

前言
关系型数据库发展至今,细节上以做足文章,在寻求自身突破发展的过程中,内存与分布式数据库是当下最流行的主题,这与性能及扩展性在大数据时代的需求交相辉映。
SQL Server作为传统的数据库也在最新发布版本SQL Server 2014中提供了新利器 SQL Server In-Memory OLTP(Hekaton),使得其在OLTP系统中的性能有了几十倍甚至上百倍的性能提升,本篇文章为大家探究一二。
大数据时代的数据如何组织应用?这恐怕众口不一。但不可否认,关系型数据依旧是当下世界最有效的应用方式。作为应用技术,也必将伴随着应用的需求而不断演化。
信息爆炸对信息处理提出了更为严苛的需求,单从传统的OLTP系统来看,性能和扩展性便是应用者最为关注的方面。假如应用者告诉你我需要当下数据库访问量100倍的计算资源,单纯硬件?显然新的技术应用呼之而出。
传统关系型数据库自诞生起自身不断完善的同时也伴随着硬件的飞速发展,性能提升上伴随处理器神奇的摩尔定律,TPC-C,TPC-E等指标不断提升,而随着今年来处理器物理工艺接近极限,CPU的主频速度几乎不再提升,这时计算机朝着多核方向进展,同时内存成本也在线性降低,不再如此昂贵,目前内存的成本已经低于10$/GB。
而固态硬盘(SSD)的广泛应用也使得传统数据库在性能上有更多的延伸。面对这些新的硬件环境,传统的关系型数据库自然也有其设计之初不可避免的自身性能瓶颈。
SQL Server 2014的传统引擎中引入缓冲池扩展(Buffer Pool Extension)功能,利用SSD的高IOPS作为缓冲池的有利延伸,构成了热,活,冷三层数据体系,有效缓解磁盘的压力。
我们可以把更多的数据放入内存,SSD中,但即便如此数据库的性能还是被自身的一些架构和处理方式所约束着。
就着前面的假设,我们要把事务处理能力提升100倍。假设我们现在的处理能力是100 TPS,而这时每个事务所以得平均CPU指令为100万个,以此提升10倍1000 TPS,每个事务的CPU指令就需降为10万个,而再提升10倍10000TPS每个事务的CPU指令就需降为1万个,这在现有的数据库系统中是不可能实现的,所以我们依旧需要新的处理方式。
一、传统数据库引擎面临的问题
有的朋友可能会说把所有数据都放入内存中就是内存数据库,就不存在短板了,但即便如此我们仍面临如下主要问题:
1.保护内存中的数据结构而采用的闩锁(latch)引起的热点 (hot spots)问题。
2.使用锁机制控制多版本并发带来的阻塞等问题。
3.使用解释型(interpretation)语言的执行计划的执行效率问题。
我们简单看下上述问题的由来
1.假设我有一个查询Q1需要访问一个数据页 页号7,此时数据页不在BufferPool(BP)中,为此系统为其分配了内存架构,并去磁盘取相关数据页置入BP中此过程正常大概10-20ms,而此时恰好另一个查询Q2需访问数据页号7,由于BP中已经存在应该页架构,如果此时允许Q2读取,则Q2将会脏读。
因此引入闩锁,当Q1去磁盘读取数据时BP中的相应架构被闩锁保护,Q2读相应的页时将被阻塞,知道Q1完成相应操作并释放闩锁,如下图1-1所示:
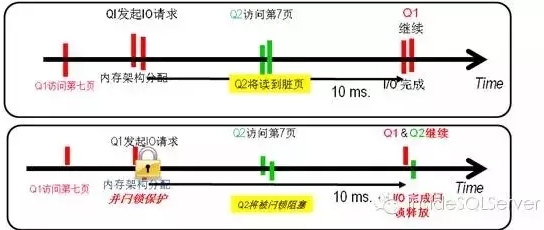
图1-1
现在有数据库系统中为保证多线程下的共享数据一致性,内存任何数据结构都需被闩锁保护。而当大量并发进程同时访问一个数据页(结构)就造成了热点问题。消耗了大量CPU的同时影响了并发吞吐。
2.假设有如下两个操作,都对数据库中的某个值进行修改:
A=1000
Q1:A = A + 100Q2: A = A + 500
在数据库中的操作为
Q1:Read A,A=A+100, Write A
Q2:Read A,A=A+500, Write A
如果是串行先后执行,则没有问题,但如果同时执行则可以出现数据的不一致情形。
Q1,Q2同时读取了A的原始值后,进行修改,则数据不一致如图1-2:
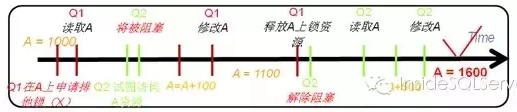
图1-2
为了解决此问题,已故的业界大神,图灵奖的获得者JimGray提出了两阶段锁概念 (Two-Phase Locking),合理地解决了并发一致性问题,并被绝大多数数据库系统应用并改进(如SQL Server中数据不同粒度下并发兼容情形引入的意向锁)。
本例中当Q1读取A时,对A加排他锁,当Q2试图读取时就会被阻塞,需等待Q1的事务完成后释放锁资源后才能继续读取。如图1-3:
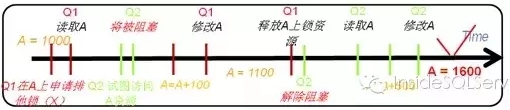
图1-3
但也正因为锁的引入,使得事务间可能出现相互阻塞,并且需要特定的进行管理锁资源,且需对死锁等问题即时检测,而这些问题自然地会影响并发性能。
3.熟悉SQL Server的人都知道一条语句在SQL Server中执行,现有进行绑定,语义分析,基于成本的优化等一些列过程然后生成相应的解释性语言执行计划,而引擎在执行相应的执行计划时会调用相应的数据库函数,运行每一个运算符,如果数据在硬盘上则会去硬盘上取数据……
这些情形使得执行解释性语言时高时间消耗的同时也打断CPU流水,使得CPU的效率无法充分发挥,而如果数据均在内存中,则可以采用更高效的方式处理。而绝大多数关系型数据库系统的执行计划均为解释性语言。
面对这些问题,巨头数据库厂商们都提供了相应的内存数据库解决方案,如Oracle的Timesten,还有最新图灵奖获得者Michael Stonebraker教授的研究H-store演化出的商业产品VoltDB等。
而微软的SQL Server 2014也推出了内存数据库SQL Server In-Memory OLTP(开发代号Hekaton),接下来我们就简要的看下Hekaton如何应对上面的问题,使得性能得到新的升华。
二、SQL Server Hekaton的应对方式
SQL Server Hekaton是一个基于内存优化的高性能的OLTP数据库引擎,且数据是可持久化的,它完全集成于SQL Server内(可与传统引擎,基于列存储引擎混合透明使用如图2-1),且是基于现代多核CPU架构设计。如图2-1:
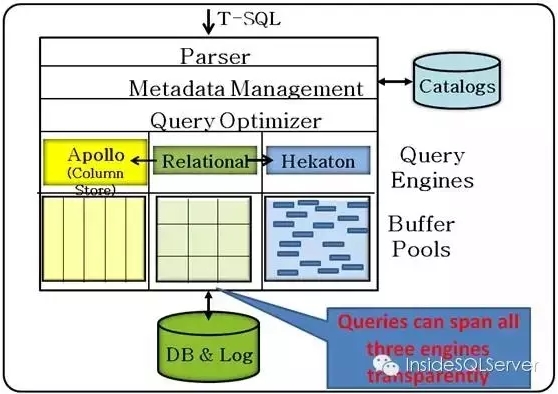
图2-1
应对上述三点性能瓶颈,热点上Hekaton采用”Bw-tree”数据结构实现Latch-free,并发锁上采用乐观并发中多版本时间戳数据行控制实现无锁事务,解释性语言执行效率采用截执行计划编译为机器代码(DLL)提升CPU效率。
下面针对这三点来简要说明下。
Hekaton中的数据页大小是弹性的,以便于增量更新Delta update,因为现有传统的update in place会使得现有的CPU Cache失效,在多核架构下会使得性能受限。数据页在内存中通过映射表管理,将每个数据页的逻辑ID与物理地址一一映射。如图2-2:
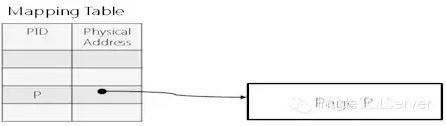
图2-2
在对数据进行更新时采用Compareand Swap(CAS)实现无锁(Latch free)操作
CAS:通过比对物理地址的值与携带值是否匹配,匹配则可操作,不匹配则拒绝操作。
如某个进程在携带的地址M的值为20,匹配地址M的实际值,如果为20则可以修改,否则拒绝如图2-3:

图2-3
在对数据页进行增量更新时每次操作均会在数据上生成一个新的增量地址作为数据页的访问入口,并采用CAS完成映射表中(mapping table)物理新地址的映射(delta address),并对针对同一数据页可能出现的同时更新进行仲裁,此时胜出者将进行更新,而失败者可以进行重试,遗憾的是目前SQL Server只会对失败操作抛出错误信息,需要我们自己捕捉错误信息并重试,具体可参考联机文档。
具体如图2-4所示:
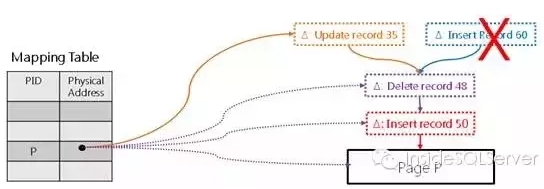
图2-4
这样的操作方式下,当更新链过长时访问数据会造成时间复杂度提升从而影响性能,SQL server会在合适的情形下进行整理,生成新的数据页,并将物理地址指向新的数据页,而老的数据页链表将会作为垃圾回收释放内存。
如图2-5:
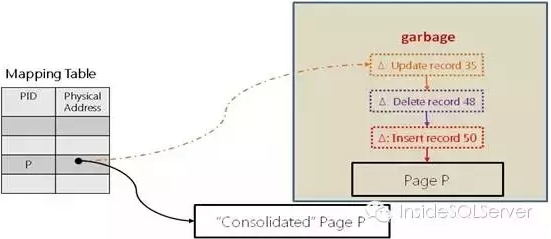
图2-5
由于数据页是弹性的,所以可能造成数据页过大或是过程,Hekaton中会在其认为合适的情形下进行页分裂或是合并。限于篇幅这里就不在详细叙述了,在实现Latch-free中所有内存中的操作都是通过一个或多个原子操作完成。感兴趣的朋友可以参考微软的相关文献。
有的朋友可能会说闩锁本身是保护内存结构的轻量级锁,况且不同类型的闩锁可能兼容,Latch-free对性能帮助能有多大呢?
实际SQL Server在访问内存中数据时,闩锁本身用作控制数据访问时成本很高,为此会在数据上加自旋锁(Spin lock)供线程探测数据是否可以访问,Spin lock实现即一个Bit位(0或1),线程会一直探测内存中的这个Bit位以试图获得自旋锁,如果可以访问则访问,否则自旋,如果几千次的探测仍无法访问则停下”休息”这个称作一次碰撞。
但是在自旋的过程CPU负荷状态,因此也就造成CPU资源白白浪费。生产中我们可能看到CPU高启,而并发却上不去,访问变慢,其中的一个原因就是大量进程访问热点数据下大量自旋锁征用使得性能受限。
而在Hekaton中无闩锁的情况下就不存在这样问题,单从这个角度来看随着线程的增加性能也是线性放大。当然除了Latch-free,其他的两个方面Hekaton同样表现出色。
前文中叙述可知,关系型数据库中事务是靠锁来保证多版本并发控制的,由此带来的阻塞死锁等问题相信所有的DBA都印象深刻。而Hekaton中采用乐观并发下多版本数据加时间戳的形式实现。
下面来简要解下。
Hekaton中将一个事务分为三个阶段,正常事务处理步骤用于我们的数据操作DML则创建新的版本行。验证提交阶段验证这个事务是否可以安全提交(根据版本数据)。提交处理阶段用于写日志,并将新的版本行数据对其它事务可见。
如图2-6:
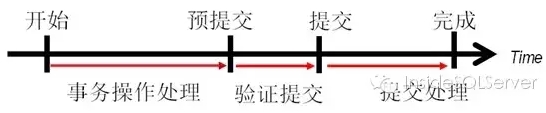
图2-6
我们通过一个实例简要说明下:
事务过程采用Timestamps(时间戳(全局时钟))标记事务和行版本,每个事务开始时赋予开始时间戳Begin_TS,用于读取正确的行版本(数据行同样均具有时间戳),行版本数据结束时间戳End_TS一般为正无穷(+∞),当进行数据更新时创建新的版本行,并将旧的版本行End_TS修改为事务ID Xb(此处非时间戳),新的版本行的Begin_TS同样标记为事务ID (Xb)。然后获取事务的End_TS (唯一),确认可提交后,提交事务,并将新旧版本的事务ID(Xb)替换成获取的End_TS。至此完成一次操作。未涉及任何锁,闩锁,阻塞。
如图2-7:
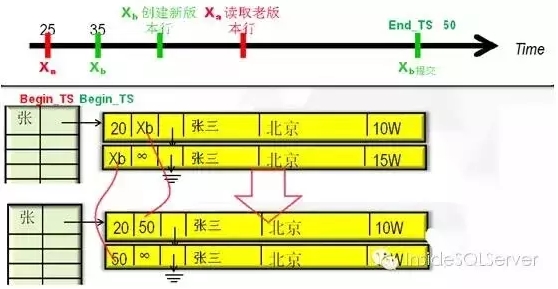
图2-7
有的同学看到上图可能回想,这样Xa读取的版本行是正确的吗?他为什么不能读到Xb的新行数据。我们来简单分析下。
Xa开始时分配的时间戳为25,Xb为35,这就意味着Xb的结束时间戳一定大于35此时Xa读取数据,时间戳范围应为Begin_TS-20,End_TS-+∞,而Xa的Begin_TS小于Xb的Begin_TS,所以读取正确如图2-8:
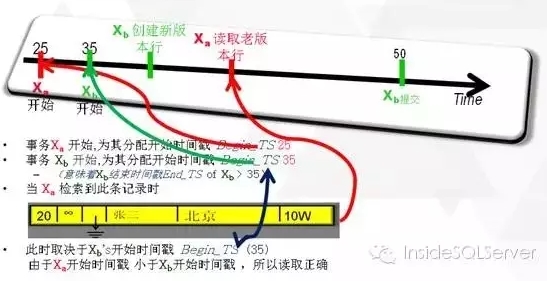
图2-8
实际上Hekaton中规定 查询的可见值区间必须覆盖此查询的开始时间戳比如一个查询事务的开始时间戳为30,他可见的行版本可以包括10至+∞,20至150,但不能看到40至+∞。如图2-9:
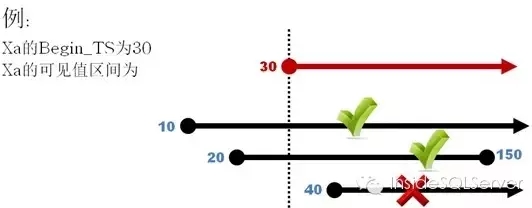
图2-9
有的同学可能会想,随着访问,DML的增加,会累积大量的无用数据占用内存,实际上根据查询自身的事务时间戳,如上当最古老的事务开始时间戳大于等于50时,旧版本的数据就可以安全的清除释放内存了。清除工作可以使多线程并行执行,对新能影响很小。
从图2-6中可以看到,并不是每个事务都可以安全提交的,在验证阶段,Hekaton会根据用户设定的隔离级别进行验证。
Hekaton为乐观并发,提供三种隔离级别的支持分别为快照隔离级别(Snapshot Isolation),可重复读隔离级别(RepeatableReads Isolation)及序列化隔离级别(Serializable),这与传统的关系型数据类似,Snapshot中是无需验证的,而可重复则需在提交前再次验证与事务开始时的数据是否一致,如一致则可提交,否则不可提交。
而序列化中顾名思义读取的区间数据都需一致,否则失败。有同学可能会想序列化中将匹配多少数据啊,成本是不是太高了,别忘了这是在内存中,依然比传统的序列化成本要低很多。
熟悉乐观级别的同学都知道,传统的乐观并发级别下回滚成本是非常高的,而Hekaton中采用验证的方式有效的规避了这项成本。提交就是写日志记录变化,并将数据行中事务ID替换成获取的时间戳,对其他事务可见。
当然提高写日志,我们都知道磁盘终究是瓶颈,为此Hekaton也有其特定的优化方式来缓解这个问题,限于篇幅这里就不在叙述。而且针对一些特定的场景我们可以选择只保留Schema而无需数据持久化(如游戏的场景数据等)。
最后,针对CPU执行效率将执行计划由解释性语言(Interpreted)替换为机器语言(Native)。
优化器可以说是关系型数据库最复杂的部分了,简单说下SQLServer优化器处理过程:一条语句交给优化器会进行绑定解析,生成解析树,然后进行语义分析生成逻辑执行计划,最后优化器再为逻辑执行计划基于成本生成物理的执行计划。
而Hekaton中,如果我们选择Native方式执行(将所执行语句通过存储过程特殊编译),在生成逻辑执行计划之后将会根据不同的算法,成本预估生成不同的物理执行计划,然后将物理执行计划转译成C语言代码再通过编译器将其编译成DLL即机器代码。如图2-10:
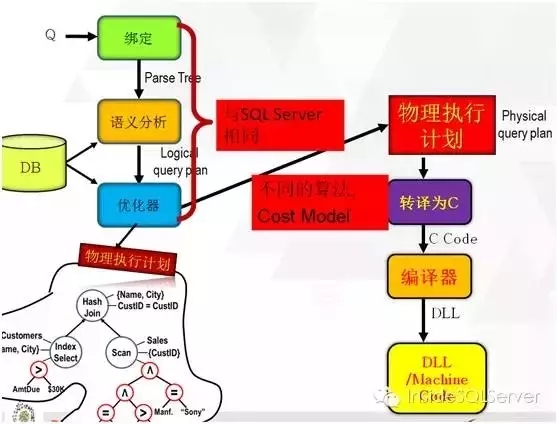
图2-10
曾经微博上有朋友问为什么Mysql重构优化器时为什么要将parsing,optimizing, execution三个模块分开而不是混在一起了,我想这里可能就找到答案了,一个优秀RDBMS它自身的健壮是多么重要。
在Native下,所有的执行都是“Goto”,直接读取数据,再也不用一个一个的function的调用,极大提升CPU的工作效率。有人可能会问这样每次都编译将是非常大的工作成本,实际上Hekaton将指定查询(存储过程)编译成DLL文件,只是在第一次将其载入内存就可以了。对于即席查询是不可以的。
Hekaton在机器代码下执行效率大幅提升,以下是微软给出的测试数据:
a.Interpreted与Native的对比,其中分为是否为内存优化表,查询单条数据所消耗的CPU指令。如图2-11:
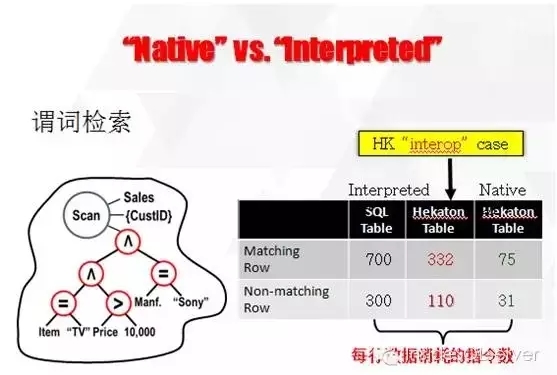
图2-11
b.随机查找1000万数据普通表与Hekaton内存优化表查询时间对比图2-12:
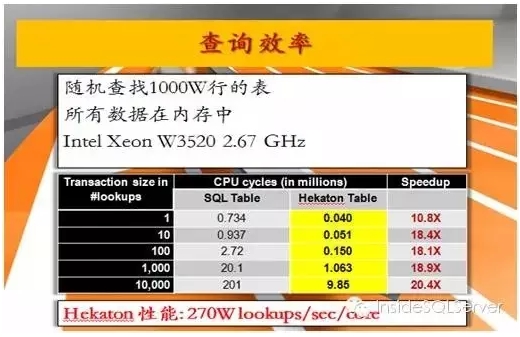
图2-12
c.普通表与Hekaton内存优化表内存中随机更新数据对比,此时不写日志如图2-13:
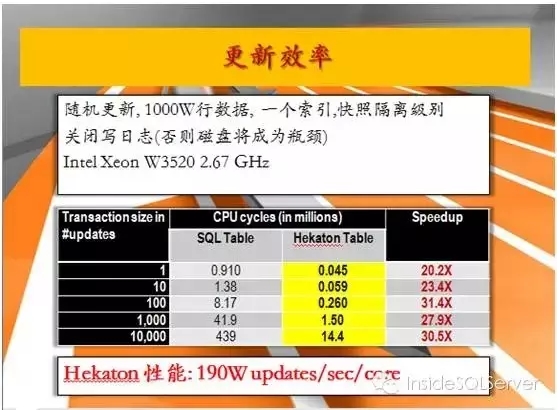
图2-13
三、Hekaton应用案例
Hekaton,古希腊语中表示百倍,虽然目前还未达到愿景,我想这个出色的团队一定能够做到。
SQL Server有了这个新利器,在应对性能问题上更加出色。在微软的官方网站上有大量案例,这里我们列举几个。
Bwin,欧洲最大的在线博彩公司,采用Hekaton后,线上每秒批处理由15000提升到250000。
EdgeNet,硅谷著名的数据服务商,采用Hekaton后,线上入库数据量由7450/s提升到126665/s均由近17倍的速度提升。如图3-1:

图3-1
而将易车的惠买车的访问量在Hekaton模拟运行时,各项性能指标都表现的很淡定。如图3-2:

图3-2
Hekaton不仅为我们解决了不少场景下的性能问题,我想面对特定场景中的一些棘手问题也有一定的帮助。比如电商热衷的秒杀/抢购。这里笔者就不在叙述业内朋友研究的排队论,批量提交等等办法。
实际上计算机在当下普遍应用都是模拟三维空间内的人为活动,试想下,抢购的过程终究有成功或是失败,就好像你在抢购热销产品时被身手矫健的大妈推到一边你没抢到一样,这不正好符合Hekaton中的事务机制?我们在设计网上产品活动的时候是否该想想模拟到现实中是什么样子的?对此,我认为我们需要的是可控,而不是控制。
四、结语
最后,这么多带给人惊喜振奋的数据库,它就完美无缺吗?当然不是。Hekaton的乐观并发级别限定使得其并不适合大量更新冲突的场景,其以空间换速度的设计要求会消耗大量内存,需要应用者合理规划设计……
请牢记“任何技术都是有缺陷的”,没有哪项技术/架构是完美无缺的,合适的场景选择合理的技术/架构才是我们的初衷。
文章来源“InsideSQLServer”订阅号,经平台及作者同意由DBA+社群转发。
全球敏捷运维峰会【杭州站】

2016 年4月16日,与你相约杭州,来一场敏捷与运维的美丽邂逅!DBA+社群联合三墩IT人开启全球敏捷运维峰会第一站:杭州站!峰会力邀来自互联网与传统企 业的资深专家,各路大咖齐聚,汇聚500+行业精英,聚焦架构、敏捷、运维三大主线,开启一场专属于IT人的年度之约!
专家阵容:或行业资深派、或著书力作派、或传统转型派、或一线实战派,总有一款是你喜欢!
绝对干货:聚焦架构、敏捷、运维三大主线,共讨传统企业在技术转型过程中的实践与困境、互联网企业在前沿技术方面的应用与心得、技术服务型企业在新老技术之间如何切换与落地,拒绝无营养的广告,绝对干货,精彩不容错过!
连接联动:汇聚社群数百顶级专家人脉,携数万社群成员声势,联合数十家媒体单位,共同打造一场连接敏捷与运维圈子的年度之约!
门票:免费!(限时限额)
VIP票:199元(限3月20日前)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721