好好的ClickHouse不用,日志存储分析非要上ES和MySQL?
Anton Sidashin
2021-07-09 09:52:08
2018年,我写过一篇关于Clickhouse的文章,这段内容在互联网上仍然很流行,甚至被多次翻译。现在已经过去两年多,同时 Clickhouse 的开发节奏仍然活跃: 上个月有 800 个合并的 PR ! 这难道没让你大吃一惊吗?或许需要一小时才能查看完这些变更日志和新功能描述,例如 2020 年:https://clickhouse.tech/docs/en/whats-new/changelog/2020/
为了公平对比,ElasticSearch仓库在同一个月有惊人的1076个合并PR,同时在功能性方面,它的节奏也非常让人印象深刻!
我们正在将 Clickhouse 用于 ApiRoad.net 项目(这是一个 API 市场,开发人员出售其 API ,目前活跃开发中)的日志存储和分析,到目前为止,我们对效果感到满意。作为一名 API 开发人员, HTTP 请求/响应周期的可观察性和可分析性对于维护服务质量和快速发现 bug 非常重要,这一点对于纯 API 服务尤其如此。
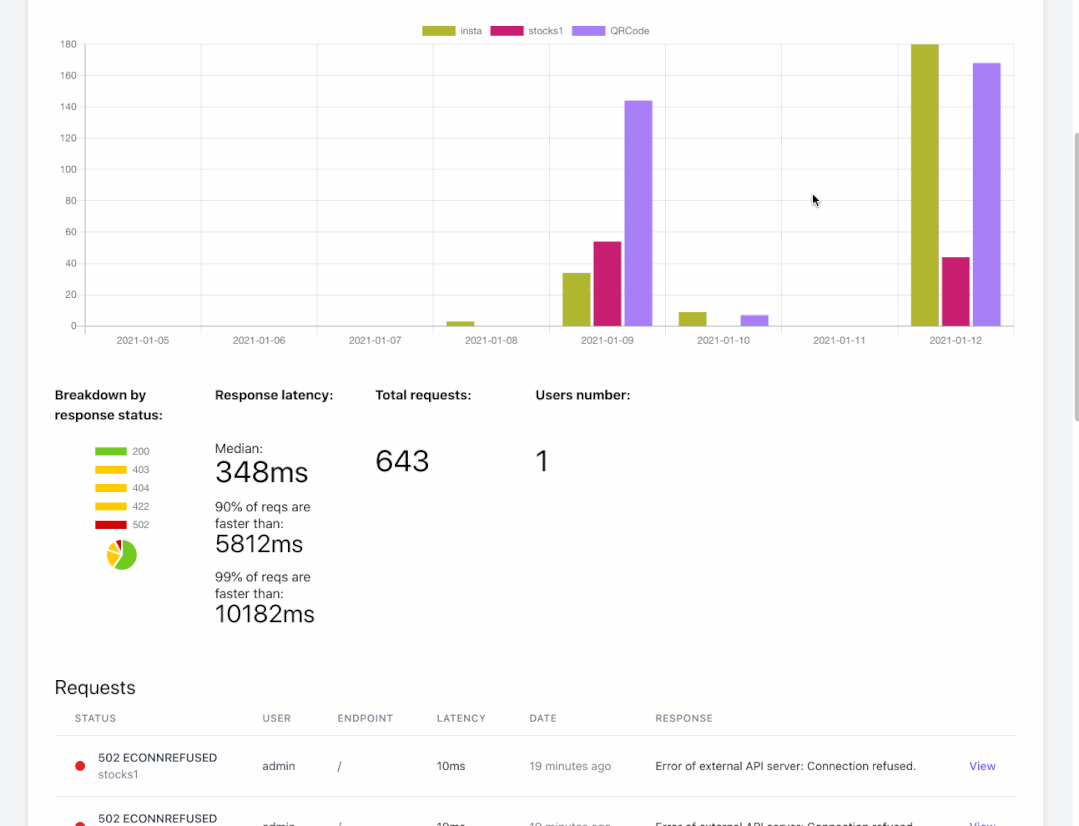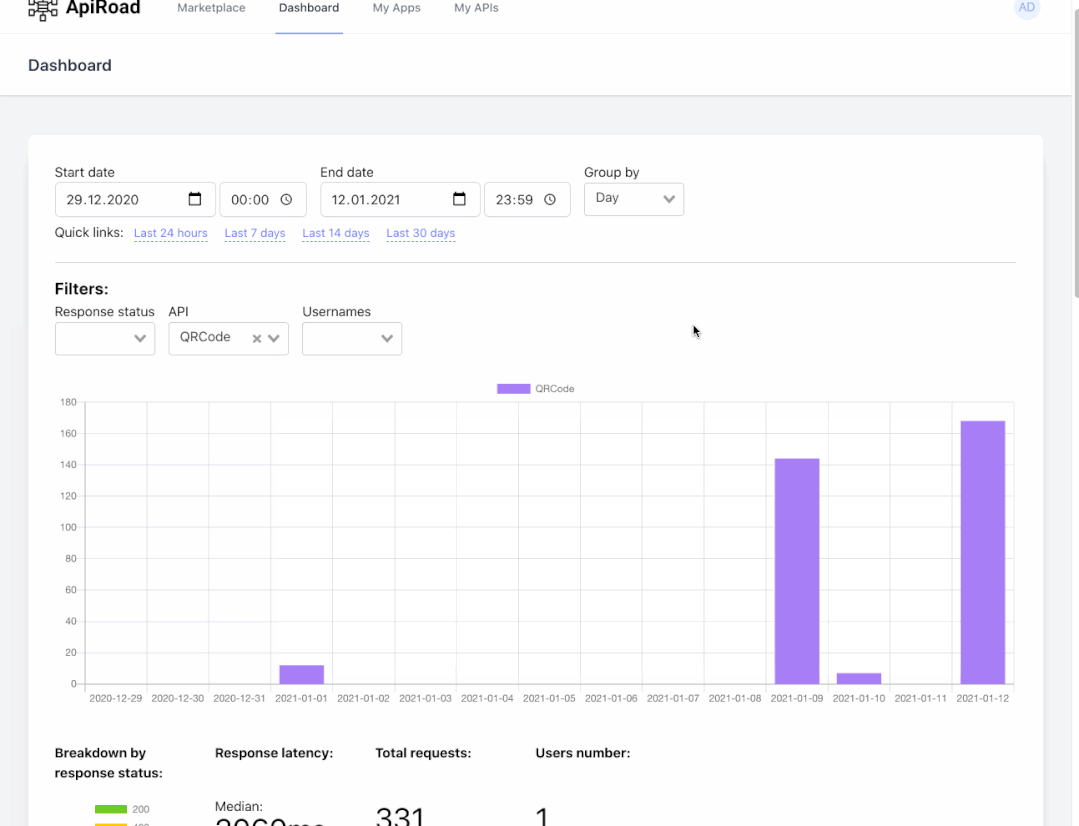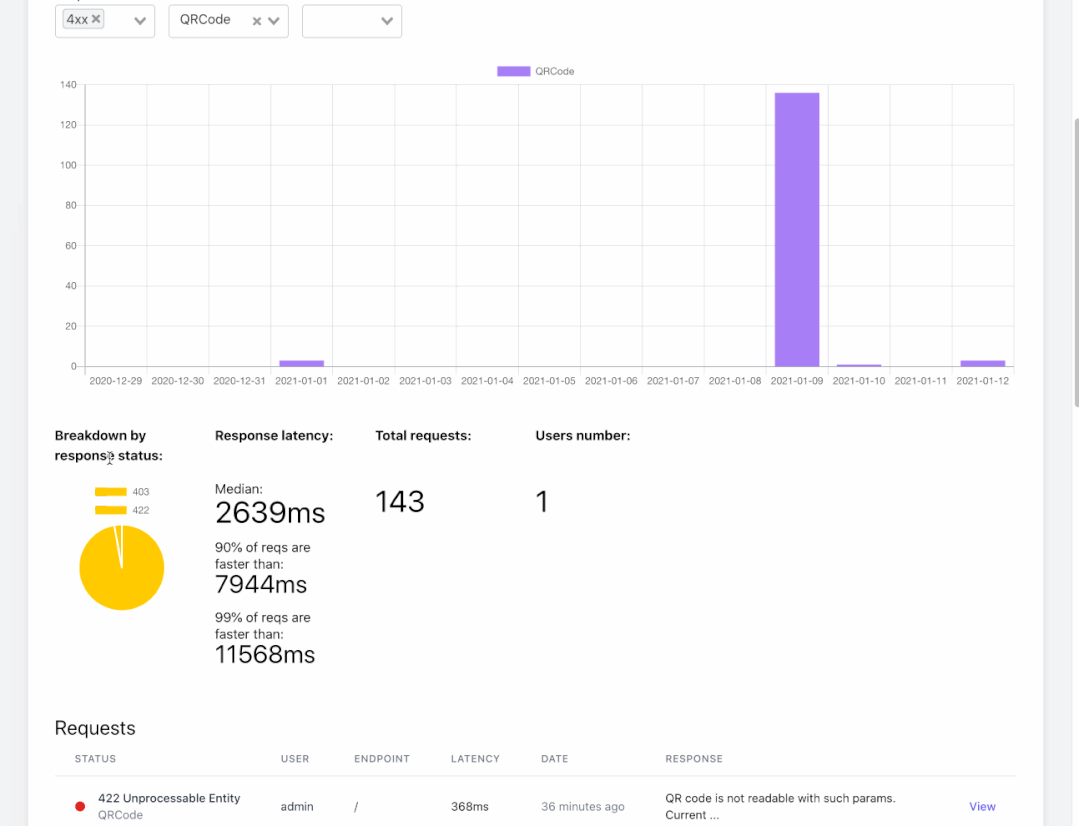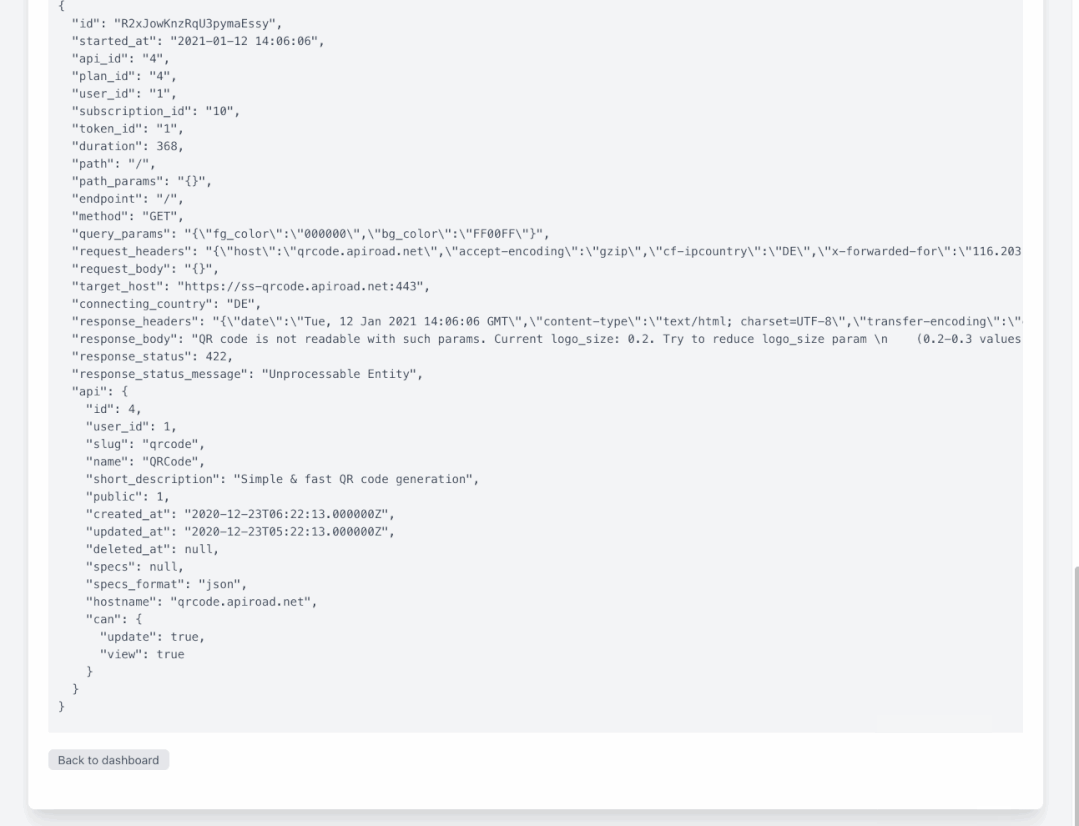
我们也在其他项目上使用 ELK( ElasticSearch,Logstash,filebeat,Kibana)技术栈用于同样目的:获取 HTTP 和邮件日志,使用 Kibana 进行事后的分析与搜索。
这篇文章主要介绍我们选择 Clickhouse 而不是 ElasticSearch(或 MySQL )作为基础数据(服务请求日志)存储解决方案的主要原因(说明:出于 OLTP的目的,我们仍会处使用 MySQL)。
一、SQL 支持, JSON 和 数组作为一等公民
SQL是用于数据分析的理想语言。我喜欢SQL查询语言,SQL schema是无趣技术的完美示例,我建议在 99% 项目中使用它从数据中发掘真相:项目代码不完美,而如果你的数据库是结构化schema 存储的,就可以相对轻松地进行改造。反言之,如果数据库数据是一个巨大的 JSON 块(NoSQL),没有人可以完全掌握数据的清晰结构,那么重构将会遇到更多麻烦。
尤其是在使用 MongoDB 的老项目中,我看到了这种情况。每一次新的分析报告和每一个涉及数据迁移的重构都无比痛苦。如果是新建一个这样的项目还算有趣——因为不需要花太多时间详细设计项目结构,只要“看看它是如何能跑起来”就行,但是维护它将会非常无趣!
但是,重要的是要注意,这种经验法则(“使用严格schema”)对于日志存储用例而言并不那么关键。这就是 ElasticSearch 如此成功、具有许多优势和灵活架构的原因。
继续回到 JSON ,就 JSON 数据的查询、语法而言,传统的关系型数据库仍在追赶 NoSQL 数据库,我们必须承认 JSON 对动态结构化数据(如日志存储)而言,是非常方便的格式。
Clickhouse 是一种在 JSON 已发展存在后(不同于 MySQL 和 Postgres )设计和构建的现代引擎。由于 Clickhouse 不必背负这些流行的 RDBMS 向后兼容性和严格 SQL 标准,Clickhouse团队可以在功能和改进方面更快速发展,实际上也的确是。Clickhouse 的开发人员有更多机会在严格 schema 与 JSON 的灵活性之间达到最佳平衡,我认为他们在这方面做得很好。Clickhouse 试图在分析领域与Google Big Query 及其他主要对手竞争,因此它对“标准” SQL进行了许多改进,这使其语法成为了杀手锏,在许多用于分析和计算目的情形下相比传统RDBMS 更多优势。
在 MySQL 中,你可以提取 JSON 字段,但是复杂的 JSON 处理仅在最新版本(具有 JSON_TABLE 函数的版本8)中可用。在 PosgreSQL 中,情况甚至更糟-在 PostgreSQL 12之前还没有直接的 JSON_TABLE 替代方案!
而这与 Clickhouse 的 JSON 及相关数组功能相比,也仅仅领先一小步。数组功能相关链接:
在很多情况下,PostgreSQL 的 generate_series() 功能很有用。来自 ApiRoad 的一个具体示例:我们需要在chart.js 时间轴上映射请求数量。每天进行常规的SELECT .. group by day,但如果某些天没有任何查询时,就会出现间隙。但我们并不想要间隙,因此需要补零,对吧?这正是 PostgreSQL 中 generate_series() 函数有用的地方。在 MySQL 中,推荐按日期创建表并进行连接,不太优雅了吧?
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-datehistogram-aggregation.html#_missing_value_2
关于查询语言:我对 ElasticSearch 的 Lucene 语法、HTTP API 以及为检索数据而编写 json 等几个方面仍然不满意。而 SQL 将是我的首选。
这是 Clickhouse 用于日期差填充时的解决方案:
SELECT a.timePeriod as t, b.count as c from ( with (select toUInt32(dateDiff('day', [START_DATE], [END_DATE])) ) as diffInTimeUnits select arrayJoin(arrayMap(x -> (toDate(addDays([START_DATE], x))), range(0, diffInTimeUnits+1))) as timePeriod ) a LEFT JOIN (select count(*) as count, toDate(toStartOfDay(started_at)) as timePeriod from logs WHERE [CONDITIONS] GROUP BY toStartOfDay(started_at)) b on a.timePeriod=b.timePeriod
在这里,我们通过 lambda 函数和循环生成一个虚拟表,然后再与按天分组的日志表进行左连接。
我认为 arrayJoin + arrayMap + range 函数方式相比 generate_series() 有更多灵活性。通过WITH FILL 关键词可用于更简洁的语法。
对于日志存储任务来说,数据schema通常会在项目生命周期中变化,ElasticSearch 允许将巨大的 JSON 块放入索引中,然后找出字段类型和索引部分。Clickhouse 也同样支持这种方法。
可以将数据放入 JSON 字段并相对快速地进行过滤,尽管在TB级上并不会很快。然后,当你经常有在特定字段查询需要时,便可以在日志表中添加物化列(materialized columns),这些列能够即时的从 JSON 中提取值。对TB级数据查询时会更加快速。
我推荐 Altinity 关于日志存储中 JSON 与 表格式对比的专题视频:
https://youtu.be/pZkKsfr8n3M
Clickhouse 在 SELECT 查询时非常快速,这在之前文章中已做讨论。
有趣的是,有证据表明,与 ElasticSearch 相比,Clickhouse 的存储效率可以高出 5-6 倍,而从查询的角度看,它的字面速度也要快一个数量级。还有另一个例子。
我相信二者没有直接的基准对比测试,至少我还未找到,因为 Clickhouse 和 ElasticSearch 在查询语法、缓存实现及整体特性上都非常不同。
MySQL 时,在仅有1亿行日志数据的表上进行如索引失效的非最优查询,都会使服务器陷入缓慢并产生内存交换,因此 MySQL 并不适合大型日志查询。但就存储而言,压缩的 InnoDB 表并没有那么糟糕。由于其基于行的特性,与 Clickhouse 相比,数据压缩方面的情况要差得多(抱歉,这次没有相关链接),但是它仍然可以在不显著降低性能的情况下设法降低成本 。因此在某些情况下,对于少量日志来说,我们依然可以使用 InnoDB 表。
在 Clickhouse 中,很容易计算 404 查询的中位数和 99 分位的耗时:
SELECT count(*) as cnt, quantileTiming(0.5)(duration) as duration_median, quantileTiming(0.9)(duration) as duration_90th, quantileTiming(0.99)(duration) as duration_99th FROM logs WHERE status=404
这里要注意 quantileTiming 函数的用法以及如何优雅地使用currying。Clickhouse 具有通用的分位数 quantile 函数!但是 quantileTiming 已针对序列化数据进行了优化,比如加载网页时间或后端响应时间的日志.
还有更多类似的,需要加权算术平均数吗?要计算线性回归吗?这很容易,只需使用专门的函数就可以。
这是 Clickhouse 相关统计函数的完整列表:
https://clickhouse.tech/docs/en/sql-reference/aggregate-functions/reference/
ElasticSearch 在这方面比 MySQL 好得多,它既具有分位数又具有加权中位数,但是它还没有线性回归。
五、MySQL 和 Clickhouse 紧密结合
MySQL 和 Clickhouse 有多种级别的相互集成,这使它们最小化数据重复的情况下非常方便在一起使用:
-
-
通过binlog将 MySQL 数据镜像至 Clickhouse
-
MySQL 数据库引擎 - 和之前方法相似但更灵活,无需 binlog
-
MySQL 表函数 通过特定查询链接 MySQL 表
-
MySQL 表引擎 在 CREATE TABLE 语句中静态描述特定表
-
我不能肯定地说动态数据库和表引擎在 JOIN 上有多么快速和稳定,这肯定是需要基准测试的。但这个概念非常吸引人-你已经可以在 Clickhouse 数据库上完整地复制 MySQL 表 ,而不必处理缓存失效和重新设置索引。
关于将 MySQL 与 Elasticsearch 结合使用,我的有限经验表明,这两种技术有太多不同。我的印象是他们彼此各说各话,并不会组合出现。所以我通常只需要把 ElasticSearch 需要索引的数据 JSON 化,然后发送到 ElasticSearch 。
之后,MySQL 数据一些迁移或任何变更操作( UPDATE/REPLACE )之后,在 Elasticseach 端找出需要重新索引的部分。关于 MySQL 和 ElasticSearch 的数据同步,这是一篇基于 Logstash 实现的文章。我不太喜欢 Logstash ,因为它的性能一般,对内存要求也很高,同时它也会成为系统中不稳定因素。对于使用 MySQL 的简单项目中,数据同步和索引往往是阻止我们使用 Elasticsearch 的因素。
是否想要附加 S3 存储的 CSV,并将其作为 Clickhouse 中的表?这非常简单。
是否要更新或删除日志行以符合数据保护规范?现在,这很容易!
在我 2018 年写第一篇文章时,Clickhouse 还没有简单的方法来删除或更新数据,这是一个真正的弊端。现在,这不再是问题。Clickhouse 利用自定义 SQL 语法删除数据行:
ALTER TABLE [db.]table [ON CLUSTER cluster] DELETE WHERE filter_expr
原因很明确,对于 Clickhouse(和其他列式数据库)来说,删除仍然是一项相当昂贵的操作,因此最好不要生产环境频繁使用。
与 ElasticSearch 相比,Clickhouse 也有缺点。首先,如果构建用于日志存储的内部分析,那么就需要最好的 GUI 工具。Kibana 目前在这方面相比 Grafana 会是很好的选择(至少,这种观点非常流行,Grafana UI 有时并不那么顺滑)。如果使用 Clickhouse ,则必须使用 Grafana 或 Redash 。(我们喜欢的 Metabase 也获得了 Clickhouse 的支持!)
但是,在我们的案例中,我们正在构建面向用户的分析方法,因此无论如何我们都必须从头开始构建分析 GUI(我们使用 Laravel,Inertia.js,Vue.js 和 Charts.js 来实现用户界面)。
另一个与生态系统有关的问题是:消费、处理、发送数据到 Clickhouse 的工具是有限制。对于 Elasticsearch,有Logstash 和 filebeat,它们是 Elastic 生态系统固有的工具,旨在完美地协同工作。幸运的是,Logstash 也可以用于将数据放入Clickhouse,从而缓解了该问题。在 ApiRoad 中,我们使用了自己定制的 Node.js 日志传送程序,该程序将日志汇总,然后分批发送给 Clickhouse(因为 Clickhouse 喜欢大批处理,而不是小的多次插入)。
我在 Clickhouse 中不喜欢的还有一些函数的奇怪命名,这是因为 Clickhouse 是由 Yandex.Metrika( Google 分析的竞争对手)创建的。比如,visitParamHas() 是用于检查JSON中是否存在特定键。通用目的,但并不是通用名称。有一堆名字不错的JSON函数名,例如JSONHas()。还有一个有趣的细节:据我所知,它们使用不同的 JSON解析引擎,虽然更符合标准,但速度稍慢。
ElasticSearch 是一个非常强大的解决方案,但我认为它最强的方面仍然是超过 10+ 节点的支持,用于大型全文检索和 facets ,复杂的索引和分值计算-这是 ElasticSearch 的亮点。当我们提及时间序列和日志存储时,似乎有更好的解决方案,而 Clickhouse 就是其中之一。ElasticSearch API 的功能非常强大,但在很多情况下,如果不从文档中复制具体 HTTP 请求,就很难记住如何做一件事,它有更多的“企业化”和“ Java 风格”。
Clickhouse 和 EasticSearch 都是占用内存很大的程序, Clickhouse 内存要求为4GB,而 ElasticSearch 的内存要求为 16GB 。我还认为 Elastic 团队关注的重点是他们新的机器学习功能,我的愚见是,尽管这些功能听起来非常新潮,但不论你拥有多少开发人员和金钱,这些庞大的功能集很难持续支持和改进。对我来说,ElasticSearch 在不断的进入“博而不精”的状态。或许,是我错了。
Clickhouse 则与众不同。设置简单、SQL 也简单、控制台客户端也很棒。通过少量配置,就可以让一切简单有效的工作起来,但是当有需要时,也可以在 TB 级数据上使用丰富的特性、副本和分片能力。
作者丨Anton Sidashin(译者:Fivezh)
来源丨网址:https://pixeljets.com/blog/clickhouse-vs-elasticsearch/
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721