
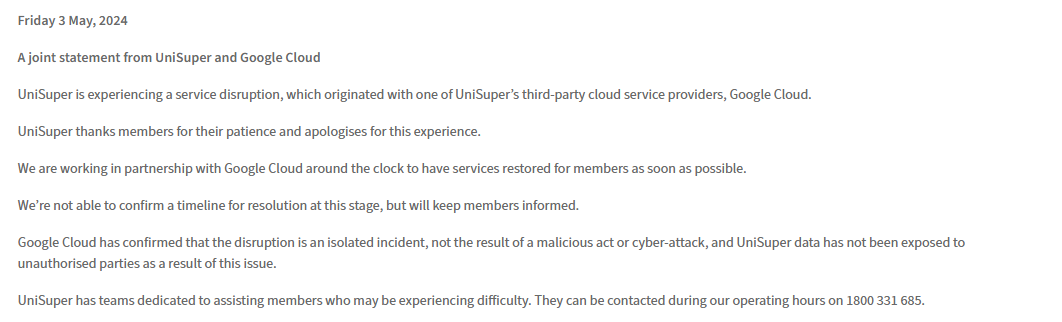
此次故障导致UniSuper基金的50多万会员自5月2日起,在整整一周内无法访问自己的退休金账户。尽管服务已于周四开始陆续恢复,但投资账户的余额数据仍需更新,以反映上周的金额。
UniSuper首席执行官Peter Chun在周三晚间向会员致信,明确表示此次故障并非由网络攻击引起,且在故障过程中没有个人数据泄露。他指出,谷歌云服务是导致此次问题的原因。
在联合声明中,Kurian和Chun强调了此次事件的孤立性,并确认谷歌云已经查明了导致服务中断的原因,并采取了相应措施以防止类似事件再次发生。他们表示,这是一起“独一无二的事件”,谷歌云在全球的客户以前从未遇到过这种情况。
尽管UniSuper通常在两个地区都备有数据副本,但由于云订阅账户的删除,两个地区的云实例均受到了影响。最终,由于另一家供应商的备份,UniSuper得以恢复服务。这些备份将数据丢失降至最低,并提升了UniSuper和谷歌云完成恢复的能力。
“UniSuper 和 Google Cloud 之间的奉献与合作使我们的私有云得到了广泛的恢复,其中包括数百个虚拟机、数据库和应用程序。”
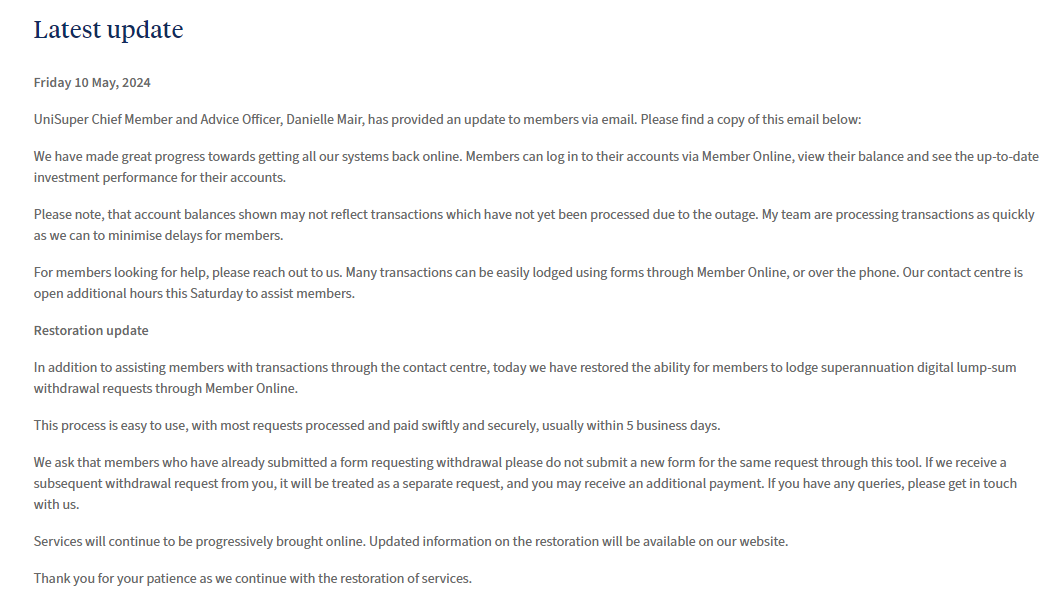
在UniSuper官网5月10日的“最新情况更新”公告中,目前“我们在让所有系统重新上线方面取得了巨大进展。会员可以通过会员在线登录自己的账户,查看账户余额并查看账户的最新投资表现。”
UniSuper管理着约1250亿美元的资金,此次服务中断引起了业界的广泛关注和担忧,同时也对全球云服务的安全性和稳定性提出了质疑。谷歌云作为全球领先的云服务提供商,此次失误对其声誉造成了重大影响。

此次事件也提醒了全球云服务用户,注意数据安全和业务连续性计划的重要性。随着云服务的普及,如何确保服务的稳定性和安全性,已成为所有云服务提供商和用户必须共同面对的挑战。
针对此次事件,云服务提供商和用户也许可以在这些方面做些改进:
强化备份机制:企业应建立全面的备份策略,包括定期备份、异地备份和云备份。备份应定期进行测试,确保在数据丢失时能够迅速恢复。此外,备份应与原数据存储在不同的物理位置,以避免单点故障。
严格的访问控制:必须对云服务的访问权限进行严格管理,避免未授权的访问和操作。应使用最小权限原则,确保员工仅拥有完成其工作所必需的访问权限。同时,对于关键操作,如数据删除,应实施二次验证机制。
变更管理流程:对于任何可能影响数据完整性和可用性的配置更改,都应遵循正式的变更管理流程。这包括预先的变更影响评估、变更记录、审批流程以及事后的变更审计。
实时监控和快速响应:实施实时监控系统,以便在数据丢失或服务中断发生时能够立即检测并响应。监控系统应能够覆盖所有关键的云服务组件,并配置有自动警报机制。
服务等级协议(SLA)和合同条款:在与云服务提供商签订合同时,应明确服务水平协议(SLA),包括服务可用性、数据保护、恢复时间和违约赔偿等条款。同时,合同中应详细规定数据所有权和责任界限。
员工安全培训:定期对员工进行安全意识和最佳实践培训,特别是对于有权限操作云服务的员工。培训内容应包括数据保护、识别钓鱼攻击、安全配置和应急响应等。
灾难恢复和业务连续性计划:制定详尽的灾难恢复计划和业务连续性计划,确保在发生重大故障时,能够迅速切换到备用系统,最小化对业务的影响。
数据分类和敏感性管理:对存储在云中的数据进行分类,并根据数据的敏感性和重要性采取相应的安全措施。对于高敏感性数据,应采用更高级别的加密和访问控制。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721