

(点击底部这里获取欧阳辰演讲完整PPT)
讲师介绍
欧阳辰,超过15年的软件开发和设计经验,目前就职于小米公司,负责小米广告平台的架构研发。
曾为微软公司工作10年,担任高级软件开发主管,领导团队参与微软搜索索引和搜索广告平台的研发工作。曾在甲骨文公司从事数据库和应用服务器的研发工作。热爱架构设计和高可用性系统,特别对于大规模互联网软件的开发,具有丰富的理论知识和实践经验。
大家好,很高兴能跟大家分享一些关于实时数据分析的话题。
刚毕业时我有幸去了Oracle公司做企业软件数据库,成为Oracle中国第一批研发员工。后来做了几年,觉得还是想做互联网软件,就去了微软,工作了十年左右。在那做两个项目,一个是搜索,一个是广告平台。去年一月份加入小米公司,现在主要负责搭建广告平台和大数据平台。
所以今天我会结合我在小米、微软的一些大数据实践,给大家谈谈我对大数据的理解,并介绍一些好用的工具。
本次演讲的内容大致分为以下部分:
大数据和价值
大数据分析工具分类
HBase的应用和改进
Druid的实时分析实践
其它工具的探索
一、大数据和价值
什么是大数据?众说纷纭。大家似乎觉得具备快、多、变化大、种类多四个特征的数据就是大数据,我个人更愿意从另一个角度来定义:只有当你拥有全量的数据,并通过非常多的数据把问题解决得比较完美时,这时候的问题才是叫做大数据问题。
给大家举个例子:比如说计算中国的人口,我们可以通过每省、每市、每区的抽样、采样等方法来获取非常接近真实的数据,很快就能完成这个任务。但是这个通过采样解决人口统计问题的场景是否就是大数据问题呢?再给大家举一个我自己在做的大数据问题——广告系统的推荐。由于每个人看的广告内容、类型都是不一样的,你需要对每个人去做算法,通过数据分析挖掘每个人的数据潜力。假设现在你想通过一些算法找到一些用户喜欢的广告或者内容,而这时你要找到的内容少了一半,你就没法推算出一半用户的数据,这时候你的效果也差了一半。也就是说你的数据量越多,覆盖越多用户,效果越好时,这时候我们可以认为它是一个真正的大数据问题。

大数据外表光鲜亮丽,就像红楼梦里的大观园,但里面其实是很无奈的。做大数据技术的同学都知道,这里面涉及到数据的清洗、整理、存储等很多很多枯燥的事情。此外,大数据还有一个特点,就是当你有了大数据,还得想如何去变现。在我看来,大数据实际上很难找到一个直接的途径来变现,它的确可以去推动业务的智能化,做内容推荐让用户的体验更好,但这些都是一些间接的变现场景,真正大数据能够变现的场景,我自己总结了一下,大概有两个方向:一个是广告,二是银行的征信系统,除了这两个领域之外,很少有公司愿意为数据买单。
下面简单介绍小米的大数据技术框架。
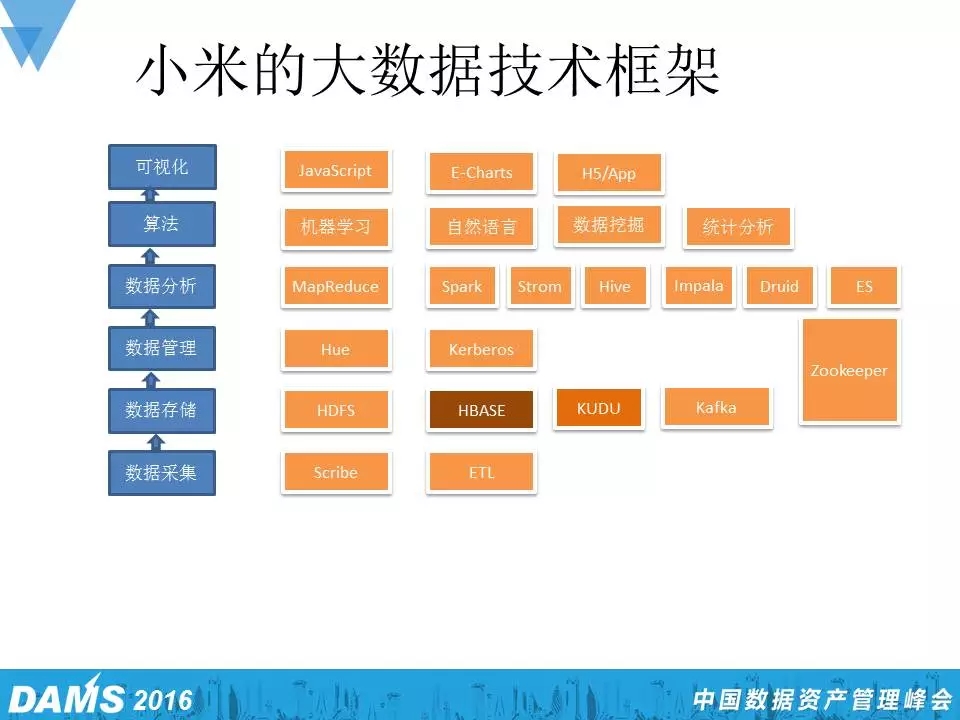
和很多公司类似,小米的大数据框架也包括数据采集、存储、管理、分析、算法和可视化。大部分组件都是开源的,另外我们会对一些核心的组件做一些深加工或者优化、自定义。其中,在数据采集部分就是Scribe,存储用得较多的还是HBase,后面我会介绍小米在这一块的优化。管理上我们用了Kerberos去做认证,在上面还有一些Spark、Storm、Hive、Impala和Druid。
说到大数据应用,种类非常多,我简单讲一下小米在大数据上的一些应用。

首先是精准营销,我们可以对每个用户做一些画像。用在搜索和推荐上,让它变得更加精准;还有互联网金融,有一些征信体系可以用到;精细化运营;还有防黄牛,因为小米手机的性价比较高,很多时候新品出来时黄牛们会去抢,另一方面,现在的黄牛手段越来越高明了,他们会模拟很多IP、新的账号或者老的账号等一些复杂的购买行为,所以就很需要采取一些手段去防黄牛。还有图片、图像的分析和处理,像小米手机新推出的宝宝相册等。
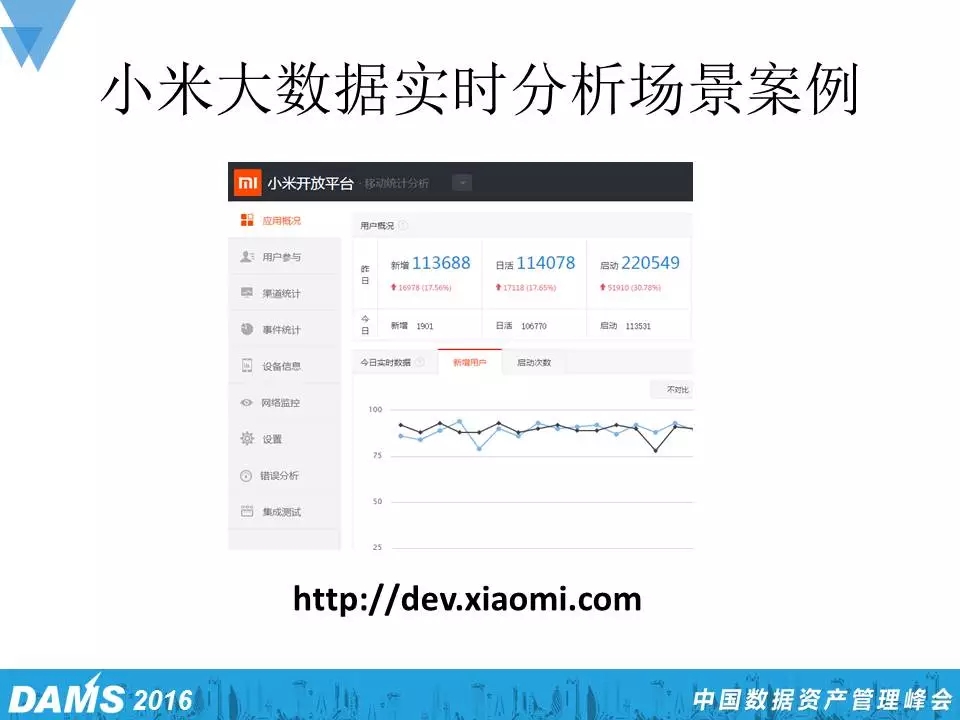
刚刚说的是一些业务的场景,还有一些给开发者用的场景。
比如说小米推出的一个数据统计分析平台,它提供一些API让你嵌进去,可以用数据分析你的应用使用情况。然后结合小米的用户画像,为开发者提供更好的数据分析服务。
目前小米日活超过千万的APP大概有二十几家,包括浏览器、应用商店、视频等,这些应用实时分析的需求非常旺盛,他们都是用这一套系统去做数据打点、AB测试、画像、分组等,所以在后面我们需要一个吞吐量大的实时数据分析处理系统来承担这部分计算的任务。
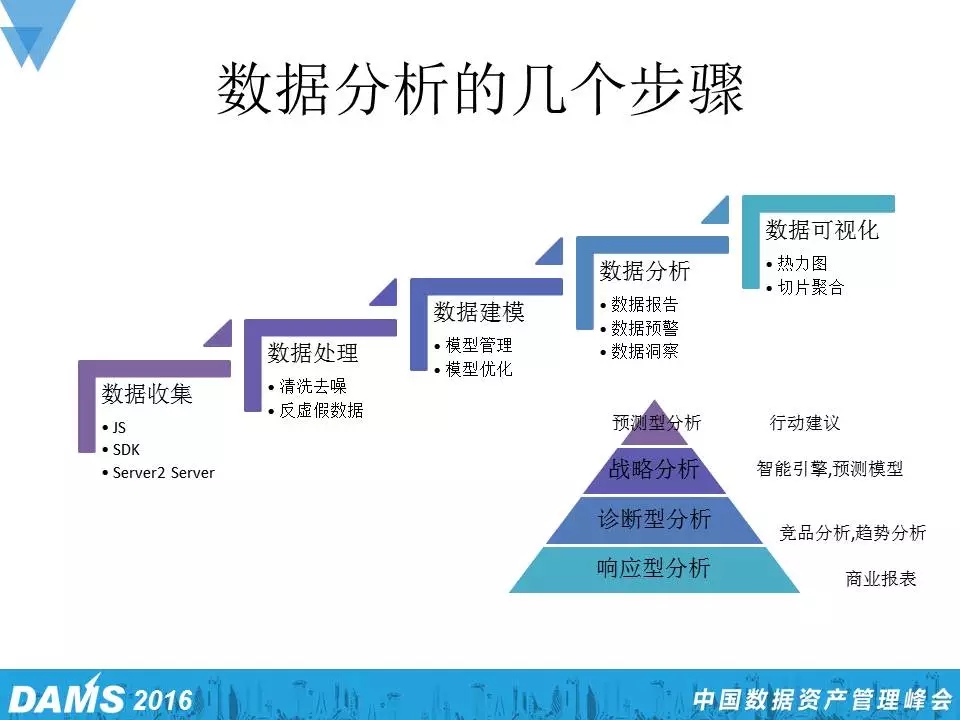
说到数据分析的步骤,最开始是数据收集,然后处理,清洗,建模,分析,最后可视化。这是大概的基本步骤。
从数据分析的类型来看,也可以分为四个层次:最下面是一个比较基础的层次,叫响应型分析,基本上是按照商业需求出商业报表。第二个层次叫诊断型分析,就是说当你有了很多数据以后,从数据里面挖掘出一些问题,或者通过数据去解释这些问题,像一些竞品分析、趋势分析。第三个层次叫战略分析,这个层次相对前面两个层次来说比较难了,即在做很多公司的分析时,你需要建个模型,然后用数据去得出一些结论,很多咨询公司就提供这种战略分析,像麦肯锡、贝恩等公司很多时候就是在这一层次做事情。最后一个层次也难,叫预测型分析。你不光要建好模,还要想到底怎么做,采用什么样的行动,给出真正的建议。
二、大数据分析工具
小米统计平台承接的数据量非常大,而且对实时的要求非常高,所以在工具的选取上也花了很多时间。下面给大家介绍一下小米在大数据实时处理时一些工具选型的思路。
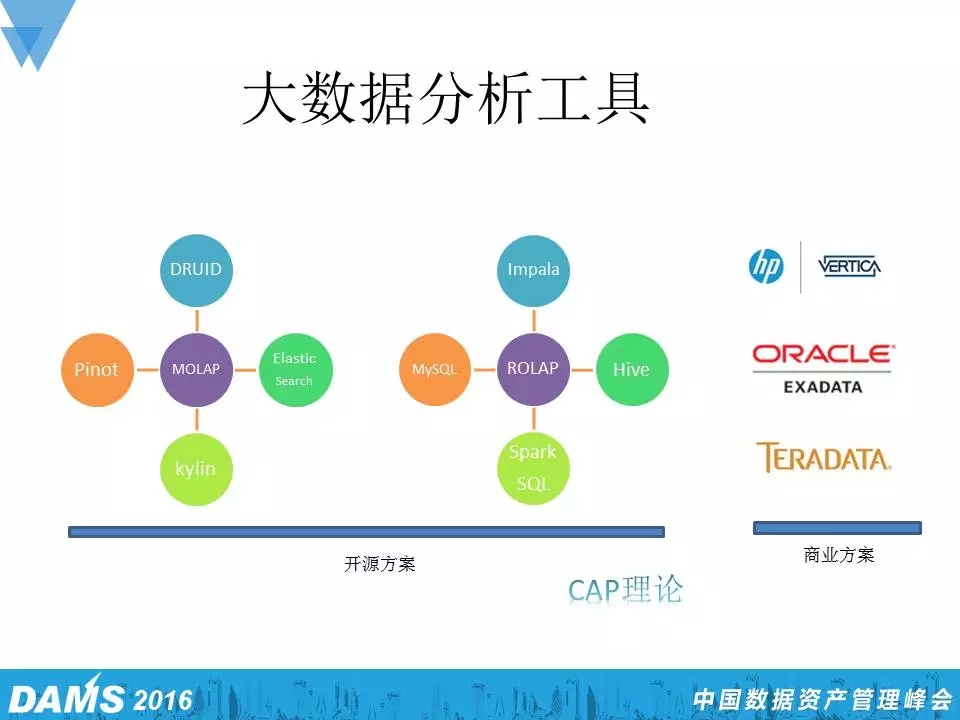
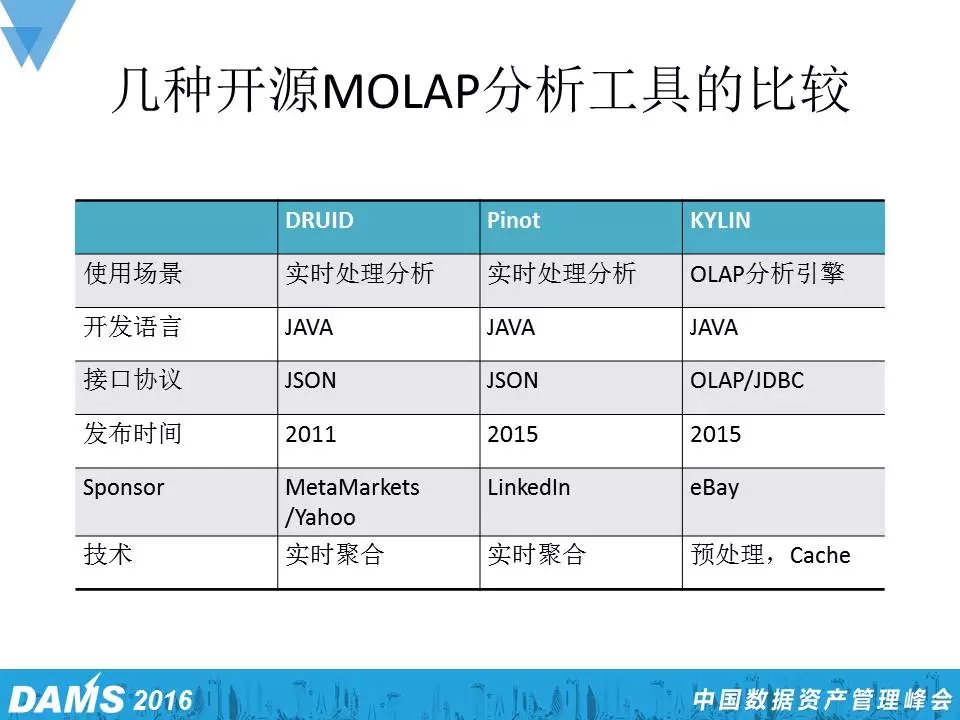
实时分析不是一个新问题,但如果上到亿万级的数据量时,这个问题也显得非常重要。在数据分析尤其是多维分析这块,有几个流派,一个流派是开源的工具,还有一个流派是商业的工具。商业的工具中有几家比较有名,一个是惠普的Vertica,一个是Oracle,Oracle的不足之处就是太贵了,成本较高,还有就是Teradata,美国加州一个老牌的多维数据分析公司。在另一边的开源软件,也可大概分为两个流派,一个叫做MOLAP ,它在设计之初就是想把数据结构变成一个多维数据库,这样查询起来既快又方便;另一个叫ROLAP,企图用传统关系型数据库去构建多维数据库,因为像MySQL、Hive这种传统数据库是非常方便的。总的来说,开源的大概有两条路,一条就是原生的支持多维的,另一条就是通过关系型数据库去模拟这种多维查询。原生多维这边工具的话,小米用的比较多的就是Druid,Pinot,Kylin和ElasticSearch。

在选数据分析工具的时候需要考虑很多事情,像一些很重要的数据量,还有就是你需要分析这些数据的维度有多少,你的用户并发度,这些都是实际过程中需要考虑的重要因素。特别是维度,维度越多,系统会越复杂。
刚刚前面讲到小米的统计工具,这里再放一张小米统计后台的架构图,我把它稍微简化了一下:
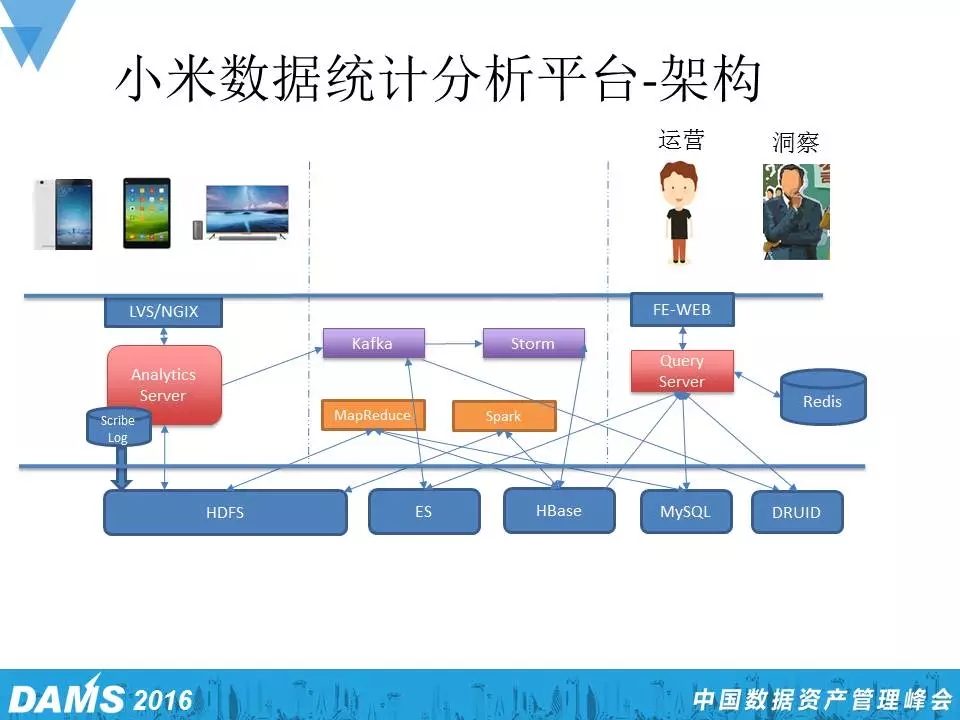
首先是手机、电视、电脑把事件通过网络打开小米分析服务器,这时服务器有两条路,一条路是把Log存在 Scirbe里面,然后通过MapReduce和HDFS去做计算和存储,结果会放到MySQL数据库和HBase中,另外一条路则是所有事件来了以后,经过Kafka以及Storm的计算集群把预计算算好,最后存到HBase中。所以在小米统计平台上像分钟级的数据都是从上面这条路来的,按天的数据则是从下面这条路来的,我们每天会用完整跑的Log去取代实时的数据,大概是这样一个过程。
三、HBase的应用和改进

小米用HBase还是蛮多的,HBase是一个比较有名的列式存储,我们公司也有三个HBase Committer,对HBase做了很多改进。比如对源代码的改进,改完以后我们又会把这些改进返回到开源社区。再如名字服务,以前的话,HBase访问要填很多Server名、端口名,现在用一个名字就可以访问,包括HBase是不支持二级索引的,我们往里面增加了索引功能。

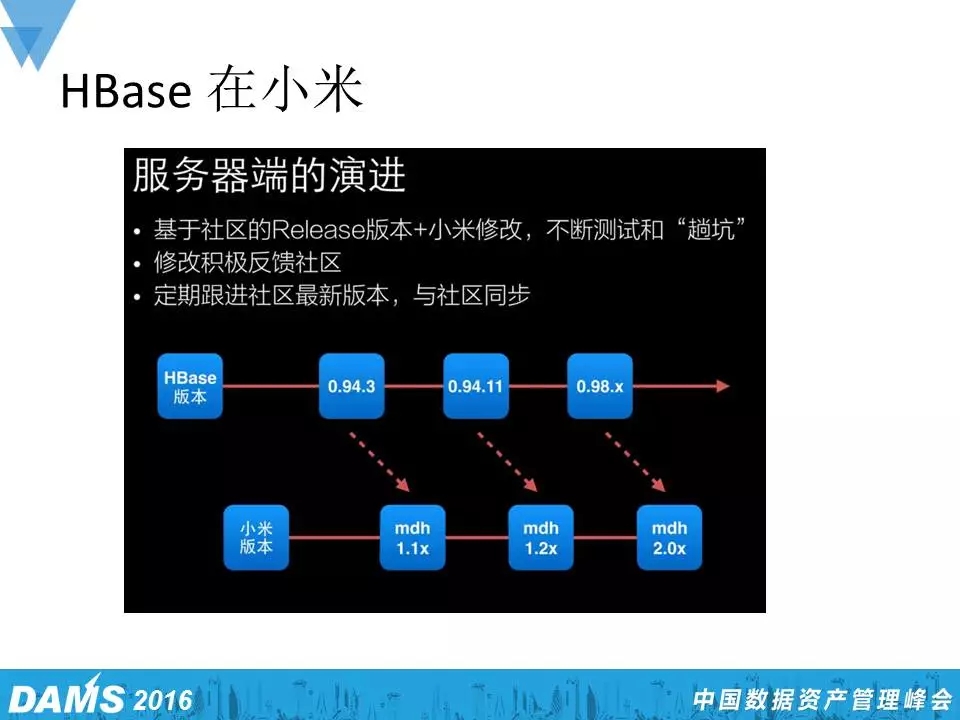
在服务器端改进的过程中,我们发现有些改进可以反馈到社区,但有些反馈回去时整个审核流程特别慢,以至于后来小米内部慢慢、逐步地就演变成了一个官方的版本,长期来看,这两个版本的融合值得深思熟虑。
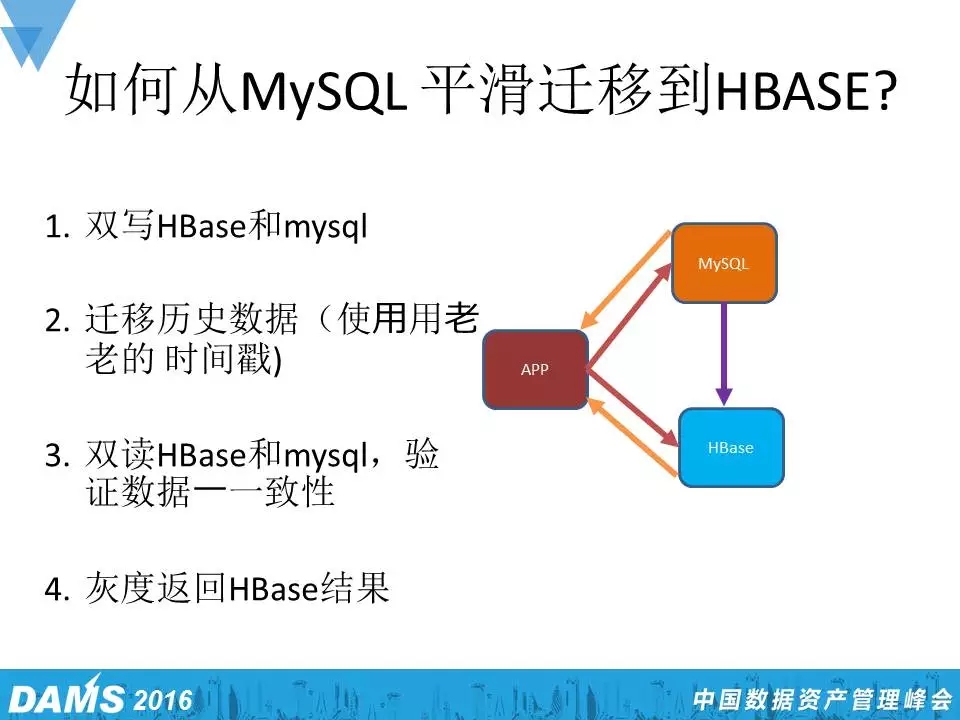
小米在初期时很多业务是使用MySQL的,因为相对来说简单粗暴,但它的容量有限。业务容量扩张以后,小米大概有两亿个用户,1.5亿个月活用户,日活也超过一亿多,MySQL一般来说是撑不住的,这个时候很多业务就需要迁移到HBase上。
因此,最后小米提出一个很Common的HBase迁移方法,在最开始写数据的时候双写,既写HBase又写MySQL的,保证新的数据会同时存在于HBase和MySQL里,第二个就是把MySQL中的历史数据迁移到HBase,这样从理论上两个数据库就能拥有同样的内容了。第三个是双读HBase和MySQL,校验数据是不是都一致,一般达到99.9%的结果时,我们就认为迁移是比较成功的。最后灰度返回到HBase结果。
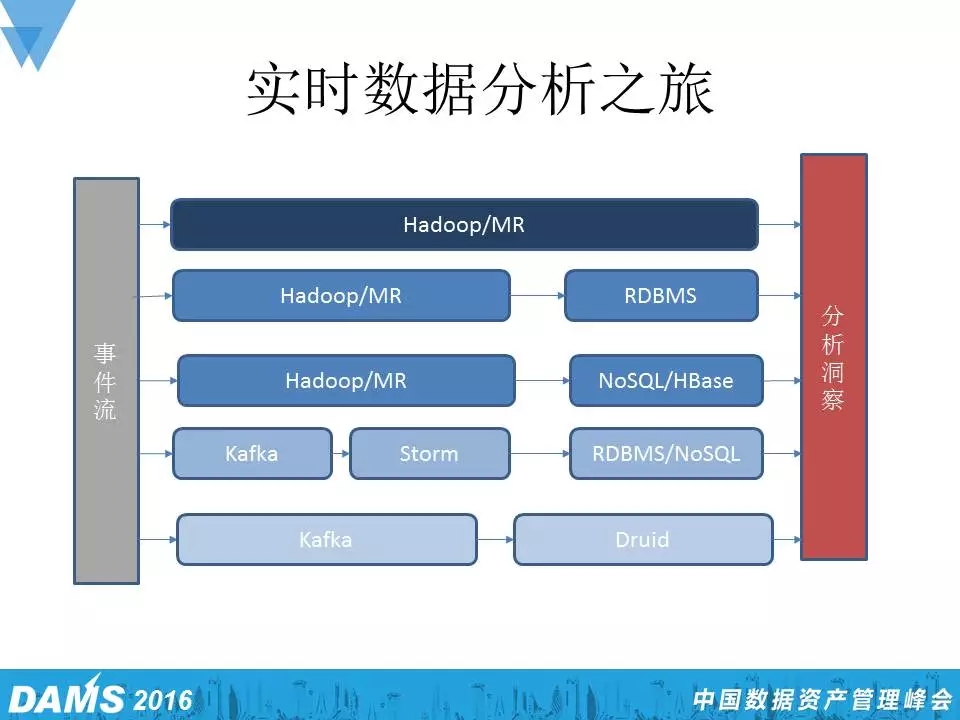
四、Druid的实时分析实践
一开始做小米统计平台时,数据其实也没有做到实时的,都是走上面的一条路,第二个阶段通过MapReduce处理以后,把数据放到关系型数据里面,比如像MySQL这样的数据库。再后来,业务慢慢扩展,RDBMS的容量有限,出现很多问题,所以到第三个阶段我们把RDBMS变成HBase,这个阶段也持续了很久,再后来我们想得到实时的数据,来到第四步,通过Kafka、Storm再到RDBMS或者NoSQL,最后一步我们直接是把数据从Kafka转到Druid。
Druid由一家叫MetaMarkets的公司开发,目前像Yahoo、小米、阿里、百度等公司都在用它大量地做一些数据的实时分析,包括一些广告、搜索、用户的行为统计。它的特点包括:
为分析而设计
为OLAP而生,它支持各种filter、aggregator和查询类型。
交互式查询
低延迟数据,内部查询为毫秒级。
高可用性
集群设计,去中性化规模的扩大和缩小不会造成数据丢失。
可伸缩
现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。
与Druid相类似的实时数据分析工具,还有Linkedln的Pinot和eBay的Kylin,它们都是基于Java开发的。Druid相对比较轻量级,用的人也多,毕竟开发时间久一些,问题也少一些。

Druid在小米内部除了应用于小米统计之外,还应用于广告系统。小米的广告系统主要是对每个广告的请求、点击、展现做一些分析,一条线是通过Kafka→Druid→数据可视化显示,另外一条路就是完整数据落盘到HDFS,每天晚上通过数据重放去纠正Druid里的一些数据,覆盖Druid的准确数据,最后做可视化。
五、其它工具的探索
Pinot

Pinot,Linkedln开发的类似于Druid的多维数据分析平台,它的功能实际上要比Druid强大一些,但因为去年才刚刚开始开源,用的人比较少。大家有兴趣的可以去试试。它的整个代码量也比较大,架构与Druid也非常相似,但它引入了更好的一种协调管理器,更多的是一种企业级别的设计,更加完整、规范。
Kylin

Kylin是eBay的开源分析工具,它的优点就是很快,特别适合每天定时报表,缺点也很明显,就是随机查询很慢。它还有一个好处就是支持标准的SQL,与Tableau等BI工具集成,可以直接连到eBay的这个Kylin工具。而且,Kylin在Fast Cubing上做了一些预处理,反应较快。
KUDU
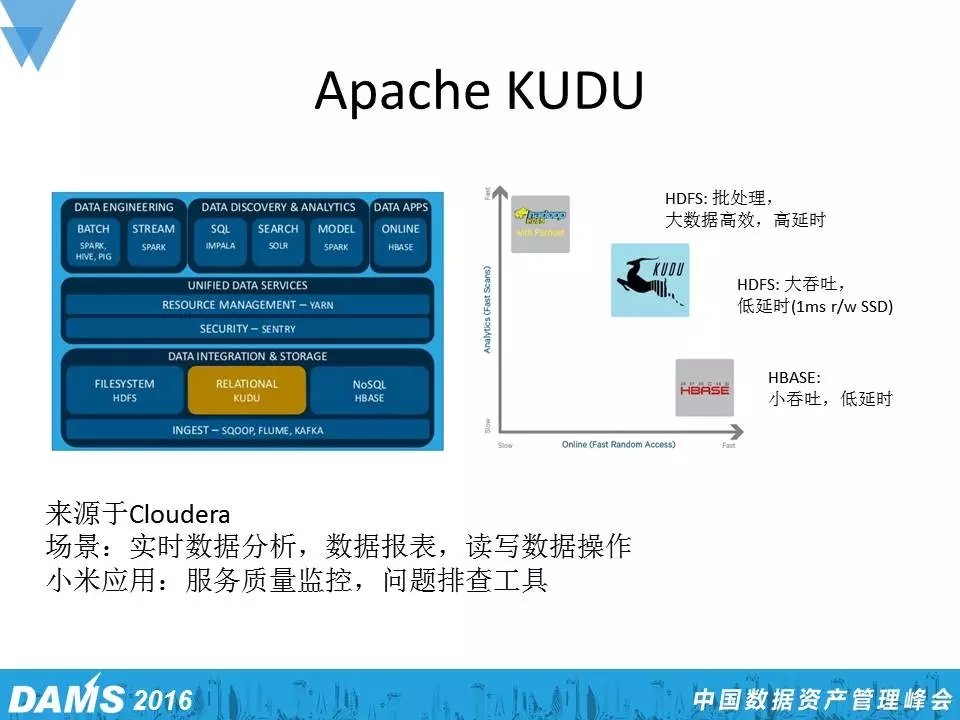
KUDU是去年十月份Apache开源的一个工具,与小米联合发布。它的定位是什么呢?大家都知道Druid是一个批处理、高容量的查询系统,响应时间很慢,而HBase可以支持快速的响应时间,但它主要是一个写少读多的情况。
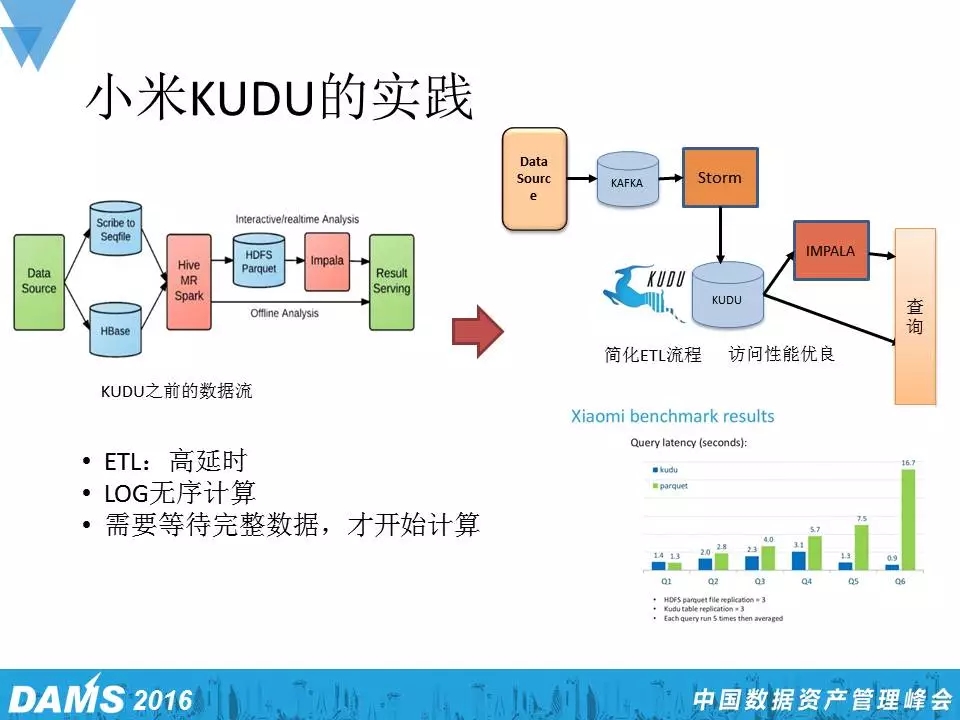
KUDU,走在这两个极端的中间,它既能够保证大吞吐,又可以保证低延时。小米从去年十月份开始使用KUDU,主要用于一些服务质量监控、问题排查,总体感觉还不错。小米也是KUDU现在最大的一个用户,因为我们很多时候需要考虑HBase和Druid综合的一些优点,所以KUDU也是小米目前实验的一个工具。
ElasticSearch
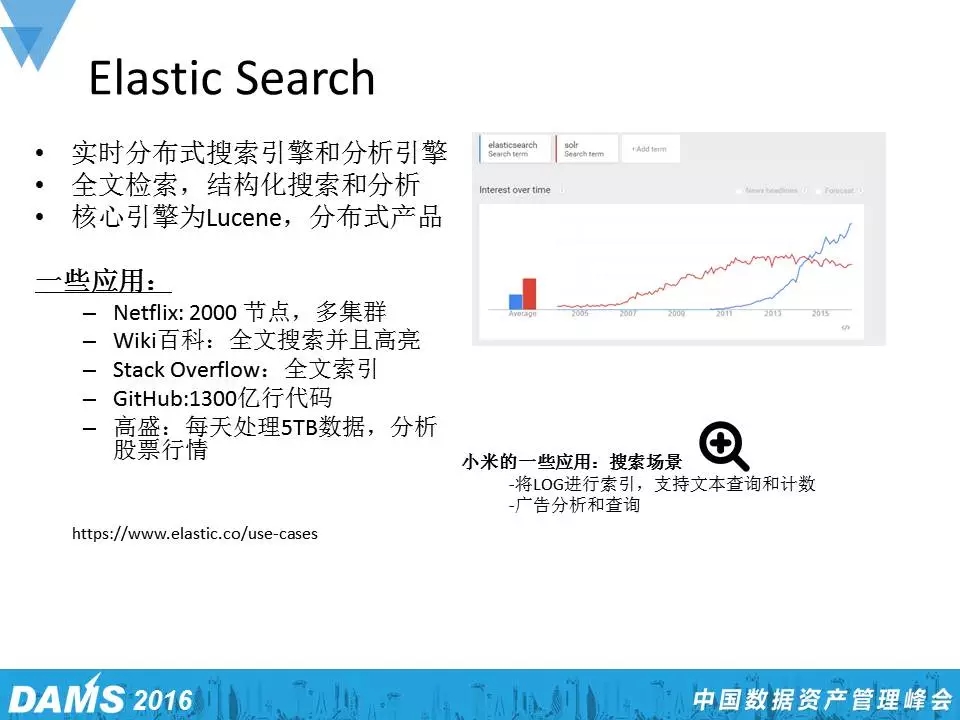
ElasticSearch可能很多公司都有实践,同样可以对LOG和信息做一些倒排表,核心是用Lucene去做索引。
最后,小米虽然每天都在处理大数据、各种用户的数据,但我自己的信念就是“我们需要像保护自己的眼睛一样保护用户的隐私”,小米在用户隐私这方面投资了很多,并做出了明确的规定。

在欧洲,很多公司内部会把数据分成很严格的等级,像个人信息,所有可以关联到个人的信息都是存在一个独立的库,任何人都没有权限去访问。还有一些普通信息,大家是可以用的,还有比如说超过一万人的一些聚合信息,可以拿去做一些算法。但个人信息是坚决不可以访问的。而在2006年4月14日,欧洲当时还推出了一个非常酷的隐私权保护条例,它定义了每个公司要设立首席数据官,来保护数据隐私,并且要求每个公司数据都是可迁移的,也就是说,你的公司虽然拥有数据,但数据有权利把属于他的个人信息从一个服务商转移到另外一个服务商。
分享的最后,总结一下我做数据分析多年来的心得:
1、没有业务应用的大数据都是耍流氓,不要纯粹去找工具,一定要结合业务去选择。
2、技术选型没有想象中那么重要,实用和精通为妙。
3、维度不够是一个永远的痛,无尽的伤。在数据分析的过程中,维度是不断增加的。所以在未来选择工具的同时,一定要考虑维度的增加。
4、像保护你的眼睛一样去保护用户的权利和隐私。
技术分享:[线上1-50期] [北京站] [上海站] [广州站] [杭州站] [济南站] [Gdevops杭州站] [Gdevops北京站] [DAMS 2016]
专家专栏:[杨志洪] [杨建荣] [陈能技] [丁俊] [卢钧轶] [李海翔] [魏兴华] [邹德裕] [周正中] [高强] [白鳝] [卢飞] [王佩]
热门话题:[Oracle] [MySQL] [DB2] [大数据] [PostgreSQL] [云计算] [DevOps] [职场心路] [其他]
近期活动:
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721