
DB-Engines数据库排行榜
新闻资讯
一、RDBMS
Oracle将推出21c,是全球唯一的融合数据库
MySQL 8.0 2020年度重大更新
PostgreSQL获得“2020年度数据库”称号
OceanBase最新2.2.7版本有重要更新
二、NoSQL
Redis 2020年度功能特性更新亮点
RocksDB 6.x大版本迭代更新回顾
Cassandra 4.0版本重大更新预览
三、NewSQL
TiDB 2020年度重大更新及技术要点分析
SequoiaDB首创专利级STP(分布式序列时钟协议)
四、大数据生态圈
Elastic 2020年度重大更新及技术要点分析
Greenplum每月迭代一个小版本,最新发布6.13.0
五、国产数据库
本期新秀:openGauss正式发布1.0.1及1.1.0版本
ArkDB 2020年度重大更新及技术要点分析
QianBaseTM2020年度重大更新及技术要点分析
六、云数据库
阿里云2020年度多款数据库产品更新汇总
腾讯云2020年度12款数据库产品更新汇总
京东智联云数据库2020年度发布汇总
RadonDB 2020年度重大更新及技术要点分析
推出dbaplus Newsletter的想法
感谢名单
为方便阅读、重点呈现,本文对各板块内容进行了精简,需阅读完整版可点击文末【阅读原文】或登录云盘下载:https://pan.baidu.com/s/1h8plZz-amxxOMMWTL2eicQ(提取码:dwqg)
DB-Engines数据库排行榜
以下取自2021年1月的数据,具体信息可以参考http://db-engines.com/en/ranking/,数据仅供参考。

DB-Engines排名的数据依据5个不同的因素:
Google及Bing搜索引擎的关键字搜索数量
Google Trends的搜索数量
Indeed网站中的职位搜索量
LinkedIn中提到关键字的个人资料数
Stackoverflow上相关的问题和关注者数
近期新闻资讯
1、2020年11月24日,国际权威调研机构Gartner公布2020年度全球数据库魔力象限评估结果,作为中国科技公司代表,阿里云首次挺进全球数据库第一阵营——“领导者”象限,这也是中国数据库40年来首次进入全球顶级数据库行列;此外,腾讯云、华为云进入了“特定领域者”象限。
2、2020年12月2日,Kubernetes官方发布公告,宣布自v1.20起放弃对Docker的支持,届时用户将收到Docker弃用警告,并需要改用其他容器运行时。但Docker作为容器镜像构建工具的作用将不受影响,用其构建的容器镜像将一如既往地在集群中与所有容器运行时正常运转。
3、2020年12月8日,CentOS项目宣布,CentOS 8将于2021年年底结束维护,为其接班的是CentOS Stream,CentOS Stream作为RHEL的上游(开发)分支在CentOS 8结束维护后会继续更新。而CentOS 7也将在其生命周期结束后停止维护。换而言之,“免费”的RHEL以后没有了。
4、2021年1月15日,Elastic公司宣布即将变更Elasticsearch和Kibana的其中一项开源许可协议——将Apache License 2.0变更为双授权许可,即SSPL + Elastic License。在不违反许可协议的前提下,变更后用户仍可自由选择使用满足自己需求的源代码或发行版。此次变更只影响使用到Apache License 2.0的源代码,与Apache License 2.0无关的部分像过去一样保持不变。例如Elasticsearch和Kibana的默认发行版会继续在Elastic License许可下发布,用户可继续免费下载和使用。
RDBMS
根据Oracle的产品策略, 2021年将会推出Oracle 21c,21c重要新特性在于进一步强化融合数据库理念。强调3M功能——多模、多工作负载、多租户,是全球唯一的融合数据库(在本地与云端均能部署)。
一、Oracle 21c重要新特性摘要
原生的区块链支持;
新的多租户Data Guard - 可插拔数据库(PDB)级别的灾难保护;
AutoML:自动化的机器学习 - 非专家级用户也可以充分利用机器学习的优势;
支持持久化内存,提供微秒级I/O响应;
JSON加速与灵活性;
In-Memory支持混合查询;
自动化的In-Memory管理;
Sharding增强:能从多个现有数据库创建分片数据库。
注:关于以上特性的具体说明,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
二、2020年度甲骨文重要发布回顾
2020年,甲骨文布了最新的Exadata X8M,Oracle Exadata X8M是业内首个采用了英特尔®傲腾™DC持久性内存和创新的数据库RDMA技术,与上一版本相比I/O吞吐量提高了2.5倍,I/O延迟降低了90%。
Oracle提供了多种方式使客户可以使用到Exadata的服务,包括了Exadata数据库一体机,Exadata公有云服务以及Exadata公有云私有化部署(ExaCC)。
另外,甲骨文还发布了Oracle数据库保护的最佳实践——ZDLRA最新版本X8,零数据丢失恢复一体机数据保护解决方案(简称恢复一体机)。
一、2020年度MySQL总体回顾
2020年,MySQL 8.0发布了4个版本8.0.19~8.0.22,在功能和稳定性方面已经具备一定的用户基础和优势,可以考虑在生产环境试用/使用。
另外,MySQL 5.6将于2021年2月停止更新,结束其生命周期(EOL),也就是说,2021年2月以后,MySQL团队将不会再为5.6系列版本的MySQL提供任何补丁,反之留给MySQL 5.7的时间也较紧张,目前截止时间是2023年10月。
在功能方面,自MySQL 8.0.18版本发布hash join,到8.0.20版本已经可以使用hash join代替BNL,现在支持半连接、反连接、外连接,改进很明显,对MGR的细节也进行了很多功能改造,在安全性、可用性方便有较大提升。
尤其是在12月2日MySQL团队发布了MySQL Database Service with Analytics Engine,将OLTP/OLAP处理合二为一,同时在性能、安全和成本方面有了很大提升,让MySQL饱受诟病的OLAP领域带来转机。
二、MySQL 8.0针对业务研发关心的特性更新盘点
1、优化器改进
1)子查询update/delete采用Semi Join半连接作了优化
MySQL的子查询一直以来以性能差著称,所以解决的方案是用join关联查询代替子查询。
通常情况下,我们希望由内到外,先完成内表里的查询结果,然后驱动外查询的表,完成最终查询,但是MySQL 5.5会先扫描外表中的所有数据,每条数据将会传到内表中与之关联,如果外表很大的话,那么性能上将会很差。
MySQL 5.6版本里,子查询终于有了强劲的优化,这意味着不改变原有SQL的情况下,通过MySQL内部的优化器把子查询改写成为join关联查询。
但是,Semi Join半连接优化仅仅是针对select查询的,针对update/delete性能仍旧很差。
2)新增Anti Join反连接优化
在MySQL 8.0.18版本里,支持对NOT IN/EXISTS子查询语句优化,优化器内部将查询自动重写为Anti Join反连接查询SQL语句。
3)新增Hash Join优化
在MySQL 8.0.18中,增加了Hash Join新功能,它适用于未创建索引的字段,做等值关联查询。在之前的版本里,如果连接的字段没有创建索引,查询速度会是非常慢的(尤其是大表,执行频率很高的话,直接会将数据库打死),优化器会采用BNL(块嵌套)算法。
Hash Join算法是把一张小表数据存储到内存中的哈希表里,并逐行去匹配大表中的数据,计算哈希值并把符合条件的数据,从内存中返回客户端。
总结:以上三个特性,在不改变SQL语句的情况下,MySQL自身就将其优化,减少了开发日常的工作,避免了生产事故的发生。
2、InnoDB
1)instant add column亿级大表毫秒级加字段
加字段是痛苦的,需要对表进行重建,尤其是对亿级别的大表,DBA会反馈开发,表太大,加不了了,那么开发就得重新调整业务逻辑,势必增加了工作量。
虽然Online DDL可以避免锁表,但如果在主库上执行耗时30分钟,那么再复制到从库上执行,主从复制就出现延迟。使用instant ADD COLUMN特性,只需弹下烟灰的时间,字段就加好了,享受MongoDB那样的非结构化存储的灵活方便,无形中减少了开发的工作量。
限制:
如果指定了AFTER,字段必须是在最后一列,否则需要重建表;
不适用于ROW_FORMAT = COMPRESSED;
DROP COLUMN需要重建表;
modify修改字段属性需要重建表。
3、系统稳定性提升
1)资源组有效解决慢SQL引发CPU告警
资源组的作用是资源隔离(你可以理解为开通云主机时勾选的硬件配置),将线上的慢SQL线程ID分配给CPU一个核,让它慢慢跑,从而不影响CPU整体性能。
注:资源组启动需开启CAP_SYS_NICE功能。
开启步骤如下:
# setcap cap_sys_nice+ep /usr/local/mysql/bin/mysqld
# getcap /usr/local/mysql/bin/mysqld
/usr/local/mysql/bin/mysqld = cap_sys_nice+ep
2)Query Rewrite插件重写DML语句
MySQL 8.0 Query Rewrite支持SELECT INSERT UPDETE DELETE REPLACE语句重写这个功能要点赞,比如开发上线时,有个SQL查询字段索引忘记加了,直接把线上CPU打满,此时,你可以将SQL重写,让业务先报错,别打死数据库,然后马上通知开发回滚,等加完索引后再上线。
注:本期Newsletter完整版中还包含有以上特性的具体操作例子,以及MySQL与TiDB的性能压测对比,提供不同场景需求的选型建议(点击本文文末【阅读原文】可下载详细阅读)
一、PostgreSQL以最高增长速度获得DB-Engines 2020年度数据库称号。
二、PostgreSQL 13正式版的提升与优化
2020年9月24日PostgreSQL 13正式发布,也是目前的最新版本。PostgreSQL 13在索引和查找方面进行了重大改进,有利于大型数据库系统,同时包括索引的空间节省和性能提高,使用聚合或分区的查询时的更快响应,使用增强的统计信息时更优化的查询计划,以及很多其他改进。
PostgreSQL 13除了具有强烈要求的功能(如并行清理和增量排序)外,还为不同大小的负载提供了更好的数据管理体验。此版本针对日常管理进行了优化,为应用程序开发人员提供了更多便利,并增强了安全性。
注:关于PostgreSQL 13的性能提升、管理优化、应用程序开发便利、安全增强的具体内容,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
三、PostgreSQL常用插件动态
1、分布式插件citus发布 9.5.1
citus是PostgreSQL的一款比较流行的sharding插件,agpl开源协议,目前为微软所拥有,国内苏宁有较大量使用案例。
2、地理信息插件postgis 3.1正式版本发布
PostGIS是专业的时空数据库插件,在测绘、航天、气象、地震、国土资源、地图等时空专业领域应用广泛。同时在互联网行业也得到了对GIS有性能、功能深度要求的客户青睐,比如共享出行、外卖等客户。
http://postgis.net/
3、时序插件timescaledb发布2.0.0
timescale是PostgreSQL的一款时序数据库插件,在IoT行业中有非常好的应用,2.0.0 的主要功能增强包括:
添加对分布式表的支持;
添加对用户定义的actions;
添加持续聚合API;
重新设计信息视图;
将企业功能移动到社区版。
https://github.com/timescale/timescaledb
4、Oracle兼容插件orafce发布3.13.4
orafce是PostgreSQL的一款增强Oracle兼容性的插件。
https://api.pgxn.org/src/orafce/
2020年,OceanBase数据库一共迭代了3个版本,最新发布的2.2.7版本在高可用性、兼容性、安全性等方面进行了重要的更新。
1、高可用性
在高可用特性方面,除了提供原有的基于多副本的高可用形态之外,又提供了基于事务日志复制技术的高可用特性—主备库,创新性的将日志和复制技术引入到了原生分布式数据库领域,提供更灵活的高可用和容灾能力。
主集群通过向备用集群发送事务日志的方式来实现数据同步,从而确保生产集群能够在遇到数据损坏、灾难等情况下仍可快速恢复业务。当OceanBase生产集群出现计划内或计划外的不可用情况时,主备库可通过将某一个备用集群的角色切换为主集群,从而保证系统的持续运行,最大限度降低服务的停机时间。另外,OceanBase在物理备份恢复方面也提供了更多的功能。
2、兼容性
OceanBase针对Oracle、MySQL这两种应用最为广泛的数据库生态都给予了很好的支持。对于MySQL,OceanBase支持MySQL 5.6版本几乎全量语法,可以做到MySQL业务无缝切换。
对于Oracle,OceanBase目前已高度兼容Oracle的各种特性,包括数据库对象、SQL 语法、函数、PL/SQL语法、系统包等,让使用Oracle数据库的应用程序可更方便迁移到OceanBase,并为应用程序开发人员提供更多功能。
最新发布的2.2.7版本在复杂查询方面做了进一步优化。同时在并行执行处理能力进一步提升,提供提前解除行锁的能力来降低锁冲突,提升系统性能。事务解锁的时机由日志持久化成功,提前到拷贝batch buffer完成,使得操作同一行的事务能够并发执行。
3、安全性
在安全特性上也进行了很多提升,除了兼容绝大部分MySQL模式的权限外,对集群级别的各种系统权限进行了细致的拆分,并在Oracle模式也支持绝大部分的系统权限、对象权限、角色等安全功能。
此外,OceanBase新增支持权限审计、用户审计、对象审计、Lable Security、数据透明加密、全链路支持SSL加密等高级安全特性。可以看到OceanBase已经可以提供从权限控制到审计的全栈安全特性,还能提供精细到行级别的访问控制,并可提供从存储到传输的数据全链路加密能力,做到防止数据泄漏、保障数据安全、数据访问记录、全方位确保用户的数据安全。
NoSQL
从2019年12月19日6.0 RC到2020年12月14日6.2 RC,长达1年的时间中,Redis提供了许多喜人的功能和特性,虽然在性能上没有质的提升,但是在功能性、易用性和可维护性上面还是有许多值得期待和关注的亮点:
1、新增ACL权限控制
从Redis 6开始支持ACL,该功能通过限制对命令和key的访问来提高安全性。ACL的工作方式是在连接之后,要求客户端进行身份验证(用户名和有效密码);如果身份验证阶段成功,则连接与指定用户关联,并且该用户具有限制。同时,该功能与旧版本是向后兼容的,完全不用担心兼容性问题。
2、新增SSL支持
Redis 6开始支持SSL,连接更加安全。
3、多线程IO
Redis以高性能著称主要得益于单进程单线程的工作方式,多路I/O复用技术让单个线程高效的处理多个连接请求,使得Redis能够获得优异的性能。多线程IO的引入,主要用来处理网络数据的读写和协议解析的性能,但是命令的执行仍然是单线程,这样设计主要是不想因为多线程而使逻辑变得复杂,需要去处理key、lua、事务、LPUSH/LPOP等并发问题。
4、无盘复制
RDB作为Redis持久化方式之一,默认生成的RDB文件会存储在本地的磁盘上,开启无盘复制后,如果不再有用,将会被立即被删除。
同时,对RDB的加载也做了优化,RDB文件的加载速度比之前变得更快了。根据文件的实际组成(较大或较小的值),大概可以获得20-30%的性能提升。
5、Redis-benchmark支持集群
6、Redis引入集群代理
从Redis 6开始引入一个集群代理,可为客户端抽象Redis集群,使其像正在于单个实例进行交互一样,可简化客户端的操作。同时在简单且客户端仅使用简单命令和功能时执行多路复用。值得注意的是,这个集群代理跟Redis不在同一个repo中。其repo如下:
https://github.com/artix75/redis-cluster-proxy
注:关于新增命令或命令优化、Info字段改进、功能或性能优化改进、客户端优化改进的内容,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
从2019年11月25日6.6.0到2020年12月22日6.15.2,长达1年的时间中,RocksDB主要在6.x这个大版本上迭代,增加一些新特性及性能方面的优化。
一、新特性
sst_dump的时候新加了readahead_size参数,可以指定scan时候读取数据的大小;
增加了Options.file_checksum_gen_factory,用户可以指定checksum的函数,在sst 文件写完之后会把checksum和对应的函数名存储在ExternalSstFileInfo;
在MultiGet的时候增加了value_size_soft_limit,用户可以指定读取Value的累积值,当超过Limit之后忽略后面值的读取;
在调用IngestExternalFiles的时候增加了checksum的校验,用户可以通过verify_file_checksum这个参数来指定,为了向后兼容可以不启用checksum的校验;
对BlockBasedTableBuilder增加了Pipeline和并行压缩优化的支持,把 Block Build/Block Compression/Block Append进行Pipeline,并通过多线程来加速整个处理过程,目前还在验证阶段;
提供了memkink的Block Cache分配机制,可提供通过DRAM所能达到的超大高速缓存(大小可达几TB);
sst_dump中增加了对不同compression level压缩文件大小和耗时的统计及显示;
通过 DB::GetMapProperty拿到一些表级别的统计信息;
支持通过timestamp的CompactRange及GetApproximateSizes;
通过配置化的方法来更好的管理serialize及compare,以方便将来更好的扩展,同时支持一些自定义扩展,如TableFactory等;
增加了当IO出错时,自动恢复功能。当Flush或者WAL写入出错时,DB进入只读模式并尝试自动恢复,当在处理压缩出时,DB还是可以正常读写,并进行自动恢复;
当使用BlobDB时,可以对Base DB开启定期的compact操作;
通过在BlobDBOptions中将enable_garbage_collection设置为true 开启对BlobDB非TTL Blob数据的垃圾回收。在Compaction期间遇到的最旧的N个文件中的所有有效Blob(其中N是非TTL Blob文件的数量乘以BlobDBOptions :: garbage_collection_cutoff的值)将重定位到新的Blob文件,对一些不再需要的Blob文件,做删除操作;
MultiGet()可以使用IO Uring并行化从同一SST文件读取的内容。默认不开启此功能,可以使用环境变量ROCKSDB_USE_IO_URING启用。
二、性能优化
在Level iterator中更多的使用前缀查找及前缀布隆过滤器来提升性能;
通过DB Option来指定预读取及其大小,默认值为512KB,可以通过options.log_readahead_size来指定;
读取及解压缩block的时候减少多于的内存拷贝,同时在Direct IO模式下,减少读取sst table和blob db时的内存拷贝;
通过内部cache机制来解决启动时大量计算block大小导致重启比较慢的问题;
通过将块缓存查找共享到适用的过滤器块,以提升带分区过滤器的MultiGet的性能;
减少基于块的表中的随机访问期间的键比较;
重用全局统计线程,以减少多实例下线程个数;
通过设置KCompactionStyleLevel来减少写放大。
Cassandra是连续8年DB-Engines排名第一的宽表数据库,支持类SQL语法CQL,开发体验接近MySQL。预计2021年Q1将发布打磨了三年多的4.0版本。其中零拷贝串流(Zero-copy SSTable streaming)、Netty节点间通信、增量式修复、审计日志、临时副本等功能都十分值得期待。
零拷贝串流是指在串流时无需将数据读到内存后再写入到网络,可直接通过网络收发数据。从而显著提升性能(3-5倍),大大减少内存和CPU占用。可应用在多种场景,如缩短故障节点的恢复时间,降低多个节点同时处于不可用状态的概率;加速节点扩容时数据迁移速率,缩短扩节点时间等。
增量式修复在4.0版本可用于生产。每次修复时无需修复已完成修复的数据,仅需修复“未修复”部分。从而减少修复时间,仅需几分钟即可完成。
注:关于零拷贝串流、增量式修复、Netty节点间通信、虚拟表、审计日志的具体介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
NewSQL
2020年,TiDB总共更新了35个版本,在稳定性、性能、安全、高可用、备份与恢复、数据迁移、部署运维和功能方面进行大量改进。
一、TiDB 4.0版本关键特性
1、性能
与3.0相比,TPC-C TpmC提升50%,TPC-H部份查询性能提升50%,主要通过IndexMerge、统一线程池、存储层缓存查询结果、Follower read、列存储引擎(TiFlash) 等特性提升性能。
2、稳定性
优化器新增SPM和16种SQL Hint确保执行查询语句的稳定性;将查询中间结果写入磁盘,避免系统OOM;新增AutoRandom Key解决大批量数据写入产生的热点问题。
3、备份与恢复
新增分布式备份与恢复工具,备份性能的高达TiKV节点* 150+ MB/s,且随TiKV节点数线性扩展,备份与恢复支持全量、Database、Table级别备份与恢复,可将备份的数据存储到NFS、AWS S3等外部存储系统。
4、安全
支持TDE;所有组件之间的通信息支持TLS;支持对系统输出的日志脱敏,防止信息泄露。
5、支持悲观事务、事务的大小限制从100MB放开到10GB
6、部署与运维
TiUP提供基于命令行的部署、运维工具,秒级部署一套TiDB、一条命令完成版本升级、扩容、缩容,极大提升部署、运维TiDB的效率;支持可视化的诊断、排查TiDB的性能的问题,功能包括:Key Visualizer、Statement、Slow Query、Diagnostic Report、Log Search & Download等。
二、TiDB 5.0-rc版本最值得关注的特性
1、性能
开启聚族索引功能,性能与4.0相比TPC-C TpmC提升了39%;开启异步提交事务(Async Commit)功能,Sysbench oltp-insert latency降低了37.3%。
2、稳定性
通过提升优化器的稳定性及限制系统任务对I/O、网络、CPU、内存等资源的占用,降低系统的抖动,长期测试72小时,衡量Sysbench TPS抖动标准差的值从11.09%降低到3.3.6%。
3、可用性
引入Raft Joint Consensus算法,确保Region成员变更时,确保在有节点故障时系统任旧可用。
4、备份与恢复
通过备份文件到AWS S3、Google Cloud GCS或者从AWS S3、Google Cloud GCS恢复到TiDB,确保企业数据的可靠性。
5、导入与导出数据
提升从AWS S3或者TiDB/MySQL导入导出数据的性能,帮忙企业在云上快速构建应用,例如:导入1TiB TPC-C数据性能提升了40%,由254 GiB/h提升到366 GiB/h;DM 2.0提供dm-master、dm-worker高可用的能力,确保部分节点故障后服务可用。
6、部署、运维
优化EXPLAIN功能、引入不可见索引等功能帮助提升DBA调试及SQL语句的效率。
2020年10月,巨杉数据库正式发布了SequoiaDB v5.0版本,其中三大黑科技:跨引擎事务一致性、原生分布式金融级容灾、多云多平台,帮助企业提高在线交易、数据中台、历史数据管理、内容管理的运维效率,降低业务开发复杂性。
在SequoiaDB v5.0中,巨杉数据库团队首创专利级STP(分布式序列时钟协议),各STP Server之间通过Raft保证逻辑时钟的强一致性,每个数据库节点通过本地的STP Client与主STP Server保持逻辑时钟一致性。当前基于这一技术,巨杉数据库已经可以支持超过4096节点,数十PB级别的海量数据扩展。
另外,v5.0版本实现了在分布式数据库中罕见的“RR(Repeatable Read)级事务隔离”,在要求ACID绝对保障的高并发环境下性能显著提升,在多次不同环境的客户压力测试环境下,相比原有版本性能提升近3倍。
大数据生态圈
Elastic在2020年共发布过5次大版本,依然围绕7.X延续,从7.6.X到7.10.X,至于令人期待的8.X依然没有明确发布日期,中间还有7.11.X,7.12.X待正式发布,笔者预计2021年第三季度会发布8.X(内容仅代表笔者个人观点与喜好,不代表社区或官方,若有异议,欢迎探讨)。
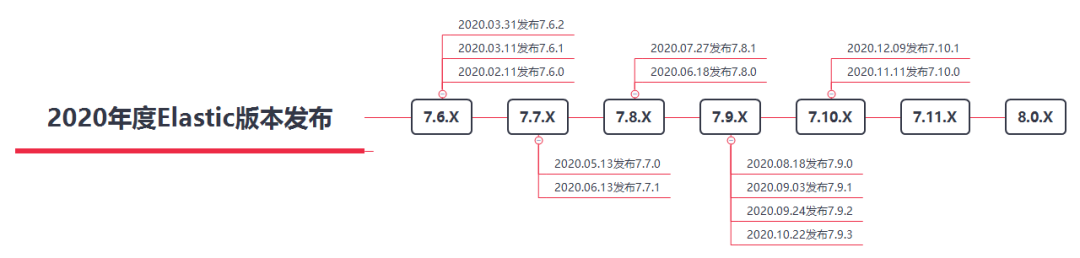
值得关注的性能优化及新特性
1、dense vector向量字段类型
向量检索可应用于很多领域,特别是图像识别、语音识别、智能问答、文本嵌入等,Elastc早期引入Vector字段类型,仅仅限于实验性阶段,7.6.0版本正式发布,对于有海量向量检索的应用项目多了一个选择。
2、off heap堆外内存
Elasitc 7.7.0版本性能优化最大的应该是off-heap堆外内存,将数据_id已到堆外内存,大大降低了JVM堆内存占用。据官方特定数据集测试,JVM堆内存利用率提升了7倍,同比之前版本可大大提升单节点挂载数据量,意味着服务器单位成本可大幅度降低,值得马上升级拥有。
3、jdk14运行环境
Elastic产品基于Java语言编写,运行于JVM之上,了解过JVM GC的同学都会习惯性的更换G1垃圾回收器,很多初学者以为Elaistc与普通Java应用一样,都需要配置GC,调优JVM,其实不然;
G1垃圾回收器出道已经多年,在普通应用中常用,但在ES里面却不是,ES团队在JDK14版本以前测试出过G1的致命BUG,所以官方一直没有承认G1的可靠性,此次7.7.0发布自带JDK14版本,意义重大,等同于官方认同了jdk14之后G1的可靠性;
此特性官方并未大张旗鼓的说明,原因不详;
关于G1在早期BUG,可详细查阅ES官方博客说明。
4、node.transform节点角色
新增一个节点角色,将原有数据转换的职责分离出来,设定独立的转换节点,使得可大规模应用于OLAP项目应用中,将实时需求与离线需求分离。
5、async search异步检索
ES虽然号称检索性能宇宙第一,但在聚合统计或者是复杂检索逻辑时,慢是无法避免的,同时也没有其它产品可替代,传统上只能应用程序端采用异步调度的方式查询或者聚合,费事费力,项目逻辑复杂性增加;ES引入异步检索之后,可大大减少应用程序端的复杂性,是开发的便利工具,也是ES提升性能的重要一环;
应用端发起异步检索,若服务端执行快,则立即返回检索结果;若超过设定时间,则返回异步检索元数据,应用端依据异步元数据再次检索即可,服务端会存储异步检索结果,有点类似应用程序的缓存。
6、wildcard通配符字段
Text类型应用在分词检索领域,所有文本都需要先分词,再检索,性能才可以;keyword类型是不分词,擅长碰撞检索场景,虽然也有推出模糊查询匹配机制,但性能上不上很好;
wildcard 就是应对上述2种情况难全的场景,特别是日志检索领域,即使在不分词情况下,依然可以使用通配符,性能较之前是杠杠,专为性能而生;
wildcard字段类型详细原理参考wiki。
7、EQL事件查询语言
7.9.0推出了EQL,全称Event Query Languge,事件查询语言,专门设计用于安全领域日志检索等,相比DSL(领域搜索语言),表达能力要更加直接,查询复杂度大大降低,比SQL更加流畅,非常值得应用;
必须承认DSL依然是Elastic.co中最强大最全面的查询语言表达式。
8、node.roles配置变更
Elasitc支持多种角色,默认单节点具备所有节点角色,也可以依据集群规模与业务需求灵活搭配;
7.9.0版本发布之后,笔者发现Elastic.co官方居然连配置参数都改变了,其实本质上没有什么变化 ,与7.8.X版本依然是兼容,在同一集群中可并行运行也不会有问题;
变化带来一些好处,首先语法上要简化一些,其次是为了后面版本推出更多的节点角色,以及具备层次的节点角色。
9、tableau可视化支持
ELK三件套融合了kibana可视化,Elasticsearch数据存储,Logstash数据采集能力,过于火爆误导很多传统BI人员以为Elasticsearch只支持Kibana,其余的不支持,很是遗憾;
7.9.0 顺势推出了ODBC驱动,可以支持Tableau可视化,终于可以结合Tableau丰富的BI能力与Elasticsearch的数据检索能力,强强联合。
10、data tier数据层概念
在以往版本里面,若要索引数据实现冷热分离,需要借助自定义标签的方式,在7.10.0版本之后,官方配置定义了此种标签,采用的是节点角色机制;
推出了多种节点角色,代表数据属于不同的生命周期,属于不同的数据层;
资源隔离上也推出了官方的设置参数,可以参考历史版本对比下,大同小异。
11、snapshot search快照搜索
快照支持搜索绝对是最应该宣传的新功能,带来的好处不言而喻;
避免原有数据还原之后搜索查询操作的麻烦,可直接搜索备份的数据;
节约数据存储,数据冷热分离之后,可直接在远程更加便宜的存储介质上查询数据;
目前7.10.0推出的依然是实验性版本,预计到下个版本就可以正式使用了。
注:更多版本的性能优化与特性介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
Greenplum 6.0升级了对应Postgres版本的内核(9.4),从而获得了更多Postgres的兼容特性;大幅增强了OLTP型负载的处理能力,从而胜任流计算和HTAP的场景。Greenplum 6.0的其它重要更新还包括:支持复制表、在线扩容、磁盘配额、支持Zstandard压缩算法、基于流复制的全新高可用机制等。
6.0自正式版发布以来,Greenplum保持每月一个小版本的迭代速率,持续提供新功能和修复补丁,目前最新版为6.13.0,于2020年12月18日发布,本版本中更新了多个新功能并修复了多个补丁,新功能如下:
内置了全新的VMware Tanzu Greenplum Connector for Apache NiFi 1.0.0.;
GPSS 升级至1.5.0版本;
以前强制设置的负载配置文件ERROR_LIMIT属性改成了可选;
集成了开箱即用的Prometheus工具;
增加了advanced_password_check contrib模块;
Greenplum数据库查询优化器增加新的服务器配置参数。
注:更多版本的新功能介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
国产数据库
openGauss在2020年6月建立社区,9月和12月分别发布1.0.1及1.1.0版本,热度持续上升,并荣获2020年度国产数据库。openGauss体现了华为特色,在过去的一年进行了大量的能力增强,快速进行产品商业化能力完善,其中主要的亮眼特性有:
1、通用能力增强
OS平台支持:支持openEuler 20.3 LTS on X86-64和麒麟V10 on ARM;支持在openEuler和CentOS的容器上运行;
支持ipv6协议:数据库支持使用ipv6协议进行连接。
2、Oracle及PG兼容性
LIST分区和HASH分区:截止1.1.0版本,openGauss支持RANGE分区、LIST分区和HASH分区,除多级分区能力外,openGauss已经能支持Oracle全部的表分区类型;
外部表:数据不存在于数据库中的表。通过向DB提供描述外部表的元数据, 可以把一个操作系统文件或者外部数据源当成数据库表, 就像这些数据存储在一个普通数据库表中一样来进行访问;
自治事务:自治事务(autonomous transaction)允许你创建一个”事务中的事务”,它能独立于其父事务提交或回滚。利用自治事务,可以开始一个新事务,完成一些工作,然后提交或回滚, 所有这些都不影响当前所执行事务的状态。自治事务约束参照规格约束的自治事务部分说明。该功能在1.1.0版本重构为线程间的通信方式;
全局分区索引(Global Partitioned Indexes):全局索引就是在全表上创建索引,它是独立的索引。如果查询引用非分区字段时可以提升性能。
3、高可用能力增强
双机HA增强:备机个数扩展到8个,并支持级联备机,级联备机从备机上复制日志,减轻主机的业务处理压力;
支持备机变为同步模式时间catchup2normal_wait_time参数可配置,备机启动与主机建立链接后,先处于日志追赶状态,等追赶的日志差距小于catchup2normal_wait_time,把备机变为同步模式。支持不同步配置文件,主备双机可能部署在不同规格的硬件上,主备的配置参数可能也不相同。修改原来的主备参数配置文件同步功能,支持不进行参数同步;
逻辑复制:在逻辑复制中把主库称为源端库,备库称为目标端数据库, 源端数据库根据预先指定好的逻辑解析规则对WAL文件进行解析, 把DML操作解析成一定的逻辑变化信息(标准SQL语句),源端数据库把标准SQL语句发给目标端数据库,目标端数据库收到后进行应用,从而实现数据同步。逻辑复制只有DML操作。逻辑复制可以实现跨版本复制,异构数据库复制,双写数据库复制,表级别复制;
支持异构数据库事务级同步能力(限DML)。
4、运维能力提升
在线添加索引:通过create index concurrently语法,以不阻塞DML的方式在线创建索引;
安装与OM工具解耦:1.1.0版本将OM工具与数据库内核进行了解耦,工具单独划分了仓库openGauss-OM,后续OM工具代码使用该仓库进行管理。具和内核分开打包,可以将两者镜像放到同一目录使用OM安装,安装方式保持不变。或者只关注内核则可以把内核镜像解压单独运行;
支持WDR自动诊断分析报告:WDR(Workload Diagnosis Report)基于两次不同时间点系统的性能快照数据, 生成这两个时间点之间的性能表现报表,用于诊断数据库内核的性能故障;
支持容器化部署(alpha):提供单机数据库的容器化部署能力。先通过脚本构建数据库的docker镜像, 启动镜像后,可以将单机数据库以容器化方式部署运行。
注:更多新特性介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
一、重大更新
升级兼容MySQL 8.0.20;
重构部分物理复制逻辑,提升从库复制性能和稳定性;
解决mvcc index search btree一致性读的问题,index lock无锁化优化;
增加大量测试用例,大幅提升ArkDB稳定性;
重构主从切换方式,修改为异步切换;
修改多个内部参数变量为原子变量,防止出现并发问题;
ArkDB连接层Arkproxy开源:https://github.com/arkdb/arkproxy;
优化arkdb redo log的对齐方式,可以提升读写性能;
ArkDB热备份工具开发,用于ArkDB数据物理备份,同时也支持从原生MySQL 8.0热备份升级到ArkDB;
二、新功能
新增Arkolap引擎,开启数据库多模引擎,提升ArkDB的olap分析能力;
支持ArkDB、Arkolap数据双引擎混合存储;
实现Arkolap数据智能同步,断点续传功能;
实现了一条复杂SQL语句在执行时,可选择在ArkDB和Arkolap任一存储引擎中查询的功能,提升并发查询效率。
三、技术要点分析
ArkDB在2020开发新增了Arkolap列式存储引擎,支持数据行列混合双引擎存储,用户只需在建表时,标注数据需要同步到Arkolap引擎,ArkDB内部同步数据到Arkolap引擎。在复杂的OLAP数据分析场景下,ArkDB支持TP数据和AP数据的混合连接查询,且100%兼容MySQL语法,保证最高兼容性的同时,ArkDB也拥有了强大的OLAP分析能力。
易鲸捷QianBaseTM在2020年陆续进行了多个版本的产品迭代并发布了4个正式版本,QianBaseTM1.6.0~1.6.3,结合用户需求和项目实践,对产品在功能、可用性、稳定性及扩展性方面进行研发优化,主要新增特性包括:
添加了binlog reader功能(技术预览):为应用提供主库到备库的数据实时同步能力;
支持悲观锁:采用加锁保护机制控制并发,同时支持死锁检查,异常锁信息清理,锁信息诊断等高级功能;
增强在线DDL功能:支持大部分常见的在线DDL操作;
扩展Hint功能:可兼容Oracle的hint语法;并支持CQD在Hint里设置,方便用户对需手工优化的SQL处理;
优化存储和计算引擎,提升系统高可用性:QianBaseTM提供快速故障检测插件包,支持软硬件毫秒级检测,并可加快恢复速度;
优化RMS内存管理机制,提升系统稳定性:提供RMS内存基层保护机制,保证系统高负载下仍可稳定运行;
ODBC 驱动支持ClipVarchar,节省大量网络带宽。
注:更详细的新特性介绍,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
云数据库
一、云原生关系型数据库PolarDB与分布式版PolarDB-X 2020年度更新
2020年2月:
PolarDB MySQL支持全局一致性:PolarDB的读写分离模块从低到高分别提供了最终一致性、会话一致性和全局一致性共三种。
2020年3月:
PolarDB-X底层数据节点支持RDS三节点(X-DB):通过支持RDS三节点(X-DB)和访问链路优化,PolarDB-X提供了RPO=0以及更加底的访问延迟。
2020年6月:
云原生分布式数据库PolarDB-X正式发布,支持超高并发和海量数据存储能力。
2020年8月:
PolarDB-O发布索引增强功能:PolarDB-O支持在分区表上并发创建索引,解决索引创建在大表中耗时过长的问题,同时支持索引添加Invisible状态,解决用户希望索引先失效然后确认无影响后再进行删除的需求。
2020年9月:
PolarDB-X发布两大全新企业级功能:混合负载HTAP和全局二级索引透明分布式:利用PolarDB-X的HTAP智能混合负载技术、数据查询强一致技术、资源链路强隔离技术和在线分析加速技术,PolarDB-X可以使在线交易和在线复杂查询的性能大大提升,效率提升5到10倍以上。全局二级索引功能,可以支持多维字段拆分,提供透明分布式拆分能力,满足业务对不同维度查询拆分的诉求。
2020年10月:
PolarDB MySQL发布公测新版本8.0.2:PolarDB MySQL发布公测新版本 8.0.2与社区版MySQL 8.0.18版本完全兼容,支持热重启(Warm BufferPool)、hash join等功能,进一步提升PolarDB的可用性稳定性和面向大表查询的性能。
2020年11月:
PolarDB-O到PolarDB-O DBLINK发布并上线。
2020年12月:
PolarDB-O到Oracle的DBLINK发布上线:PolarDB-O支持PolarDB-O到Oracle的DBLink功能,支持公有云PolarDB-O用户通过DBLINK功能访问线下或者ECS自建Oracle的数据,满足客户Oracle迁移至PolarDB-O后跨IDC网络跨实例访问远端数据库数据的需求。
二、RDS & NoSQL 2020年度更新
2020年1月:
RDS MySQL 8.0发布三节点企业版:三节点企业版三可用区部署实例支持可用性SLO是99.99%,同时实例主节点和备节点之间数据复制是强同步,提供RPO=0的数据库解决方案。
本次发布的核心功能包括:
8.0三节点企业版形态,存储类型是本地SSD盘;
8.0三节点企业版只读实例;
8.0三节点企业版独享代理,支持自动读写分离。
2020年2月:
RDS SQL Server 2019标准版Beta发布上线:SQL Server 2019版提供大数据集群扩展、混合缓存池、扩展标准语言SDK支持等新的数据库特性,同时阿里云数据库平台加持了性能洞察、按时间点恢复、数据审计、加密等全套运维解决方案,协助用户在既有业务场景或新型机器学习、人工智能业务场景下,更好地使用及管理SQL Server数据库。
RDS PostgreSQL V12发布plv8 2.3.13版本:支持使用plv8语言进行数据库的存储过程、函数编程。
2020年3-4月:
MySQL支持用户自定义调整Buffer Pool大小,目前首家支持该特性的中国云厂商:RDS MySQL支持修改InnoDB buffer pool空间大小,innodb_buffer_pool_size调整范围最小值128MB,最大值是RDS MySQL实例规格内存*80%。目前仅支持通过公式修改,在RDS参数管理和RDS参数模板中,通过系统变量DBInstanceClassMemory来设置 innodb_buffer_pool_size,如 {DBInstanceClassMemory*7/10} 表示将 RDS MySQL 实例的 innodb_buffer_pool_size 设置为规格定义的内存空间的70%大小。
HBase全品功能全面优化:
备份计划状态告警;
监控指标中新增“BDS冷存储使用空间大小”;
全量迁移、实时同步链路支持列、列族的过滤;
HBase归档ODPS,中间表改造分区表,节约计算资源;
HBase实时归档链路支持指定起始时间;
标准版新增大请求限制;
标准版OFFHEAP配置简化;
标准版JDK升级,优化特定场景下FullGC性能。
2020年5月:
RDS PostgreSQL V11支持DDL回收站、防火墙、增量订阅:RDS PostgreSQL V11开放事件触发器,支持DDL回收站、防火墙、增量订阅等功能. 增强安全、增量复制功能。
Redis 6.0发布:Redis 6.0版本在一系列关键领域进行了改进,支持新的Redis协议:RESP3,采用网络请求多线程处理提高了性能,并修复了之前版本的多个缺陷。此次在阿里云上线的规格是社区云盘版,后续会逐步支持本地盘版。
2020年6月:
RDS PostgreSQL 11发布内核新版本,时序、逻辑订阅、管理等功能增强:RDS for PG 11 20200610版本release note:1、支持插件timescaledb 1.7.1。2、支持rds_superuser 使用插件pageinspect。3、支持rds_superuser 赋予其他用户replication 权限。4、支持插件decoderbufs 0.1.0。
2020年10月:
云数据库Redis版发布数据闪回功能:业界独家支持数据闪回功能,最长可恢复7天内任意时间点(秒级)的Redis数据,避免误操作带来的数据损失,降低运维复杂度,实时保护数据。
2020年12月:
RDS PostgreSQL国内首发V13大版本,具体功能如下:
通过de-duplicate提升btree索引性能, 压缩索引空间;
聚合运算性能提升;
分区表性能提升;
通过多字段组合统计信息提升PLAN优化能力;
单个table的多个index支持并行vacuum;
支持incremental sort。
MongoDB发布4.4版本:MongoDB 4.4是MongoDB公司2020年推出的最新稳定大版本,目前阿里云首先发布了最新4.4版本,带来隐藏索引、Refinable Shard Keys、复合哈希分片键、对冲读、镜像读、Union聚合等多项新功能。
注:更多详细更新信息,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
一、腾讯云MySQL 8.0年度重大更新
1、腾讯云MySQL 8.0中针对性能提升的特性有:
快速加列;
异步删除大表;
SQL限流;
热点更新保护。
2、腾讯云MySQL中针对安全提升的特性有:
支持透明加密。
3、腾讯云MySQL中针对可用性提升的特性有:
多可用区容灾。
二、腾讯云数据库PostgreSQL年度功能更新
2020年,腾讯云数据库PostgreSQL每月均有版本发布,其中在3月份发布了Serverless化的PostgreSQL功能,主从延迟同步优化功能和只读实例功能。
功能速递:
Serverless实例支持灵活的资源弹性分配;
主从同步优化解决了社区仍未解决的大量drop场景下的同步日志堆积问题;
只读实例能有效的降低用户主实例的数据访问压力,实现读写分离的能力。
三、腾讯云Redis支持多可用区部署
2020年12月,腾讯云数据库Redis发布了跨可用区部署功能,支持同Region下跨任意可用区部署,同时针对缓存场景对延迟的苛刻要求,提供故障本地就近切换,就近只读功能。在提升服务可用性的同时,保障缓存的读取延迟。
四、云数据库Tendis正式发布
2020年12月,腾讯云数据库Tendis正式发布。Tendis是腾讯云自研、100%兼容Redis协议的数据库产品,作为一个高可用、高性能的分布式KV存储数据库,从访问时延、持久化需求、整体成本等不同维度的考量,推出了存储版和混合存储版的不同产品形态:
存储版:兼容Redis核心数据结构与接口,可提供大容量、低成本、强持久化的数据库服务,适用于兼容Redis协议、需要大容量且较高访问性能的温数据存储场景;
混合存储版:由缓存Redis和引擎Tendis两大组件构成,适用于KV(key-value)存储场景,通过将冷数据从内存驱逐,并在磁盘存储全量数据的方式,平衡了存储场景中性能和成本之间的难题,在冷数据占比较大的场景中可帮业务降低多达80%的运营成本。
五、腾讯发布全Serverless Database架构的云原生数据库TDSQL-C(原CynosDB )
全Serverless Database:2020年12月腾讯发布了国内首个计算和存储全Serverless架构的云原生数据库CynosDB Serverless;
支持数据库根据业务负载自动启停,无感扩缩容,并按实际使用的计算和存储资源计费,不用不付费;
满足小程序云开发等SaaS应用,IoT和边缘计算等不确定负载,以及开发测试等低频使用场景。
六、时序数据库CTSDB超大集群架构升级
2020年,CTSDB持续迭代,其中在9月份更新的超大集群架构升级新特性最值得关注。
超大集群架构升级:CTSDB在9月份进行架构升级,在集群中节点数量超过30个的超大规模场景,可以将当前的通用集群架构优化升级为混合节点集群架构,充分保证多节点超大集群的性能稳定;
多伦多一区上线:随着CTSDB上线多伦多一区,时序数据库CTSDB已上线华北、华东、华南和北美等地区。
七、云数据库MongoDB版本更新总结
1、腾讯云MongoDB新版本迁移产品newDTS for MongoDB 1.0版本发布
2020年7月,由腾讯云MongoDB自研的新版本迁移产品newDTS for MongoDB 1.0版本发布,具备跨版本迁移、自动重试、断点续传等企业级特性。2021年newDTS for MongoDB将支持更多特性,如跨架构迁移、异构迁移如迁移到ES等场景。
2、腾讯云MongoDB发布单节点版本、跨可用区版本
2020年11月,腾讯云MongoDB正式发布了单节点版本,在保障性能的同时,运营成本仅为集群版本1/3,适用于个人或企业学习、业务内部测试环境等场景。
2020年12月,腾讯云MongoDB发布了跨可用区版本,将支持同region下将实例的节点分布到任意不同的可用区,实现单实例跨区容灾的能力,满足企业的容灾需求。
八、云数据库Tcaplus发布3.46版本、3.50版本
2020年7月,TcaplusDB发布3.46版本,支持全局索引能力,客户可以在使用PB级存储、毫秒时延的KV数据库服务的同时,享用数据的聚合查询能力,支持在海量并发、不锁表、异步构建索引。
2020年10月,正式发布了TcaplusDB的3.50版本,支持本地开发环境,具体内容如下:
利用TcaplusDB的Local版本,支持本地开发环境,客户可以在不访问TcaplusDB云服务环境的情况下开发和测试应用程序;
Local版本帮助客户节省吞吐量、数据存储和数据传输费用。客户在开发应用程序时无需Internet连接;
Local版可提供免费的下载,并通过Docker 镜像提供服务。具有单示例即可服务、一键安装、一键启服的便捷使用能力。
九、腾讯云TDSQL-A ClickHouse版重磅上线
2020年12月,腾讯云TDSQL-A ClickHouse版发布,基于ClickHouse引擎,提供高性能、高可用和低成本的易用实时分析数据库解决方案。
TDSQL-A ClickHouse版与社区版高度兼容,且做了大量优化和云上适配,尤其对数据导入做了大量优化;
基于数据传输服务DTS的强大数据同步能力,能稳定高效将OLTP的数据同步到 ClickHouse,提供OLTP到OLAP的无缝联动,并能和已有腾讯云IT架构融为一体。
十、腾讯云TDSQL PostgreSQL版(原TBase OLTP版)
2020年9月底发布Oracle兼容版本,整体Oracle兼容性95%以上。可以帮助用户尽可能平滑地从Oracle迁移到腾讯云数据库上。
新发布的Oracle兼容版高度兼容Oracle语法,全面支持Oracle数据类型和操作符,包括大对象BLOB、CLOB等;
支持Oracle的各种分区表类型和语法;
支持connect by,merge into,pivot,同义词,hint、rowid、rownum等各种Oracle语法;
支持各种Oracle系统内置包,包括DBMS_SQL、DBMS_OUTPU等等;
支持自治事务;
支持dblink等。
十一、DBbridge具备数据库国产化迁移完整方案
2020年6月,DBbridge 1.0版本发布,支持Oracle到tencentDB的评估、结构迁移、全量迁移等功能,提供一站式数据迁移平台以及专家服务,满足企业数据库国产迁移需求。
2020年12月,DBbridge 2.5.11版本发布,支持Oracle到tencentDB的增量同步,反向同步和数据对比等功能,实现了完整的数据库国产迁移解决方案,满足企业数据的迁移、同步及灾备需求。
十二、腾讯云数据库智能管家DBbrain功能更新总结
2020年5月,DBbrain升级数据库健康得分体系,结合 AI,更贴合用户数据库真实运行状况。同时推出业内首款基于规则和代价估算的SQL优化效果预测及对比引擎;
2020年7月,DBbrain发布监控大盘、性能趋势、数据库帐号鉴权及常用运维命令快捷执行、数据库帐号安全扫描、异常告警消息通知推送、健康报告自定义邮件推送等功能,重点发布“SQL限流”和“热点数据防护”两大功能;
2020年10月,DBbrain完成对TDSQL、TDSQL-C的完美适配,将大量传统人工的数据库运维工作智能化;
2020年11月,DBbrain正式对外发布数据库安全特性,包括合规审计、数据脱敏、敏感数据发现、安全治理等功能。
注:更详细的产品技术分析,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
发布了分析型云数据库JCHDB,查询性能比传统开源数据库快上千倍,数据分析可实时得到结果,可满足业务对实时数据分析的需求;
分布式数据库TiDB可支持TiFlash,可在同一数据库中同时支持交易和数据分析,简化了业务架构,提升了业务性能;
云数据库MySQL提供了读写代理和只读代理功能,不但可以自动进行读写分离,并且只读实例也可具有高可用性;支持小版本升级,无感知迁移到最新版本;
云数据库PostgreSQL发布12.2版本,支持SQL/JSON路径,支持在线重建索引,分区表性能大幅度提升;发布s3_fdw数据流转插件,支持PostgreSQL到对象存储OSS数据流转,扩展PG数据库存储能力;
云数据库MongoDB提供多种节点副本集,可提供更高的数据读取性能;分片集群支持横向扩容,可按需升级集群的性能与容量;
数据仓库JDW发布6版本,OLTP性能比5版本提升70倍以上;支持小版本升级,无感知迁移到最新版本;
DTS发布数据订阅服务,可实时获取数据库的增量数据;发布数据同步服务,可用于数据异地灾备、业务系统数据流转等场景。
MyNewSQL领域的RadonDB云数据库在2020年度值得关注的新功能有:
1、一键数据均衡功能:radon rebalance
用户业务在分布式数据库上运行一段时间后,在大量数据的写入下,通过监控会发现不同后端数据有多有少,随数据量的增加,有的差别会比较大,从而导致数据量很大的节点负载会比较重。基于这种场景,新增加了数据均衡功能:radon rebalance。这个命令旨在重新平衡后端之间的数据(分区表)。
2、支持白名单地址段功能
针对有些用户需要支持一些连续地址片段的白名单,比如10.0.0.0/24,配置可以根据正则表达式进行配置。
3、增加xa事务的管理功能
针对一些异常场景下两阶段事务中有些prepared事务没有最终提交,且后端节点可能比较多,需要提供统一管理接口可以查看整体集群中事务相关状态,并能及时处理异常事务。
4、进一步完善读写分离功能,完善审计相关功能,支持后端指定分片数,丰富和完善集成测试。
5、各种生产环境和场景下发现的问题的fix和完善,如并发极端情况的死锁问题。
6、把迁移工具移到RadonDB中,成为功能子集,完善接口
整合shift迁移功能,作为基础库,抽象出interface接口,供radon层shift manager模块调用。radon层设计Shift manager插件模块,在plugin目录下新增shiftmanager目录,封装一组对shift启动/等待迁移结束/终止迁移等基本操作接口,并提供获取相应对状态信息的接口。并对每一个迁移对实例进行管理。维护每个实例的迁移状态、迁移进度、成功失败等信息,简化设计,降低了代码耦合及后续新增迁移类型功能的开发和维护的难度。
注:更多新功能介绍,可详细阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
推出dbaplus Newsletter的想法
dbaplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、时序数据库、大数据生态圈、国产数据库、云数据库等几个版块。
我们不以商业宣传为目的,不接受商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎大家监督指正。
Newsletter的发布周期约每隔三个月一期,下期计划时间是2021年4月19日~4月30日,大家如果有相关的信息提供欢迎发送至邮箱:newsletter@dbaplus.cn
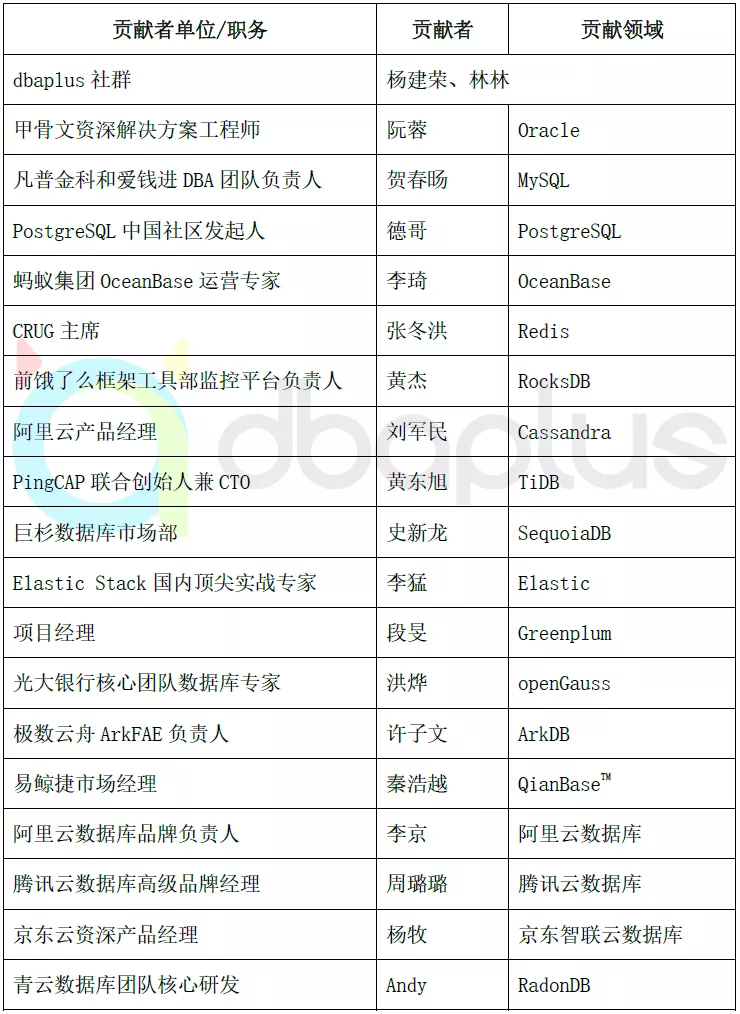
感谢名单
最后,要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后。
欢迎提供Newsletter信息,
发送至邮箱:newsletter@dbaplus.cn
欢迎技术文章投稿,
发送至邮箱:editor@dbaplus.cn
往期回顾:
↓点此下载完整版Newsletter(提取码:dwqg)
阅读原文








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721