
分库分表实战内容基本上很少有人去分享,在网上能够搜出来的也大多属于一些方法论,但大部分技术开发真正缺少的恰恰是这些实操经验,所以后续的内容多以实践为主,携手诸位真正彻底悟透分库分表相关的技术。
尤其是对于库内分表这块的分享,当你去搜索单表数据增长过快该如何处理时,一般都会推荐你做分表处理,但你几乎找不到较为全面的实操教学,网上讲述分表技术更多是停留在表面的理论概念层次做阐述,而本章中则会结合自身之前接触的一个项目业务,再对库内分表技术进行全面阐述~
一、源自于软硬结合的特殊业务
在讲本次主题之前,先来聊聊之前碰到的这个业务,这个业务比较特殊,相信很多小伙伴从未碰到过,这种业务本身用户量大,甚至可以说用户量非常非常少,因为业务的起源来自于一款硬件设备,但具体的设备类型由于某些缘故就不透露了,可以理解成是下面这个东东:

虽然当时的硬件设备并不是这个,但也和它很类似,相信大家但凡在超市购过物都认识它,也就是超市收银台的收银机,当时我们是对外提供了一千台设备,这种设备通常一台只有一个用户,所以当时整个系统上线后所有的用户加起来,涵盖后台管理员、超级管理员账号在内,也不过1200个用户,这个用户规模相较于常见业务而言属实不多。
而当时我们需要负责的就是:为这些设备开发一个操作系统,这里不是指Windows、Linux、Mac这类嵌入式的底层系统,而是给机器的操作员开发一个操作界面,就类似于诸位在超市购物时,超市收银员用手操作的那个界面。
因为这些机器本身会安装一个带UI的系统,里面也支持安装一些软件,我们的软件会以GUI的形式嵌入这些设备,当时我要干的就是直接开发API接口,然后提供给GUI界面界面调用。本质上就属一个前后端分离的项目,只不过前端从原本的Web界面变成了GUI界面。
大家听起来这个项目是不是特别容易完成,用户量又少代表不需要考虑并发,也不会存在太大的流量冲击,性能要求也不会太高,似乎就是一个简简单单的单体增删改查项目呀?但事情远没有表面这么简单,诸位请接着往下看。
1、项目的难点
起初当我收到通知要负责这个需求时,从表面浅显的想了一下,似乎发现也不是太难,就是一个单体项目的CRUD工作,以我这手出神入化的CV大法,Hlod住它简直轻轻松松,因此当时也没想太多就直接接手了,项目初期由于团队每位成员经验都很丰富,各自凭借着个人的Copy神功,项目的开发进度可谓是一骑千里,但慢慢的问题来了,而且这个问题还不小!
当时大概对外预计分发1000台机器,每台机器正式投入运营后,预估单日会产生500~600条数据的产出,套到前面的举例中,也就是大概会向几百个超市投放共计1000台收银机,每个收银台平均下来之后,大概单日内会有500~600个顾客结账!
这里咱们做个数学题:现在有1000台机器,每台机器单日就算产生500条数据:1000 * 500 = 500000,这也就意味着单日的账单表中会新增50W条流水数据,单月整个账单表的数据增长量为:50W * 30 = 1500W!
单月数据增长1500W的概念不言而喻,这也就代表着一年的数据增长量为1500W * 12 = 1.8E,这批机器投入后预估最少会运行三年起步,甚至十年乃至更久,同时第一批次就要投入1000台,后面可能还会有第二批次、第三批次.....的投入。
50W只是最低的账单流水数据量,后续正式运营后可能数据量更大,此时架构的设计就成了难题!
2、方案的探讨
基本上当时团队的成员中,没人在此之前碰过这类需求,因此开了一个研讨会,去决定该如何将具体的方案落地,这里有人也许会说,数据量这么大,快上分布式/微服务啊!但实则解决不了这个问题,Why?因为项目整体的用户量并不大,最多同一时刻也才1000并发请求,就算这个并发量再增大几个级别,这里用单体架构优化好了也能够抗住,所以问题并不在业务系统的架构上面,而是在数据落库这方面。
这里直接用分库可以吗?答案是也不行,Why?因为整个项目中只有账单表才有这么大的数据量,其他的用户表、系统表、功能菜单表、后台表......,基本上不会有太大的数据量,所以直接做分库也没必要,属实有些浪费资源。
有小伙伴可能想到了!在之前的文章中好像聊过《MySQL的表分区技术》,这里可以按月份对流水表做分区呀!乍一听似乎像那么一回事,但依旧不行,因为第一批机器投入后,单月预计就会产生1500W条数据,后续可能会增加机器数量,因此单月的数据量达到2000W、3000W.....都有可能,如果按月做表分区,每个分区里面都有几千万条数据,一张账单表的流水随着时间推移,数据量甚至会达到几十亿!
一张表中存储几十亿条数据,这基本上不现实,虽然InnoDB在数据页为16KB尺寸下,单表最多能存储64TB数据,有可能这几十亿条数据真的能存下去,但查询时的性能简直令人头大,并且最关键的是不方便后续对数据做维护、管理、备份和迁移工作。
因此经过一番探讨后,最后决定选择了表分区技术的进阶版实现,即单库内做水平分表,按月份对数据做分表,也就是将账单表分为month_bills_202210、month_bills_202211、month_bills_202212.......以月份结尾的多张表,每个月的账单流水数据最终都会插入到各自的月份表中。
最终架构定型为:业务系统使用单体架构 + 数据库使用单库 + 流水表按月份做水平分表。
二、按月分表方案的落地实践
在上一阶段中已经决定好了具体的方案,但又该如何将方案落地呢?首先咱们先把方案落地的思路捋清楚:
①能够自动按月创建一张月份账单表,从而将每月的流水数据写入进去。
②写入数据时,能够根据当前的日期,选择对应的月份账单表并插入数据。
实现了上面两个需求后,整个方案近乎落地了一半,但接下来该如何去实现相应功能呢?咱们一点点来动手实现。
1、利用存储过程实现按月动态创建表
创建表的SQL语句大家都不陌生,按月份创建表之前,自然也需要一份原生创建表的DDL语句,如下:
CREATE TABLE `month_bills_202211` (`month_bills_id` int(8) NOT NULL AUTO_INCREMENT COMMENT '账单ID',`serial_number` varchar(50) NOT NULL COMMENT '流水号',`bills_info` text NOT NULL COMMENT '账单详情',`pay_money` decimal(10,3) NOT NULL COMMENT '支付金额',`machine_serial_no` varchar(20) NOT NULL COMMENT '收银机器',`bill_date` timestamp NOT NULL COMMENT '账单日期',`bill_comment` varchar(100) NULL DEFAULT '无' COMMENT '账单备注',PRIMARY KEY (`month_bills_id`) USING BTREE,UNIQUE `serial_number` (`serial_number`),KEY `bill_date` (`bill_date`))ENGINE = InnoDBCHARACTER SET = utf8COLLATE = utf8_general_ciROW_FORMAT = Compact;
上述的语句会创建一张月份账单表,这张表主要包含七个字段,如下:
| 字段 | 简介 | 描述 |
|---|---|---|
month_bills_id |
月份账单ID | 主要作为月份账单表的主键字段 |
serial_number |
流水号 | 所有账单流水数据的唯一流水号 |
bills_info |
账单详情 | 顾客本次订单中,购买的所有商品详情数据 |
pay_money |
支付金额 | 本次顾客共计消费的总金额 |
machine_serial_no |
收银机器 | 负责结算顾客订单的收银机器 |
bill_date |
账单日期 | 本次账单的结算日期 |
bill_comment |
账单备注 | 账单的额外备注 |
其中注意的几个小细节:
①日期字段使用的是timestamp类型,而并非datetime,因为前者更省空间。
②账单详情字段用的是text类型,因为这个字段可能会出现很多的信息。
③定义了一个和表没有关系的自增字段作为主键,用于维护聚簇索引树的结构。
除开有上述七个字段外,还有三个索引:
| 索引字段 | 索引类型 | 索引作用 |
|---|---|---|
month_bills_id |
主键索引 | 主要作用就是用来维护聚簇索引树 |
serial_number |
唯一索引 | 当需要根据流水号查询数据时使用 |
bill_date |
唯一联合索引 | 当需要根据日期查询数据时使用 |
到这里就有了最基本的建表语句,主要是用来创建第一张月份账单表,如果想要实现动态按照每月建表的话,还需要用到存储过程来实现,接着来写一个存储过程。
最终撰写出的存储过程如下:
DELIMITER //DROP PROCEDURE IF EXISTS create_table_by_month //CREATE PROCEDURE `create_table_by_month`()BEGIN-- 用于记录下一个月份是多久DECLARE nextMonth varchar(20);-- 用于记录创建表的SQL语句DECLARE createTableSQL varchar(5210);-- 执行创建表的SQL语句后,获取表的数量DECLARE tableCount int;-- 用于记录要生成的表名DECLARE tableName varchar(20);-- 用于记录表的前缀DECLARE table_prefix varchar(20);-- 获取下个月的日期并赋值给nextMonth变量SELECT SUBSTR(replace(DATE_ADD(CURDATE(), INTERVAL 1 MONTH),'-', ''),1, 6) INTO @nextMonth;-- 设置表前缀变量值为td_user_banks_log_set @table_prefix = 'month_bills_';-- 定义表的名称=表前缀+月份,即 month_bills_2022112 这个格式SET @tableName = CONCAT(@table_prefix, @nextMonth);-- 定义创建表的SQL语句set @createTableSQL=concat("create table if not exists ",@tableName,"(`month_bills_id` int(8) NOT NULL AUTO_INCREMENT COMMENT '账单ID',`serial_number` varchar(50) NOT NULL COMMENT '流水号',`bills_info` text NOT NULL COMMENT '账单详情',`pay_money` decimal(10,3) NOT NULL COMMENT '支付金额',`machine_serial_no` varchar(20) NOT NULL COMMENT '收银机器',`bill_date` timestamp NOT NULL DEFAULT now() COMMENT '账单日期',`bill_comment` varchar(100) NULL DEFAULT '无' COMMENT '账单备注',PRIMARY KEY (`month_bills_id`) USING BTREE,UNIQUE `serial_number` (`serial_number`),KEY `bill_date` (`bill_date`)) ENGINE = InnoDBCHARACTER SET = utf8COLLATE = utf8_general_ciROW_FORMAT = Compact;");-- 使用 PREPARE 关键字来创建一个预备执行的SQL体PREPARE create_stmt from @createTableSQL;-- 使用 EXECUTE 关键字来执行上面的预备SQL体:create_stmtEXECUTE create_stmt;-- 释放掉前面创建的SQL体(减少内存占用)DEALLOCATE PREPARE create_stmt;-- 执行完建表语句后,查询表数量并保存再 tableCount 变量中SELECTCOUNT(1) INTO @tableCountFROMinformation_schema.`TABLES`WHERE TABLE_NAME = @tableName;-- 查询一下对应的表是否已存在SELECT @tableCount 'tableCount';END //delimiter ;
上述这个存储过程比较长,但基本上都写好了注释,所以阅读起来应该还是比较轻松的,也包括该存储过程在MySQL5.1、8.0版本中都测试过,所以大家也可以直接用,主要拆解一下里面较为难理解的一句SQL,如下:
SELECT SUBSTR(replace(DATE_ADD(CURDATE(), INTERVAL 1 MONTH),'-', ''),1, 6) INTO @nextMonth;
这条语句执行之后会生成一个202212这样的月份数字,主要用来作为表名的后缀,以此来区分不同的表,但里面用了几个函数组合出了该效果,下面做一下拆解,如下:
-- 在当前日期的基础上增加一个月,如2022-11-12 23:46:11,会得到2022-12-12 23:46:11select DATE_ADD(CURDATE(), INTERVAL 1 MONTH);-- 使用空字符代替日期中的 - 符号,得到 20221212 23:46:11 这样的效果select replace('2022-12-12 23:46:11', '-', '');-- 对字符串做截取,获取第一位到第六位,得到 202212 这样的效果select SUBSTR("20221212 23:46:11",1,6);
经过上述拆解之后大家应该能看的很清楚,最终每次调用该存储过程时,都会基于当前数据库的时间,然后向后增加一个月,同时将格式转化为YYYYMM格式,接下来调用该存储过程,如下:
call create_table_by_month();+------------+| tableCount |+------------+| 1 |+------------+
当返回的值为1而并非0时,就表示已经在数据库中查到了前面通过存储过程创建的表,即表示动态创建表的存储过程可以生效!接着为了能够每月定时触发,可以在MySQL中注册一个每月执行一次的定时事件,如下:
create EVENT`create_table_by_month_event` -- 创建一个定时器ON SCHEDULE EVERY1 MONTH -- 每间隔一个月执行一次STARTS'2022-11-28 00:00:00' -- 从2022-11-28 00:00:00后开始ON COMPLETIONPRESERVE ENABLE -- 执行完成之后不删除定时器DOcall create_table_by_month(); -- 每次触发定时器时执行的语句
MySQL5.1版本中除开引入了存储过程/函数、触发器的支持外,还引入了定时器的技术,也就是支持定时执行一条SQL,此时咱们可借助MySQL自带的定时器来定时调用之前的存储过程,最终实现按月定时创建表的需求!
但定时器在使用之前,需要先查看定时器是否开启,如下:show variables like 'event_scheduler';如果是OFF关闭状态,需要通过set global event_scheduler = 1 | on;命令开启。如果想要永久生效,MySQL8.0以下的版本可找到my.ini/my.conf文件,然后找到[mysqld]的区域,再里面多加入一行event_scheduler = ON的配置即可。
这里再附上一些管理定时器的命令:
-- 查看创建的定时器show events;select * from mysql.event;select * from information_schema.EVENTS;-- 删除一个定时器drop event 定时器名称;-- 关闭一个定时器任务alter event 定时器名称 on COMPLETION PRESERVE DISABLE;-- 开启一个定时器任务alter event 定时器名称 on COMPLETION PRESERVE ENABLE;
经过上述几步后,就能够让MySQL自己按月创建表了,但为啥我会将定时器的时间设置为2022-11-28 00:00:00这个时间后开始呢?因为202211这张表我已经手动建立了,不将建立表的工作放在月初一号执行,这是因为前面的存储过程是创建下月表,而不是创建当月表,同时月底提前创建下月表,还能提高容错率,在MySQL定时器故障的情况下,能预留人工介入的时间。
2、写入数据时能够根据月份插入对应表
作为一个后端项目,必然还需要搭建客户端,这里用SpringBoot+MyBatis来快速构建一个单体项目(最后会给出完整源码),这里需要注意,月份账单表对应的实体类中要多出一个targetTable字段,如下:
public class MonthBills {// 月份账单表IDprivate Integer monthBillsId;// 账单流水号private String serialNumber;// 支付金额private BigDecimal payMoney;// 收银机器private String machineSerialNo;// 账单日期private Date billDate;// 账单详情private String billsInfo;// 账单备注private String billComment;// 要操作的目标表private String targetTable;// 省略构造方法和Get/Set方法.....}
上述的实体类与之前的表字段结构几乎完全相同,但会多出一个targetTable属性,后续会用来记录要操作的目标表,接着再撰写一个工具类,如下:
public class TableTimeUtils {/** 使用ThreadLocal来确保线程安全,或者可以使用Java8新引入的DateTimeFormatter类:* monthTL:负责将一个日期处理成 YYYYMM 格式*/private static ThreadLocal<SimpleDateFormat> monthTL =ThreadLocal.withInitial(() ->new SimpleDateFormat("YYYYMM"));// 表的前缀private static String tablePrefix = "month_bills_";// 将一个日期格式化为YYYYMM格式public static String getYearMonth(Date date) {return monthTL.get().format(date);}// 获取目标数据的表名(操作单条数据公用的方法:增删改查)public static void getDataByTable(MonthBills monthBills){// 获取传入对象的时间Date billDate = monthBills.getBillDate();// 根据该对象中的时间,计算出要操作的表名后缀String yearMonth = getYearMonth(billDate);// 将表前缀和后缀拼接,得到完整的表名,如:month_bills_202211monthBills.setTargetTable(tablePrefix + yearMonth);}}这个工具类主要负责处理日期的时间格式,以及用来定位要操作的目标表名,对于日期格式化类:SimpleDateFormat由于是线程不安全的,所以使用ThreadLocal来确保线程安全!上述工具类中主要提供了两个基础方法:getYearMonth():将一个日期格式化成YYYYMM格式。getDataByTable():获取单条数据操作时的表名。有了工具类后,接着来撰写Dao、Mapper层的代码,如下:public interface MonthBillsMapper {int deleteByPrimaryKey(Integer monthBillsId);int insertSelective(MonthBills record);MonthBills selectByPrimaryKey(Integer monthBillsId);int updateByPrimaryKeySelective(MonthBills record);}
上述是月份账单表对应的Dao/Mapper接口,因为我这里是通过MyBatis的逆向工程文件自动生成的,所以名字就是上面那样,我这边未成更改,接着来看看对应的xml文件,如下:
<insert id="insertSelective" parameterType="com.zhuzi.dbMachineSubmeter.entity.MonthBills">insert into ${targetTable}<trim prefix="(" suffix=")" suffixOverrides="," ><if test="monthBillsId != null" >month_bills_id,</if><if test="serialNumber != null" >serial_number,</if><if test="payMoney != null" >pay_money,</if><if test="machineSerialNo != null" >machine_serial_no,</if><if test="billDate != null" >bill_date,</if><if test="billComment != null" >bill_comment,</if><if test="billsInfo != null" >bills_info,</if></trim><trim prefix="values (" suffix=")" suffixOverrides="," ><if test="monthBillsId != null" >#{monthBillsId,jdbcType=INTEGER},</if><if test="serialNumber != null" >#{serialNumber,jdbcType=VARCHAR},</if><if test="payMoney != null" >#{payMoney,jdbcType=DECIMAL},</if><if test="machineSerialNo != null" >#{machineSerialNo,jdbcType=VARCHAR},</if><if test="billDate != null" >#{billDate,jdbcType=TIMESTAMP},</if><if test="billComment != null" >#{billComment,jdbcType=VARCHAR},</if><if test="billsInfo != null" >#{billsInfo,jdbcType=LONGVARCHAR},</if></trim></insert>
上述这么大一长串,其实也不是俺手敲的,依旧是MyBatis逆向工程生成的代码,但我对其中的一处稍微做了改动,如下:
-- 原本生成的代码是:insert into month_bills_202211-- 然后被我改成了:insert into ${targetTable}
还记得最开始的实体类中,咱们多添加的那个targetTable属性嘛?在这里会根据该字段的值动态的去操作不同月份的表,接着来写一下Service层的接口和实现类,如下:
// Service接口(目前里面只有一个方法)public interface IMonthBillsService {int insert(MonthBills monthBills);}// Service实现类public class MonthBillsServiceImpl implements IMonthBillsService {private MonthBillsMapper billsMapper;public int insert(MonthBills monthBills) {// 获取要插入数据的表名TableTimeUtils.getDataByTable(monthBills);// 返回插入数据的状态return billsMapper.insertSelective(monthBills);}}在service层目前仅实现了一个插入数据的方法,其中的逻辑也非常简单,仅仅在调用Dao层的插入方法之前,获取了一下当前这条数据要插入的表名,最后来看看Controller/API层,如下:("/bills")public class MonthBillsAPI {private IMonthBillsService billsService;// 账单结算的API("/settleUp")public String settleUp(MonthBills monthBills){// 设置账单交易时间为当前时间monthBills.setBillDate(new Date(System.currentTimeMillis()));// 使用UUID随机生成一个流水号monthBills.setSerialNumber(monthBills.getMachineSerialNo()+ System.currentTimeMillis());// 调用新增账单数据的service方法if (billsService.insert(monthBills) > 0){return ">>>>账单结算成功<<<<";}return ">>>>账单结算失败<<<<";}}
在API层主要对外提供了一个账单结算的接口,这里为了方便测试,所以对于请求方式的处理就没那么严谨了,在调用该接口后,会先获取一下当前系统时间作为账单时间,接着会随机生成一个UUID作为流水号,最后就会调用service层的insert()方法。
到这里为止就搭建出了一个最简单的WEB接口,接着来做一个小小的测试,这里为了方便就不用专门的PostMan工具了,就通过浏览器简单的调试一下,接口如下:http://localhost:8080/bills/settleUp?billsInfo=白玉竹子*3:9999.999&payMoney=9999.999&machineSerialNo=NF-002-X
最终测试效果图如下:
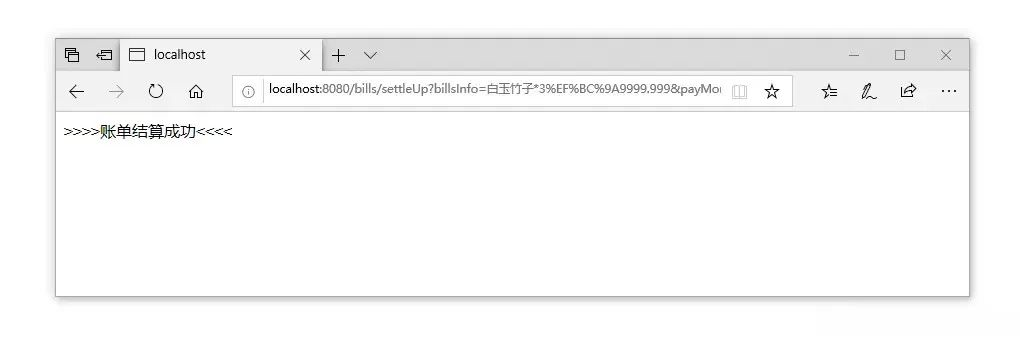
效果很明显,确实做到了咱们需要的效果,接着来看看控制台输出的SQL日志,如下:

主要可以观察到,原本xml中的动态表名,最终会根据月份被替换为具体的表名,最后再来看看数据库中的表是否真正插入了数据,如下:
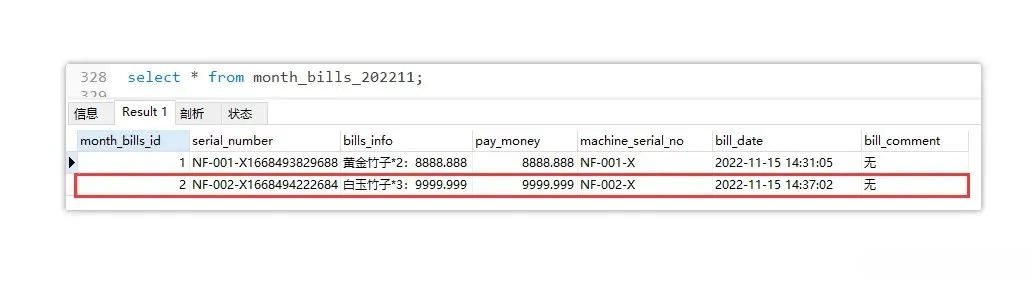
因为之前测试过一次,因此表中早有了一条数据,主要观察第二条,的确是咱们刚刚测试时插入的数据,这也就意味着咱们按月动态插入的需求已经实现。
但看到这里估计绝大部分小伙伴略微有些懵,毕竟一通代码下来看起来,尤其是不在IDEA工具里面,没那么方便调试,因此最后画一个执行流程图,提供给诸位来梳理整体思路!
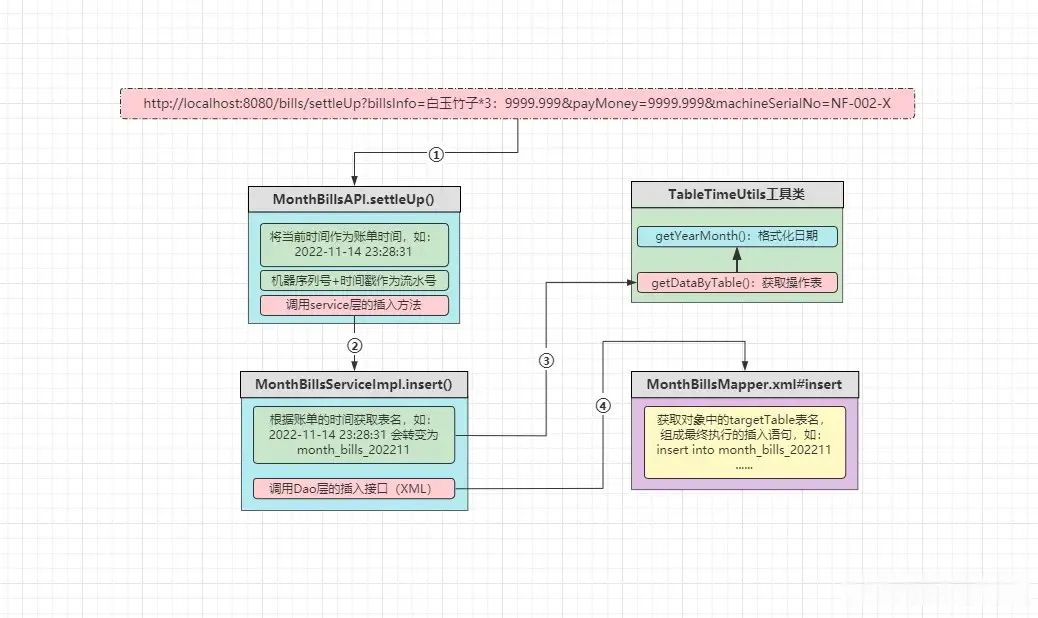
执行流程
①客户端调用结算接口,传入相关的账单数据,即账单详情、账单金额、收银机器。
②API层会先获取当前系统时间作为账单交易的时间,然后调用Service层的插入方法。
③Service层会先根据账单交易时间,获取到数据具体要插入的表名,接着调用Dao层接口。
④Dao层会根据上层传递过来的表名,生成具体的SQL语句,然后执行插入数据的操作。
三、按月分表后要解决的问题
上述已经将最基础的需求做了简单实现,那么接着再分析一下这些月份账单表还会有哪些需求呢?
①除去最基本的新增操作外,还会有删除、修改、查询账单的需求。
②一般账单表中的流水数据,都会支持按时间进行范围查询操作。
上述这两个需求会是账单表中还会存在的操作,对于第一点也比较容易实现,就是要求客户端在修改、删除、查询数据时,都必须携带上对应的时间,一般客户端的修改、删除操作都是基于先查询出数据的基础之上的,而一般查询数据都会按照月份进行查询,或者根据流水号进行查询。
1、根据流水号查询数据
还记得前面对于流水号的设计嘛?前面没有太过说明,这里咱们单独拧出来聊一聊:
setSerialNumber(monthBills.getMachineSerialNo()+System.currentTimeMillis());
这里使用了收银机器序列号+时间戳作为账单流水号,因为同一台机器在同一时间内,绝对只能对一个账单进行结算,所以再结合递增的时间戳,就能够得到一个全局唯一的流水号。System.currentTimeMillis()获取到的时间戳是13位数字,会放在机器序列号的后面,那接下来如果客户端要根据流水号查询账单数据,又该如何定位具体的表呢?首先需要在工具类中撰写一个新的方法:
// 根据流水号得到表名public static void getTableBySerialNumber(MonthBills monthBills){// 获取流水号的后13位(时间戳)String timeMillis = monthBills.getSerialNumber().substring(monthBills.getSerialNumber().length() - 13);// 将字符串类型的时间戳转换为long类型long millis = Long.parseLong(timeMillis);// 调用getYearMonth()方法获取时间戳中的年月String yearMonth = getYearMonth(new Date(millis));// 用表的前缀名拼接年月,得到最终要操作的表名monthBills.setTargetTable(tablePrefix + yearMonth);}
上面这个方法实际上很简单,就是先解析流水号中的时间戳,然后根据时间戳得到具体的年月,最后拼接表的前缀名,得到最终需要操作的表名,接着来写一下Dao层代码,如下:
<!-- 在MonthBillsMapper中多定义一个接口:--><!-- MonthBills selectBySerialNumber(MonthBills record); --><!-- 定义返回的结果集 --><resultMap id="ResultMapMonthBills" type="com.zhuzi.dbMachineSubmeter.entity.MonthBills" ><constructor ><idArg column="month_bills_id" jdbcType="INTEGER" javaType="java.lang.Integer" /><arg column="serial_number" jdbcType="VARCHAR" javaType="java.lang.String" /><arg column="pay_money" jdbcType="DECIMAL" javaType="java.math.BigDecimal" /><arg column="machine_serial_no" jdbcType="VARCHAR" javaType="java.lang.String" /><arg column="bill_date" jdbcType="TIMESTAMP" javaType="java.util.Date" /><arg column="bill_comment" jdbcType="VARCHAR" javaType="java.lang.String" /><arg column="bills_info" jdbcType="LONGVARCHAR" javaType="java.lang.String" /></constructor></resultMap><!-- 定义字段列表 --><sql id="Base_Column_List" >month_bills_id, serial_number, bills_info, pay_money, machine_serial_no,bill_date, bill_comment</sql><!-- 编写对应的查询语句,这里依旧是通过 ${targetTable} 动态表名做查询 --><select id="selectBySerialNumber" resultMap="ResultMapMonthBills"parameterType="com.zhuzi.dbMachineSubmeter.entity.MonthBills" >select<include refid="Base_Column_List" />from ${targetTable}where serial_number = #{serial_number,jdbcType=VARCHAR}</select>
接着来写一下Service层的代码,如下:
// 在IMonthBillsService接口中多定义一个方法MonthBills selectBySerialNumber(MonthBills monthBills);// 在MonthBillsServiceImpl实现类中撰写具体的实现public MonthBills selectBySerialNumber(MonthBills monthBills) {// 根据流水号获取要查询数据的具体表名TableTimeUtils.getTableBySerialNumber(monthBills);// 调用Dao层根据流水号查询数据的方法return billsMapper.selectBySerialNumber(monthBills);}
这里的实现尤为简单,仅调用了一下前面写的工具类方法,获取了一下要查询数据的动态表名,接着再来写一下API层的接口,如下:
// 根据流水号查询数据的APIpublic String selectBySerialNumber(MonthBills monthBills){// 调用Service层根据流水号查询数据的方法MonthBills result = billsService.selectBySerialNumber(monthBills);if (result != null){return result.toString();}return ">>>>未查询到流水号对应的数据<<<<";}
接着来做一下测试,调用地址如下:
http://localhost:8080/bills/selectBySerialNumber?serialNumber=NF-002-X1668494222684
测试效果图如下:

此时会发现,根据流水号查询数据的效果就实现啦,这里主要是得设计好流水号的组成,其中一定要包含一个时间戳在内,这样就能够通过解析流水号的方式,得到具体要查询数据的表名,否则根据流水号查询数据的动作将异乎寻常的困难,因为需要把全部表扫描一次才能得到数据。
设计好根据流水号查询数据后,对于修改和删除的操作则不再重复撰写啦!因为过程也大致相同,就是在修改、删除时,同样先根据流水号定位到具体要操作的表,接着再去对应表中做相应操作即可。
2、按时间范围查询数据
按时间范围查询账单的流水数据,这是所有后台管理系统中都支持的功能,在这个项目中也不例外,但想要实现这个功能,则必须要有先实现两个功能:
①能够根据用户输入的两个时间范围,得到两个日期之间的所有表名。
②能够根据第①步中得到的表名,生成对应的查询语句,能够在单张表、多张表中通用。
上述这两个需求实际上实现起来也并不难,接着来一起做一下!
(1)得到两个日期之间的所有表名
想要实现这个功能,那必然需要再在工具类中撰写一个方法,如下:
// 获取按时间范围查询时,两个日期之间,所有月份账单表的表名public static List<String> getRangeQueryByTables(String startTime, String endTime){// 声明一个日期格式化类SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM");// 声明保存表名的集合List<String> tables = new ArrayList<>();try {// 将两个传入的字符日期转换成日期类型Date startDate = sdf.parse(startTime);Date endDate = sdf.parse(endTime);//用 Calendar 进行日期比较判断Calendar calendar = Calendar.getInstance();while (startDate.getTime() <= endDate.getTime()){// 把生成的月份拼接表前缀名,加入到集合中tables.add(tablePrefix + monthTL.get().format(startDate));// 设置日期,并把比对器的日期增加一月calendar.setTime(startDate);calendar.add(Calendar.MONTH, 1);// 获取增加后的日期startDate = calendar.getTime();}} catch (ParseException e) {e.printStackTrace();}// 返回两个日期之间的所有表名return tables;}
该方法需要传入两个参数,即两个字符串类型的时间,接着会通过Calendar工具类,对两个日期的大小做判断,当开始日期小于结束日期时,则会直接将表前缀名与年月拼接,得到一张月份账单表的表名,接着会对开始日期加一个月,然后继续重复上一步......,直至得到两日期之间的所有表名。
(2)根据表名集合生成对应的SQL语句
想要实现这个功能其实也非常简单,只需要做一堆判断即可,再在工具类中写一个方法:
// 根据日期生成SQL语句的方法public static String getRangeQuerySQL(String startTime, String endTime){// 先获取两个日期之间的所有表名List<String> tables = getRangeQueryByTables(startTime, endTime);// 提前创建一个字符串对象保存SQL语句StringBuffer sql = new StringBuffer();// 如果查询的两个日期是同一张表,则直接生成 BETWEEN AND 的SQL语句if (tables.size() == 1){sql.append("select * from ").append(tables.get(0)).append(" where bill_date BETWEEN '").append(startTime).append("' AND '").append(endTime).append("';");// 如果本次范围查询的两个日期之间有多张表}else {// 则用for循环遍历所有表名for (String table : tables) {// 对于第一张表则只需要查询开始日期之后的数据if (table.equals(tables.get(0))){sql.append("select * from ").append(table).append(" where bill_date > '").append(startTime).append("' union all ");}// 对于最后一张表只需要查询结束日期之前的数据else if (table.equals(tables.get(tables.size()-1))){sql.append("select * from ").append(table).append(" where bill_date < '").append(endTime).append("';");// 对于其他表则获取所有数据} else {sql.append("select * from ").append(table).append("' union all ");}}}// 返回最终生成的SQL语句return sql.toString();}
这个方法看起来似乎有些长,但其实功能也非常简单,如下:
①如果两个日期在一个月内,则生成BETWEEN AND的查询语句。
如果两个日期间隔了多月,则用
for
循环遍历前面得到的表名:
如果是第一张表,则只需要查询开始日期之后的数据,再用union all拼接后面的语句。
如果是最后一张表,则只需要查询结束日期之前的数据,以;分号结尾即可。
如果是中间的表,则查询对应的所有数据,接着继续用union all拼接其他语句。
接着做个简单的小测试,效果如下:
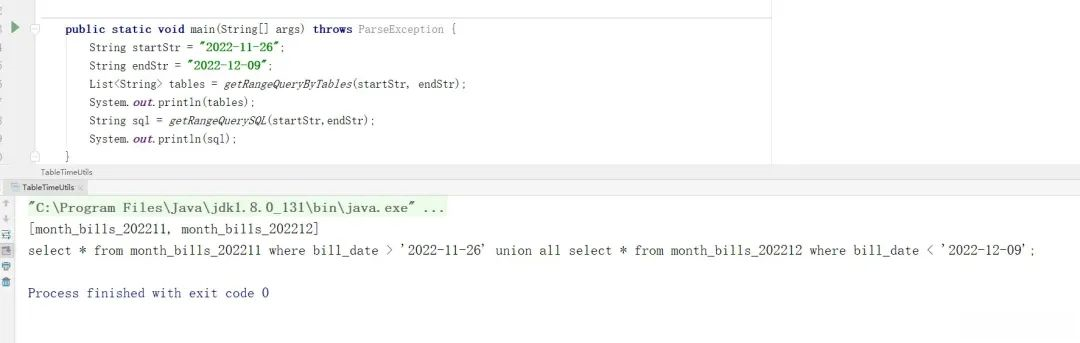
很明显,通过这两个方法,可以实现最初咱们提出的两个需求,实现这两个基础功能后,接着套入到前面的项目中~
(3)实现按时间做范围查询的API接口
依旧按照之前的步骤,先定义Dao层的接口和.xml文件,如下:
// 定义一个返回多条数据的接口List<MonthBills> rangeQueryByDate(@Param("sql") String sql);<select id="rangeQueryByDate" resultMap="ResultMapMonthBills"parameterType="java.lang.String" >${sql}</select>
主要观察xml文件中的代码,因为这里需要实现自定义SQL的执行,所以将SQL语句的生成工作放在了外部完成,在xml中仅需将对应的SQL语句发给MySQL执行,并接收返回结果即可,接着来写一下Service层的接口和实现:
// 在IMonthBillsService接口中多定义一个方法List<MonthBills> rangeQueryByDate(String startTime, String endTime);// 在MonthBillsServiceImpl实现类中撰写具体的实现public List<MonthBills> rangeQueryByDate(String startTime, String endTime) {// 获取范围查询时的SQL语句String sql = TableTimeUtils.getRangeQuerySQL(startTime,endTime);return billsMapper.rangeQueryByDate(sql);}
其实核心工作已经在之前的工具类中完成了,这里仅需调用工具类中,生成两个日期之间的查询语句即可,接着再写一下API层的对外接口,就大功告成啦!如下:
// 按照范围查询两个日期之间的所有账单数据public String rangeQueryByTime( String start,String end){// 调用Service层根据流水号查询数据的方法List<MonthBills> bills = billsService.rangeQueryByDate(start, end);if (bills != null){return bills.toString();}return ">>>>指定的日期中没有账单数据<<<<";}
在这里面仅仅只是调用了Service层的方法而已,接下来测试一下,测试地址为:
localhost:8080/bills/rangeQueryByTime?start=2022-11-01&end=2022-11-30
最终效果如下:
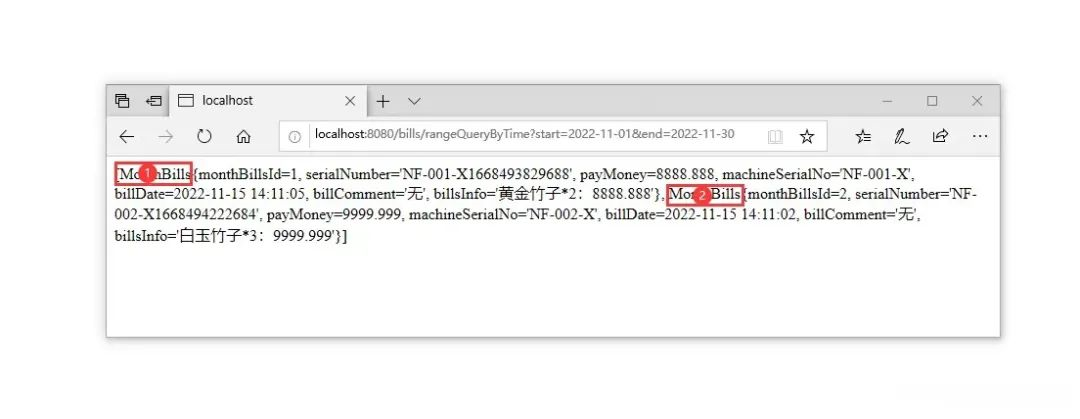
因为我表中就两条数据,所以就做了一个单月表的测试,这里单月账单表的数据查询无误,大家也可以再建立一张其他月份的账单表,效果也是照样没有问题的~
(4)按时间范围查询数据小结
其实这里的做法仅仅只是为了给大家演示效果,之前的实际业务中远比这更加复杂,因为每张月份账单表会有上千万条数据,不可能一次性查询几张、几十张的月份账单表,这样对于网络、资源的开销太大。
实际业务中,一方面会限制查询的日期范围,最多只允许客户查询近六月的账单流水。另一方面还会结合数据分页,也就是每页仅显示20条数据,随着用户的翻页动作触发后,才会对每张不同的月份账单表做查询。
对于这种会批量查询所有账单表的业务,基本上是查询一些流水交易金额的统计数据,而且也仅是提供给后台系统操作,用于定时跑批去生成统计数据,如近一周、一月、一季、半年、一年的交易金额、账单总量.....等这类需求。
这里给大家实现这个需求的目的在于:让大家理解按月做了水平分表后,该如何查询多张表的数据。
四、库内分表篇总结
看到这里,对于库内分表篇的内容也接近了尾声,有小伙伴也许会疑惑:那如果我每月的数据量更大怎么办呢?比如前面的例子中,如果再投入了多批机器怎么办?每月的数据量达到3000W、6000W.....甚至上亿怎么办?
如若你存在这块的顾虑,其实大可不必担心,因为咱们既然可以按月分表,那能否按半月为周期分表呢?能否按星期分表呢?能否以三天、一天为一个维度分表呢?答案显然是可以的,所以数据量无论有多大,都可能按不同的周期来划分表。
不过一般对于库内分表的场景会很少用到,毕竟库中只有某些表的数据量较大时,才会选用这种方案,如果整库的数据量较大、访问压力较高,则会直接采用分库方案(不过本篇的内容,对于一些身处东南亚的朋友,应该用的还是比较频繁的~)。
其实库内分表除开本文讲解的方式外,大家通过整合Sharding-JDBC框架来实现会更加轻松,但那样会导致依赖变多,所以如果你项目中不需要用到太多的分表,则可采用本文这种方式实现。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721