
生活在信息爆炸时代的我们越来越清晰的认识到海量信息与数据分析的重要性,如提高数据挖掘能力、为运营决策提供关键数据、通过数据分析助力业务创新、在商业决策中的提供较有价值的信息等成为关键,于是大数据分析平台作为在各大公司迅速崛起。如何为企业个性化打造高效性、准确性、敏捷型等的大数据实时分析平台成为了技术团队的挑战。
RAP(RealtimeAnalysis Platform)是爱奇艺技术产品团队基于Apache Druid [1] + Spark/ Flink 构建的分钟级延时的实时联机分析处理OLAP(On-Line Analytical Processing)的实时分析平台,支持通过Web向导配置完成超大规模实时数据的多维度分析,能为用户提供一体化的OLAP分析操作流程,只需要几步简单的配置,即可自动建立OLAP模型、并生成分钟级延时的可视化报表。也可以通过RAP API获取聚合数据,与业务平台进行集成。服务于会员、推荐、BI等诸多个业务,总计上线数百个流计算任务,支持上千张多维分析报表。
本文将介绍爱奇艺大数据实时分析平台RAP的设计思路、技术架构演进以及业务应用实践。
一、实时分析需求
自2010年开始爱奇艺开展了大数据业务,打造了基于Hive + MySQL的第一代OLAP数据分析平台。但随着业务的快速发展和数据量的急剧增长,Hive的离线分析已经无法满足业务对数据实时性的需求。于是逐渐引入Kylin、Impala、Kudu、Druid、ElasticSearch等不同的数据存储/查询引擎,演化出离线数仓、实时数仓、流式数仓等不同OLAP形态。
在推出RAP实时分析平台之前,业务自行构建实时分析服务面临以下困难:
OLAP选型困难:众多OLAP引擎满足多样化需求,但也带来了不少问题。业务需要了解不同OLAP引擎的优缺点,花费大量精力学习,依然可能选错;
开发成本高:用户需要写Spark或Flink代码进行实时流数据处理,并进行报表前端开发,流程冗长而复杂;
数据实时性差:从数据产生到数据可被查询,中间存在较高时延(从数十分钟到天级别不等),且查询较慢;
维护耗费时间:数据源发生改变时,修改的范围会覆盖整个流程,从数据处理到报表配置全部需要变更,很难操作和维护。
针对以上问题,我们搭建了支持通过Web向导配置完成超大规模实时数据的多维度分析,生成分钟级延时的可视化报表,在保证数据实时性和分析灵活性的同时,降低开发和维护成本,并将整个分析流程平台化的RAP实时分析平台。
二、实时分析平台架构演变
2.1 RAP 1.x
▌2.1.1 OLAP选型
在开发大数据实时分析平台RAP平台之前,需要选择一款适合实时分析场景的OLAP引擎。
大数据实时分析的典型场景具备以下几个特征:
时序数据:基于时间的系列数据,比如实时VV、实时监控数据
时延低:要求几分钟甚至秒级延时
查询快:大规模查询秒级返回结果
根据典型场景的需求,我们综合评估了常见的几款OLAP引擎,最终选择Druid(Druid是一款开源的为时序数据设计的亚秒级查询延迟的数据存储引擎,主要用于进行OLAP聚合分析。)做为RAP的底层OLAP引擎。针对实时聚合分析场景(绝大部分是时序数据),Druid是更适合使用的数据引擎。基于Druid,我们设计了第一代的实时分析平台 RAP。
▌2.1.2 产品设计
RAP将实时分析的开发流程抽象为五个步骤:数据接入、数据处理、聚合分析、报表配置和实时报警,并且将这些步骤通过向导化的Web页面指导用户配置。
数据接入
无需输入集群IP等信息,可通过下拉框选择接入的实时数据源,目前支持4大类型数据:用户数据、服务日志、监控数据、其他Kafka数据源。
数据处理
为了扩展和优化Druid的功能,RAP支持基于流计算的数据处理功能,在对数据进行处理后写入Druid。在2.x版本中,我们同时支持使用Flink流计算引擎。
用户在页面上配置数据处理规则,RAP将这些规则翻译成爱奇艺自研的StreamingSQL语句,最终生成Spark Streaming流任务进行处理,用户无需编写流任务。
除了Spark SQL自带的预定义函数外,RAP还内置了一些用户常用的函数,比如将IP到省份、城市、运营商等常用转换函数。
聚合分析
用户通过界面化的操作定义实时分析OLAP模型,配置聚合分析所需的维度和聚合方式,如计数、独立计数、求和等,根据模型配置对实时数据进行预聚合。
在这个过程中,无需关心底层数据存储及OLAP引擎,RAP会自动翻译并优化相关参数。例如,接入Druid时需要根据经验配置参数(如task.partition,windowPeriod,queryGranularity等),RAP可以根据用户的配置(数据最大延时时间、watermark)以及数据源的信息(Kafka QPS)自动调节配置信息。
报表配置
用户可以基于实时分析模型的维度和指标配置报表(图表展示方式、以及查询条件等),RAP根据报表配置自动生成Druid查询,获取结果后提供给报表平台,并可以自动推荐合适的查询粒度,支持设置动态的过滤条件,用户无需关心查询语句如何配置。
实时报警
RAP支持对数据配置报警,可以配置阈值、同比/环比等报警。由于Kafka数据存在晚到的可能,实时报警支持配置延时时间获取一段时间前的数据进行判断,减少误报可能。
通过以上几步简单配置,就可以完成实时分析的整体流程。相比于传统方式,RAP将整体耗时从天级别缩短到30分钟,大幅提升开发和分析效率。
▌2.1.3 RAP架构
RAP的整体架构如下图所示,其中部分功能模块为RAP 2.x 支持:

2.2 RAP 2.x
RAP发布后发现了一些不足之处,如:在任务重启阶段的数据会被丢失,报表出现问题无法自行排障等。同时由于Kafka版本为0.8.2,无法通过KIS功能接入,导致Druid的很多功能并不能集成到RAP里,而且旧版接入方式(Tranquility [2])即将被废弃。因此我们增加对某些Druid高级功能的支持,并对架构进行了一系列的重构,上线了RAP2.x版本。
▌2.2.1 集成Druid KIS接入方式
Kafka Indexing Service [3]是为 Kafka 数据源设计的索引服务,可以保证消息摄入的 Exactly Once 语义,由Kafka索引任务直接从Kafka数据源读取消息写入Druid。
Kafka索引任务的启动和生命周期管理由运行在Overlord上的Supervisor进行管理,Overlord是Druid上负责接受任务,协调任务分配,创建任务间的锁和返回给调用方任务状态的进程。
每个Druid数据源对应一个Supervisor,只需向Overlord提交一个配置文件启动Supervisor,即可实现将Kafka数据摄入至Druid,唯一的条件是使用KIS的Kafka数据源版本必须在0.10.x及以上。当使用KIS接入Druid时,可以使用一些Tranquility接入不支持的高级功能,如更精确的独立计数HLL Sketch [4]等。
在RAP 2.x版本中,支持用户选择使用KIS接入Druid。当选择了KIS接入,如果用户的Kafka数据源版本在0.10.x及以上且没有进行数据处理,RAP会直接将Kafka数据源按配置通过KIS接入Druid;反之,如果Kafka数据源低于0.10.x或使用了数据处理,RAP会将数据处理的结果投递到RAP管理的公共Kafka集群,再通过KIS接入Druid。同时,在2.x版本中,RAP已经支持设置HLL Sketch独立计数指标(RAP 1.x使用Approximate histogram进行独立计数,其误差较大、且没有置信区间)。
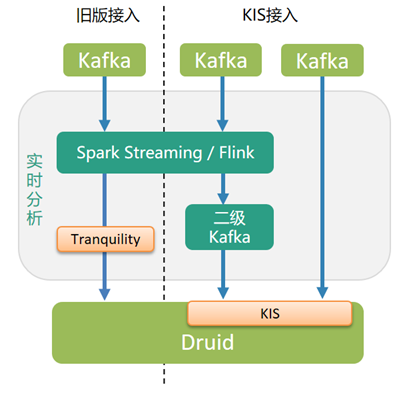
▌2.2.2 支持Flink计算引擎和函数管理功能
Apache Flink [5]是支持数据流处理和批量处理的分布式数据处理引擎,能够实现秒级处理数据,并且支持Exactly Once语义。通过使用Flink计算引擎,RAP数据处理可以从分钟级降到秒级,结合KIS接入的使用,可以保证从数据处理到Druid的Exactly Once摄入。而流任务函数管理功能可以让用户提交定制化的处理方式,可以应用在数据的字段上进行处理,丰富了数据处理功能。
▌2.2.3 增强任务诊断功能
为解决当报表出现问题时,无法自行排查这样的问题,在RAP 2.x版本中丰富了数据质量监控的内容。主要包含两个方面:流任务监控和Druid摄入监控,流任务监控是关于流任务运行情况的监控信息,Druid摄入监控是Druid数据摄入的监控信息。
流任务监控包括流任务延时情况图、实时摄入监控图、延时丢弃数据采样和错误数据采样。其中,流任务延时情况图记录了每个时间的任务延时情况,可以帮助定位是不是由于堆积任务过多导致的问题;实时摄入监控图中记录了流任务处理数据的历史,如果出现丢弃数据或者错误数据的点,点击后会在采样表格里展示具体丢弃或错误的数据,这样可以快速排查是否是数据时间戳超过了延时时间,或者数据处理设置的问题。Druid摄入监控展示的是Druid实时摄入的指标(见参考资料Ingestion metrics (Realtime process)小节 )。
三、实时分析业务应用
3.1 会员业务日志实时数据监控
2019年6月 爱奇艺会员规模突破1亿,为了提供更好的会员服务,RAP被会员业务用于对线上日志数据进行实时分析、实时报警。其中,会员业务的实时数据主要是日志数据,日均处理数百亿数据,结合RAP的分钟级分析和秒级查询的特性,已实现分钟粒度报警,且能够快速响应问题。同时会员团队将相关数据生成对应质量服务报表,提供给运维人员以数据指导。
RAP同时为会员监控体系提供数据支持,可短时间内快速接入95%系统,提供60+种维度的数据统计,能快速生成700+张实时报表,报警时效提升80%,大幅提升线上故障排查效率与响应速度。
3.2 推荐算法效果监测
合理的推荐算法可帮助爱奇艺从海量视频中挑选出高度定制化的内容推送给用户,而过去每次新算法的上线都需要1天的时间去分析用户效果。这样会引发2个问题:算法上线流程长、不好的算法影响时间长。所以通过实时数据来验证算法的有效性,指导算法迭代更新是非常必要的。
爱奇艺推荐业务使用RAP平台对推荐视频点击量(UV、VV)、用户观影时长(PPUI)等数据进行实时分析,监控分桶算法的效果,实现在30分钟内及时切换推荐算法提高用户体验。
3.3 智能电视实时预警
线上视频播放可能出现各种问题,需要有效的方法对线上故障进行监控,并及时向相关人员预警。视频播放故障有多方面原因,可以利用播放时收集的各种信息进行排查,如基于客户端版本、服务器IP、所在城市等多维度对错误率、卡顿比等指标进行分析,从而定位故障根因。
智能电视业务使用RAP分析实时数据监控故障,帮助实现“监控-报警-分析-解决-验证”的闭环流程,实现5分钟实时报警,并且可以通过多维度分析追溯故障根因,保障视频播放质量。

四、RAP的未来
未来RAP将会继续增加实时分析链路的监控,提供更细粒度的分析链路诊断功能,完善流计算处理引擎的处理能力,提高资源利用率,增强各环节的Exactly Once能力。提供更完备的数据分析能力,支持留存、智能分析等,让爱奇艺大数据实时分析平台RAP更具高性能。
参考资料
[1]https://druid.apache.org/
[2]https://druid.apache.org/docs/latest/ingestion/tranquility.html
[3]https://druid.apache.org/docs/0.14.2-incubating/development/extensions-core/kafka-ingestion.html
[4]https://druid.apache.org/docs/latest/development/extensions-core/datasketches-hll.html
[5]https://flink.apache.org/flink-architecture.html
[6]https://druid.apache.org/docs/latest/operations/metrics.html
活动推荐
2020年5月29日,北京,Gdevops全球敏捷运维峰会将开启年度首站!重点围绕数据库、智慧运维、Fintech金融科技领域,携手阿里、腾讯、蚂蚁金服、中国银行、平安银行、中邮消费金融、建设银行、农业银行、民生银行、中国联通大数据、浙江移动、新炬网络等技术代表,展望云时代下数据库发展趋势、破解运维转型困局。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721