
背景
Flink + Kafka 平台化设计
Kafka 在实时数仓中的应用
问题 & 改进
一、背景介绍
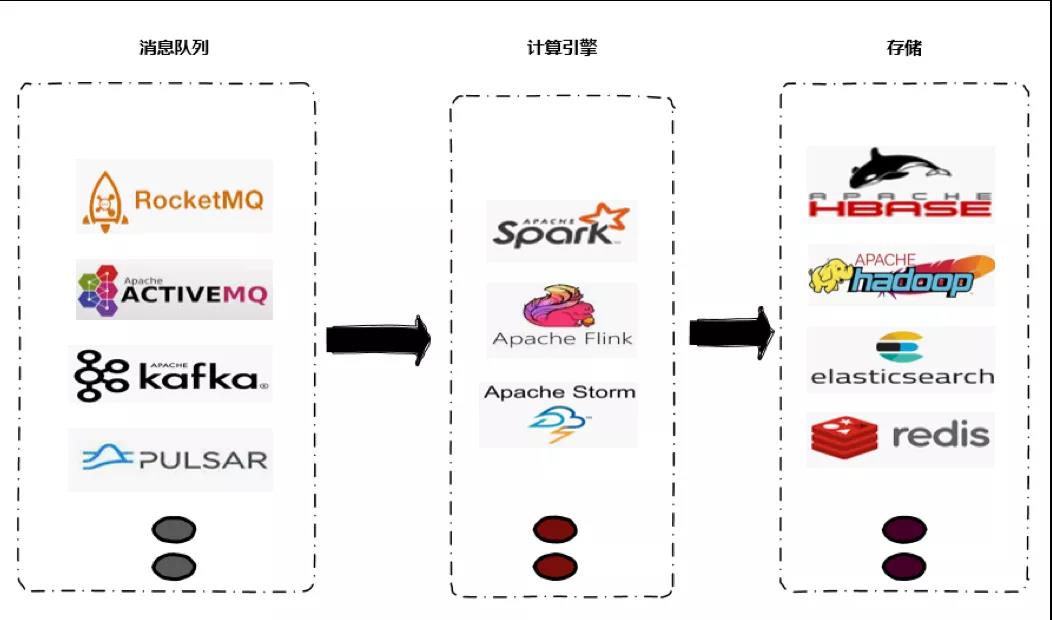
目前流平台通用的架构一般来说包括消息队列、计算引擎和存储三部分,通用架构如下图所示。客户端或者 web 的 log 日志会被采集到消息队列;计算引擎实时计算消息队列的数据;实时计算结果以 Append 或者 Update 的形式存放到实时存储系统中去。
目前,我们常用的消息队列是 Kafka,计算引擎一开始我们采用的是 Spark Streaming,随着 Flink 在流计算引擎的优势越来越明显,我们最终确定了 Flink 作为我们统一的实时计算引擎。
Kafka 是一个比较早的消息队列,但是它是一个非常稳定的消息队列,有着众多的用户群体,网易也是其中之一。我们考虑 Kafka 作为我们消息中间件的主要原因如下:
高吞吐,低延迟:每秒几十万 QPS 且毫秒级延迟;
高并发:支持数千客户端同时读写;
容错性,可高性:支持数据备份,允许节点丢失;
可扩展性:支持热扩展,不会影响当前线上业务。
Apache Flink 是近年来越来越流行的一款开源大数据流式计算引擎,它同时支持了批处理和流处理,考虑 Flink 作为我们流式计算引擎的主要因素是:
高吞吐,低延迟,高性能;
高度灵活的流式窗口;
状态计算的 Exactly-once 语义;
轻量级的容错机制;
支持 EventTime 及乱序事件;
流批统一引擎。
基于 Kafka 和 Flink 的在消息中间件以及流式计算方面的耀眼表现,于是产生了围绕 Kafka 及 Flink 为基础的流计算平台体系,如下图所示:基于 APP、web 等方式将实时产生的日志采集到 Kafka,然后交由 Flink 来进行常见的 ETL,全局聚合以及Window 聚合等实时计算。

目前我们有 10+个 Kafka 集群,各个集群的主要任务不同,有些作为业务集群,有些作为镜像集群,有些作为计算集群等。当前 Kafka 集群的总节点数达到 200+,单 Kafka 峰值 QPS 400W+。目前,网易云音乐基于 Kafka+Flink 的实时任务达到了 500+。
二、Flink+Kafka 平台化设计
基于以上情况,我们想要对 Kafka+Flink 做一个平台化的开发,减少用户的开发成本和运维成本。实际上在 2018 年的时候我们就开始基于 Flink 做一个实时计算平台,Kafka 在其中发挥着重要作用,今年,为了让用户更加方便、更加容易的去使用 Flink 和 Kafka,我们进行了重构。
基于 Flink 1.0 版本我们做了一个 Magina 版本的重构,在 API 层次我们提供了 Magina SQL 和 Magina SDK 贯穿 DataStream 和 SQL 操作;然后通过自定义 Magina SQL Parser 会把这些 SQL 转换成 Logical Plan,在将 LogicalPlan 转化为物理执行代码,在这过程中会去通过 catalog 连接元数据管理中心去获取一些元数据的信息。我们在 Kafka 的使用过程中,会将 Kafka 元数据信息登记到元数据中心,对实时数据的访问都是以流表的形式。在 Magina 中我们对 Kafka 的使用主要做了三部分的工作:
集群 catalog 化;
Topic 流表化;
Message Schema 化。
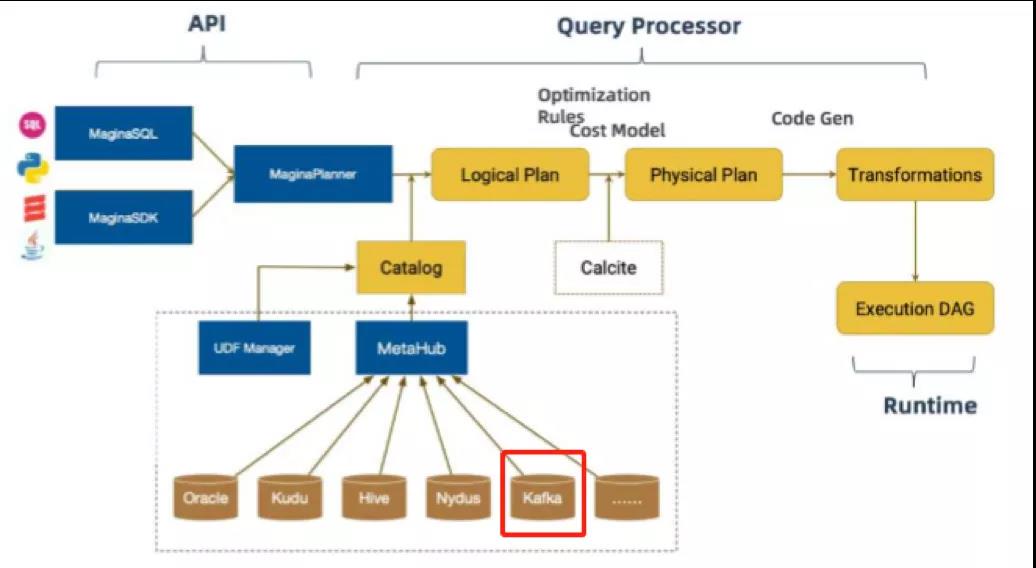
用户可以在元数据管理中心登记不同的表信息或者 catalog 信息等,也可以在 DB 中创建和维护 Kafka 的表,用户在使用的过程只需要根据个人需求使用相应的表即可。下图是对 Kafka 流表的主要引用逻辑。

三、Kafka 在实时数仓中的应用
Kafka 在实时数仓使用的过程中,我们遇到了不同的问题,中间也尝试了不同的解决办法。
在平台初期, 最开始用于实时计算的只有两个集群,且有一个采集集群,单 Topic 数据量非常大;不同的实时任务都会消费同一个大数据量的 Topic,Kafka 集群 IO 压力异常大;
因此,在使用的过程发现 Kafka 的压力异常大,经常出现延迟、I/O 飙升。
我们想到把大的 Topic 进行实时分发来解决上面的问题,基于 Flink 1.5 设计了如下图所示的数据分发的程序,也就是实时数仓的雏形。基于这种将大的 Topic 分发成小的 Topic 的方法,大大减轻了集群的压力,提升了性能,另外,最初使用的是静态的分发规则,后期需要添加规则的时候要进行任务的重启,对业务影响比较大,之后我们考虑了使用动态规则来完成数据分发的任务。
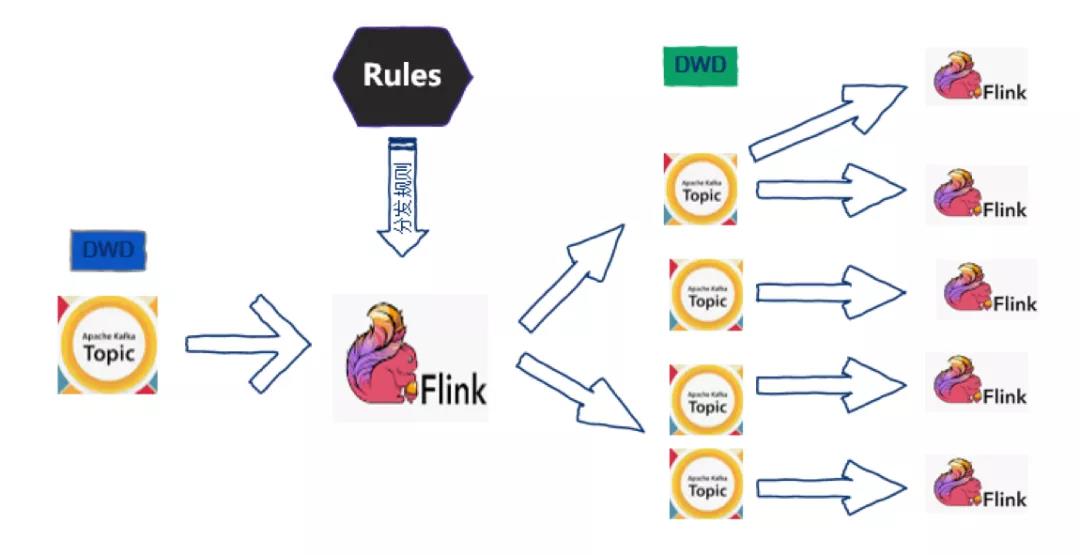
解决了平台初期遇到的问题之后,在平台进阶过程中 Kafka 又面临新的问题:
虽然进行了集群的扩展,但是任务量也在增加,Kafka 集群压力仍然不断上升;
集群压力上升有时候出现 I/O 相关问题,消费任务之间容易相互影响;
用户消费不同的 Topic 过程没有中间数据的落地,容易造成重复消费;
任务迁移 Kafka 困难。
针对以上问题,我们进行了如下图所示的 Kafka 集群隔离和数据分层处理。其过程简单来说,将集群分成 DS 集群、日志采集集群、分发集群,数据通过分发服务分发到 Flink 进行处理,然后通过数据清洗进入到 DW 集群,同时在 DW 写的过程中会同步到镜像集群,在这个过程中也会利用 Flink 进行实时计算的统计和拼接,并将生成的 ADS 数据写入在线 ADS 集群和统计 ADS 集群。通过上面的过程,确保了对实时计算要求比较高的任务不会受到统计报表的影响。
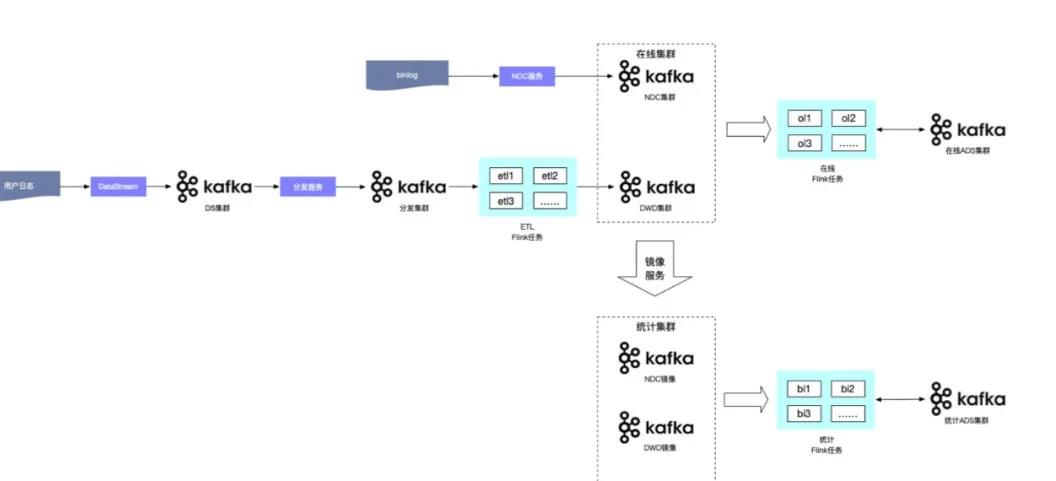
通过上面的过程,确保了对实时计算要求比较高的任务不会受到统计报表的影响。但是我们分发了不同的集群以后就不可避免的面临新的问题:
如何感知 Kafka 集群状态?
如何快速分析 Job 消费异常?
针对上面两个问题,我们做了一个 Kafka 监控系统,其监控分为如下两个维度,这样在出现异常的时候就可以进行具体判断出现问题的详细情况:
集群概况的监控:可以看到不同集群对应的 Topic 数量以及运行任务数量,以及每个 Topic 消费任务数据量、数据流入量、流入总量和平均每条数据大小;
指标监控:可以看到 Flink 任务以及对应的 Topic、GroupID、所属集群、启动时间、输入带宽、InTPS、OutTPS、消费延迟以及 Lag 情况。
流批统一是目前非常火的概念,很多公司也在考虑这方面的应用,目前常用的架构要么是 Lambda 架构,要么是 Kappa 架构。对于流批统一来讲需要考虑的包括存储统一和计算引擎统一,由于我们当前基建没有统一的存储,那么我们只能选择了 Lamda 架构。
下图是基于 Flink 和 Kafka 的 Lambda 架构在云音乐的具体实践,上层是实时计算,下层是离线计算,横向是按计算引擎来分,纵向是按实时数仓来区分。
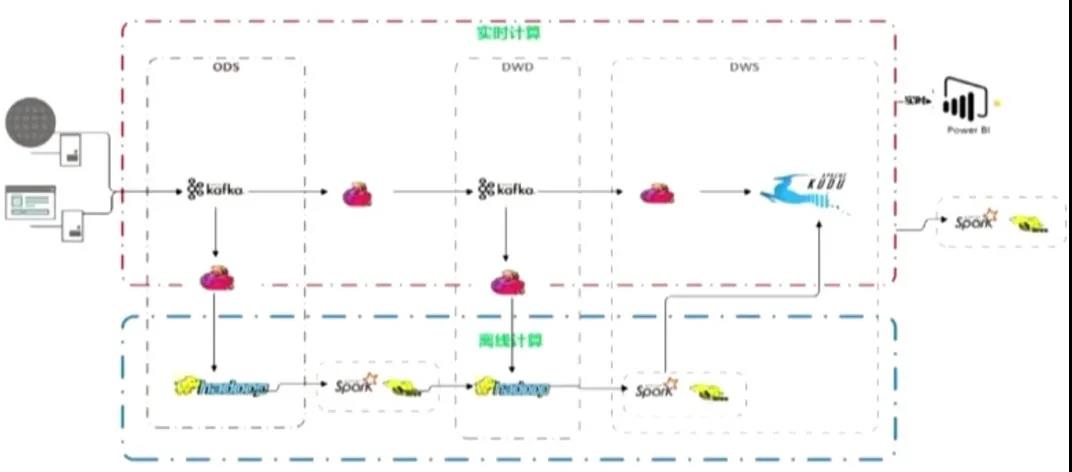
四、问题&改进
在具体的应用过程中,我们也遇到了很多问题,最主要的两个问题是:
多 Sink 下 Kafka Source 重复消费问题;
同交换机流量激增消费计算延迟问题。
Magina 平台上支持多 Sink,也就是说在操作的过程中可以将中间的任意结果插入到不同的存储中。这个过程中就会出现一个问题,比如同一个中间结果,我们把不同的部分插入到不同的存储中,那么就会有多条 DAG,虽然都是临时结果,但是也会造成 Kafka Source 的重复消费,对性能和资源造成极大的浪费。
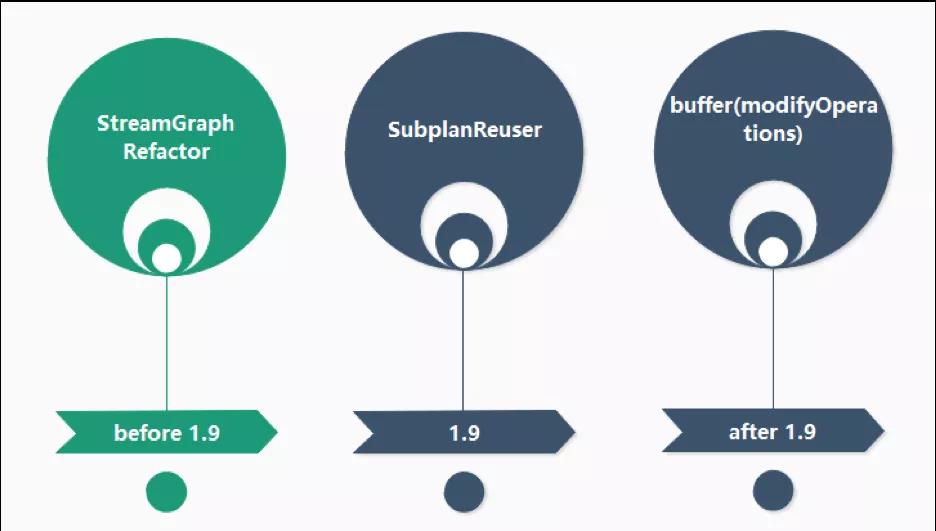
于是我们想,是否可以避免临时中间结果的多次消费。在 1.9 版本之前,我们进行了 StreamGraph 的重建,将三个 DataSource 的 DAG 进行了合并;在 1.9 版本,Magina 自己也提供了一个查询和 Source 合并的优化;但是我们发现如果是在同一个 data update 中有对同一个表的多个 Source 的引用,它自己会合并,但是如果不是在同一个 data update 中,是不会立即合并的,于是在 1.9 版本之后中我们对 modifyOperations 做了一个 buffer 来解决这个问题。
这个问题是最近才出现的问题,也可能不仅仅是同交换机,同机房的情况也可能。在同一个交换机下我们部署了很多机器,一部分机器部署了 Kafka 集群,还有一部分部署了 Hadoop 集群。在 Hadoop 上面我们可能会进行 Spark、Hive 的离线计算以及 Flink 的实时计算,Flink 也会消费 Kafka 进行实时计算。在运行的过程中我们发现某一个任务会出现整体延迟的情况,排查过后没有发现其他的异常,除了交换机在某一个时间点的浏览激增,进一步排查发现是离线计算的浏览激增,又因为同一个交换机的带宽限制,影响到了 Flink 的实时计算。
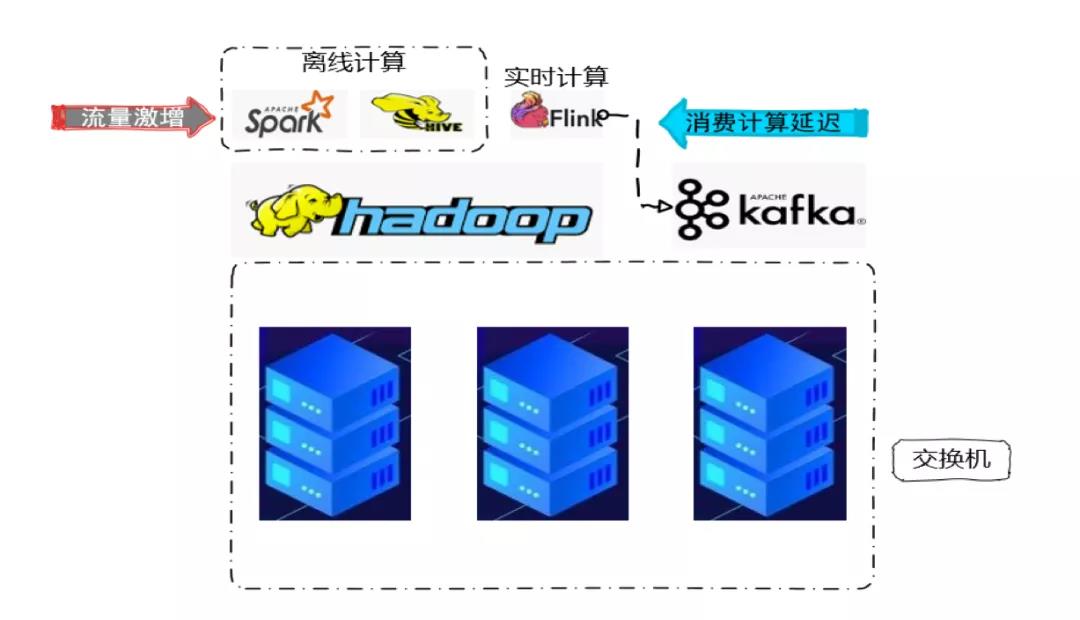
为解决这个问题,我们就考虑要避免离线集群和实时集群的相互影响,去做交换机部署或者机器部署的优化,比如离线集群单独使用一个交换机,Kafka 和 Flink 集群也单独使用一个交换机,从硬件层面保证两者之间不会相互影响。
Q&A
Q1:Kafka 在实时数仓中的数据可靠吗?
A1:这个问题的答案更多取决于对数据准确性的定义,不同的标准可能得到不同的答案。自己首先要定义好数据在什么情况下是可靠的,另外要在处理过程中有一个很好的容错机制。
Q2:我们在学习的时候如何去学习这些企业中遇到的问题?如何去积累这些问题?
A2:个人认为学习的过程是问题推动,遇到了问题去思考解决它,在解决的过程中去积累经验和自己的不足之处。
Q3:你们在处理 Kafka 的过程中,异常的数据怎么处理,有检测机制吗?
A3:在运行的过程中我们有一个分发的服务,在分发的过程中我们会根据一定的规则来检测哪些数据是异常的,哪些是正常的,然后将异常的数据单独分发到一个异常的 Topic 中去做查询等,后期用户在使用的过程中可以根据相关指标和关键词到异常的 Topic 中去查看这些数据。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721