
作者介绍
刘明,易鲸捷首席技术架构师,具有20年软件研发经验,其中15年在数据库系统实现方面。参与过惠普公司数据仓库产品Neoview和SeaQuest的研发,现致力于Apache Trafodion及EsgynDB的研发工作。
Trafodion是Apache基金会的一个开源项目,提供了一个成熟的企业级SQL-on-HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。此外,对于需要保证数据一致性、需要标准SQL开发接口,或者需要实时数据读写分析的应用,Trafodion也是一个十分合适的解决方案。
Trafodion的渊源可以追溯到数据库技术的“史前时代”。
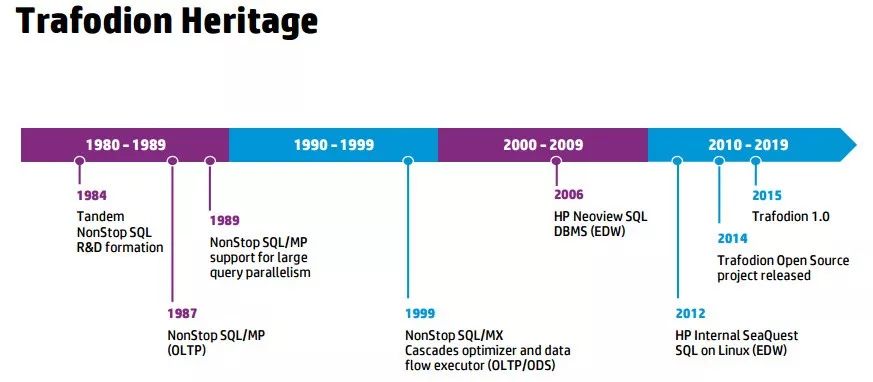
Trafodion的鼻祖是天腾 (Tandem) 公司的NonStop SQL。之后在1989年,天腾推出了NonStop SQL/MP,它是第一个MPP分布式数据库,实现海量并发SQL执行。在当时的历史条件下,NonStop SQL/MP开创性地提供了线性横向扩展能力(我们如今耳熟能详的scale out)。
1999年,在Graefe Goetz的帮助下,NonStop SQL/MX诞生了,它实现了基于成本的CBO SQL优化器和基于数据流的MPP SQL执行器。2002年,惠普公司和康柏公司合并,已被康柏收购的天腾也成为了惠普的一部分。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续产品SeaQuest。SeaQuest将Neoview从其专有的硬件,和专有的NonStop OS操作系统中移植到通用的x86服务器和通用的Linux操作系统上。
2014年,乘着大数据的浪潮,SeaQuest将底层的数据存储和访问引擎移植到HBase/Hadoop上,并创新地开发出HBase分布式事务处理等新技术,从而推出了Trafodion,并将全部代码开源,贡献给社区。
因此Trafodion是秉承了超过20年的技术积累而诞生的。其成熟的SQL引擎和各种Utility并不是几个技术天才在Google论文的启发下一挥而就,而是经过多年的团队努力和不断创新才得以完成。
Trafodion是一个建立在Hadoop/HBase平台上的关系型数据库,它的Welsh原意是“事务”。Trafodion能够完整地支持ANSI SQL 99标准,并支持ACID事务。基于最新的HBase发行版,Trafodion能够利用HBase的扩展性管理海量数据,并能提供极低的访问延迟。这些特点使得Trafodion成为了一个创新的大数据解决方案。
传统的RDBMS在扩展性上存在瓶颈,无法处理PB级别的海量数据,因此催生了大量的NoSQL数据库。但是NoSQL方案不提供方便的SQL接口,并且放弃了ACID支持。对于需要严格数据一致性的应用,NoSQL一般都无法满足需求。
Hive等SQL on Hadoop项目提供了类似SQL的访问接口,又构建在极具横向扩展能力的Hadoop平台上,既解决了大数据的扩展能力,又提供了用户熟悉的SQL接口。但是它们也存在几方面的问题。
首先,Hive等项目的SQL支持并不完整;其次,Hive等方案在访问数据时,有比较大的延迟,不能支持OLTP或者operational类型的应用。而Impala、Stinger等实时SQL on Hadoop方案则关注于大数据分析,适用于数据只写入一次而多次读取的场景。这类方案一般都无法提供实时修改和写入数据的功能,比如Impala就不支持UPDATE和DELETE语句。
Trafodion结合了传统RDBMS和NoSQL HBase各自的优点,提供了一种全新的数据访问方式。它的主要特性如下:
Trafodion是一个企业级的SQL DBMS,能提供所有传统商业RDBMS为用户提供的服务。和传统数据库的区别在于,Trafodion基于Hadoop/HBase构建,能够提供极佳的水平扩展能力。当用户数据量增加时,只需增加普通的计算机节点即可横向扩展存储和计算能力。
Trafodion提供完整的ANSI SQL语言支持,包括DDL、DML、事务控制语句,而不是类似HQL等提供的SQL语言的子集。Trafodion还提供常见的商业数据库才提供的utility,比如数据库备份和恢复。
Trafodion支持UDF和存储过程。
Trafodion提供Linux和Windows版本的ODBC/JDBC驱动。基于ODBC/JDBC的应用可以方便地移植到Trafodion平台上来。
Trafodion采用分布式事务处理算法提供严格的ACID事务一致性保护,采用日志技术保护用户数据在软硬件故障情况下依然可以得到恢复。
Trafodion拥有一个非常成熟的基于成本的SQL优化器 ,针对operational类型的工作负载进行了很多优化。
Trafodion拥有一个MPP并发执行引擎,采用数据流驱动构架,中间数据保存在内存中,不需要将中间数据保存在HDFS上;也不需要MapReduce等模型的启动开销;Trafodion利用LLVM的JIT方式生成运行时代码来解析表达式;利用这些执行器的先进技术,Trafodion保证了毫秒级别的查询响应时间。
Trafodion可以无缝地集成原生的HBase、Hive数据。比如用户可以直接在Trafodion中进行Hbase、Hive和Trafodion的多表join操作。或者利用Trafodion的SQL接口直接访问存放在Hive和HBase的原生数据,无需做数据移动和转换。
支持索引,约束等标准关系数据库特性。提供数据的快速随机访问,并在数据库级别保证数据的一致性。
除了拥有以上介绍的这些技术特性,Trafodion项目完全开源。用户可以直接从 http://trafodion.apache.org 下载使用,无需任何License费用。Trafodion和底层的Linux版本无关,也支持各种Hadoop发行版,因此使用Trafodion,用户可以避免采用商业软件带来的供应商锁定问题。
可以将Trafodion看作是一个构建在可扩展Hadoop平台上的传统数据库。基于此,Trafodion可以有多种适合的应用场景。
首先,Trafodion能够处理海量的数据,数据量超过了传统数据库可以处理的范围。而且Trafodion可以对数据进行随机的增删改查,完整地支持ACID事务。比较适用的应用场景就是物联网应用。
随着道路运输业的飞速发展,道路交通安全事故逐年增加,同时还存在道路运输运营效率低、能耗高、效益产出低等问题,与国外先进水平相比,我国平均油耗要高10%-25%。目前我国绝大多数客运及危化品运输企业车辆运营与监控调度管理水平偏低,设备和平台的合规率比较低,既无法适应政府管理部门相关管理要求,也无法满足企业自身对车辆精细管理的要求。
车联网企业利用大数据和物联网技术,对道路上运行车辆进行实时数据采集和分析,对客运车节能减排监控和驾驶行为进行监测分析。
他们采用Trafodion作为底层数据库,达到了良好的效果。车辆轨迹加载和查询,表大小为133亿。对该表数据的混合加载能力达到每秒8000条,在加载的同时,有300个并发连接查询, 80%的用户查询最近7天内的告警信息,20%用户查询15天内的告警数据,所有查询响应时间均小于1秒。
首先,使用传统数据库的主要限制之一在于数据量增大到一定程度时,数据库在扩展性上遇到瓶颈。比如扩展的成本太大,添加计算和存储节点以及软件License的费用惊人。
因此为了应对快速增加的数据量,很多应用不得不采用前后端Cache缓存、读写分离、分库分表等技术,导致应用程序编写难度增加,维护成本提高。当公司业务蒸蒸日上,数据持续增长的情况下,这些技术手段已使用到了极限,然而应用的性能提升却无法跟上数据增长的速度。
这正是催生大量NoSQL数据库的主要原因。但多数NoSQL数据库为了扩展性而牺牲了SQL的易用性,用户需要使用各种不同的编程语言,学习各种NoSQL的编程方式,比如MongoDB,用户需要学习JavaScript、Ruby或者Python;Riak采用了十分不易书写的REST接口;Cassandra、Redis……不一而足。
即使编程语言对于很多程序员来说并不是问题,但多数NoSQL数据库仅仅提供非常底层的数据读写功能。比如MongoDB不支持Join、key-value数据库不支持聚集操作等等。因此,使用这些简单API的应用开发人员需要花很多精力来完成那些原本是数据库开发人员的任务。
比如做join,可以采用Hash Join、Nest Loop Join或者sort merge join等不同方法,实现这些方法并不是非常简单的事情,而应用程序开发人员需要投入很多精力来实现这些和应用无关的功能,无法专注于更有价值和创新意义的应用开发。况且每一个NoSQL的开发都不是随意学习一两天就可以开始使用的,需要一定的学习曲线。我觉得学习SQL语言比学习MongoDB的开发要简单一点儿。
另外值得一提的是,NoSQL放弃了对ACID事务的支持,而将这些任务都交给应用开发人员处理。而支持事务处理,尤其是分布式情况下的事务和数据一致性是很复杂的事情。
如果你也有类似的困扰,不妨考虑使用Trafodion来解决。
很多正在使用传统关系数据库的公司和组织,往往已经投入了很多人力物力,开发了大量基于SQL的应用程序。在面对数据量不断增长的情况下,如果迁移到NoSQL,则需要大量的投入,将原有代码抛弃重新开发。如此就势必会遇到前面描述的种种困难,并且过去的投资全都白白浪费了。
而Trafodion本身就是一个关系型数据库,因此从传统数据库应用迁移的成本极低。Trafodion关注于帮助用户解决迁移问题,比如启其开发团队特意为兼容用户原有的Oracle应用而对Trafodion现有的标准SQL做了很多扩展:
Sequence Numbers
NEXTVAL and CURRVAL oracle syntax
PIVOT functionality
ROWNUM() function to return sequential numbers for returned
因此当你的应用本身基于关系型数据库,又面临数据量不断增长的困境,不妨考虑采用Trafodion来重用过去的应用,保护过往投资,节约新的投入。
最后,让我们看看Hadoop生态圈。Hadoop在大数据领域已经成长为最受瞩目的明星,众多公司已经大量使用Hadoop,从各自所拥有的海量数据中挖掘出新的商业价值。
Hadoop的MapReduce非常强大,但其固有的缺点在于:MapReduce仅适于批处理任务,而且开发难度很大。因此HBase、Hive得到了长足的发展。
利用HBase,用户可以在HDFS上进行随机的数据访问。Trafodion正是基于HBase的这种能力构建起来的。然而HBase功能相对简单,基于其进行开发需要学习HBase的专业知识;HBase不支持跨行跨表的ACID事务、不支持二级索引、不支持Join操作、不支持聚集。凡此种种却都是数据应用中非常需要的功能,意味着必须由应用层来自己负责。
Trafodion将以上这些特性一一实现,开发人员可以使用描述性语言SQL,也无需考虑事务一致性,从而可以专心于自身的商业价值开发。因此使用HBase的很多应用场景都可以考虑使用Trafodion来解放开发人员,无需再去实现本应由数据库提供的服务。
再来看看Hive。利用Hive,用户可以使用熟悉的SQL语言来进行Hadoop上的大数据分析。然而传统的Hive仅仅是将SQL语言翻译为MapReduce,因此还是更加适合批处理任务。主要的问题在于MapReduce job的启动成本,Sort/Shuffle将中间计算结果存放在HDFS磁盘上等等,这些因素都限制了Hive查询的响应速度和延迟。
因此标准的Hive使用场景为:定期进行数据的批量加载,再进行批处理计算。这个数据加载周期短则一个小时,长的甚至每天才加载一次数据。更糟糕的是,分析计算本身往往也需要数分钟甚至数小时的时间。因此这种计算模式往往无法满足结果的时效性,而越来越多的应用希望能提供更加实时的计算。
在线广告投放、实时交通状况分析等场景下,1小时前的数据已经降低了分析的可用性,更多的期望是分钟级别甚至秒级的实时性。比如为驾驶员提供道路信息的系统,如果每隔1小时才可以进行分析,那么即使分析计算可以在1秒内完成,其分析的数据却是1小时前的,那么驾驶员已经堵车堵了一小时,这样的系统就失去了意义。
为了满足实时性,一些新的实时分析系统涌现出来。比如Hortonworks的Stinger,采用Tez DAG型计算模型,极大地提高了响应速度,Stinger开发团队声称已经有100倍的性能提高。与此同时,其他的实时解决方案,比如Impala应声而出。Impala不再采用Map Reduce计算模型,而是采用和Trafodion相同的MPP并发执行引擎直接读取HDFS,以此获得极低的数据响应延迟,进而支持实时数据分析。然而Stinger、Impala的底层数据存储,比如ORCFile,Parquet等都无法支持随机写入修改功能。因此即便Stinger和Impala可以提供秒级别的分析响应能力,实时的数据依旧无法立即加载到Stinger和Impala的数据集中,所以Stinger/Impala还是仅仅能够提供准实时的分析能力。
用户期望能够对在线数据进行实时加载、实时分析。而Stinger、Impala虽然可以提供实时分析能力,但无法提供实时加载能力。在这种情况下,Trafodion就是一个十分适合的解决方案。比如用Flume、Storm等对在线数据进行收集和流式处理,将处理后的数据实时加载到Trafodion数据库中,然后利用标准SQL对数据进行实时分析处理。近年来,一些技术能力强大的公司利用Storm+HBase来实现流式、实时计算,效果良好。在这类场景下也可以使用Trafodion替换HBase以便更加高效地使用SQL,而不是HBase Java API来进行开发。
在大数据时代,历史悠久的Trafodion还只是一个新产品,还有很多功能需要逐步完善。本文中提及到的其他技术,各自都很优秀,没有任何一个产品可以替代其他。正如《七周七数据库》的作者所说,一个好的木匠不会只有一种工具。通过本文的简浅介绍,不妨把Trafodion放入你的工具箱,在需要时让它试试身手。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721