
杨亚洲,前滴滴出行专家工程师,现任OPPO文档数据库MongoDB负责人,负责数万亿级数据量文档数据库MongoDB内核研发、性能优化及运维工作,一直专注于分布式缓存、高性能服务端、数据库、中间件等相关研发。后续持续分享《MongoDB内核源码设计、性能优化、最佳运维实践》。
前言
某智能产品业务数据之前存储在Elasticsearch(Es)中,磁盘占用约30T(按照单副本计算),总数据量25亿,按照不同业务分类分别存在于不同表中。迁移前,业务存在较严重的性能及成本问题,当前业务已经迁移部分数据到MongoDB中,迁移后效果明显,成本实现十倍级节省,业务抖动问题也得以解决。
当前我司已有数百亿Es数据迁移MongoDB,同时也有数百亿MongoDB迁移Es,根本原因业务就是选型错误引起。
本文以该场景业务迁移作为案例,主要分享以下方面的内容:
MongoDB适用场景及不适用场景
MongoDB和Es各自优势
MongoDB和Es同样数据,真实磁盘消耗对比
对《从MongoDB迁移到ES后,我们减少了80%的服务器》一文的一些不同看法
没有万能的数据库,本文最后会总结MongoDB和Es各自的适用场景,以客观立场分析评价MongoDB和Es,拒绝“捧一个,踩一个”。
Es绝对是一款优秀的搜索引擎,在模糊匹配、全文搜索、复杂检索等方面相比MongoDB拥有更大的优势。
本文对应业务场景查询比较简单,查询更新等条件都是固定字段,不涉及复杂检索,所以在此场景MongoDB更具优势。另外,MongoDB当前默认的wiredtiger存储引擎,在高压缩、高性能、锁粒度等方面进一步提升了MongoDB在该场景下的优势。
我司已有多个业务数百亿级数据从Es迁移MongoDB,由于其他业务迁移MongoDB的时间较早,之前没有详细记录迁移前后的ES和MongoDB详细资源对比,只有大概资源消耗比值。为了尽量客观评价迁移前后的数据对比,因此选择近期正在从Es迁移MongoDB的一个集群,同时记录源集群和目的集群的详细资源占用情况,这样的对比结果会更加客观真实。
一、业务背景
该业务存储智能产品相关数据,总数据量20多亿,单个集群ES磁盘消耗约30T。业务迁移背景如下(以下为业务开发同事整理):
Es集群不太稳定,造成秒级耗时,对我们业务影响挺大,感知非常明显;
具体我们业务需求,主要是根据用户id来进行精确查询,没有复杂全文检索、模糊查询等需求,所以其实用不到Es的优点;
Es成本太高。
二、源Elasticsearch集群资源及部署情况
源ES集群业务在两个机房各申请了一个集群,由业务自己通过双写的方式来保障数据一致性,当一个集群异常业务自己切流量到另外一个集群。
源ES集群部署架构及资源规格如下:

如上图所示,由于为了实现两机房双活容灾及单集群抖动引起的业务故障,在A机房和B机房各搭建了一个ES集群,业务通过双写来自己维护两个集群的数据一致性。
当A机房集群1异常,或者A机房掉电,则业务切流量到B机房备集群2,对应架构图如下:
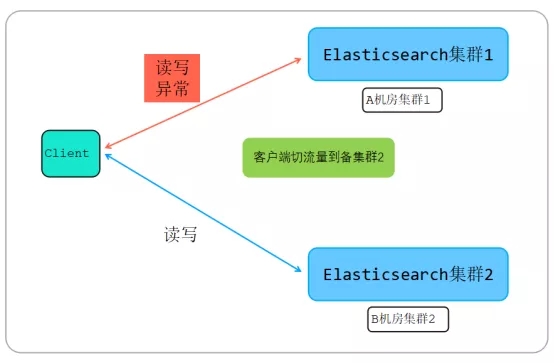
A机房集群1和B机房集群2内部部署架构完全已有,单个集群总共有26个节点,每个节点都部署在容器中,单个容器规格资源如下所示:
CPU:32
内存:64G
磁盘:2T
磁盘类型:SSD
单个集群总资源消耗如下:
CPU:32*26=832
内存:64G*32=2048G
磁盘:2T*32=64T
两个集群总资源消耗如下:
CPU:32*26*2=1664
内存:64G*32*2=4096G
磁盘:2T*32*2=128T
从上面的分析可以看出,为了保障业务多活和集群高可用,业务通过双写实现,异常后业务自己判断切换,这增加了业务痛点。该架构主要痛点如下:
成本高,本身每个集群都是多副本,第2个备集群进一步增加了成本;
增加了业务开发难度,业务需要双写逻辑;
数据一致性无法得到保障,例如集群1异常或者故障,业务读写切到集群2,当集群1恢复正常,异常这断时间内,集群2的数据会比集群1多;
不利于业务快速迭代开发;
业务只是按照固定字段做查询,查询条件单一,这种场景选择MongoDB本身性能会更好。
三、目的MongoDB集群架构
业务开始迁移MongoDB的时候,通过和业务对接梳理,该集群规模及业务需求总结如下:
总数据量20多亿;
Es数据单集群磁盘消耗总和30.5T左右;
读写峰值流量流量很小,几百上千;
同城两机房多活容灾;
分片数及存储节点套餐规格选定评估过程如下:
内存评估
我司都是容器化部署,以以网经验来看,MongoDB对内存消耗不高,历史百亿级以上MongoDB集群单个容器最大内存基本上都是64Gb,因此内存规格确定为64G。
分片评估
业务读写流量很低,但是数据量较大,因此分片数确定为2个分片。
磁盘评估
按照以往测试验证及线上真实数据迁移对比,同样的数据存入MongoDB和Es中真实磁盘消耗占比如下:
MongoDB:Es ≈ 1:6
25亿Es真实磁盘消耗30.5T,预计MongoDB磁盘消耗5T左右,考虑到未来数据增长,我们按照50亿数据计算,预计需要10T空间。2个分片,因此每个分片5T数据,最终确定单个mongod实例容器磁盘规格5T。
CPU规格评估
由于容器调度套餐化限制,因此CPU只能限定为16CPU(实际上用不了这么多CPU)。
mongos代理及config server规格评估
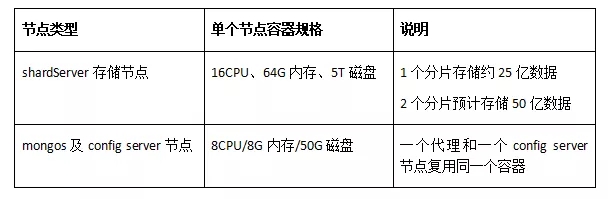
此外,由于分片集群还有mongos代理和config server复制集,因此还需要评估mongos代理和config server节点规格。由于config server只主要存储路由相关元数据,因此对磁盘、CUP、MEM消耗都很低;mongos代理只做路由转发只消耗CPU,因此对内存和磁盘消耗都不高。最终,为了最大化节省成本,我们决定让一个代理和一个config server复用同一个容器,容器规格如下:
8CPU/8G内存/50G磁盘,一个代理和一个config server节点复用同一个容器。
分片及存储节点规格总结:2分片/16CPU、64G内存、5T磁盘。
mongos及config server规格总结:8CPU/8G内存/50G磁盘
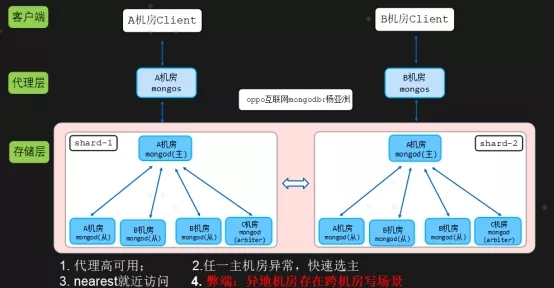
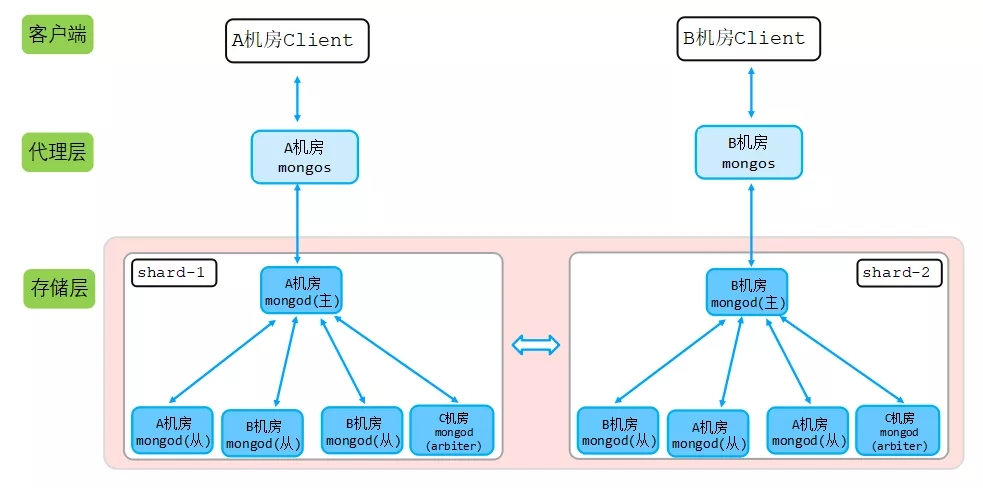
由于该业务所在城市只有两个机房,因此我们采用2+2+1(2mongod+2mongod+1arbiter模式),在A机房部署2个mongod节点,B机房部署2个mongod节点,C机房部署一个最低规格的选举节点,如下图所示:
说明:
每个机房代理部署2个mongos代理,保证业务访问代理高可用,任一代理挂掉,对应机房业务不受影响。
如果机房A挂掉,则机房B和机房C剩余2mongod+1arbiter,则会在B机房mongod中从新选举一个主节点。arbiter选举节点不消耗资源
客户端配置nearest ,实现就近读,确保请求通过代理转发的时候,转发到最近网络时延节点,也就是同机房对应存储节点读取数据。
弊端:如果是异地机房,B机房和C机房写存在跨机房写场景。如果A B C为同城机房,则没用该弊端,同城机房时延可以忽略。
四、性能优化过程
该集群优化过程按照如下两个步骤优化:数据迁移开始前的提前预优化、迁移过程中瓶颈分析及优化、迁移完成后性能优化。
和业务沟通确定,业务每条数据都携带有唯一_id(用户生成的,不是MongoDB内部生成),同时业务查询更新等都是根据_id维度查询该设备下面的单条或者一批数据,因此片建选择_id。
分片方式
为了充分散列数据到2个分片,因此选择hash分片方式,这样数据可以最大化散列,同时可以满足同一个_id数据落到同一个分片,保证查询效率。
预分片
MongoDB如果分片片建为hashed分片,则可以提前做预分片,这样就可以保证数据写进来的时候比较均衡的写入多个分片。预分片的好处可以规避非预分片情况下的chunk迁移问题,最大化提升写入性能。
sh.shardCollection("user_xxx.user_xxx", {_id:"hashed"}, false, { numInitialChunks: 8192} )
注意事项:切记提前对ssoid创建hashed索引,否则对后续分片扩容有影响。
就近读
客户端增加nearest 配置,从离自己最近的节点读,保证了读的性能。
mongos代理配置
A机房业务只配置A机房的代理,B机房业务只配置B机房代理,同时带上nearest配置,最大化的实现本机房就近读,同时避免客户端跨机房访问代理。
禁用enableMajorityReadConcern
禁用该功能后ReadConcern majority将会报错,ReadConcern majority功能注意是避免脏读,和业务沟通业务没该需求,因此可以直接关闭。
MongoDB默认使能了enableMajorityReadConcern,该功能开启对性能有一定影响,参考:
1、MongoDB readConcern 原理解析:
https://developer.aliyun.com/article/60553
2、OPPO百万级高并发MongoDB集群性能数十倍提升优化实践:
https://mongoing.com/archives/29934
3、MongoDB源码分析、更多实践案例细节:
https://github.com/y123456yz/reading-and-annotate-mongodb-3.6
存储引擎cacheSize规格选择
单个容器规格:16CPU、64G内存、7T磁盘,考虑到全量迁移过程中对内存压力,内存碎片等压力会比较大,为了避免OOM,设置cacheSize=42G。
全量数据迁移过程中,迁移速度较块,内存涨数据较多,当脏数据比例达到一定比例后用户读写请求对应线程将会阻塞,用户线程也会去淘汰内存中的脏数据page,最终写性能下降明显。
wiredtiger存储引擎cache淘汰策略相关的几个配置如下:
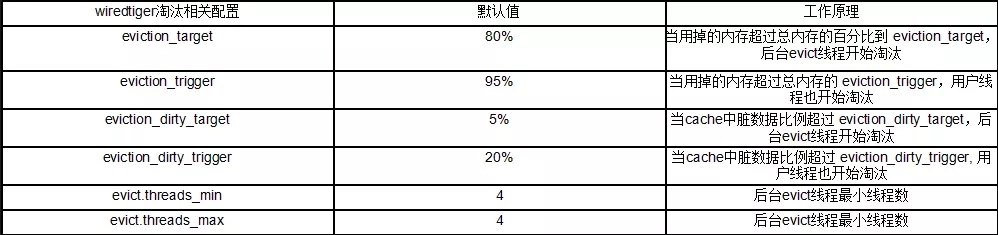
由于业务全量迁移数据是持续性的大流量写,而不是突发性的大流量写,因此eviction_target、eviction_trigger、eviction_dirty_target、eviction_dirty_trigger几个配置用处不大,这几个参数阀值只是在短时间突发流量情况下调整才有用。
但是,在持续性长时间大流量写的情况下,我们可以通过提高wiredtiger存储引擎后台线程数来解决涨数据比例过高引起的用户请求阻塞问题,淘汰涨数据的任务最终交由evict模块后台线程来完成。
全量大流量持续性写存储引擎优化如下:
db.adminCommand( { setParameter : 1, "wiredTigerEngineRuntimeConfig" : "eviction=(threads_min=4, threads_max=20)"})
更多存储引擎及mongodb内核涉及实现参考:
mongodb源码分析、更多实践案例细节:
https://github.com/y123456yz/reading-and-annotate-mongodb-3.6
前面章节我们提到,在容器资源评估的时候,我们最终确定选择单个容器套餐规格为如下:
16CPU、64G内存、5T磁盘。
全量迁移过程中为了避免OOM,预留了约1/3内存给mongodb server层、操作系统开销等,当数据迁移完后,业务写流量相比全量迁移过程小了很多。
也就是说,前量迁移完成后,cache中涨数据比例几乎很少,基本上不会达到20%阀值,业务读流量相比之前多了很多(数据迁移过程中读流量走原Es集群)。为了提升读性能,因此做了如下性能调整(提前建好索引):
节点cacheSize从之前的42G调整到55G,尽量多的缓存热点数据到内存,供业务读,最大化提升读性能。
每天凌晨低峰期做一次cache内存加速释放,避免OOM。
五、迁移MongoDB后性能对比
当前已有2个表从Es迁移到该MongoDB集群,同时该业务新增了15亿其他业务数据到该集群,当前目的MongoDB集群已有近20亿数据。
由于该集群ES没有历史时延统计曲线统计,因此ES的时延统计只有以下现象(来自业务方反馈):
查询秒级耗时,对我们业务影响挺大,感知非常明显。
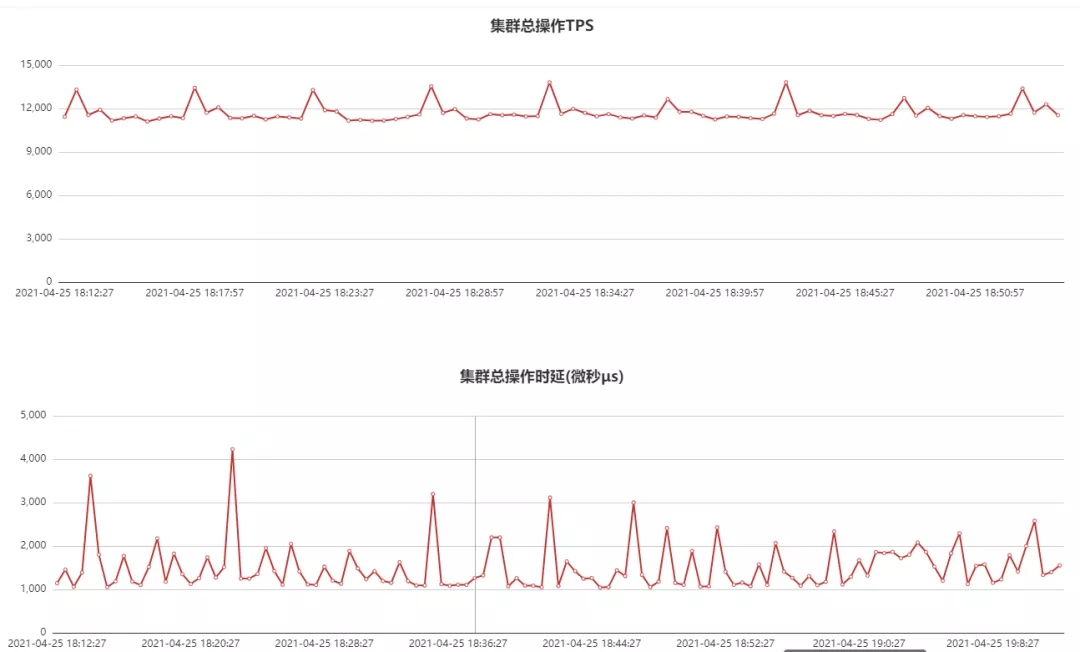
从上面的监控可以看出,由于除了迁移有源Es的数据,另外还有该业务的其他业务数据流量流向该集群,因此MongoDB集群流量相比Es会更高,MongoDB整体时延约1.5ms左右,远远好于之前Es的秒级时延抖动。
六、迁移成本收益对比
原Es单个集群一共26个节点,每个节点副本容器规格:32CPU、64Gmem、2T磁盘,磁盘类型SSD,单个集群规格总结如下:
单集群节点总数:26
每个节点规格:32CPU、64Gmem、2T磁盘
总数据量:25亿
为了实现机房多活容灾和业务高可用,实际部署了两个Es集群,实际规格成本还的在上面的基础上增加一倍。
当前该MongoDB集群已有约16亿数据(其中部分为Es集群以外数据,该集群除了存储部分Es迁移过来的数据,还存储该业务线其他业务数据),该MongoDB集群规格如下:
分片数:2
单分片副本数:4
每个节点规格:16CPU、64G mem、5T磁盘
两个分片预计存储最大数据量:预计存储Es集群中总数据量的两倍。
CPU、MEM内存成本对比计算过程
源Es两个集群和目的MongoDB集群资源对比如下:

说明:由于集群部署方式可能有很多冗余,上面的CPU和内存成本比对比实际上不客观,可能Es部署时候规格设置浪费。当然,MongoDB实际上CPU资源也非常空闲,所以CPU和内存指标对比无太大参考作用。
磁盘成本对比计算过程(成本比约6:1)
由于目的MongoDB集群中当前除了有源ES迁移过来的部分表外,还有该业务的其他数据,为了保障磁盘对比的客观性,磁盘对比选材过程如下(说明:源Es有两个集群,这里只计算单个集群单分数据的磁盘消耗,如果按照两个集群计算,磁盘成本比为12:1,这种对比方法不客观):
只对比从源Es中迁移到MongoDB中的表;
只对比源Es集群和目的MongoDB集群表中数据量完全一样的表;
排除源ES迁移到MongoDB但是当前还没有迁移完的表;
源Es集群只计算一个集群单副本的磁盘消耗;
通过上面的选择算法,基本上做到了同样数据在Es和MongoDB中的对比,磁盘真实消耗对比结果如下(说明:以下数据的Es磁盘占用为单个Es集群单副本方式计算结果,如果算2个Es集群,Es磁盘还需要乘2,es由我司Es开发人员提供,为了客观公平,Es按照一个集群单副本计算;MongoDB磁盘占用计算方法为2个分片主节点真实磁盘占用之和,包括数据磁盘消耗+索引磁盘消耗):
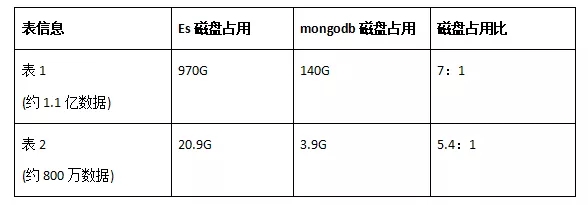
从上面的数据对比可以看出,同样的数据Es磁盘占用约为MongoDB磁盘占用的6倍,和之前其他Es迁移MongoDB过程的数据占用比值类似。
表1文档内容如下:
{"_id" : null,"channel" : null,"content" : "04A193398BE7xxx7E080E2C3CC7B3sxxxxxxxxxC99F9520B8CD0842638DB0F550E125xxxxxxxxxxxxxDB5D3F320642A42CECD3EB5C27714524D0C1BF2A0C6B607D0DFDB669D6633A0E48C65B2623EA15E6DBB0FBF643150E18DD3D0575BDE448C03735A8841E312F8AF0D2BF67D1D357D1AB6249BF3FA4E014C5Axxxxxxxxxxxxxx30C10487667","create_time" : ISODate("2021-02-16T09:56:03Z"),"duid" : "6F9E856EDDBB5xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxF41B0676FB2DE2171C18450E683DE1E9523B518F266856E01B0D6855E29911E5D10F0FA7E4A8EE5816333D89296E7554F05A58","update_time" : ISODate("2021-02-16T09:56:03Z")}
表2文档内容如下:
{"_id" : "F9654874C1A37F74DA5E862C408EDC45","channel" : "10001","content" : "BA7110279AF5XXXXXXXXX6D7ACB8D0F9XXXXXXXXXXXXXX5CDB4693BE949F70E78A20E","create_time" : ISODate("2021-01-21T11:49:46Z"),"imei" : "F96548XXXXXXXXXXXXXXXXX2C408EDC45","update_time" : ISODate("2021-01-21T11:49:46Z")}
七、Elasticsearch和MongoDB各自适用场景总结
由于业务开发对业务场景评估不到位,当前我司线上MongoDB和Es适用过程存在如下现象:
数百亿Es数据迁移MongoDB
也有数百亿MongoDB数据迁移到Es
从线上真实业务使用情况为例,以下场景不适合MongoDB,实际上也不适合mysql等数据库:
8字段以上的随机组合查询
有些业务场景,查询条件是由用户触发,查询条件不固定,可能存在多个字段的随机组合查询。MongoDB和MySQL等数据库,都需要手动创建索引,由于8字段以上的随机组合查询情况种类太多,因此很难手动建索引覆盖所有场景,所以选择Es更优,只是成本会更高。
全文检索
虽然MongoDB也支持全文检索,MongoDB-4.2以下版本全文检索能力性能和ES没法比,建议全文检索适用Es。
MongoDB-4.2全文搜索已经开始支持Lucene 引擎,可能性能会有很大提升,暂时没做研究,也没做性能对比,后续有空在研究。
其他复杂检索,例如非前缀模糊匹配查询
例如查询db.member.find({"name":{ $regex:/XXX/ }}),查询name字段包含XXX的查询,这类查询Es更优,因为mongodb、mysql等底层都是KV存储,查找KEY的时候都是从左到右比较key字符串,如果是非前缀匹配模糊查询,就需要全表扫描。
查询以某字段为开头的文档,db.member.find({"name":{$regex:/^XXX/}})这类就比较适合用mongodb查询,前缀匹配。
MongoDB和Es不同场景性能对比(以下为真实线上数据对比):

最后,脱离业务场景评估一个数据库优劣很不合适,主流数据库都优其存在的意义,不能因为数据库在某种场景下不合适而全盘否定该数据库。
八、对《从MongoDB迁移到ES后,我们减少了80%的服务器》一文的不同看法
《从MongoDB迁移到ES后,我们减少了80%的服务器》一文中以下观点个人认不太赞同,主要如下:
MongoDB近几年持续排名全球前五,市值近两年已翻数倍,当前市值近200亿左右。DB-Engines Ranking排名得分持续提升,说明本身有自己得市场和应用场景,而不是浪得虚名,没《从MongoDB迁移到ES后,我们减少了80%的服务器》一文中说的不堪一击。
服务器80%节省?mongodb部署架构严重资源浪费
从该文章可以看出,单个文档200多字节,MongoDB存储引擎wiredtiger默认高压缩、高性能、细粒度锁。单个复制集即可存储数十亿数据,你们用了十多个容器。
同样的数据,默认mongodb磁盘占用是Es的六分之一,加上这是日志集群,MongoDB可以采用1mongod+1mongod+1arbiter部署,规格8c/32gb/100gb 2个容器就可以满足要求。这样的部署才是合理的,成本会比同样数据Es减少数倍。如果用mongodb,本身2个8c/32gb/100gb+1个低规格选举节点容器即可搞定的事,你用了15台。
任意组合的,现有MongoDB是不支持的?
任意组合的查询不是mongodb不支持,是建索引麻烦,包括mysql、tidb等数据库都是需要手动一个一个建索引。
性能提高十倍?一个走索引一个不走索引,这种数据对比不客观
这本身就是个数据库选型问题,随机组合条件太多,索引不好建,你应该把索引查询条件对应索引建好后对比。不过多字段的随机组合查询,确实不适合用mongodb,建索引麻烦。
建议把mongodb对应查询索引建好,重新测试下查询性能数据。
MongoDB单集合数据量超过10亿条,此情况下即使简单条件查询性能也不理想?
我司最大的mongodb集群单表几千亿数据,查询2ms以内。
10亿规模对我们线上业务就是毛毛雨,我们把mongodb集群归类为如下几档:
小规模集群:数据量<100亿
中型集群:数据量100亿到1000亿之间
大型集群:数据量大于1000亿
当前我司15%-20%左右集群是百亿级以上集群,已成功实现单个集群万亿级离线数据读写存储,当前正在挑战单个万亿级实时在线数据高并发在线读写。
万亿级离线数据读写优化案例详见:《用最少人力玩转万亿级数据,我用的就是MongoDB!》
后续将分享《单集群万亿级在线数据高并发读写优化实践》
没有人敢在核心项目中使用MongoDB?
我司25%-35%以上数据存储文件、图片等元数据,甚至包括少量交易集群,非常核心,当前我司规模早已超过万亿级。
MongoDB有的,Es都有?
没有万能的数据库,正如上文所述,MongoDB在高并发写、固定字段索引查询方面的性能表现。此外MongoDB存储引擎高压缩高性能,在成本上面体现很明显。
业务场景很重要,不能“捧一个,踩一个”,主流数据库都有其存在的理由,排名第五绝不是浪得虚名。
只有用事务的才是核心数据?
不太赞成这样定义核心数据,用事务的不一定是核心数据,不用事务的也未必不是核心数据。例如我司存储的几千亿文件、图片等元数据,没有用到事务,但是是非常核心的数据,丢失会造成严重后果。
结合公司内部使用MongoDB为例,有时候出现以下情况:一些不适合MongoDB的业务场景,例如全文检索、8字段以上的随机组合查询、非前缀匹配模糊查询,这些场景本身不适合选用MongoDB,但是业务选型错误,造成使用过程中的瓶颈。
甚至有相关研发人员因为选型错误在各种群里面说:“远离mongo,珍爱生命”(该业务有全文检索需求);此外还存在业务数组索引使用不当引起集群抖动(该业务数组用法没建索引引起),认为MongoDB设计有问题,这些都是极不负责的行为。
通过这些真实业务接触过程中的案例,总结如下几点:
没有万能的数据库,切记结合自身业务场景,选择最优数据库;
主流数据库都有其存在的理由,不要因为在某些场景不适合而全盘否定该数据库其他层面的优势。例如不能因为MongoDB在全文检索等复杂检索上面的弱势而全面否定MongoDB,也不能因为Es在磁盘成本、高并发读写等方面的劣势而否定Es在复杂检索上面的优势;
切记以偏概全,捧一个踩一个,这都是及其不客观的行为。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721