
作者介绍
许昌永,高级DBA,微软SQL Server MVP,十年以上SQL Server使用经验。曾就职于腾讯公司,从事了六年游戏行业SQL Server数据库开发和管理。目前就职于跨境电商DX.COM三年多,负责公司SQL Server和MongoDB的数据库架构设计、高可用部署、运维管理和性能优化等工作。翻译出版了书籍《PowerShellV3——SQL Server 2012数据库自动化运维权威指南》
在SQL Server的日常管理中,让SQL Server高效运行,且性能良好,是DBA需要做的事。DBA需要了解数据库的日常运行情况,对性能进行分析和调优,需要对线上环境部署监控。那我们都需要监控哪些方面呢?
1. SQL Server服务器的CPU、内存、IO、网络流量、缓存等资源性能怎么样,各个相关服务如SQL Server服务、SQL Server代理服务等是否正常运行,这些一般使用开源的监控软件Zabbix来设置告警,当然针对数据库服务器的特性,添加一些SQL Server数据库引擎的性能计数器进行收集。
2. SQL Server各种日志会记录有用的信息。因此可以监控SQL Server错误日志、SQL Server代理日志等。
3. SQL Server数据库避免不了一些异常状态,比如错误的脚本导致的异常,空间不够,磁盘挂了,复制失败了等。这里我先提提SQL Server事件。这个意味着SQL Server发生特定错误产生的事件,每个事件都有对应的数据库、严重级别、错误号、错误文本。可以针对一些极其严重的错误如823、824、825、832、855、856等进行特定错误监控,还可以针对严重的错误级别进行监控,如错误等级从19到25。
4. 生产环境都会部署各种高可用技术,无论是镜像、日志传送、复制还是Alwayson,都需要部署相应的监控,注意一个是要监控是否正常运行,再就是性能怎么样,设置一定的告警阈值。
上面的监控基本能满足基本生产需求,那么我们还要监控哪些方面呢?
5. SQL Server的连接超时、执行超时、死锁。
6. SQL Server活动进程、慢查询、阻塞。
7. 等待统计对于分析SQL Server引擎性能瓶颈非常关键,帮助诊断SQL Server以及特定查询和批处理的性能问题。
8.环形缓冲区包含了最小的系统输出,记录了大量的XML格式信息,用于帮助分析状态的变化提供更好的思路。可以监控连接、异常、调度、安全、内存等。
9. 审核SQL Server数据库引擎实例或单独的数据库,跟踪和记录数据库引擎中发生的事件。
10. 可以结合Powershell实现自动化监控部署、结合SSRS实现平台化展示。再进一步深入到Web端的部署、运维、监控、性能分析等一体化。
监控是SQL Server数据库引擎的一大主题,了解整个数据库引擎的监控架构,并做好全面的监控,是很必要的。我们就拿最常见的死锁来谈谈SQL Server的监控。
SQL Server中如何监控死锁
所谓死锁: 是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
由于资源占用是互斥的,当某个进程提出申请资源后,使得有关进程在无外力协助下,永远分配不到必需的资源而无法继续运行,这就产生了一种特殊现象:死锁。
在SQL Server中为了阻止死锁大量充斥在系统中,我们有一个死锁监控的后端线程来帮助解决死锁。
如果我们查看sys.dm_os_waiting_tasks,我们可以发现一个系统任务一直处于等待状态:REQUEST_FOR_DEADLOCK_SEARCH。该线程每五秒钟被唤醒,来查看是否有死锁。如果发现死锁,它将结束一个会话。它会杀掉两个会话中的一个,让另一个会话拥有需要的所有资源。
SQL Server会判断,要确保杀掉的是最容易回滚的会话。因为如果SQL Server杀掉一个事务,它所做的任何工作必须回滚到数据库的同步状态。它由LOG USED的值来决定。
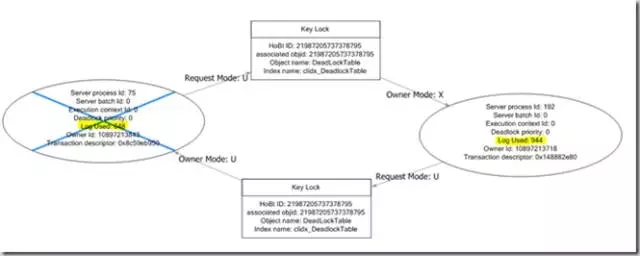
我们可以看到上例图杀掉了会话75而不是192,因为会话75使用了648字节日志而会话192使用了944字节。
后端线程每五分钟唤醒检查死锁。如果发现,它遵照上例的流程去决定如何解决。然而,当它第一次唤醒,立马唤醒第二次,确保不是一个嵌套死锁。如果有,会被杀掉,然后返回睡眠状态。下一次唤醒在4.90秒之后(预估唤醒时间花费10毫秒)。每次递减100毫秒,将每秒唤醒10次处理死锁。
方法一:
Windows性能监控器(Performance Monitor)
Object: SQLServer:Locks
Counter: Number of Deadlocks/sec
Instance: _Total
下面的查询提供了自从上次重启以来在本服务器上发生的所有死锁:
SELECT cntr_value AS NumOfDeadLocks
FROM sys.dm_os_performance_counters
WHERE object_name = 'SQLServer:Locks'
AND counter_name = 'Number of Deadlocks/sec'
AND instance_name = '_Total'
方法二:
跟踪标识(Trace Flags)1204和1222
Trace Flag 1204至少从SQL Server 2000开始存在。Trace Flag 1222从SQL Server 2005被包含进来。两者的死锁信息被记录到SQL Server错误日志(ERRORLOG)。
方法三:
SQL Server Profiler和服务端的SQL Trace
Trace Event Class: Locks Event Name: Deadlock Graph
像上面示例一样给出一个XML图示。非常容易阅读并找出当前正在进行什么动作。
方法四:
扩展事件(Extended Events)
自从SQL Server 2008开始的监控新方式。扩展事件最终会取代SQL Server Profiler(注意:SQL Server Profiler在被放弃属性列表中)。和SQL Server Profiler一样它提供了相同的XML图示,并且在性能影响上更轻量级。
方法五:
System Health
一个新的默认跟踪,但它不像SQL Server默认跟踪(Default Trace)那样有有限数量的跟踪信息且不能修改。我们可以修改system health的定义,它内置于扩展事件中。不像默认跟踪,system health可以跟踪到刚才已经发生过的死锁信息。我们可以从system health获取这些信息用来分析而不用部署我们自己的扩展事件监控。
使用扩展事件跟踪监控死锁
我们通过SQL Server 2012图形界面来部署一个扩展事件跟踪会话。然后可以生成SQL脚本,在2008或2008 R2版本下运行类似的跟踪。
步骤1:
通过“Object Explorer”连接到实例,展开“Management”、“Extended Events”、“Sessions”。
步骤2:
右键点击“Sessions”,创建一个新的会话向导。
步骤3:
输入会话名称“Deadlock_Monitor”,点击下一步。
步骤4:
选择不使用模板(像SQL Server Profiler模板一样,预设了一些默认选项一起启动,但没有一个满足我们需求的模板),点击下一步。
步骤5:
选择要捕获的事件,在“Event library”输入deadlock,可看到如下图所示:
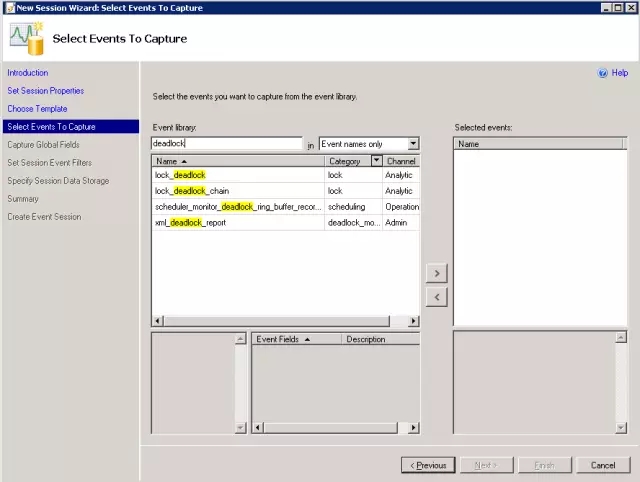
步骤6:
选择“xml_deadlock_report”,添加到右侧选择的事件列表中。再单击下一步。
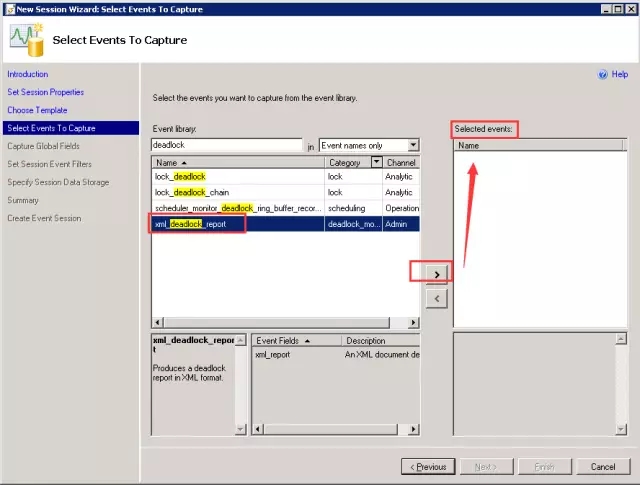
步骤7:
选择要捕获的列,这里我们选择下一步。
步骤8:
定义过滤条件,这里我们忽略这个设置,点击下一步。
步骤9:
选择保存数据到文件,设置文件路径和最大值等。点击下一步。
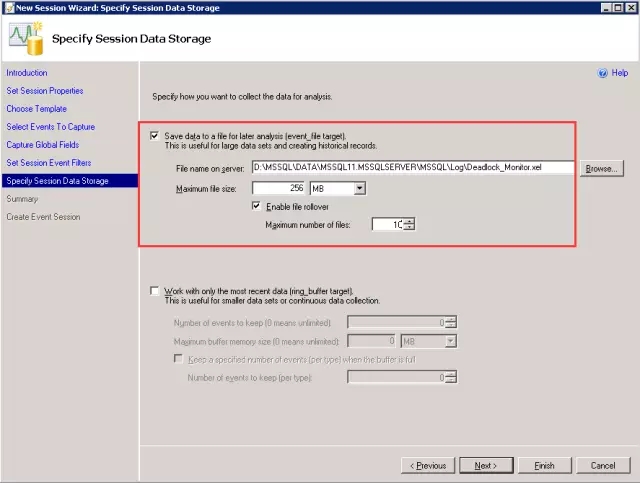
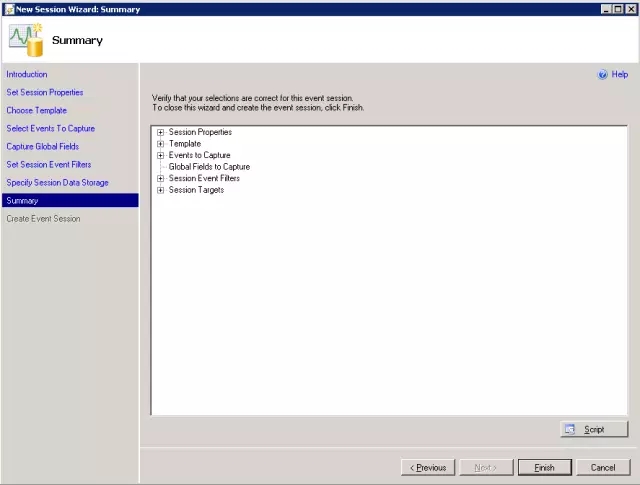
步骤10:
检查所有的配置,点击完成来安装和启用会话。
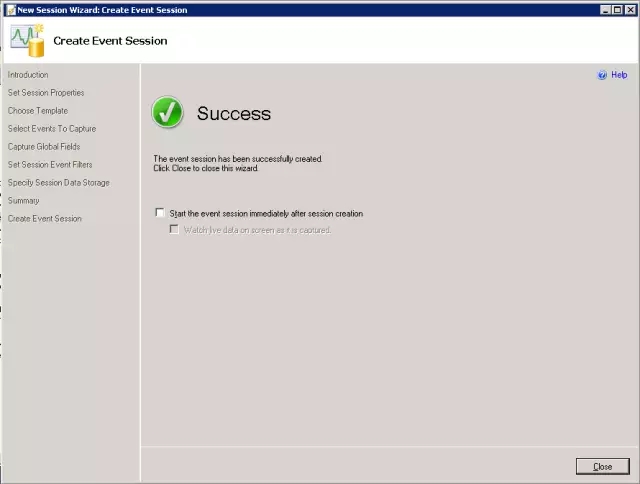
步骤11:
现在我们可以启动捕获,并查看活动数据。
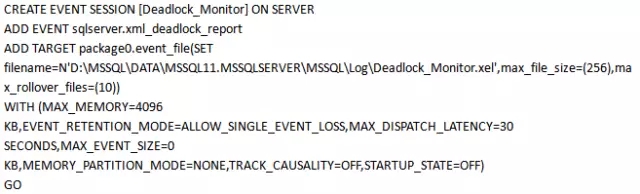
步骤12:
在刚才创建会话“Deadlock_Monitor”上右键点击生成脚本。
步骤13:
在会话“Deadlock_Monitor”上右键选择启动会话。
步骤14:
分别在两个查询窗口执行如下语句。

步骤15:
在“Deadlock_Monitor”上的package0.event_file上右键选择“View Target Data…”。选择对应timestamp的死锁条目,在Details的xml_report值里显示的就是死锁的XML文件,可双击打开。点击Deadlock即可看到死锁的图形化展示。
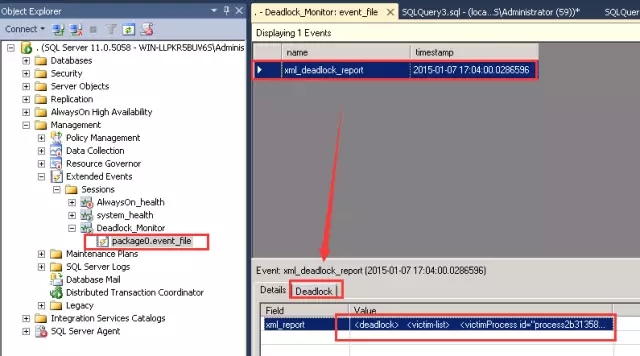
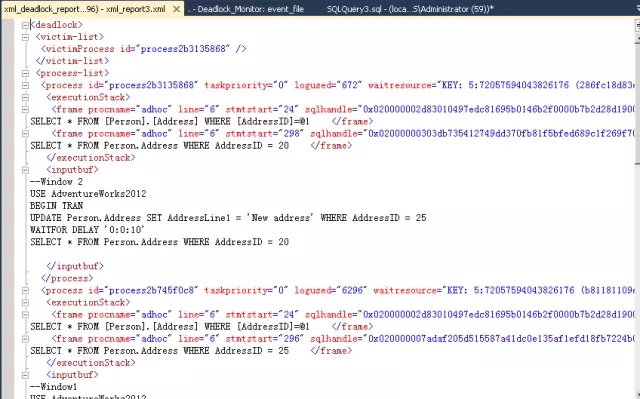

深入进阶
死锁详细信息还有几个步骤可用来配置扩展事件来监控死锁。
我想去讨论另外两个事件来捕获到分析死锁更详细的信息。
Lock: Deadlock事件类
这个事件类可以用来验证死锁牺牲品。这个事件说明什么时候请求需要一个锁,但被取消作为一个死锁牺牲品。
Lock: Deadlock chain事件类
这个事件类用于监控死锁状态。当有一个死锁时该事件被触发。通过在实例级别监控这个事件,我们能够识别那些对象在死锁中,我们是否在应用程序中有死锁导致的性能问题。
步骤1:
在之前的“Deadlock_Monitor”会话上右键选择“Properties”。选择“Events”页,将lock_deadlock和lock_deadlock_chain事件类添加到右侧已选择事件列表。
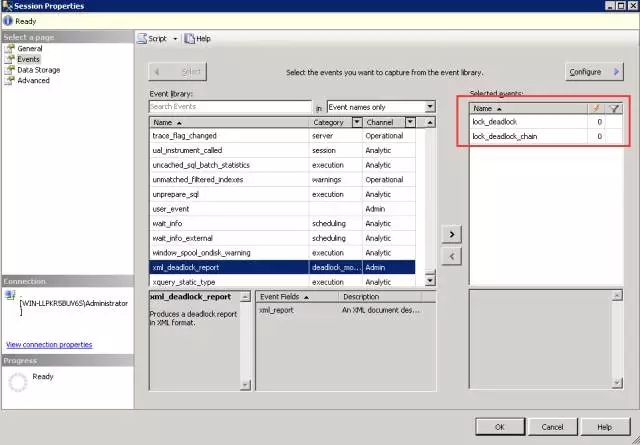
步骤2:
运行之前的死锁示例。
步骤3:
在“Deadlock_Monitor”上的package0.event_file上右键选择“View Target Data…”。选择对应timestamp的死锁条目。
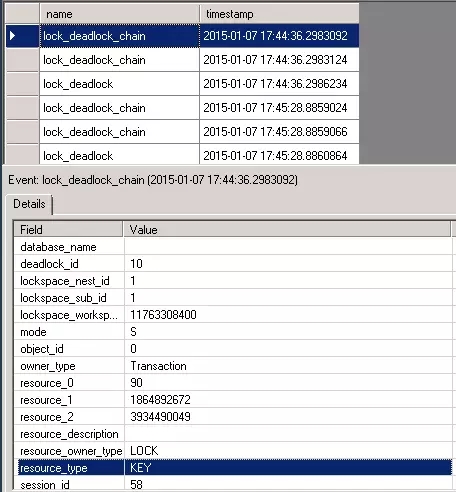
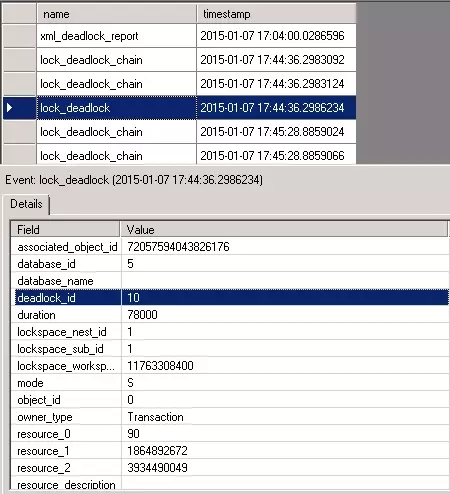
如果有用户反馈说他们在应用程序的错误日志里发现了输出了死锁信息,而且是在深夜。我们就可以知道怎么监控和获取死锁数据了。
使用system_health
默认跟踪会话监控死锁
自SQL Server 2008以后,提供了扩展事件(Extended Events)来跟踪系统分析定位问题。默认的system_health会话一直在运行,可以帮助你更快的定位问题。
运行如下脚本可以看到system_health扩展事件会话:
即便是你没有启动任何扩展事件会话,这个查询也会返回一行system_health会话。
SQL Server 2012版本之前,并不提供管理扩展事件会话的图形界面,你可以从这里下载SQL Server 2008 Extended Events SSMS Addin插件:http://extendedeventmanager.codeplex.com/
安装好后,可以按如图方式找到扩展事件管理界面:
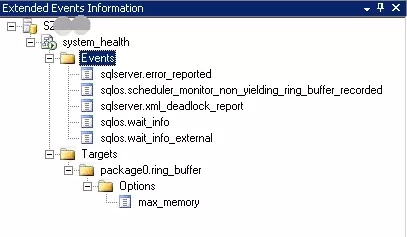
而在SQL Server 2012版本中,则通过如图方式可以找到该界面:
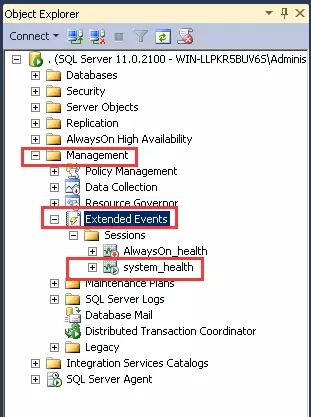
我们右键点击“system_health”,生成脚本,我们可以看到该会话的内容。你也可以在SQL Server的安装目录:C:\Program Files\Microsoft SQL Server\MSSQL11.
从定义可以看到,会话的输出包含callstack、sessionID、TSQL和TSQL Call Stack且当安全等级大于20或者错误号为17803等。它们与内存压力相关、Non-yielding scheduler问题、死锁和一些类型的等待。
会话输出被捕获到遵从FIFO规则的ring_buffer中,ring_buffer是一个内存使用者,它以二进制格式存储捕获数据。当事件会话启用的时候,数据即可被捕获。当停止会话的时候,分配给ring_buffer的内存被释放,且数据消失。注意:对于SQL Server 2012之前,system_health的目标只有ring_buffer,从SQL Server 2012开始,增加了event_file的输出。
你可以通过关联sys.dm_xe_session_targets和sys.dm_xe_sessions视图来查看ring_buffer或event_file的内容,并转换二进制数据为XML格式。
SELECT name, target_name, CAST(target_data AS XML) target_data
FROM sys.dm_xe_sessions s
INNER JOIN sys.dm_xe_session_targets t
ON s.address = t.event_session_address
WHERE s.name = 'system_health'
GO
注意:event_file的输出是文件的存储路径,而ring_buffer的输出是捕获到的数据。
在ring_buffer中,每一个事件元素都有一个数据子集和一个动作子集。这些动作是在会话的定义中。数据元素包含了每个事件的数据类型列的所有值。这些列可通过sys.dm_xe_object_columns视图输出。让我们解析XML格式以表格格式查看内容。因为每个事件返回数据列的不同集合。下面给一个error_reported事件的例子。
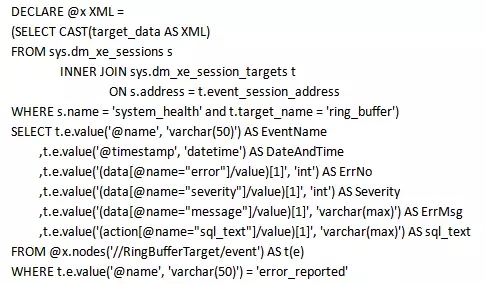

对于system_health最有帮助的用途之一是跟踪死锁。对于目标ringbuffer,存储多少数据依赖于被监控机器上的该目标的容量,以及产生最大数量的设置相关,这些将在每个会话的定义中。你可以在system_health会话的输出中找到过去的死锁记录。
所有查询都会在system_health输出中,可以通过运行下面的代码获得一个死锁报表。

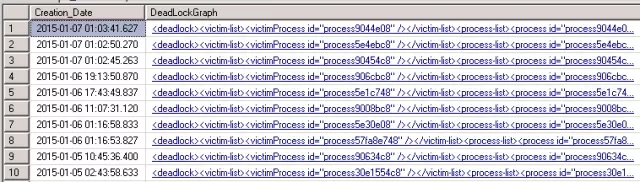


查看process-list的inputbuf子元素,可以看到导致死锁的代码片段,process-list显示所有死锁参与者的进程ID。process元素包含spid、数据库id、登录名、隔离级别、客户端应用程序名。Resource-list元素包含在死锁中的资源。查看owner-list和waiter-list元素可以看到这两个进程如何互相阻塞。
尝试将该XML的输出保存为XDL文档,用SSMS打开异常。目前有两个选择可以以图形方式打开死锁图表:SQL Sentry Plan Explorer Pro 和 SQL Server 2012 Management Studio,详见:https://www.sqlskills.com/blogs/jonathan/graphically-viewing-extended-events-deadlock-graphs/








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721