





转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
Oracle的优化工具很是丰富,大家基本都会常用到的awr,ash,addm自不必多说,还有大量的tuning包,可能在EM中去用感觉还方便一些,就是动动鼠标,所见即所得,而且sql monitor作为11g的新特性,对于调优来说也是如虎添翼。但是作为前线的工程师们,总是会有各种环境的挑战,想用图形工具还是比较困难的,优化工具虽好,但是使用起来如果不太方便,或者很多时候不能很快定位问题,就会让人感觉使不上劲,眉毛胡子一把抓。这也是我简单定制这些工具的一个动力。所谓磨刀不误砍柴工,这些强大的工具简单包装一下,就会有不一样的效果来。我基本会从下面的几个方面来说明一下我所做过的简单定制。如果能够帮助到大家,我深感荣幸。
目录
简单定制的思路
简单定制awr
简单定制ash
简单定制addm
简单定制OSM
1
如果说定制的思路,那么我目前是使用了SQL,shell和PL/SQL之间做转换或者互相调用来实现。不管怎么样,能够实现定制需求就行。
2
1.1 定制awr的动力
首先来看看第一个优化工具AWR,大家在做性能问题诊断的时候,awr是不可或缺的工具,使用?/rdbms/admin/awrrpt.sql可能大家使用的多了, 有时候感觉输入参数还是有些太繁琐了。一边复制,一边在一个快照列表中翻找对应的快照,其实还是不太方便。
比如我想查看某一周以前的早上8点到9点的快照,生成一个awr报告来对比现在的性能情况,那么我首先得算一下大概需要多少天的快照,然后从一个冗长的快照列表中去翻找需要的快照号,快照列表类似下面的格式。
Instance DB Name Snap Id Snap Started Level
------------ ------------ --------- ------------------ -----
TEST01 TEST01 1274 19 Oct 2014 08:00 1
1275 19 Oct 2014 08:30 1
1276 20 Oct 2014 09:00 1
好不容易找到begin snap_id,拷贝完成,突然忘了看end snap_id,又得上下翻屏,其实,我只是想生成一个报告而已。
对于历史问题的分析如果经常需要找历史awr报告,这种情况就尤其痛苦,所以我决定改变这种状况。
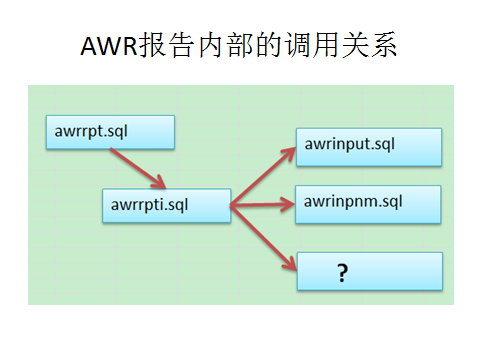
我是从$ORACLE_HOME/rdbms/admin/awrrpt.sql开始分析的,其实这个脚本的调用关系如下图所示。
awrinput.sql 是做输入参数的校验的,
awrinpnm.sql 是做报告文件名处理的。
所以最关键的就是第三个脚本了。内容就是调用dbms_workload_repository的方法了。内容如下:
Select output from table(dbms_workload_repository.&fn_name( :dbid,:inst_num,:bid, :eid,:rpt_options ));
既然说要定制,就需要把这些参数都给拿下。
于是我没有急于马上风风火火定制,而是发现其实我可以先定制一些历史快照的使用情况。
比如我想得到某天某个时间段的快照情况,那么我只需要简单输入对应的时间参数就可以马上得到一个快照列表了,根据需要随时调整也没问题。
比如我想知道2014年10月19日3点到8点的快照情况,输出应该类似下面的样式。
DB_NAME SNAP_ID SNAPDAT LVL
--------- ---------- -------------------------- ----------
TEST01 1262 19 Oct 2014 02:00 1
1263 19 Oct 2014 03:00 1
1264 19 Oct 2014 04:00 1
1265 19 Oct 2014 05:00 1
1266 19 Oct 2014 06:00 1
1267 19 Oct 2014 07:00 1
1268 19 Oct 2014 08:00 1
1269 19 Oct 2014 09:00 1
于是我写了脚本先实现这个功能,这样调用脚本 sh showsnap.sh 20141019 3 8
快照前后各宽裕一个小时,这样我就轻松的得到快照列表了。
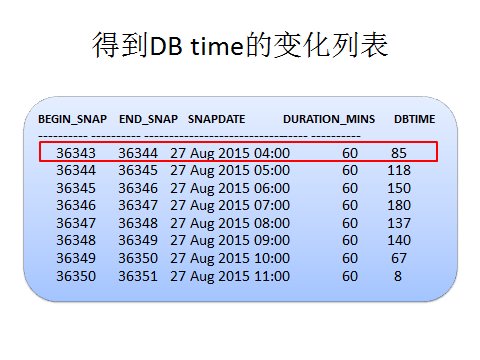
我们在这个基础上更进一步,其实输出快照号的同时也可以同时输出DB time的情况,这是在定制后得到的DB time情况。
得到的是快照点的对应的DB time,比如快照36343~36344,持续60分钟,DB time为85分钟,以此类推。得到这样的DB time列表,还是可以发现很多潜在的问题,可以充分结合awr来进行诊断,但是不足之处还是后知后觉,这部分功能可以进一步进行深化,先不做更多讨论。
可以这样运行脚本生成上面的结果 sh showsnap2.sh 20150827 5 10
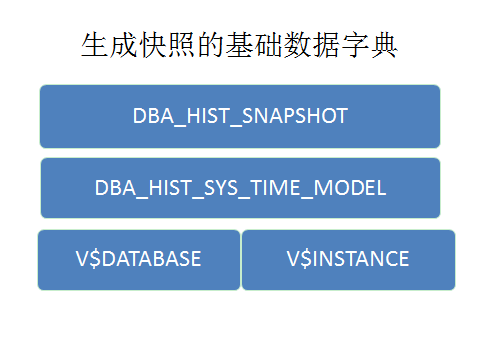
showsnap2.sh这个脚本的实现思路主要是基于下面的几个数据字典。
由于定制前做了一些准备工作,所以定制AWR的时候就会更加灵活。
1.4 定制awrrpt.sql
定制AWR的核心部分就是下面的这句。
select output from table(dbms_workload_repository.&fn_name( :dbid,:inst_num,:bid, :eid,:rpt_options ));
所以我定制的语句如下,使用print生成了参数列表,然后直接在dbms_workload_repository.awr_report_html一次性传入值,如果是text格式的,直接调用awr_report_text即可。
使用的语句如下:
print "
WHENEVER SQLERROR EXIT 5
SET FEEDBACK OFF
SET HEAD OFF
SET PAGES 0
connect ${DB_CONN_STR}@${SH_DB_SID}\n
select d.dbid||','||i.instance_number||','||$1||','||$2||',0' text
from v\$database d,
v\$instance i ;
" | sqlplus -s /nolog > awr_inputs.lst
sqlplus -s ${DB_CONN_STR}@${SH_DB_SID} <<EOF
set pages 0
set linesize 1500
set termout on;
spool awrrpt_$1_$2.lst
select output from table(dbms_workload_repository.awr_report_html( `cat awr_inputs.lst`));
spool off;
set termout off;
clear columns sql;
EOF
如果awrrpt.sql完成了之后,还有一个福利就是awrsqrpt.sql,我们可以抓取到快照时间范围内sql的执行计划情况。这个时候唯一需要补充参数就是sql_id,需要调用dbms_workload_repository.awr_sql_report_text就可以得到文本格式执行计划报告。
如果想得到html格式,就是dbms_workload_repository.awr_sql_report_html
这样调用即可 sh genawrsqltext.sh 12315 12316 xxxxx 其中xxxxx为sql_id
3
AWR的简单定制如此,ASH的部分也是如法炮制,所以整个分析的思路也是相似的。
核心步骤也是dbms_workload_repository.ash_report_html。当然主要差别在于ASH中是不依赖快照的,需要传入的参数为两个时间戳,精确到秒,比如20151208010000 20151208020000 就是12月8号的凌晨1点到2点的ASH需要的参数。
这样调用即可 sh genashhtml.sh 20151208010000 20151208020000 即可。
脚本主要内容如下:
select d.dbid||','||i.instance_number||',to_date('||chr(39)||$1||chr(39)||','||chr(39)||'yyyymmddHH24MISS'||chr(39)||'),to_date('||chr(39)||$2||chr(39)||','||chr(39)||'yyyymmddHH24MISS'||chr(39)||')' text from v\$database d, v\$instance i ;
select output from table(dbms_workload_repository.ash_report_html(`cat ash_inputs.lst`));
4
对于ADDM而言,差别就比较大了。因为ADDM的部分涉及到pl/sql的一些方面,ADDM会调用dbms_advisor.create_task生成一个任务,通过dbms_advisor.set_task_parameter来设置一些参数属性,然后通过dbms_advisor.execute_task来执行任务,最后通过 dbms_advisor.get_task_report(‘$TASK_NAME’,‘TEXT’,‘TYPICAL’)来输出最终的报告。
当然ADDM的部分还是和快照相关,调用的方法类似下面的方式sh genaddmhtml.sh 12315 12316 ,其中12315,12316是对应的快照号。
脚本主要内容如下:
dbms_output.put_line(task_name);
dbms_advisor.create_task('ADDM',task_name);
dbms_advisor.set_task_parameter(task_name, 'START_SNAPSHOT', $1);
dbms_advisor.set_task_parameter(task_name, 'END_SNAPSHOT', $2);
dbms_advisor.execute_task(task_name);
end;
/
prompt
prompt Generating the ADDM report for this analysis ...
prompt
prompt
set long 1000000 pagesize 0 longchunksize 1000
column get_clob format a80
select dbms_advisor.get_task_report('$TASK_NAME', 'TEXT', 'TYPICAL')
from sys.dual;
5
5.1 OSM简介
在sql调优中,对于sql语句的实时监控显得尤为重要,如果某条sql语句的性能比较差。可能从前端的直观感觉就是执行时间比较长。
对于dba来说,可能关注的相关因素需要多一些。
1)可以通过top命令来监控sql的性能情况,查看cpu使用率较高的oracle process,然后通过查看session和process得绑定得到对应的session,然后得到对应的sql语句。
2) 如果已经过去了一段时间,而且在缓存中已经没有对应的sql语句了,可以通过awr得到一个大体的报告做分析,排查问题的大体范围,在这个基础上定位更精准的时间段,做一个ash。
3) 如果已经定位到sql_id了,想做进一步的分析,可以通过awrsqrpt来得到对应时间段的执行计划
。。。
对于执行计划的分析方式就更多了,但是oracle也提供了一些比较方便的功能集,你用或者不用,它就在那里。
sql monitor是一个实时的sql监控工具,11g里对dbms_tune做了不少的改进和提升。动态视图v$sql_monitor中有被监控的sql语句的一些明细信息。
一般对于执行时间超过5秒的sql语句,都会成为监控对象
如果想得到sql monitor报告也绝非难事,可以通过dbms_sqltune.report_sql_monitor的方式得到一个html报告。比如下面的小例子。
SELECT dbms_sqltune.report_sql_monitor(
sql_id => '$1',
report_level => 'ALL',
type=>‘HTML'
) comm from dual;
任何性能瓶颈都会暴露在你的眼前,这种图形化的调优其实还是很不错的。在无法使用图形界面的环境,得到一个html报告绝对是一种很难得的福利。
OSM中的v$sql_monitor类似v$session的机制,数据都会刷新
自动生成sql monitor的html或text 格式报告
报告生成频率的控制
对报告进行筛查,得到报告中的top sql
对历史报告进行深度分析
但是有个问题就是比如某个sql语句造成的问题已经发生了一段时间,想查看之前的执行情况,v$sql_monitor基本上就无从得知了,因为数据已经被刷出去了。
这个时候想查看更多的信息就比较困难了,为了能够及时和准确的定位,我们可以借助sql_monitor在后台启用一个job不定时的去查找,把这部分数据给缓存起来,目前我是采用平面文件的形式。
整个流程图如下:
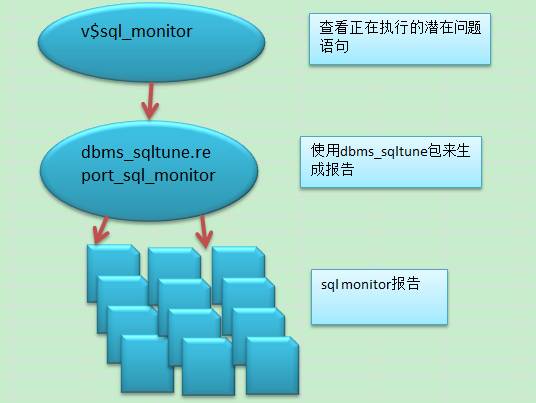
如果大半夜有性能问题但是不是很紧要的情况下,我希望一切都能很自然一些,我可以在工作时间更高效的处理。从我的实践来看,我是在一个指定的目录下每隔10分钟去查找一次性能sql,如果当天已经有生成报告就不重新生成了,这个是报告生成的频度控制。
每天上班之后,我可以调用脚本根据时间来过滤得到一个排行榜,Duration时间最长的语句肯定是需要重点关注的。
grep -A2 Duration *$DATE |grep s\<|sed 's/<td>//g'|sed 's/<\/td>//g'|sort -n -k2
结果不到一个多月,生成了800个报告,这么多报告是好事,毕竟已经有了详细的报告和数据,但是如果一下子消化这么多的报告,肯定是有难度,而且没有很强的针对性,可能有些sql在一个月中的几天才会运行。有些sql可能每天都会运行,有些可能就运行一次,很长时间不会再次运行,我们需要关注的就是那些运行频繁的问题sql语句。SQL monitor的报告类似下面的格式。
-rw-r--r-- 1 prodbuser dba 277992 Jul 26 00:37 cjqdgd14xjwjm_rpt.lst_140726
-rw-r--r-- 1 prodbuser dba 280710 Jul 27 09:28 cjqdgd14xjwjm_rpt.lst_140727
-rw-r--r-- 1 prodbuser dba 282220 Jul 28 05:09 cjqdgd14xjwjm_rpt.lst_140728
-rw-r--r-- 1 prodbuser dba 277690 Jul 30 01:31 cjqdgd14xjwjm_rpt.lst_140730
-rw-r--r-- 1 prodbuser dba 249000 Aug 1 11:58 cjqdgd14xjwjm_rpt.lst_140801
-rw-r--r-- 1 prodbuser dba 296867 Aug 2 13:08 cjqdgd14xjwjm_rpt.lst_140802
-rw-r--r-- 1 prodbuser dba 285240 Aug 3 01:28 cjqdgd14xjwjm_rpt.lst_140803
-rw-r--r-- 1 prodbuser dba 295055 Aug 4 10:49 cjqdgd14xjwjm_rpt.lst_140804
看到这么多的报告都有点晕,不知道该从哪里开始查起。
而且直接在生产环境没有目的的进行语句的执行计划抽取,性能问题也会做很多额外的无用功。
可以使用如下的命令来生成sql语句,然后在其他的环境中运行,做问题sql语句的分析,用sql语句来分析sql语句,这叫一物降一物。
ls -l *.lst* |awk '{print $9}'|awk -F_rpt.lst_ '{print "insert into issue_sql values('\''"$1 "'\'', " $2");"}' > issue_sql.sql
生成的sql语句类似下面的形式。
insert into issue_sql values('07aw4r5syzydx', 140818);
insert into issue_sql values('091n6gmzgwxzs', 140805);
insert into issue_sql values('0cdthzpx2jn4q', 140722);
insert into issue_sql values('0cdthzpx2jn4q', 140727);
insert into issue_sql values('0cdthzpx2jn4q', 140729);
insert into issue_sql values('0cdthzpx2jn4q', 140803);
insert into issue_sql values('0cdthzpx2jn4q', 140805);
insert into issue_sql values('0d0n1waazr2fs', 140722);
拷贝到别的环境去。
> scp issue_sql.sql xxxxx@xxxx.19.xxxx.47:~
然后创建一个临时的小表
create table issue_sql (sql_id varchar2(30),sql_date number);
@issue_sql.sql
然后就开始使用sql语句来分析了,先来一个大概的,看看哪些sql语句出现的频率最高。
select *from (select sql_id,count(*)cnt from issue_sql group by sql_id) order by cnt desc;
SQL> select *from (select sql_id,count(*)cnt from issue_sql group by sql_id) order by cnt desc;
SQL_ID CNT
------------------------------ ----------
648600hq1s1s8 25
4gz51fphuarsw 23
94mgu2k08hm4r 23
4ad8ypr3nf6vm 22
30kfnx73k75jf 2
9cbk5x6hwq0mu 2
3rkmrqq7wsvas 1
比如我们想看看八月份以来哪些sql语句执行频率最高,可以使用如下的方式:
SQL> select *from (select sql_id,count(*)cnt from issue_sql where sql_date like '1408%' group by sql_id) order by cnt desc;
SQL_ID CNT
------------------------------ ----------
648600hq1s1s8 13
99pnz5pr7tgpb 13
4ad8ypr3nf6vm 13
cjqdgd14xjwjm 4
还可以指定某些天,或者一些更为复杂的判断条件。
对于语句的执行时间进行更细粒度的监控,如果没有图形工具的情况,手工分析还是不爽,如果会一些开发,可以继续定制。比如我采用Java语言尝试对sql的执行时间进行统计,可以生成一个时间曲线图。用Java是因为我只会用Java做一点点字符串处理的功能J。
要做这部分工作是因为总是在分析数据的时候没有一个整体的感觉,而且又没有图形界面可用,只好在字符界面里想点办法,这个没有大规模采用,也是因为本身有华而不实的成分,也算自娱自乐吧。


上面仅供自娱自乐,如果有完备的环境最好还是不要这么干。
所以这些简单的定制,其实也会发现在一定程度上,我们可以让这些性能诊断工具更符合我们的口味。在不影响性能,能够大幅度提高问题处理水平的情况下,还是推荐按需定制。
当然我只是抛砖引玉,还有更多的优化工具,比如dbms_tune可以有更多定制,sqltrpt也是一个很容易被大家忽略的神器。
本篇文章需要的脚本小编已总结好,大家可以关注DBA+社群微信公众号:dbaplus,只需回复“脚本”即可下载相关文档。
作者介绍:杨建荣
【DBA+社群】北京发起人
Oracle ACE-A,YEP成员,现就职于搜狐畅游,拥有6年以上的数据库开发和运维经验,曾任amdocs DBA,负责亚太电信运营商的数据业务支持,擅长电信数据业务,数据库迁移和性能调优。
拥有Oracle 10g OCP,OCM, MySQL OCP认证,对shell,java有一定的功底,曾在2015年数据库大会进行关于数据迁移和升级的主题分享,现在每天仍在孜孜不倦的进行技术分享,每天通过微信,技术博客共享,已连续坚持550多天。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看陈科《memcached&redis等分布式缓存的实现原理》;
回复005,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复006,看郑晓辉《存储和数据库不得不说的故事》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看李海翔《MySQL优化案例:半连接(semi join)优化方式导致的查询性能低下》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看徐桂林《以应用为中心的企业混合云管理》。
DBA+社群是全中国最大的涵盖各种数据库、中间件及架构师线条的微信社群!有100+专家发起人,建有15大城市微信群,6大专业产品群,多达10000+跨界DBA加入队伍。每天1个热议话题,每周2次线上技术分享,不定期线下聚会与原创专家团干货分享,更多精彩,欢迎关注dbaplus微信订阅号!

扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA


