
作者介绍
朱伟,微博广告SRE团队负责人,《智能运维:从0搭建大规模分布式AIOps系统》作者之一。目前负责微博广告业务可用性的保障与优化、资源利用率的提升、监控报警系统的建设以及自动化体系的推进。
一、前言
广告业务监控中,我们经常碰到多维度的数据储存和查询分析需求,比如,我们可能需要基于秒级粒度去统计某个接口 TP999 耗时,或者需要基于秒级粒度去统计微博广告在各个场景下的请求量,再或者我们需要基于分钟粒度去展示广告收入的日环比和周同比。
同时,随着微博广告流量的日益增长,微博广告监控指标越来越多,我们的监控指标引擎承载的压力也越来越大。
那么,在这些复杂多变的流量洪峰下,如何更灵活快速地去查看我们的系统指标性能呢?
这里假设您已经拥有了一个高可用的分布式 ClickHouse 集群,下面我将通过三个业务监控需求用例,来为您介绍在微博广告业务百亿流量下,我们如何通过 ClickHouse 的数据抽样和物化视图功能,来快速灵活地可视化我们的监控指标。
二、性能指标 TP999
耗时是反馈我们系统性能的一个重要指标。以前我们会通过预聚合的方式来计算一个接口的平均耗时,这种方式会降低对监控指标引擎的查询压力,但是却容易掩盖我们系统的性能问题。
比如一个接口的耗时持续出现在 [ 0-10 ]ms 和 [ 90 -100 ]ms 两个区间,但是计算出来的平均值却是在 50ms 左右。我们以为系统是正常的,因而忽略去排查那些耗时在 [ 90-100 ]ms 请求。
所以现在我们开始将平均耗时修改成 TP999、TP99 这样的方式来计算我们的接口耗时。我们能更容易地跟踪我们系统的性能,但是却增加了我们监控指标引擎的查询压力。
我们需要把我们的每一条请求都储存在一张明细表中,好在 ClickHouse 的高性能读写和横向扩展能力,让我们依然可以很快地去查询接口的TP999耗时。ClickHouse 为何如此之快,这里就先不赘述了,后期,我会通过一篇文章来介绍。
同时我们还可以通过 ClickHouse 的抽样功能来辅助降低引擎查询压力。这里需要注意的是,只有在创建表结构时开启抽样查询功能,才能执行抽样查询 SQL 。
那么如何开启抽样查询功能呢,其实很简单,比如我们想以 datetime 维度进程抽样展示,只要在您的建表语句中包含 SAMPLE BY intHash64(datetime) ,同时,在您的主键中,也就是 ORDER BY 里面,必须包含抽样的字段。完成的建表语句如下:
CREATE TABLE default.ods_nginx_access_log
ON CLUSTER clickhouse
(
date Date,
datetime DateTime,
host String,
port String,
status String,
cost_time UInt32,
request_number UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/ods_nginx_access_log', '{replica}')
PARTITION BY date
ORDER BY (date, intHash64(datetime), host, port, status)
SAMPLE BY intHash64(datetime)
SETTINGS index_granularity = 8192;
ReplicatedAggregatingMergeTree 是多副本的聚合 MergeTree 引擎,从而保存数据的高可用性。
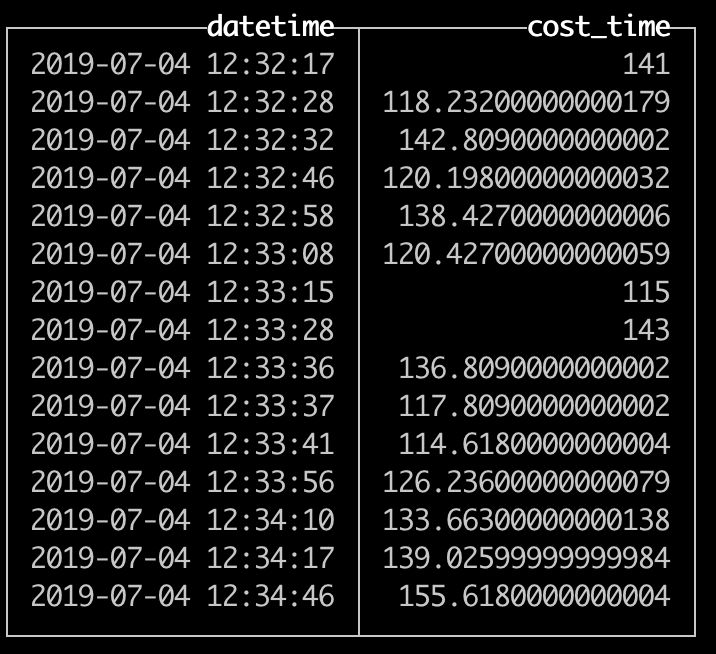
此时,我们就可以对该表的数据,以 datetime 字段进行抽样查询,比如,我们要抽样查询 10% 的数据,就可以在 SELECT 查询语句中加上 SAMPLE 0.1。完整的查询 SQL 如下:
SELECT
datetime,
quantile(0.999)(cost_time)
FROM default.ods_nginx_access_log
SAMPLE 0.1
GROUP BY datetime
ORDER BY datetime
SQL 在 ClickHouse 中执行结果如下:
三、基于物化视图和聚合表引擎的多维度查询
在上面的例子中,由于 TP999 的特殊要求,我们只能基于明细表来查询,虽然做了抽样,但是查询的数据依然可能很大。那么在多维度查询的场景下,我们可以通过物化视图和聚合表引擎,按照指定的时间粒度和维度指标预聚合我们的查询指标,从而降低查询的压力。
聚合表引擎 AggregatingMergeTree 会根据我们指定的时间粒度和维度指标预聚合我们的监控数据,再通过与物化视图的结合,实时的将明细表中的数据聚合到一张物化视图表中,而不是等我们查询时才聚合生成的数据。因此,在查询性能上会带来很大的提升,降低查询对监控数据引擎的压力。
那么,在多维度查询前,我们需要基于我们指定的时间粒度和维度指标创建一张物化视图聚合表。这里我们创建一张以 host,port,status 三个维度聚合统计每秒钟请求数的物化视图聚合表,以 datetime 作为抽样字段。建表语句如下:
CREATE MATERIALIZED VIEW default.dw_nginx_access_log_1s \
ON CLUSTER clickhouse \
ENGINE = ReplicatedAggregatingMergeTree('/clickhouse/tables/{layer}-{shard}/dw_nginx_access_log_1s', '{replica}') \
PARTITION BY date \
ORDER BY (date, intHash64(datetime), host, port, status) \
SAMPLE BY intHash64(datetime)
SETTINGS index_granularity = 8192 \
AS SELECT \
date, \
datetime, \
host, \
port, \
status, \
sumState(request_number) AS request_number \
FROM default.ods_nginx_access_log \
GROUP BY date, datetime, host, port, status;
sumState 是一个聚合函数,主要用于 AggregatingMergeTree 表引擎中,用于在聚合过程中保存指定字段的聚合状态。
此时,这张物化视图聚合表 dw_nginx_access_log_1s 就在实时聚合明细表 ods_nginx_access_log 中的数据了,我们可以通过下面这条 SQL 查询监控数据:
SELECT
datetime,
host,
port,
status,
sumMerge(request_number) AS request_number
FROM default.dw_nginx_access_log_1s
GROUP BY
datetime,
host,
port,
status
ORDER BY datetime
sumMerge 聚合函数用于合并 sumState 聚合状态,完成聚合并返回聚合结果。
当我们需要在 Grafana 中展示我们的监控指标时,我们就可以根据上面的查询 SQL 稍加修改,来展示我们的指标。比如,我们想在 Grafana 上展示各个主机的 QPS,就可以通过下面的 SQL 来完成:
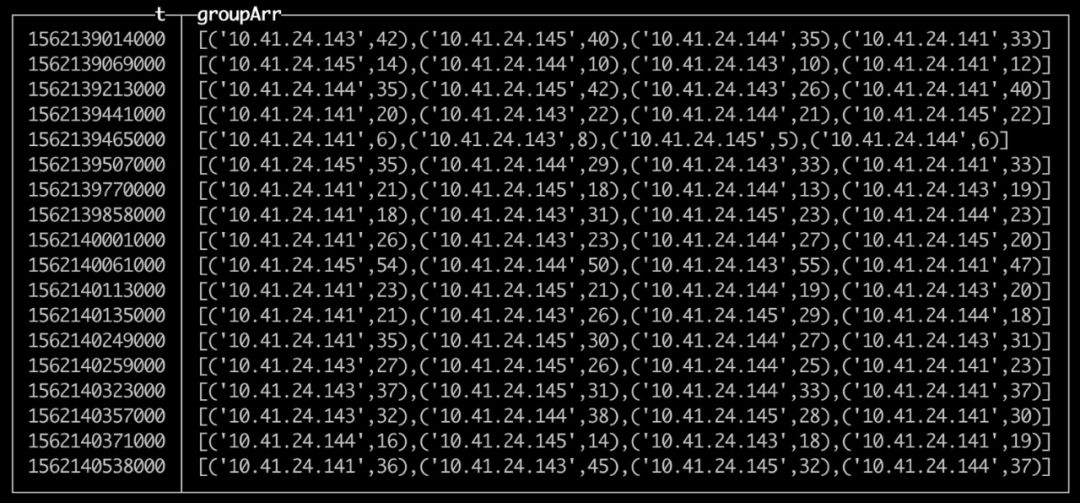
SELECT
(intDiv(toUInt32(datetime), $interval) * $interval) * 1000 AS t,
groupArray((host,request_number)) AS groupArr
FROM
(
SELECT
datetime,
host,
sumMerge(request_number) AS request_number
FROM default.dw_nginx_access_log_1s
GROUP BY
datetime,
host
)
GROUP BY t
ORDER BY t
SQL 在 ClickHouse 中执行结果如下:
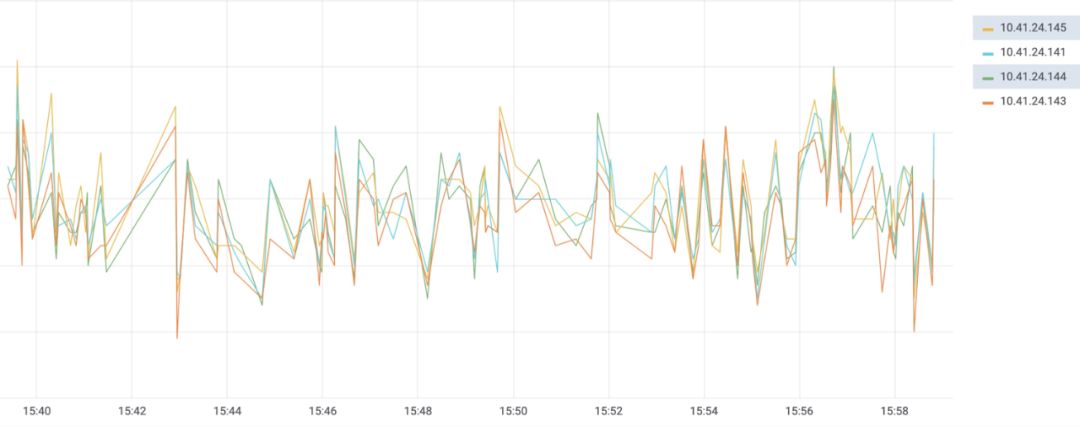
分主机 QPS 监控图效果如下:
四、请求量的日环比和周同比监控
在微博广告的监控需求中,经常需要对一些指标进行历史走势对比监控,如下图所示:
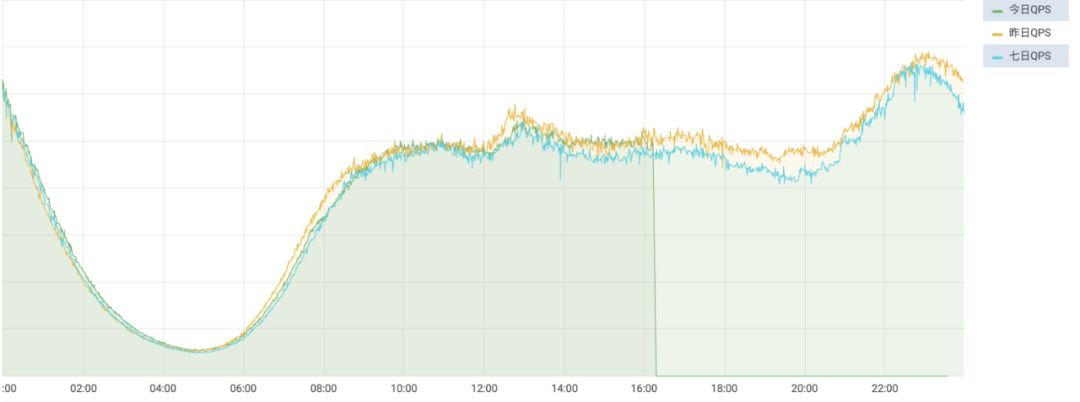
ClickHouse 对于这种展示需求也能够轻松实现,具体 SQL 如下:
SELECT
(intDiv(toUInt32(datetime), $interval) * $interval) * 1000 AS t,
sumMerge(request_number) AS "今日QPS"
FROM default.dw_nginx_access_log_1s
GROUP BY t,
ORDER BY t
SELECT
t + 86400000,
count() AS "昨天QPS"
FROM
(
SELECT
(intDiv(toUInt32(datetime), $interval) * $interval) * 1000 AS t,
count()
FROM default.dw_nginx_access_log_1s
WHERE (datetime >= toDateTime($from - 86400)) AND (datetime < toDateTime($to - 86400))
GROUP BY t
ORDER BY t
)
SELECT
t + 86400000 * 7,
count() AS "七日QPS"
FROM
(
SELECT
(intDiv(toUInt32(datetime), $interval) * $interval) * 1000 AS t,
count()
FROM default.dw_nginx_access_log_1s
WHERE (datetime >= toDateTime($from - 86400 * 7)) AND (datetime < toDateTime($to - 86400 * 7))
GROUP BY t
ORDER BY t
)
五、总结
ClickHouse 优秀的读写处理性能,丰富强大的函数支持,以及灵活的 SQL 查询,支撑了微博广告监控系统的百亿流量请求和复杂业务需求。
它不仅集成了 Graphite、Druid、ElasticSearch 等时序数据库、分析引擎的优势,同时也扩展了它们的不足,拓展了我们监控系统能力的广度和深度,给我们监控运维带来了极大的便利。
当我们面对一个复杂的系统,我们依然可以从容的展示系统内部各个环节的性能和业务指标。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721