
在实际开发中,有时候会收到一些服务的监控报警,比如CPU飙高,内存飙高等,这个时候,我们会登录到服务器上进行排查。本篇博客将涵盖这方面的知识:Linux性能工具。
一次线上问题排查模拟
背景:服务在平稳运行一段时间后,CPU突然飙高。通过top命令,可以确认下,到底是哪个进程导致CPU飙高了(也许是误报呢?)。
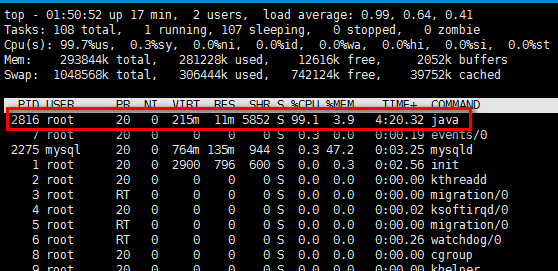
top
从上面可以看到图中PID是2816的进程,CPU使用率非常高。使用top -Hp 2816来对该进程下的线程进行观察。图中可以发现,2825这个线程CPU非常高。
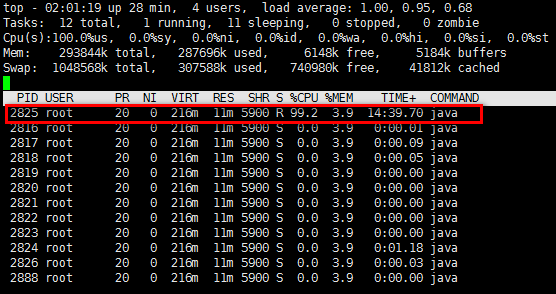
查看进程下的线程信息
这里利用Python非常方便的把十进制的线程ID转化成了16进制。
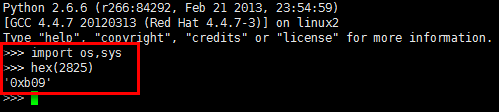
进制转换
为什么要这么做呢?因为在接下来的线程DUMP文件中使用的就是16进制的NID。

线程DUMP文件
在实际中,我们应该利用jstack pid多DUMP几次,因为线程存在状态转换,因此多次DUMP有利于抓取到线程更多的信息。图中,你可以观察到,一个线程得到了锁,在运行,迟迟没有释放,而另一个线程一直在等待这个锁。至此,就可以到去查看代码去分析为什么锁迟迟不释放的原因了。
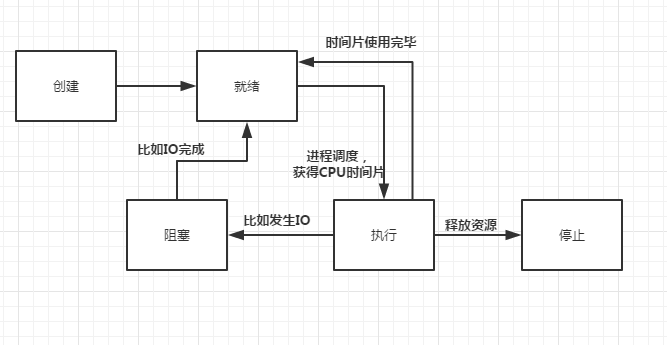
线程状态转换
性能监测工具top详解
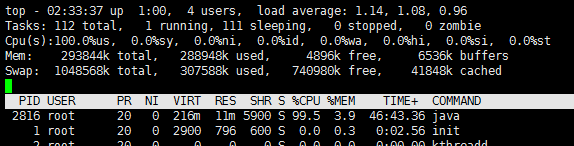
上文的案例中,就使用到了top,而在实际中,top的信息量是很大的,这里详细分析下。
top
第一行:涉及到2个时间,一个是系统时间,一个是机器运行的时间。【我们应该重点关注的是机器运行的时间,Why? 有时候,重启机器能带来很多问题,你懂的!】
多少用户登录了系统?【通过who/w/history可以查到更多信息】
3个load值是什么含义?分别代表的是1MIN,5MIN,15MIN机器的负载情况,如何确定负载的大小呢?需要和CPU的核数相结合来看,比如该机器是4核CPU,那么如果load值超过了4,就意味着负载很大了!【在top下按下1可以观察出CPU的个数】,关于系统负载,具体可以阅读前面文章Linux中load average意义(请戳我)。
第二行:主要是总共有多少个任务,重点应该关注的是僵尸状态的任务数。
第三行:主要是CPU的一些信息。
US/SY:说的就是用户进程和系统进程使用CPU的占比。
NI:即NICE,表示被调整过线程优先级的进程占比,这个比例正常不应该很大。
ID:表示空闲;WA表示资源等待的时间,比如在瞬时大流量下,服务打了很多日志的话,那么这个值就会飙高,因为这会很消耗资源的。
HI:硬中断,一般就是外设引起的,如果HI飙高的话,那么意味着外设在硬件层面出现了问题。SI表示软中断。
ST:即steel,如果该主机是虚拟的话会有这个ST信息,也即是该虚拟机从宿主机获取CPU的时间片的百分占比。
用户空间和系统空间
第四、五行:这里主要说2个概念性的东西:buffer 和 cache。
buffer主要是什么呢?应该是待处理的数据,主要是处理2个系统之间速度不匹配的问题。而cache,一般应该是结果数据的缓存,比如从DB加载一些信息供查询用。
SWAP分区,就是想利用硬盘的做一部分缓存,如果SWAP交换非常频繁的话,就是说内存不够用!
列表说明:PID 进程ID、USER 用户、PR 优先级、VIRT 虚拟内存、RES 驻留内存、SHR 共享内存
这里需要指出的是,RES表示的是该进程实际占用的内存,而并不是申请的内存大小。也就是说当前进程所占用的内存物理大小是 RES-SHR。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721