
DB-Engines数据库排行榜
一、RDBMS
Oracle发布21c,包含200多项创新
MySQL发布8.0.24及8.0.25版本
PostgreSQL发布14 Beta 1,新增众多特性
OceanBase宣布开源及发布V3.1版本
二、NoSQL
RocksDB发布6.19.x及6.20.x版本
三、NewSQL
TiDB发布5.0版本
SequoiaDB发布3.4.3和5.0.2版本,并正式推出四大产品线
四、时序数据库
本期新秀:MatrixDB发布4.0版本
五、大数据生态圈
Elastic发布3个重大版本
Greenplum发布6.16版本
五、国产数据库
达梦发布DM 8.4版本
openGauss发布2.0.0版本并更新2.0.1版本
QianBase发布正式1.6.6SP2版本
ArkDB上半年更新汇总
六、云数据库
阿里云20多款数据库产品上半年更新汇总
腾讯云8款数据库产品上半年更新汇总
京东云9款数据库产品上半年更新汇总
RadonDB兼容MySQL 8.0
推出dbaplus Newsletter的想法
感谢名单
为方便阅读、重点呈现,本文对各板块内容进行了精简,需阅读完整版可点击文末【阅读原文】或登录云盘下载:https://pan.baidu.com/s/1AiTkYKnCXWkU21PBEmnCgQ(提取码:nsnl)
DB-Engines数据库排行榜
以下取自2021年6月的数据,具体信息可以参考http://db-engines.com/en/ranking/,数据仅供参考。
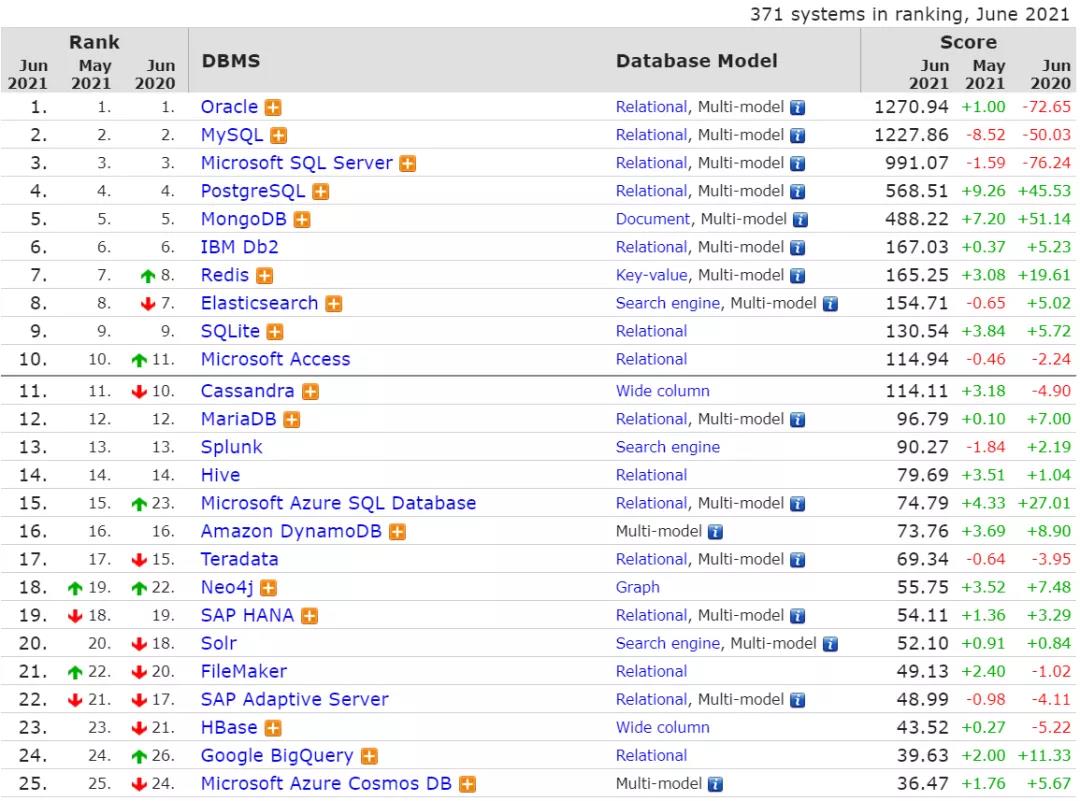
DB-Engines排名的数据依据5个不同的因素:
Google及Bing搜索引擎的关键字搜索数量;
Google Trends的搜索数量;
Indeed网站中的职位搜索量;
LinkedIn中提到关键字的个人资料数;
Stackoverflow上相关的问题和关注者数。
RDBMS
今年1月份,甲骨文公司宣布在Oracle云中推出新版本的全球领先融合数据库Oracle数据库21c。Oracle 21c可作为数据库引擎,为云端和本地部署Oracle数据库服务提供支持,最新版本包含200多项创新,关键创新包括:
不可变区块链表:区块链表提供不可变的仅插入功能,表中各行以加密形式链接在一起。Oracle数据库内置篡改检测和预防技术,可帮助客户防止内部人员或黑客冒充管理员或用户进行非法更改。区块链表作为融合数据库的一部分,可通过标准SQL进行访问,并支持完整分析和事务,易用性和功能表现远优于既有的区块链实施。区块链表特性在所有Oracle数据库版本中均免费提供。
原生JSON数据类型:提供新的JSON数据类型表现方式,将扫描速度加快了10倍、更新操作速度提高了4倍,使得Oracle SQL/JSON在YCSB基准测试中的运行速度比MongoDB和AWS DocumentDB快了2倍。与先前的版本相同,用户可以混合或联结JSON与其他数据类型;索引任何JSON要素以实现快速OLTP;在所有格式中使用声明式平行SQL分析;以及对多个JSON文档和集合运行复杂联结,且均不需要编写自定义应用代码。
数据库内机器学习AutoML:AutoML可大规模、自动化构建和比较机器学习模型,促进非专业用户对机器学习技术的利用。借助全新的AutoML用户界面,非专业用户能轻松使用数据库中机器学习功能。此外,甲骨文提供全新的异常检测、回归和深度学习分析算法,进一步丰富了数据库中机器学习算法库。
数据库内JavaScript:嵌入式Graal多语言引擎(Graal Multilingual Engine)支持JavaScript数据处理代码运行于存放的数据库之内,消除了成本高昂的网络传输工作。此外,用户可轻松在JavaScript代码中执行SQL,JavaScript数据类型将自动映射至Oracle数据库的数据。
持久内存支持:数据库数据和重做日志存储在本地持久内存(PMEM)中,可显著提升IO绑定负载的性能。用户可直接对存储在直接映射持久内存文件系统中的数据运行SQL,无需通过IO代路径或大型缓冲区高速缓存。此外,新数据库算法可防止将不完整或不一致的数据存码储到持久内存中。
更高性能的图形模型:可基于关系进行数据建模并探索社交网络、物联网中的连接和模式。进一步优化内存可减少分析大图形所需的内存空间,无需任何更改即可加快现有应用的运行速度。此外,用户还可使用Java语法,创建、扩展图形算法,以及Java语法在编译时进行优化,亦可作为原生算法使用。
数据库内存自动化:Oracle 21c新增自治管理内存列存储,可自动管理内存列存储中的放置和删除对象,然后追踪使用模式并从列存储中移动和删除对象,从而帮助简化流程和提高效率。此外,自治管理内存列存储还能够根据使用模式来自动执行列压缩。Oracle 21c提供全新的内存矢量联接算法,加快了复杂查询的速度。
自动化分片:数据分片功能不共享软硬件,可部署在本地或云端环境。为了简化分片设计和使用,Oracle 21c提供了分片顾问工具(Sharding Advisor Tool),可评估数据库schema及其负载特征,针对性能、可扩展性和可用性进行优化的分片数据库设计,同时支持跨分片的自动备份和恢复功能。
4月20日及5月11日,MySQL分别发布了8.0.24和8.0.25版本。8.0.24修复及功能更新较多,修复了219个Bug,其中有两位中国人的贡献,Yuxiang Jiang和Zhai Weixiang发现了Bug并贡献了修复的补丁程序。
关于修复的具体内容,请参阅官网(https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-24.html),除此之外,8.0.24版本在以下所列的功能点进行了更新:
MySQL Enterprise Audit现在支持对审计日志进行删减;
服务器通过在关闭连接之前将原因写入连接的方法,使得客户端收到一个包含客户端超时内容的错误消息,解决了以往服务器关闭连接而客户端无法获得正确原因的问题;
客户端连接失败消息里添加了端口号信息;
MySQL Keyring 功能从插件过渡到服务器组件,包括一款社区版/企业版组件及两款企业版组件;
升级使用curl 7.74.0;
Performance Schema增加了一些新的性能指标,包括:memory/sql/dd::infrastructure,memory/sql/dd::object。并对一些已有的指标进行改进和重命名;
为认证插件增加了系统变量,允许配置caching_sha2_password插件运行哈希次数;
空间地理信息方面增加了新的函数 ST_LineInterpolatePoint() 、 ST_LineInterpolatePoints() 、ST_PointAtDistance()和ST_Collect() 。此外CAST() 和 CONVERT() 增加了对地理空间数据的支持扩展;
InnoDB的 AUTOEXTEND_SIZE最大值从64M 增至4GB;
clone_donor_timeout_after_network_failure配置的超时时间由之前的固定值5分钟扩展到最大30分钟,用以提供更多的时常去解决网络问题;
向MGR的allowlist里面增加新成员不再需要停止/再启动MGR;
使用--skip-slave-start启动从服务器不在需要登录数据库服务器的主机。
5月15日,PostgreSQL发布14 Beta 1,在性能、管理、备份恢复、安全、SQL等方面均有新特性或增强,以下列举重点特性(对应的场景和价值,可点击本文文末【阅读原文】详细阅读本期Newsletter完整版):
一、性能
1、大量连接高并发优化(无论active和idle),上万连接无性能损耗
2、索引增强
缓解高频更新负载下的btree索引膨胀
支持sort接口,大幅提升Create GiST和SP-GiST索引的速度
支持SP-GiST覆盖索引功能满足任意维度聚集存储
BRIN支持布隆过滤和multi range
3、并行计算增强
并行顺序扫描支持chunk大IO利用prefetch能力大幅提升顺序IO扫描吞吐性能,解决小IO无法打满块设备吞吐指标的问题。
PL/pgSQL RETURN QUERY支持并行计算
刷新物化事务支持并行计算
4、内置sharding功能接口 postgres_fdw 持续增强
支持外部表异步并行计算
bulk insert
远程分区表的子分区可以import foreign schema生成外部表
支持truncate外部表
支持会话级持久化foreign server连接
5、分区表性能趋近完美
分区裁剪能力提升减少子分区subplan和重复的cached plans
增减分区时使用alter table detach|attach PARTITION concurrently模式完全避免锁冲突
6、窗口函数性能提升,支持增量sort,提升带窗口查询的场景的排序性能
7、自定义扩展统计信息增强,支持多个表达式为组合的扩展柱状图信息收集, 提升以表达式为组合过滤条件的选则性评估精度
8、支持multiple extended statistics,增强or,and多条件的选择性评估精度
9、大表search IN ( consts )优化,支持linear search TO hash table probe (当 in里面的consts 个数>= 9个时)
10、TOAST支持lz4压缩算法
11、libpq驱动支持pipeline模式,SQL请求支持异步化通信,大幅度提升性能,降低RT
二、数据类型和SQL
1、支持multi range类型,兼容range类型已知的所有操作符、索引
2、支持jsonb下标语法,大幅度简化JSON类型的使用,支持set原子操作
3、支持存储过程OUT参数
4、支持group by grouping sets,rollup,cube distinct语法过滤重复group组合
5、递归(CTE)图式搜索增加广度优先、深度优先语法,循环语法
6、增加date_bin函数,支持任意起点,按任意interval切分bucket,输入一个时间戳返回这个时间戳所在的bucket timestamp
7、支持tid range scan扫描方法,允许用户输入需要扫描指定数据块的范围
8、ecpg支持declare statement
三、管理
1、垃圾回收增强
concurrently模式创建索引不会引起垃圾膨胀
增加一个全速vacuum模式在触发后会忽略索引和sleep参数执行vacuum以最快速度完成vacuum freeze
在表里的垃圾占用的PAGE较少时跳过index vacuum从而提高vacuum效率
2、analyze提升(支持父表的全局视角统计信息, 支持IO prefetch加速analyze)
3、系统视图和管理函数增强
新增pg_stat_progress_copy视图,支持COPY导入数据进度监控,导入多少行,排除多少行(where filter)
新增pg_stat_wal统计信息视图,跟踪wal日志统计信息
新增 replication slot 统计信息视图 - pg_stat_replication_slots
pg_locks 增加 wait_start 字段,跟踪锁等待开始时间
sessions_killed统计指标,指导如何分析数据库有没有性能瓶颈,瓶颈是什么?top瓶颈是什么?如何优化?
pg_prepared_statements增加硬解析、软解析次数统计
支持查看当前会话和其他会话的内存上下文,诊断内存消耗问题
4、新增 GUC 参数
增加log_recovery_conflict_waits GUC参数,支持standby query&startup process conflict恢复冲突超时(deadlock_timeout)日志打印
增加track_wal_io_timing GUC参数,支持wal日志buffer write,fsync IO等待时长统计,在pg_stat_wal视图中查看
增加idle_session_timeout GUC参数,断开长时间空闲的会话
增加 client_connection_check_interval GUC参数, 协议层支持心跳包, 如果客户端已离线,可以快速中断这个客户端此前运行中的长SQL - Detect POLLHUP/POLLRDHUP while running queries
5、SQL命令增强
REINDEX command增加 tablespace 选项,支持重建索引到指定表空间
REINDEX command支持分区表,自动重建所有子分区的索引
6、插件功能增强
新增 pg_surgery 插件,可用于修复corrupted tuple。
新增old_snapshot插件,打印快照跟踪条目(每分钟一条, OldSnapshotTimeMapping结构)的内容,old_snapshot_threshold相关
pg_amcheck插件增加heap table数据页格式错误、逻辑错误检测功能
四、流复制与备份恢复
1、长事务逻辑复制优化,增加streaming接口,逻辑复制支持流式decoder和发送,无需等待事务结束,大幅度降低大事务、长事务的复制延迟
2、逻辑复制sync table data阶段支持多线程,允许同步全量数据的同时接收wal逻辑日志,可以缩短大表首次同步到达最终一致的耗时
3、alter subscription语法增强,支持add/drop publication
4、recovery性能增强 - recovery_init_sync_method=syncfs - 解决表很多时, crash recovery递归open所有file的性能问题 - 需Linux新内核支持
5、允许hot standby作为pg_rewind的源库
6、增加remove_temp_files_after_crash GUC参数,在数据库crash后重启时自动清理临时文件
7、standby wal receiver 接收时机优化,无需等待startup process replay结束,大幅度降低standby在重启后的wal接收延迟
五、安全
1、新增pg_read_all_data,pg_write_all_data角色,支持一次性赋予tables/views/sequences对象的读、写权限
2、默认使用SCRAM-SHA-256认证方法,提升安全性,完全规避md5可能的密钥泄露和协议攻击问题
3、pg_hba。conf clientcert支持verify-ca或verify-full校验客户端证书真伪,检验证书DN内容是否匹配连接的数据库用户
4、SSL客户端证书校验增加clientname CN DN提取选项,遵循 RFC2253
5、libpq协议层支持数据库状态判断(standby or primary)
6、libpq支持target_session_attrs属性配置:"any", "read-only", "read-write","primary","standby",and "prefer-standby"
6月1日,OceanBase正式宣布开源,并成立OceanBase开源社区。OceanBase采用木兰公共协议MulanPubL-2.0版,协议允许所有社区参与者对代码进行自由修改、使用和引用。
同时,OceanBase正式对外发布了V3.1版本。该版本实现了更强的混合负载能力与产品化提升。
混合负载能力:OceanBase数据库新版本的分布式并行执行引擎可使得OceanBase集群的多个数据库节点并行运行查询和DML语句,并且能够通过资源组的方式将TP和AP工作负载使用的资源进行隔离,而且实现了对大尺寸事务的支持,允许用户在一条DML语句中修改上亿行数据,真正实现了用一套系统支持实时混合负载。
兼容性:在V3.1版本,OceanBase数据库兼容了绝大部分Oracle数据库的SQL语法、函数、过程性语言、系统包、性能视图等功能。
高可用:在V3.1版本,OceanBase数据库对于集群的总控服务、选举算法、数据动态负载均衡机制都进行了大量的重构和优化,让OceanBase数据库在大集群规模、复杂高可用场景下,都能够实现RTO<30s的目标,并且数据的负载均衡效率大幅度提高。
可扩展能力:截止V3.1版本,OceanBase数据库已涵盖了Oracle的大多数分区类型,以及MySQL的全部分区类型。此外,该版本提高了单机分区数上限并支持了大事务,真正做到通过一套引擎解决混合负载的原生分布式数据库产品。
产品易用性:在V3.1版本,OceanBase数据库在产品易用性上做了很多工作,包含日志梳理、视图管理和升级。
NoSQL
近期,RocksDB分别发布了6.19.x和6.20.x版本。2个大版本主要修复了一些Bug及一些使用行为上的变化,新功能上主要围绕BackupEngine和BlobDB展开。
关于修复的具体内容,请参阅官网(https://github.com/facebook/rocksdb/releases),除此之外,在以下所列的功能点进行了更新:
添加了将BackupEngine备份作为只读数据库打开的功能,使用BackupEngine::GetBackupInfo()提供的BackupInfo::name_for_open和env_for_open和include_file_details=true;
添加了对集成BlobDB的BackupEngine支持,当共享表文件时,在备份之间共享Blob文件。由于当前的限制,blob文件始终使用kLegacyCrc32cAndFileSize命名方案,并且增量备份必须读取数据库中的所有blob文件并对其进行校验和,即使对于已备份的文件也是如此;
向BackupEngine::CreateNewBackup(WithMetadata)添加了一个可选的输出参数,以返回新备份的BackupID;
添加了BackupEngine::GetBackupInfo / GetLatestBackupInfo用于查询单个备份;
尽管用于启用它的API预计会发生变化,但根据SST架构(与版本>= 6.15.0兼容),使功能区过滤器成为长期支持的功能;
为BlobDB的新实现支持压缩过滤器。添加FilterBlobByKey()到CompactionFilter. 子类可以覆盖此方法,以便压缩过滤器可以确定在压缩期间是否必须读取实际的blob值。使用新的kUndeterminedinCompactionFilter::Decision表示需要进一步的操作来让压缩过滤器做出决定;
向BackupEngine::GetBackupInfo添加一个选项以包含每个备份文件的名称和大小。特别是在备份之间存在文件共享的情况下,这提供了对备份空间使用情况的详细洞察。
NewSQL
4月8日,TiDB发布5.0版本,在性能、稳定性、易用性、高可用与安全合规等方面都取得了很大进步,并增加了多个企业级特性,在OLTP Scale的基础上实现了一栈式数据实时分析的需求,关键特性如下:
TiDB通过TiFlash节点引入了MPP架构。这使得大型表连接类查询可以由不同TiFlash节点共同分担完成。当MPP模式开启后,TiDB将会根据代价决定是否应该交由MPP框架进行计算。MPP模式下,表连接将通过对JOIN Key进行数据计算时重分布(Exchange操作)的方式把计算压力分摊到各个TiFlash执行节点,从而达到加速计算的目的。经测试,TiDB 5.0在同等资源下,MPP引擎的总体性能是Greenplum 6.15.0与Apache Spark 3.1.1两到三倍之间,部分查询可达8倍性能差异。
引入聚簇索引功能,提升数据库的性能。例如,TPC-C tpmC的性能提升了39%。
开启异步提交事务功能,降低写入数据的延迟。例如:Sysbench设置64线程测试Update index时, 平均延迟由12.04ms降低到7.01ms,降低了41.7%。
通过提升优化器的稳定性及限制系统任务对I/O、网络、CPU、内存等资源的占用,降低系统的抖动。例如:测试8小时,TPC-C测试中tpmC抖动标准差的值小于等于2%。
通过完善调度功能及保证执行计划在最大程度上保持不变,提升系统的稳定性。
引入Raft Joint Consensus算法,确保Region成员变更时系统的可用性。
优化EXPLAIN功能、引入不可见索引等功能帮助提升DBA调试及SQL语句执行的效率。
通过从TiDB备份文件到Amazon S3、Google Cloud GCS,或者从Amazon S3、Google Cloud GCS恢复文件到TiDB,确保企业数据的可靠性。
提升从Amazon S3或者TiDB/MySQL导入导出数据的性能,帮忙企业在云上快速构建应用。例如:导入1TiB TPC-C数据性能提升了40%,由254 GiB/h提升到366 GiB/h。
一、3.4.3和5.0.2版本发布
2月以来,SequoiaDB巨杉数据库主要在3.4.3版本和5.0.2版本上完善功能,并进行性能方面的优化,已于6月27日发布。
3.4.3和5.0.2都是修复版本,目前两个版本上修复的问题相同。从大版本上来看,5.0大版本包含更丰富的功能,包括MVCC、按时间点恢复和STP(时间序列协议)等功能。
1、功能
SQL引擎:
完善SQL实例组功能
MySQL/MariaDB增加preferedinstance配置参数,可灵活配置读操作访问的实例
SequoiaDB引擎:
fap功能完善,支持MongoDB的findAndModify及bulkWrite功能
增加数据源功能,实现跨集群的数据访问
2、性能优化
SQL引擎:
优化MySQL索引查询性能
优化MySQL multistatement数据插入性能
SequoiaDB引擎
优化并发回放性能
优化主子表下对切分键排序查询的性能
二、正式推出四大产品线
5月15日,巨杉数据库基于「湖仓一体」架构,针对不同的业务需求场景发布DP融合数据平台、TP事务型数据库、CM内容管理数据库和DOC文档型数据库四大产品线。「湖仓一体」架构支持联机交易、流处理和分析,并同时支持结构化、半结构化和非结构化数据的存储,能降低数据流动带来的开发成本及计算存储开销,提升企业海量数据处理的“人效”和“能效”。
时序数据库
MatrixDB是北京四维纵横数据技术有限公司自研的超融合时空数据库,可同时支持关系型数据和时空数据的快速采集、高效存储、实时分析以及机器学习(ML+AI)。与传统的关系数据库+专用时空数据库相结合的架构相比,超融合时空数据库性能快10-100倍,并能大幅降低成本,提升开发运维效率。
5月11日,MatrixDB正式发布4.0版本,新版包括如下新特性:
1、Mars引擎
Mars引擎是自研的存储引擎。该引擎包含如下特性:
列式存储
数据编码和压缩
聚集下推优化
无索引扫描的优化
在时序场景中,适合存储历史冷数据,基于时间戳的聚集查询性能极高。
2、多节点自动化部署
在MatrixDB 3系统单节点自动化部署的基础上,实现了多节点自动化部署。只用不到5分钟,即可部署好一个多节点集群。
3、冷热分级存储UDF
为方便用户为时序表建立分区、维护分区表、冷热数据转换,实现了关于创建分区模板、建立分区、替换冷热分区的一整套管理接口。
4、time_bucket_gapfill
时序组件MatrixTS中,在time_bucket函数基础上,增加了time_bucket_gapfill函数。可以为缺失的时间间隔按照规则填充。目前支持两种填充规则:
locf:用聚合组中之前出现的值填充;
interpolate:对缺失的值做线性插值填充。
大数据生态圈
截至6月20日,Elastic.co发布了3个重大版本,7.11.x、7.12.x,7.13.x,令人期待的8.x.x版本预计第4季度或2022年发布。
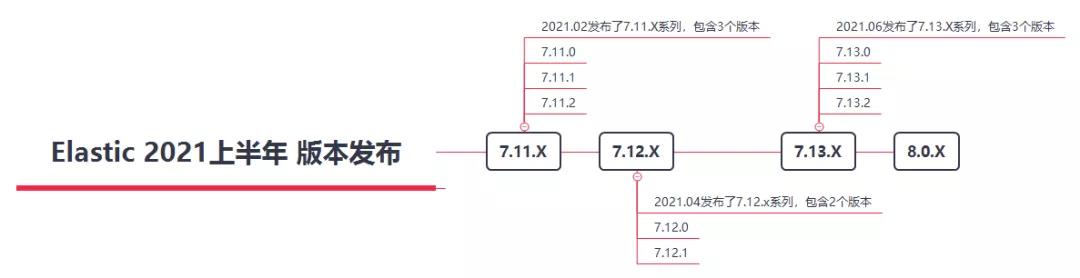
2021上半年Elastic版本发布
1、Runtime field运行时字段
在7.11.x之前版本,应用中若需要动态组合一些字段,如查询或者聚合,或者其他、默认采用的Script-Painless脚本,虽然功能上能满足,但性能是一个损失,同时若字段需要复用,则需要同时执行多个脚本;
runtime field运行时字段,算是ES一个小小的新创新,带来了一些新的玩法,大大简化之前版本直接使用脚本的的场景,也能支持多个场景复用字段,达到灵活与性能兼具;
runtime field运行时字段,目前官方提供2种使用形式,一种提前在mappings中定义,一种是在DSL中动态创建。建议可以尽快使用,尽可能将旧版本直接使用script的场景切换到最新的运行时字段方式来;
runtime field,运行时字段,虽然带来了诸多便利与好处,但也需要注意不可滥用,毕竟运行时计算依然依赖了script。
2、Forzen tier冻结层
7.12.x版本,Elasticsearch推出了冻结层特性,相比7.10.x增加了一个新的数据层概念,要知道ES为了解决海量数据的存储成本,推出了非常大胆创新的Searchable Snapshots能力,相比其它数据产品,ES备份的数据快照不用还原就可以搜索使用,虽然性能相比正常的索引稍微弱一些,但也大大的节约了时间与存储成本。冻结层就属于这个概念,目的就是把备份快照数据划分到冻结层,提供了索引从创建到所有可能使用阶段的生命周期管理;
结合ILM (index lifecycle management),让索引的自动化运维能力大大提升;
配套Searchable snapshots索引快照搜索能力,单集群可轻松应对海量数据存储与查询,用极少资源挂载数百TB或PB数据量成为可能,还在对于成本考虑的公司或技术人员可以换换思维了。
3、JDK16.x运行环境
从7.12.x开始,Elasticsearch升级了内置默认的JDK版本,当前版本是jdk16.x, 至于为什么升级到最新版本,官方并没有给出最佳解释,升级JDK当然可以获得一些性能提升或者其它方面便利;
JDK16.x版本,查阅官方增加了一些新的特性,其中最引入注意的是Vector API,近几年支持SIMD指令集数据分析产品大火,介于JDK版本特性问题,基于Java语言编写的大数据产品想要在数据分析能力得到性能的极致提升,非常难于实现,不如硬件CPU直接。JDK16.x开始支持SIMD指令,如果ES在未来某个版本开始直接支持SIMD,那么单机数据分析性能也可以直追Clickhouse,再结合Elastic Stack生态,个人很看好;
目前很多Java家族数据产品,想要做到SIMD,不借助JDK的话,只能通过JNI方式,混合使用C++的能力。这很别扭,也很无奈, 很期待Elasticsearch早日支持JDK Vector API。
Greenplum 6.0自正式版发布以来,保持每月一个小版本的迭代速率,持续提供新功能和修复补丁,目前的最新版是6月4日发布的6.16.2,更新功能如下:
1、服务器
解决了分区键类型和搜索值类型不同时Postgres planner分区选择的问题;
解决了以下问题:在具有 exec 位置INITPLAN的函数上运行 \df+ 时,Execute on列未正确显示“initplan”;
解决了由于服务器保存某些数据上下文的时间超过所需时间而可能发生的内存不足情况;
修复了创建DOMAIN时master和segment之间collname值的不一致;
解决了在指定CREATE MATERIALIZED VIEW失败并显示ERROR:division by zero when WITH NO DATA was being specified。
2、执行器
解决了由于内存上下文TupleSort的双重释放导致数据库出现PANIC的问题。
3、gpload
解决了gpload会因列名使用大写或混合大小写字符而失败的问题。gpload现在会自动为YAML控制文件中尚未引用的列名添加双引号。
此外,在过去的一个月中,Greenplum监控管理平台Greenplum Command Center(GPCC)和流数据处理和下一代ETL组件Greenplum Stream Server(GPSS)均进行了版本更新。其中,GPSS 1.6.0已于5日28日正式发布,GPCC 6.5已于5月31日正式发布。
注:更多版本的更新介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
国产数据库
近期,达梦发布了DM 8.4版本,其中值得关注更新如下:
DM DSC+DataWatch功能完善,对标Oracle RAC+ADG的同城双中心方案;
新增用户代理身份认证支持;
新增异步备库延时和定点重演支持;
新增dblink连接到网关功能支持;
新增超长大字段支持;
Linux下支持记录操作系统日志;
新增字符串后缀空格比较统一策略;
新增调试工具显示游标计划;
新增查询分区子表支持全局索引;
新增部分空间函数支持;
新增读写分离集群支持按服务名配置指定读负载的分配策略;
集群增加查看同步延时的时间差;
新增嵌套表支持参数为查询表达式支持;
新增物化视图的明细表类型支持临时表;
新增合并公用表达式的过滤条件并下放实现;
动态视图加载机制改造。
3月30日,openGauss发布2.0.0版本,其中值得关注的更新如下:
运维功能增强:极简安装、扩容工具功能增强、灰度升级、WDR诊断报告新增数据库运行指标;
高可用增强:支持延迟备库、备机支持逻辑复制、备机IO写放大优化;
开发功能增强:Data Studio客户端工具也针对内核的多个特性增加了适配。
6月,openGauss发布2.0.1版本,其中值得关注的更新如下:
增加备机xlog归档功能;
增强智能索引推荐能力。
6月5日,QianBase(钱库金融数据库)R1.6.6SP2版本正式发布。自2月份截止到QianBase1.6.6SP2发布,累计新增了以下功能:
数据库:
Binlog reader功能
表数据和索引比对功能
Savepoint支持多回滚点
QueryCache一系列功能增强
导入导出功能
预热只保存事务内语句
预热强制指定执行计划
Querycache虚表与querycache_hdfs数据进行对应
可设定RS级别以及事务级别行锁数量上限
备份恢复
支持binlog reader表备份恢复
快速恢复模式
滚动升级和滚动重启
连接服务:
多ActiveDCSMaster
JDBC T4驱动缓存
基础架构:
支持NTP服务器HA配置
2021上半年ArkDB主要更新如下:
ArkDB升级兼容MySQL 8.0.23。
ArkDB引擎物理复制模型重构,实现极速主从切换,大幅提升切换的稳定性。
优化启动流程,提升启动速度大幅提升。
ArkDB重构logic复制逻辑,避免潜在的死锁发生。
ArkDB优化mvcc index search btree一致性读的问题,index lock无锁化优化,死锁优化。
ArkDB新增对压缩表空间和自定义page size的支持。
ArkDB写性能优化,增加大量测试用例,大幅提升ArkDB稳定性。
Arkolap增加流控功能,提升OLTP引擎和OLAP引擎的数据同步性能。
Arkolap功能优化,支持在线动态调整同步相关参数。
Arkolap支持binlog复制模式。
Arkolap兼容性改进,兼容了更多的特殊语法和类型。
ArkDB中间件Arkpoxy大幅性能优化提示。
ArkDB中间件Arkpoxy完成对8.0的完全兼容。
ArkDB备份稳定性提升,完善了快照备份功能。
云数据库
一、云原生关系型数据库PolarDB与分布式版PolarDB-X更新
PolarDB PostgreSQL版宣布开源:阿里云宣布开源云原生数据库能力,PolarDB for PostgreSQL正式对外开放源代码。阿里云将加大开源数据库社区投入,与合作伙伴、开发者共同打造生态,共建云原生数据库2.0。
PolarDB MySQL新版本5.7.1.0.6发布上线:支持秒级加字段(Instant add column)功能,用户频繁扩充字段瞬时完成;以及多项“秒杀”场景优化(Statement Queue)。
PolarDB-X发布5.4.10版本:主要能力包括支持LOCALITY语法、支持全局二级索引的智能索引推荐、新增支持三权分立模式等功能。
二、阿里云RDS数据库产品更新
RDS MySQL新功能发布:只读实例支持多Endpoint功能,只读实例可为不同业务提供不同Endpoint,提升业务隔离性。支持validate_password插件,密码校验插件可帮助客户灵活配置密码强度、密码长度、密码规则、大小写规则、特殊字符规则等校验条件,提供更为安全方便的配置策略。RDS MySQL 适配validate_password插件,满足多样的密码配置需求。
三、阿里云NoSQL数据库产品更新
云原生多模数据库Lindorm新功能发布:支持Ganos引擎,提供时空数据的存储、检索和分析能力。Ganos是阿里云推出的一款包含管理「空间几何数据」、「时空轨迹」、「专题栅格」、「遥感影像」的时空大数据引擎系统。内置了高效的时空索引算法、空间拓扑几何算法、遥感影像处理算法等,结合阿里云Lindorm的分布式存储能力及Spark分析平台能力,可广泛应用于空间/时空/遥感大数据存储、查询、分析与数据挖掘场景。
发布数据流订阅功能Lindorm Streams,数据流式订阅功能支持行级保序,当数据发生变更时,通过订阅触发其他应用的业务处理,方便增量、实时数据和业务的联动处理。
云数据库Redis版新功能发布:Redis云盘版支持主从实例自动弹性变配功能,用户可配置当业务高峰时,自动升配应对业务高峰;发布网络带宽调整功能,用户可根据业务需求灵活弹扩实例的带宽,并快速无感的提升实例带宽;性能监控全面升级,优化监控指标展示效果和响应速度,同时交互上增强了操作便捷度,选择查看时间范围十分钟内可提供5秒级别的监控数据,更精准的定位线上问题;推出访问审计日志,提供更强大的日志审计能力。
图数据库GDB新功能发布:只读节点功能正式全网发布,满足大量的数据库读取需求,增加应用的吞吐量,实现读取能力的弹性扩展,分担数据库压力。
四、云原生数据仓库和数据湖更新
云原生数据仓库AnalyticDB MySQL版新功能发布:弹性模式发布了ES8(8核32GB) ES16(16核64GB)两个入门级小规格。弹性模式分时弹性功能支持跨AZ弹性,解决了此前分时弹性由于ECS等基础资源不足导致资源弹出失败问题,提高了分时弹性功能的可用性。
支持物化视图批量更新功能,支持用户自定义物化视图以及数据刷新逻辑,用于简化定时报表和ETL计算开发过程。
发布基于Spark引擎的离线计算能力,支持一份数据,既可用ADB SQL引擎进行读写、查询计算,也可以用Spark引擎进行迭代计算。
云原生数据仓库ADB PostgreSQL版新功能发布:发布共享SSD云盘实例,支持共享云盘功能和多Master节点架构,通过主备节点支持共享SSD云盘架构,节省存储资源。通过多Master节点架构,提升数据高吞吐写入能力,以及提升高并发查询能力。
发布COPY/UNLOAD命令,支持导入和导出OSS数据,其同时兼容Redshift语法,帮助Redshift业务迁移;内核发布自动收集信息,自动垃圾空间回收功能Auto Vacuum & Analyze;发布单节点内并行查询功能,低并发下单条查询可以充分利用多核资源,提升性能。
数据库混合云敏捷DBStack版V1.0.0发布,AnalyticDB PostgreSQL版作为数据库轻量化底座DBStack上的第一款发布产品,用于更好的支撑Teradata/Oracle/DB2等传统数据仓库迁移。
注:更多关于阿里云其它数据库产品的更新介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
一、腾讯云MySQL发布8.0 20201230版本
4月,腾讯云MySQL发布8.0 20201230版本,其中值得关注的新特性有:
合并官方8.0.19、8.0.20、8.0.21、8.0.22变更
支持动态设置 thread_handling 线程模式或连接池模式
新改进:
优化BINLOG LOCK_done锁冲突,提升写入性能
使用Lock Free Hash 优化 trx_sys mutex冲突,提升性能
redo log刷盘优化
buffer pool初始化时间优化
大表drop table清理AHI优化
审计性能优化
同时修复若干bug
4月,发布数据库代理能力。数据库代理是位于云数据库服务和应用服务之间的网络代理服务,用于代理应用服务访问数据库时的所有请求。
数据库代理访问地址独立于原有的数据库访问地址,通过数据库代理地址的请求全部通过代理集群中转访问数据库的主从节点,进行读写分离,将读请求转发至只读实例,降低主库的负载。
二、腾讯云数据库PostgreSQL新功能汇总
2月份以来,云数据库PostgreSQL发布了诸多特性,其中包括大量安全增强特性以及管理优化的功能。其中重点能力有:实例安全组、二次身份认证、实例回收站、5秒监控与告警。
三、腾讯云MongoDB发布4.2正式版
MongoDB发布4.2正式版:
MongoDB发布4.2正式版,正式支持的分片集群下的事务,同时支持自定义proxy数量、mongod数量等能力,优化了的备份回档能力,配合业务使用更方便。
MongoDB支持跨可用区部署:
腾讯云MongoDB发布了跨可用区部署的公测版,用户可以选择将集群的3个节点部署在3个不同可用区。
目前跨可用区的第二期和第三期在持续开发中,未来将支持普通集群到跨可用区集群的任意转换,用户可自行调整节点的部署方式。
四、腾讯云数据库SQL Server 2019正式发布
4月,SQL Server发布新特性,其中值得关注的新特性有:实例版本升级、实例架构升级、tag支持、离线迁移,并发支持、备份易用性优化、实例支持修改vpc网络。
5月,SQL Server 2019正式上线对外发布,支持多种产品架构,在性能、易用性、安全性上显著增强。
五、腾讯云DBbrain新功能汇总
4月,DBbrain正式对外发布支持自建数据库自治,可采用直连接入或者agent接入两种方式接入自建数据库,使得多种类型的自建数据库(包括腾讯云CVM自建数据库、用户本地IDC自建数据库、其他云厂商虚拟机上的自建数据库等)也能拥有DBbrain提供的监控告警、诊断优化、数据库管理等自治服务能力。
5月,DBbrain发布新特性,其中值得关注的新特性有:
合规审计:支持日志导出;自定义审计规则;上线合规审计计费;
无主键表:新增扫描实例无主键表功能,并加入健康报告内容;
健康评分:评分打分周期从30min优化到5min;
自治服务:支持实例热点更新保护功能;
空间分析:支持用户发起任务拉取表空间、碎片信息;
邮件发送:支持邮件分时段发送;
SQL优化:支持insert, update, delete语句索引、重写建议;
热点更新保护:正式全量对外发布;
kill会话:支持可查看kill会话历史记录及持续kill详情。
注:更多关于腾讯云其它数据库产品的更新介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
一、云数据库MySQL、MariaDB、Percona
MySQL实例支持小版本升级,可将MySQL版本升级到当前的最新版本。
运维账号,支持权限设置,可在技术支持人员运维时,提供合适的权限。
提供空间保护功能,可根据配置在空间不足时,自动清理binlog。
主备切换时,可通过站内信,邮件等方式通知运维人员。
慢日志,审计日志支持按用户和关键字进行过滤检索。
二、分布式数据库TiDB
提供参数配置功能, 满足不同业务系统的调优需求。
支持小版本升级,可将TiDB集群升级到当前版本的最新小版本。
支持节点重启,可以手动重启集群中的指定节点,满足灵活的运维需求。
支持从RDS MySQL到TiDB的增量迁移,可在线数据。
三、分析型云数据库JCHDB
提供参数配置功能, 满足不同业务系统的调优需求。
上线20.8.11.17和21.3.5.42版本,提供更丰富的版本选择。
支持集群版本升级,可将集群升级到指定的版本。
支持审计,可记录用户执行的所有SQL语句,满足安全合规要求。
支持慢查询功能,满足业务优化的需求。
四、云数据库PostgreSQL
提供最新的PostgreSQL 13版本。
支持创建实例时进行资源的打标(Tag)。
支持自动续费。
五、数据库仓库JDW
支持小版本升级,可将JDW集群升级到当前最新的小版本。
支持慢查询功能,满足业务优化的需求。
六、数据迁移DTS
数据订阅支持PostgreSQL。
支持MySQL到TiDB的增量数据同步。
七、JMR
发布JMR-2.1.1版本,组件升级Tez-0.9.1、Hadoop组件分离为HDFS 2.8.5 & YARN 2.8.5。
发布JMR-2.2.0版本,OS升级为CentOS 7.6、升级组件Hue 4.7.1、新增Flume 1.9.0、升级Flink版本至1.12.4。
增强HBase服务监控。
增强对组件服务的监控告警/服务运维能力。
1、新增和提升功能
值得关注的新功能:RadonDB兼容MySQL 8.0。
2、主要语句修改
主要做了以下语句的兼容修改:
Data Definition Statements
新增了对ALTER DATABASE Statement、RENAME TABLE Statement语句的支持;
完善了对ALTER TABLE Statement、CREATE DATABASE Statement、CREATE INDEX Statement、CREATE TABLE、DROP DATABASE Statement、DROP INDEX Statement、DROP TABLE Statement、TRUNCATE TABLE Statement语句的解析和功能支持。
Data Manipulation Statements
完善了对DELETE Statement、INSERT Statement、REPLACE Statement、UPDATE Statement、CHECKSUM TABLE Statement、KILL Statement语句的解析和功能支持;
新增了对CHECK TABLE Statement、OPTIMIZE TABLE Statement、ANALYZE TABLE Statement语句的支持。
Utility Statements
完善了对EXPLAIN Statement语句的解析和功能支持。
新增了对DESCRIBE Statement和HELP Statement语句的支持。
新增了对大小写敏感验证。
Xenon更新
Raft协更新:learner不再执行change master to和start slave操作;
修复数据量较小情况下重建失败问题:在重建之前校验GTID,检查有无本地事务;重建之后移除binlog;
修复部分经常跑失败的测试用例,部分代码重构;
改进日志系统,优化日志输出信息;改进创建账号时ssl标志不友好的方式;改进包管理方式,使用go mod管理。
3、开源多款数据库容器化产品
RadonDB开发团队研发并开源了多款数据库容器化产品(MySQL、PostgreSQL、ClickHouse),支持在Kubernetes和KubeSphere上安装部署和管理。正式成立RadonDB开源社区。
推出dbaplus Newsletter的想法
dbaplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、时序数据库、大数据生态圈、国产数据库、云数据库等几个版块。
我们不以商业宣传为目的,不接受商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎大家监督指正。
Newsletter的发布周期约每隔三个月一期,下期计划时间是2021年10月份,大家如果有相关的信息提供欢迎发送至邮箱:newsletter@dbaplus.cn
感谢名单
最后,要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后。
欢迎提供Newsletter信息,
发送至邮箱:newsletter@dbaplus.cn
欢迎技术文章投稿,
发送至邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721