
一、背景
目前线上业务量与日俱增,每日的订单量超过千万,资金流动大,资金安全成为了重点关注的问题。为了确保每一笔交易的正确性,提高资金的正确性和保障业务的利益,除了RD代码逻辑严格以外,还需要对每日甚至每小时订单的流水进行核对,对异常情况能及时处理。面对千万级的订单量,人工对账肯定是不可行的,所以,实现一套对账系统成为了必然的事,不仅为资金安全提供依据,也节省公司运维人力,数据更加可视化。
目前这套系统已覆盖聚合渠道网关与外部渠道100%的对账业务,完成春晚期间支付宝亿级订单量对账,完成日常AC项目千万级订单量对账,对账准确率实现6个9,为公司节省2~3个人力。
二、介绍
对账模块是支付系统的核心功能之一,不同业务设计的对账模型不同,但是都会遇到以下几个问题:
海量的数据,就目前聚合支付的订单量来看,设计的对账系统需要应对千万级的数据量;
面对日切、多账、少账等异常差异订单应该如何处理;
账单格式、下载账单时间、下载方式等不一致问题。
针对以上问题,并结合财经聚合支付系统的特点,本文将设计一套可以应对千万级数据量、分布式和高可用的对账系统,利用消息队列Kafka的解耦性解决对账系统各模块之间的强依赖性。
文章从三个方面介绍对账系统,第一方面,总体介绍对账系统的设计,依次介绍各个模块的实现及其过程中使用到的设计模式;第二方面,介绍对账系统版本迭代的过程,为什么需要进行版本迭代,以及版本迭代过程中踩过的“坑”;第三方面,总结现有版本的特点并提出下一步的优化思路。
三、系统设计
图1为对账系统总结构图,分为六个模块,分别是文件下载模块、文件解析并推送模块、平台数据获取并推送模块、执行对账模块、对账结果统计模块和中间态模块,每个模块负责自己的职能。
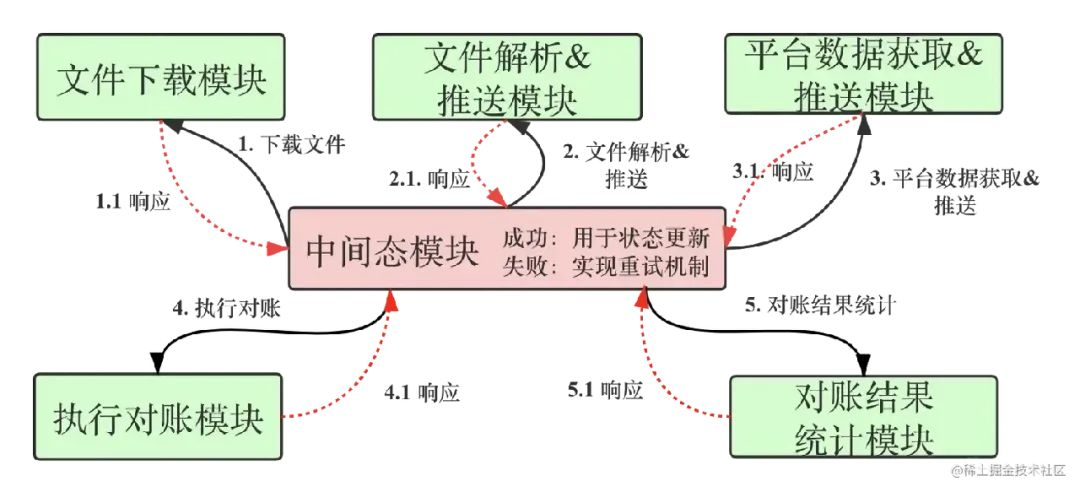
图1 对账系统总结构图
图2为对账系统利用Kafka实现的状态转换图。每个模块独立存在,彼此之间通过消息中间件Kafka实现系统状态转换,通过中间态UpdateReconStatus类实现状态更新和message发送。这种设计不仅实现流水线对账,也利用消息中间件的特点,实现重试和模块之间的解耦。
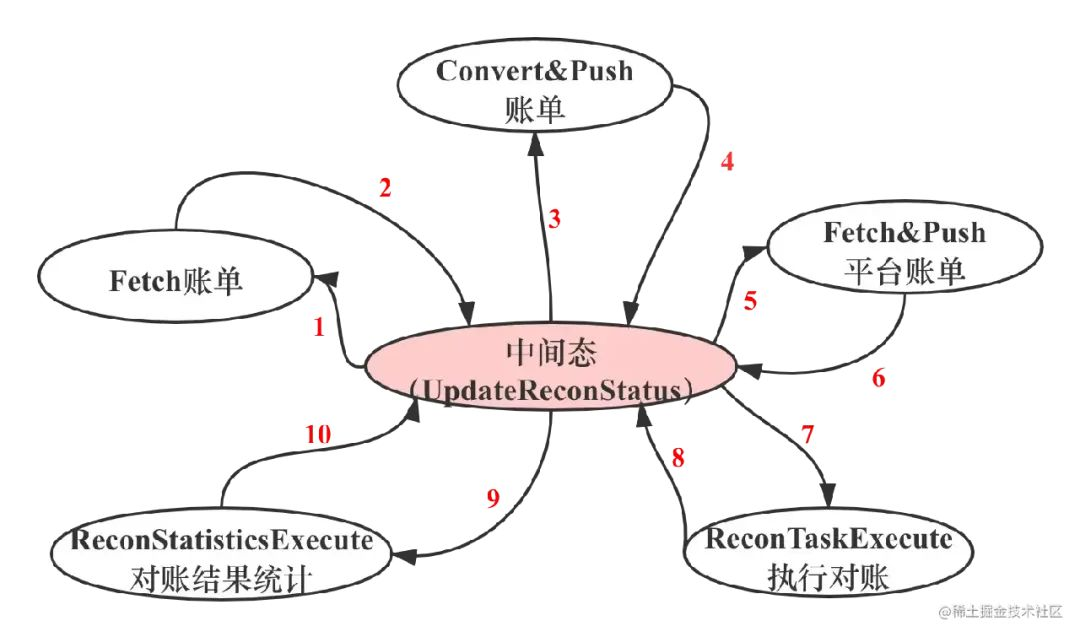
图2 对账系统状态转换图
为了更好的了解每个模块的实现过程,下面将依次对各个模块进行说明。
1)设计
文件下载模块主要完成各个外部渠道账单的下载功能。众所周知,聚合支付是聚众家三方机构能力为一体的支付方式,其中三方机构包括支付宝、微信等支付界的领头羊,多样性的支付渠道导致账单下载存在多样性,如何实现多模式、可拔插的文件下载能力成为该模块设计的重点。分析Java设计模式的特点,本模块采用接口模式,符合面向对象的设计理念,可实现快速接入。具体实现类图如图3所示(只展示部分类图)。

图3 文件下载实现类图
下面就以支付宝对账文件下载方式为例,具体阐述一下实现过程。
2)实现
分析支付宝接口文档,目前采用的下载方式为HTTPS,文件格式为.csv的压缩包。根据这些条件,本系统的实现方式如下(只摘取了部分代码)。由于消息中间件Kafka和中间态模块的机制,已经从系统层面考虑了重试的能力,因此不需要考虑重试机制,后续模块也如此。
public interface BillFetcher {// ReconTaskMessage 为kafka消息,// FetcherConsumer为自定义账单下载后的处理方式String[] fetch(ReconTaskMessage message,FetcherConsumer consumer) throws IOException;}
@Componentpublic class AlipayFetcher implements BillFetcher {public AlipayFetcher( BillDownloadService billDownloadService) {Security.addProvider(new BouncyCastleProvider());billDownloadService.register(BillFetchWay.ALIPAY, this);}...public String[] fetch(ReconTaskMessage message, FetcherConsumer consumer) throws IOException {String appId = map.getString("appId");String privateKey = getConvertedPrivateKey(map.getString("privateKey"));String alipayPublicKey = getPublicKey(map.getString("publicKey"), appId);String signType = map.getString("signType");String url = "https://openapi.alipay.com/gateway.do";String format = "json";String charset = "utf-8";String billDate = DateFormatUtils.format(message.getBillDate(), DateTimeConstants.BILL_DATE_PATTERN);String notExists = "isp.bill_not_exist";String fileContentType = "application/oct-stream";String contentTypeAttr = "Content-Type";//实例化客户端AlipayClient alipayClient = new DefaultAlipayClient(url, appId, privateKey, format, charset, alipayPublicKey, signType);//实例化具体API对应的request类,类名称和接口名称对应,当前调用接口名称AlipayDataDataserviceBillDownloadurlQueryRequest request = new AlipayDataDataserviceBillDownloadurlQueryRequest();// trade指商户基于支付宝交易收单的业务账单// signcustomer是指基于商户支付宝余额收入及支出等资金变动的帐务账单request.setBizContent("{" +""bill_type":"trade"," +""bill_date":"" + billDate + """ +" }");AlipayDataDataserviceBillDownloadurlQueryResponse response = alipayClient.execute(request);if(response.isSuccess()){//do 根据下载地址获取对账文件,通过流式方式将文件放到指定的目录下...System.out.println("调用成功");} else {System.out.println("调用失败");}}}
具体步骤:
重写构造方法,将实现类注入到一个map中,根据对应的下载方式获取实现类;
实现fetch接口,包括构造请求参数、请求支付宝、解析响应结果、采用流式将文件放入对应的目录下,以及这个过程中的异常处理。
1)设计
前面提到,聚合支付是面对不同的外部渠道,对账文件的多样性不言而喻。比如微信是采用txt格式,支付宝采用csv格式等等,而且各个渠道的账单内容也是不一致的。如何解决渠道之间账单的差异性成为该模板需要重点考虑的问题。通过调研和现有对账系统的分析,本系统采用接口模式+RDF(结构化文本文件)的实现方式,其中接口模式解决账单多模式的问题,同时也实现可拔插的机制,RDF工具组件实现账单的快速标准化,操作简单易会。具体实现类图如图4所示(只展示部分类图)。

图4 文件标准化实现类图
下面就以支付宝对账文件解析为例,具体阐述一下实现过程。
2)实现
根据支付宝的账单格式,提前定义RDF标准模板,后续账单解析将根据模板将每一行对账文件解析为对应的一个实体类,其中需要注意标准模板的字段必须要和账单数据一一对应,实体类的字段可以多于账单字段,但必须包括所有的账单字段。接口定义如下:
public interface BillConverter<T> {//账单是否可以使用匹配器boolean match(String channelType, String name);//转换原始对账文件到Hivevoid convertBill(InputStream sourceFile, ConverterConsumer<T> consumer) throws IOException;//转换原始对账文件到Hivevoid convertBill(String localPath, ConverterConsumer<T> consumer) throws IOException;}
具体实现步骤如图5所示:

图5 文件解析流程图
定义RDF标准模板,如下为支付宝业务流水明细模板,其中body结构内字段名必须和实体类名保持一致。
{"head": ["title|支付宝业务明细查询|Required","merchantId|账号|Required","billDate|起始日期|Required","line|业务明细列表|Required","header|header|Required"],"body": ["channelNo|支付宝交易号","merchantNo|商户订单号","businessType|业务类型","production|商品名称","createTime|创建时间|Date:yyyy-MM-dd HH:mm:ss","finishTime|完成时间|Date:yyyy-MM-dd HH:mm:ss","storeNo|门店编号","storeName|门店名称","operator|操作员","terminalNo|终端号","account|对方账户","orderAmount|订单金额|BigDecimal","actualReceipt|商家实收|BigDecimal","alipayRedPacket|支付宝红包|BigDecimal","jiFenBao|集分宝|BigDecimal","alipayPreferential|支付宝优惠|BigDecimal","merchantPreferential|商家优惠|BigDecimal","cancelAfterVerificationAmount|券核销金额|BigDecimal","ticketName|券名称","merchantRedPacket|商家红包消费金额|BigDecimal","cardAmount|卡消费金额|BigDecimal","refundOrRequestNo|退款批次号/请求号","fee|服务费|BigDecimal","feeSplitting|分润|BigDecimal","remark|备注","merchantIdNo|商户识别号"],"tail": ["line|业务明细列表结束|Required","tradeSummary|交易合计|Required","refundSummary|退款合计|Required","exportTime|导出时间|Required"],"protocol": "alib","columnSplit":","}
实现接口的getChannelType、match方法,这两个方法用于匹配具体使用哪一个Convert类。如匹配支付宝账单,实现方式为:
@Overridepublic String getChannelType() {return ChannelType.ALI.name();}@Overridepublic boolean match(String channelType, String name) {return name.endsWith(".csv.zip");}
实现接口的convertBill方法,完成账单标准化;
@Overridepublic void convertBill(String path, ConverterConsumer<ChannelBillPojo> consumer) throws IOException {FileConfig config = new FileConfig(path, "rdf/alipay-business.json", new StorageConfig("nas"));config.setFileEncoding("UTF-8");FileReader fileReader = FileFactory.createReader(config);AlipayBusinessConverter.AlipayBusinessPojo row;try {while (null != (row = fileReader.readRow(AlipayBusinessConverter.AlipayBusinessPojo.class))) {convert(row, consumer);}...}
将标准化账单推送至Hive。
平台数据获取一般都是从数据库中获取,数据量小的时候,查询时数据库的压力不会很大。但是数据量很大时,如电商交易,每天成交量在100万以上,通过数据库查询是不可取的,不仅效率低,而且容易导致数据库崩溃,影响线上交易,这点会在后续的版本迭代中体现。因此,平台数据的抽取是从Hive上获取,只需要提前将交易数据同步到Hive表中即可,这样做不仅效率高,而且更加安全。
考虑到抽取的Hive表不同、数据的表结构,数据收集器Collector类也采用了接口模式。Collector接口定义如下:
public interface DataCollector {void collect(OutputStream os) throws IOException;}
根据目前平台数据收集器实现情况,可以得到类图如图6所示。
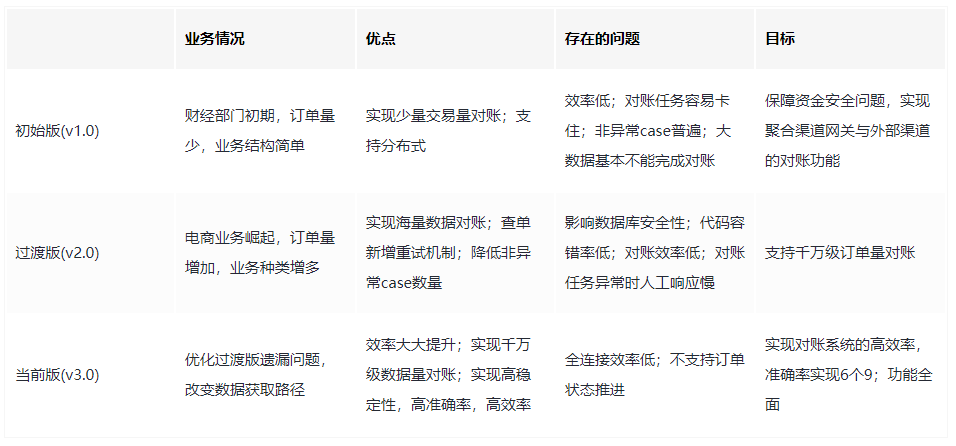
图6 平台数据收集器实现类图
该模块主要完成Hive命令的执行,在平台账单和渠道账单已全部推送至Hive的前提下,利用Hive处理大数据效率高的特点,执行全连接sql,并将结果存入指定的Hive表中,用于对账结果统计。
对账任务执行成功之后,需要统计全连接后的数据,重点统计金额不一致、状态不一致、日切、少账(平台无账,渠道有账)和多账(平台有账,渠道无账)等差异。针对不同的情况,本系统分别采用如下的解决方案:
金额不一致:前端页面展示差异原因,人工进行核对;
状态不一致:针对退款订单,查询平台退款表,存在且金额一致认为已对平,不展示差异,其他情况,需要在前端页面展示差异原因,人工进行核对;
日切:当平台订单为成功,渠道无单时,根据平台订单创建时间判断是否可能存在日切,如果判断是日切订单,会将这笔订单存入buffer文件中,待统计结束后,将buffer文件上传至Hive日切表中,等第二天重新加载这部分数据实现跨日对账。对于平台无订单,渠道有单的情况,通过查询平台数据库判断是否存在差异,如果存在差异,需要在前端页面展示差异,人工进行核对。
少账:目前主要通过查询平台数据库判断是否存在差异,确认确实存在差异时,需要在前端页面展示差异,人工进行核对。
多账:目前这种有可能是日切,会先考虑日切,如果不在日切范围内,需要在前端页面展示差异,人工进行核对。
中间态模块是用于各模块之间状态转换的模块,利用Kafka和状态是否更新的机制,实现消息的重发和对账状态的更新。从一个状态到下一个状态,必须满足当前状态为成功,对账流程才会往下一步执行。中间态的设计不仅解决了重试问题,而且将数据库的操作进行了收敛,更符合模块化的设计,各个模块各司其职。重试次数也不是无限的,目前设置的重试次数为3次,如果3次重试后依然没有成功,会发lark通知,人工介入解决。
总之,对账工作,既复杂也不复杂,需要我们细心,对业务要有深入的了解,并选择合适的处理方式,针对不同的业务,不断迭代优化系统。
四、版本迭代
系统的设计很大程度受业务规模的影响,对于财经聚合支付而言,订单量发生了几个数量级的变化,这个过程中不断暴露出对账系统存在的问题,优化改进对账系统是必然的事。从系统设计到目前大致可以分为三个阶段:初始阶段、过渡阶段和当前阶段。
初始版上线后实现了聚合渠道对账的自动化,尤其在2018年的春节活动中,资金安全提供了重要的保障,实现了聚合和老合众、支付宝、微信等渠道的对账。随着财经业务的发展,抖音电商的快速崛起,对账系统逐渐暴露出不足,比如对账任务失败增多,尤其是数据量大的对账、非正常差异结果展示、对账效率低等问题。通过不断分析,发现存在以下几个问题:
系统的文件都是放在临时目录tmp下的,TCE平台会对这个目录下的文件定时清理,导致推送文件到Hive时会报找不到文件的情况,尤其是大数据量的对账任务;
Kafka消息积累多,导致对账流程中断,主要是新增渠道,对账任务增加,同时Hive执行队列是共享队列,大部分的对账流程因为没有资源而卡住;
非正常差异结果展示,主要是查单没有增加重试机制,当查询过程中出现超时等异常,会出现非正常差异结果,还有部分原因是日切跨度小而导致的非正常差异结果。
考虑到初始版对账系统存在的不足和对账功能的急迫性,对初始版进行过渡性的优化,初步实现大数据量的对账功能,同时也提高了差异结果的准确率。相比初始版,该版本主要进行了以下几点优化:
文件存放目录由临时目前改为服务下的某一个目录,防止大文件被回收,文件上传到Hive后删除文件;
重新申请独占的执行队列,解决资源不足导致对账流程卡住的问题;
查单新增重试机制,日切跨度增大,解决非正常差异结果展示,提供差异结果的准确率。
过渡版集中解决初始版明显存在的问题,对于一些潜在的问题并没有彻底解决,如代码容错率低、对账任务异常后人工响应慢、对账效率低、数据库安全性低等问题。
当前版优化的宗旨是实现对账系统的"三高",分别为高效率、高准确率(6个9)和高稳定性。
对于高效率,主要体现在平台数据获取慢,而且存在数据库安全问题,针对这块逻辑进行了优化,改变数据获取途径,由原来的数据库获取改为从高效率的Hive中获取,只需要提前将数据同步到Hive表中即可。
对于高准确率,主要优化对账差异处理逻辑,进一步细化差异处理方式,新增差异结果报警,细化前端页面差异原因。
对于高稳定性,主要优化RDF处理对账文件发生异常时新增兜底逻辑,提高系统的容错性;对账任务失败或超过指定重试阈值时增加报警,加快人工响应速率;对查单等操作数据库逻辑增加限流,防止数据库崩溃。
版本迭代过程可以总结如下,希望读者别重复入坑,尤其是大文件处理方面。
总结
对账系统模型与业务息息相关,业务不同,对账系统模型也会不同,但是大部分对账系统的整体架构变化不大,主要区别是各个模块的实现方式不同。希望本文介绍的对账系统能为各位读者提供设计思路,避免重复入坑。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721