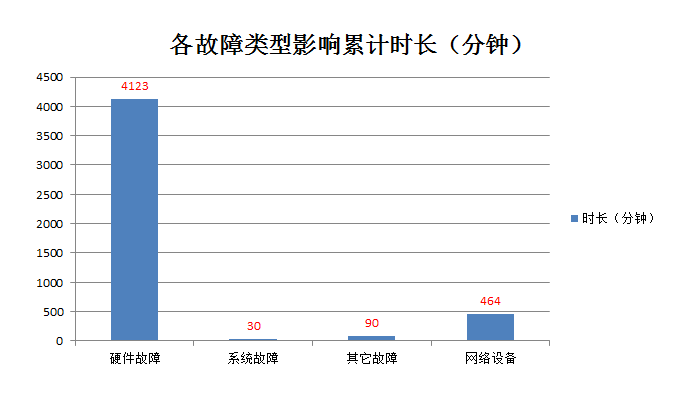
这里有几个地方需要说明一下。
可以看到硬件故障遥遥领先,这个4500分钟是一个累计的值,不是一次故障的影响时间,比如有1000台机器,一台机器影响1分钟,1000台就是1000分钟。
这是积累了好几年的一个数值,所以会把这个影响放大。
2、硬件故障的反思
监控维度要全
监控粒度要细
不能等待问题降临,要直面迎击
100多台服务器,硬件巡检12台有磁盘坏块
没有条件,不能坐以待毙,要敢于DIY
DB time抖动的分析,后面会讲到
做历史问题,遗留问题的终结者
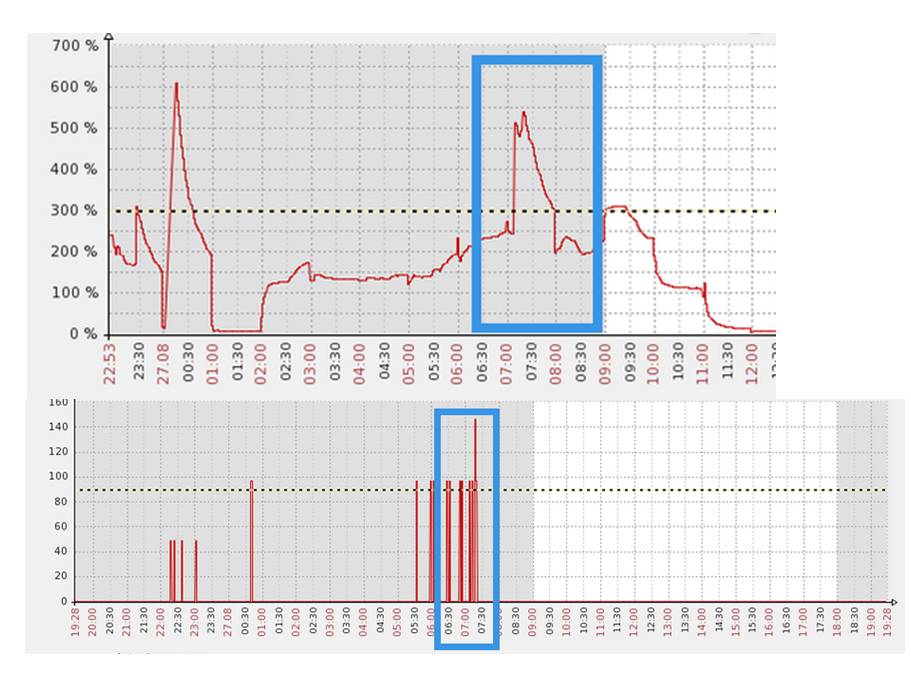
我举一个例子来说明一下监控的重要性,可能对于备库的监控也是个盲点。
这是一台备库的CPU使用情况,蓝色的部分表示使用情况,在平时负载是很高的。
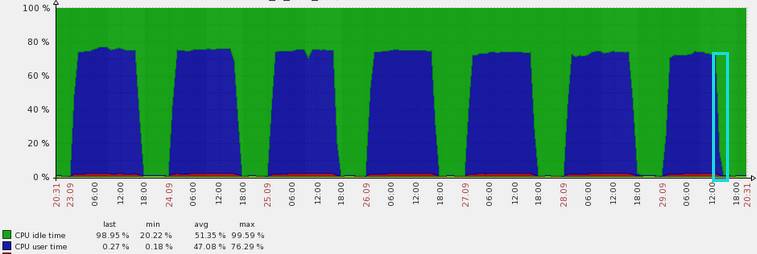
当然深入分析之后,发现有一些查询只在备库上运行,在做大量的全表扫描,分析之后发现问题其实完全可以避免,创建一个相应的索引即可修复。
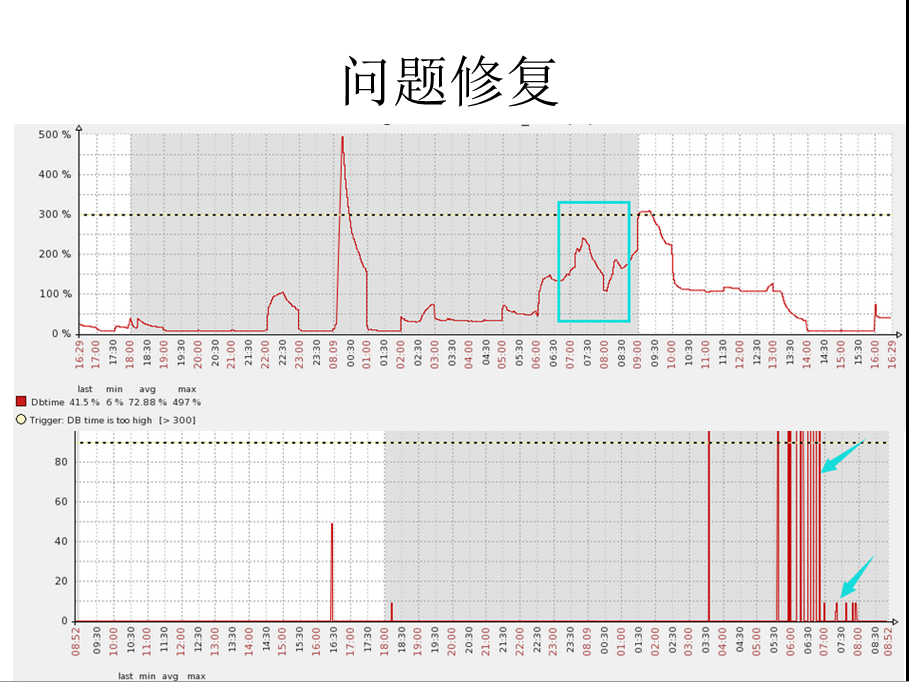
修复后的情况如下,可以看到CPU使用率几乎触底。
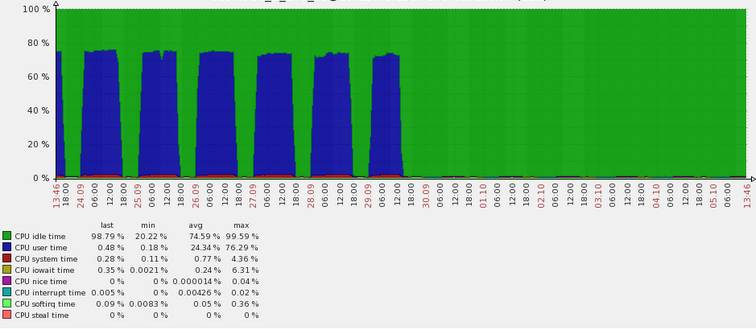
3、运维管理
运维管理的内容很多,我说说日常维护和一些细节问题。
(1)日常维护
使用空格的技巧:这是学到的一种专业态度,对于不熟悉,不确定的环境,黑屏时先敲一下空格,敲了回车很可能会有致命问题。
空格的惨案:这个惨案也是听来的,如果使用下面的命令 ifconfig –a6 vs ifconfig –a 6 就因为一个空格就会造成网络地址瞬间修改,如果是rac,节点瞬间就会倒下。
简单至极的维护案例:system表空间满,如果发现表空间满的情况,不要急于添加数据文件,倒底是应用不规范存放数据到了system表空间还是审计日志占用了大量空间,可以参考MOS得到一些专业指导,在有些版本直接清理审计日志可能会有死锁。
(2)不可忽略的细节
既然说到这么细了,我再多提几个。
外部表使用exp会有奇怪的问题,还是要用expdp来做。
安装数据库软件时silent模式下的参数在10g和11g中竟然有一个细小的差别。
responsefile,responseFile你看出来了吗?
合理利用新特性
使用sql_monitor,竟然发现一条运行14天的sql语句,当然其它方式也可以做到。
少踩一些坑
drop datafile导致的备库bug,在10.2.0.4以前,主库如果drop datafile,备库的MRP会直接挂掉,这是一个bug,官方解决方案是重建备库,当然我比较任性,其实也可以手工修复。
灵活变通,省事省力
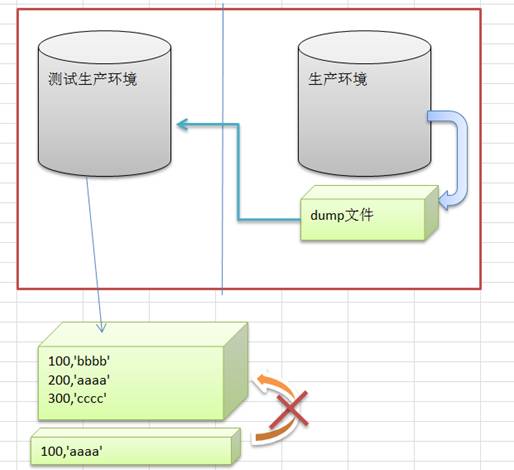
5T数据和1M数据的灵活切换。这个我拿一个小案例来说明,生产环境需要紧急复现一个问题,这个工作通过测试生产环境来完成,但是测试生产环境已经数据有5T,而从生产环境抽取的客户数据只有1M。
直接导入1M的数据,很可能因为逐渐冲突而导入失败。这个时候就可以使用闪回数据库来实现。可以做到5T和1M数据的灵活切换。
说到优化。
不定时的性能炸弹sqlprofile:sqlprofile是一个临时方案。有一个sqlprofile调优的语句在一年后发生了严重的性能问题,原因就在于里面的数据情况发生了很大变化,导致原油的执行计划资源消耗太大。
临时提交的变更4个小时的pl/sql和1分钟的sql:之前有同事在升级前紧急提交一个pl/sql脚本是作为数据插入,但是测试不够充分,结果在生产执行了近4个小时,当然问题期间,我们进行了优化,其实改造成一条sql语句,insert xxxx select xxxx from xx where 一分钟就可以搞定。
sqlldr加载性能问题的分析:有一个sqlldr加载的性能问题诊断,在各方掐架的情况下,我默默使用scp传送一个文件,证明了其实是网络问题。
优化部分我举一个案例:数据库无法登录的诊断。
某一天收到报警说数据库无法登录,报错信息如下:
报错的原因看起来是audit的问题,其实sysdba登录会自动写audit,当然audit区域空间占用很小。
但是问题时间段的归档频率可以说明问题,横轴是每个小时的切换频率,纵轴是日期:
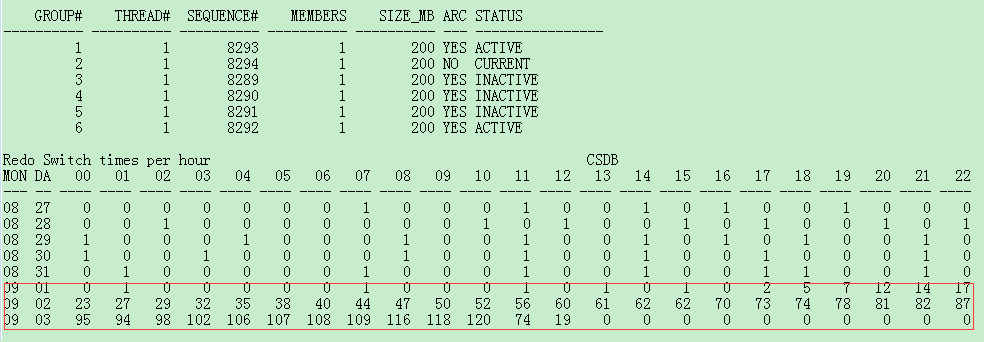
可以看到归档切换很频繁,想必应用做了调整,但是我还是看了看awr报告分析了一下。发现top1的sql语句是一个update,当然看性能也没有什么大的问题。

语句如下:

下面的报告对比可以说明问题的原因,rows per Exec有很大的差别,其实这个表只有1万条的数据。

所以很容易看出来,这是冗余数据的问题导致了大量的归档。
稍后做了对比测试:
运行3分钟,日志切换14次(存在冗余数据)
运行7分钟,日志切换0次(删除冗余数据)
开发和业务对于数据库运维非常重要,可能这个部分大家都会轻视。
定制awr,ash,addm——
这些工具其实可以简单定制,会极大提高工作效率。
熟练掌握开发技能——
数据库连接满的原因分析:之前分析的一个数据库连接满的问题,还是在查看开发源代码后发现jdbc没有正确释放连接导致,当然还是比较隐蔽的一个小问题。
熟练掌握业务——
通过业务优化sql:通过业务来优化sql其实还是非常中肯的一种方式,改进幅度最大,把技术需求转化为业务需求。
我来举一个分区规则,业务和技术的脱钩的例子,可能看起来比较绕,大家耐心看一下。
之前做数据迁移的时候,有一个分区表特别慢,最后发现分区元数据如下:

所以说分区规则可能存在问题。发现分区规则是多键值的情况。
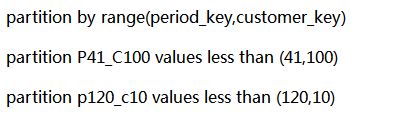
我们来看看分区规则的元数据情况,似乎和业务需求和吻合的。
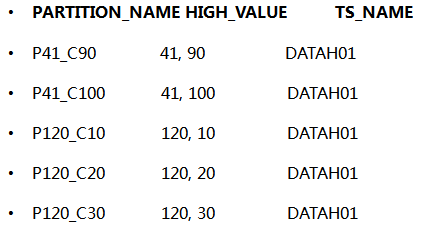
那么实际的数据存放情况呢。以p120_c10分区为例。可以看到数据有些乱。

多键值分区需要格外注意,点到为止。
对DBA更高的要求,更高的挑战
开发技能
数据架构
一专多能
新技术前沿
全栈DBA
展望
自动化运维
精细化运维
这个部分看起来比较虚,但是都是我们目前在做的。比如说精细化运维,一个目前的简单的zabbix改进就是db time的监控。其实通过这个可以发现很多的潜在问题。
调优之后的情况如下。
所以大家一起努力,办法总比困难多。有很多人觉得平淡,其实可以再努力一下,坚持一下。借用知乎的一句话。平淡其实是很奢侈的,那意味着有许多爱你的人在为你付出。在DBA+社群,在这里,就是我们可爱的DBA们。
作者介绍 杨建荣
【DBA+社群】联合发起人。
Oracle ACE-A、YEP成员,现就职于搜狐畅游,拥有6年以上的数据库开发和运维经验,曾任amdocs DBA,负责亚太电信运营商的数据业务支持,擅长电信数据业务,数据库迁移和性能调优。
拥有Oracle 10g OCP,OCM,MySQL OCP认证,对shell,ava有一定的功底,曾在2015年数据库大会进行关于数据迁移和升级的主题分享,现在每天仍在孜孜不倦的进行技术分享,每天通过微信,技术博客共享,已连续坚持700多天。
在本文末发表评论,并获得点赞数最多的前5人,每人可获赠以下书籍一本!

PostgreSQL即学即用(第2版)
本书以众多示例贯穿始终,演示如何实现在别的数据库难以实现或根本不可能实现的任务,涵盖LATERAL横向关联查询语法、增强的JSON支持、物化视图机制以及其他重要功能特性。
特别鸣谢图灵出版社(www.ituring.com.cn)为本次活动提供图书赞助。
全球敏捷运维峰会【杭州站】

杭州站倒计时:2016年4月16日,DBA+社群联合Linux中国、三墩IT人开启全球敏捷运维峰会第一站:杭州!
技术大咖云集:峰会力邀来自阿里、京东、淘宝、网易、IBM、浙江移动、新炬网络、蘑菇街、百世物流等互联网与传统企业的资深大咖,汇聚500+行业精英!
互联网 VS 传统的碰撞:共同探讨互联网前沿技术应用心得、传统企业技术转型的实践与困境、全程拒绝无营养的广告,绝对干货,精彩不容错过!
DBA+社群专属购票优惠
门票优惠价:39元(原价99元)
(优惠码:dbaplus001)
VIP票优惠价:199元(原价299元)
(优惠码:dbaplusvip)
报名方式:猛戳“Gdevops官网”抢票吧!









230721
1、导入Mongo Monitor监控工具表结构(mongo_monitor…
上面提到: 在问题描述的架构图中我们可以看到,Click…
PMM不香吗?
如今看都很棒