
序言:国产数据库迎来新发展
DB-Engines数据库排行榜
新闻快讯
一、RDBMS家族
MySQL发布8.0.12版本
MariaDB 10.3功能展示
Percona发布5.7.23版本
RocksDB发布5.15.10版本
SQL Server发布2019公开预览版
PostgreSQL发布11 beta3版本
Greenplum发布5.11版本
二、NoSQL家族
MongoDB Server 4.0新功能介绍
Neo4j发布3.4.7版本
ArangoDB发布3.3.16版本
三、NewSQL家族
TiDB发布2.1 RC2版本
CockroachDB发布2.0版本
四、大数据生态圈
Hadoop发布3.1.1版本
ElasticSearch发布 6.4.1版本
Apache HAWQ发布2.4.0.0新版本
Druid发布0.12.3版本
五、国产数据库概览
K-DB发布集群数据库版本
OceanBase发布2.0版本
SequoiaDB开源SequoiaSQL
六、本期新内容:云数据库
本期新秀:TDSQL发布正式版10.2.0
本期新秀:RadonDB发布1.0.1版本
七、推出dbaplus Newsletter的想法
八、感谢名单
为方便阅读、重点呈现,本期Newsletter(2018年9月)将对各个板块的内容进行精简。需要阅读全文的同学可登录 https://pan.baidu.com/s/1ZhvM4V75DNtpoIyKOiUf7Q 进行下载。
序言:国产数据库迎来新发展
金秋九月,天朗气清,中国的数据库行业迎来了一波新的热点事件。分布式数据库领域新消息不断,也让大家开始关注中国的分布式数据库。首先是短短一周内,PingCAP和SequoiaDB巨杉数据库陆续宣布了C轮的数千万美元融资,融资的消息在IT圈成功“刷屏”。此后,在杭州的云栖大会上,蚂蚁金服的OceanBase也发布了2.0,而蚂蚁金服副CTO胡喜在现场“挖断网线”的多活容灾演示,也给大家切身体验了金融级数据库的严格要求以及强大数据安全保护能力。
国产分布式数据库迎来了快速发展期,2017年,Gartner作为业界最权威的技术和市场分析机构,也首次将阿里云数据库、南大通用和SequoiaDB巨杉数据库三款中国数据库产品列入数据库报告,则是整个国际数据库业界对中国数据库行业的一致认可。
中国数据库市场已经到了一个新的时代,作为参与者,我们感到十分欣喜。
研发层面,自研与技术创新是中国新一代分布式数据库的重要共同点。从零开始研发的数据库核心引擎,既是技术商业化的必然选择,也让企业在产品和路线上更有特色,更容易得到市场的认可。
技术层面,数据库技术的发展来到了拐点,分布式数据库和云化架构成为未来必然的方向。而在分布式数据库这个赛道上,中国和海外产品处在同一起跑线。
此外,随着中国在移动互联网、人工智能、物联网等领域的快速发展,新的应用、新的数据类型催生了数据库的新需求、新场景。同时,中国大型企业在金融级别的严苛应用环境下,对分布式数据库的技术迭代和场景创新更重要,在许多方面甚至远远领先于海外产品。
展望未来,新一代分布式数据库将迎来新的技术转型期。根据Gartner数据库报告显示,分布式数据库未来的核心技术方向主要有几个,包括分布式云化的架构,多种SQL支持,数据存储的Multimodel多模存储,HTAP混合交易/分析架构等等。
在技术和市场的共同推动下,国产分布式数据库会进入产品和市场的快速发展期。在中国新一代数据库如此巨大的潜在市场下,相信每一款产品都会有自己适应的应用场景和行业领域,希望大家可以一起努力,共同通过技术创新,让中国的用户,摆脱基础软件对于海外产品的依赖,也为中国所有核心技术创新的企业、创业者们,建立一条技术到商业的成功路径示范!
本期序言撰稿人:巨杉数据库CTO 王涛
DB-Engines数据库排行榜
以下取自2018年9月的数据,具体信息可以参考http://db-engines.com/en/ranking/,数据仅供参考。
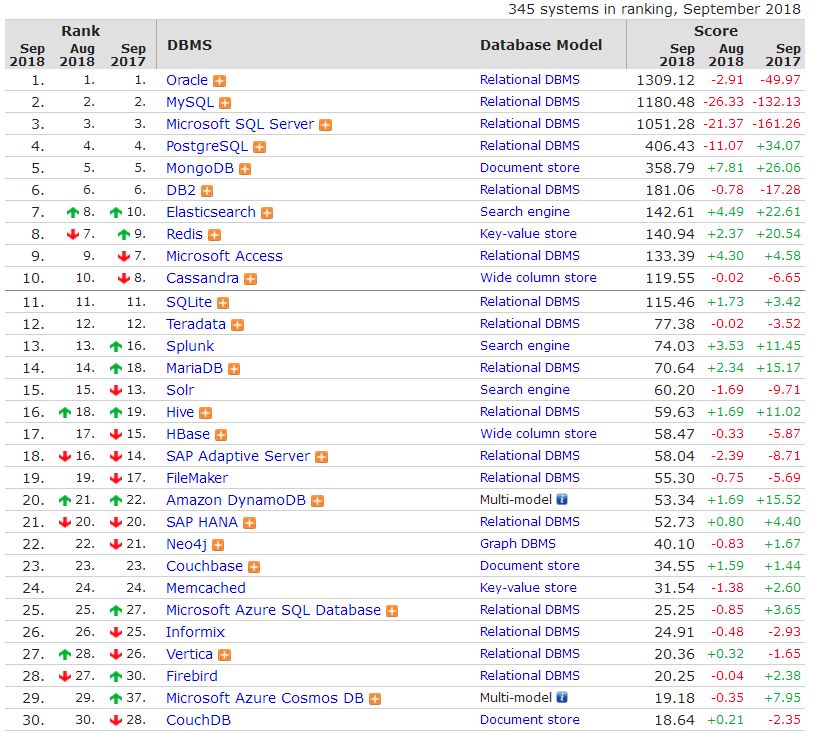
DB-Engines排名的数据依据5个不同的因素:
Google以及Bing搜索引擎的关键字搜索数量;
Google Trends的搜索数量;
Indeed网站中的职位搜索量;
LinkedIn中提到关键字的个人资料数;
Stackoverflow上相关的问题和关注者数。
新闻快讯
1、据CNBC 8月1日报道,亚马逊将弃用Oracle数据库,计划在2020年第一季度前将内部基础设施完全迁移至AWS。
2、2018年8月中旬,Redis Labs将该公司开发的Redis模块由AGPL改成了Apache v2.0和Commons Clause(共用条款)相结合的许可证,对销售许可证涵盖的软件作了限制,闭源RediSearch、Redis Graph、ReJSON、ReBloom、Redis-ML。
3、Redis Labs年增长60%。
4、9月上旬,多人要求修改Redis主从复制术语master/slave,Redis作者在尽量不影响项目的情况下做了一些妥协。
5、Python开发者Victor Stinner公开提交了4个PR,希望能将Python文档和代码中出现的 "master" 和 "slave" 修改为像 "parent" 和 "worker" 这样的术语,以及对其他类似的术语也进行修改。
6、eBay从OpenStack转移,重新平台化,拥抱Kubernetes和Docker。此外,eBay还设计、构建了自己的服务器,并构建了一个可在其所有团队中共享的内部人工智能(AI)引擎。
7、国产数据库融资:
PingCAP完成C轮5000万美元融资:2018年9月12日,新型分布式关系型数据库公司PingCAP宣布完成5000万美元C轮融资。
巨杉数据库完成C轮数千万美元融资:2018年9月18日,巨杉数据库宣布完成由嘉实投资领投的C轮融资。
8、OceanBase在9月21日的云栖大会上,现场演示金融级多活容灾能力:OceanBase近期发布了2.0版本,蚂蚁金服副CTO胡喜在现场做了“挖断网线”的多活容灾演示。
RDBMS家族
2018年7月27日,MySQL发布8.0.12版本。值得关注的更新有:
rewrite插件支持DML语句
rewrite插件式5.7版本引入,本次更新开始支持insert、update、replace这些DML语句。
Group Replication优化
新增了参数group_replication_exit_state_ action来控制,如果一个实例发现自己属于被抛弃(网络分区发生后的少数派)的实例的情况下,这个值默认为ABORT_SERVER,也就是说,少数派会自己关闭,这个值也可以设置为READ_ONLY,这个设置下,会以只读(设置super read only)的形式加入集群,并设置状态为ERROR。
InnoDB支持表变更的新算法INSTANT
该变更来自于腾讯DBA团队贡献,(Bug #28100103, Bug #91074)
本次变更融入一个新算法ALGORITHM=INS TANT,侧重于处理只需要修改元数据就可以完成的变更,对于应用使用更为便捷。
filesort 算法的缓存设置优化
MySQL在处理Order by的时候,如果没有索引可以用,会采用一个名为file sort的算法排序,有一个关联的参数sort_buffer_size,执行sql需要进行file sort,那么MySQL就会给当前回话直接分配sort_buffer_size大小的内存出来,在新版本中内存分配变成了按需分配。
参考:https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-12.html
1、MariaDB 10.3重构了KILL掉未提交的空事务
参数innodb_kill_idle_transaction(是Percona XtraDB引用的参数),意思为当一个事务长时间未提交,那么这个连接就不能关闭,内存就不释放,并发一大,导致DB连接数增多,就会对性能产生影响。
默认是0秒,你可以根据自己的情况设定阈值。超过这个阈值,服务端自动杀死未提交的空闲事务。
MariaDB在10.2.6版本里将其移除,因不再捆绑Percona XtraDB,分道扬镳。
MariaDB在10.3版本里,增加了3个参数,对标Percona的功能:
1)idle_transaction_timeout (所有的事务)
2)idle_write_transaction_timeout(写事务)
3)idle_readonly_transaction_timeout (只读事务)
注:单位为秒。这里设置了空事务未提交的时间为2秒,当超过2秒后,系统自动将其连接杀死。
设置这个参数后只针对新的连接有效,正在执行的连接无效。
参考:https://mariadb.com/kb/en/library/transaction-timeouts/
2、MariaDB 10.3解决掉了UPDATE不支持同一张表的子查询更新
案例:
CREATE TABLE t1 (c1 INT, c2 INT);
INSERT INTO t1 VALUES (10,10), (20,20);
UPDATE t1 SET c1=c1+1 WHERE c2=(SELECT MAX(c2) FROM t1);
在5.7和8.0上执行,会直接抛出错误:
ERROR 1093 (HY000): You can't specify target table 'a' for update in FROM clause
而这条语句在MariaDB10.3上执行,则顺利通过。
MySQL目前只能改写SQL实现,即max那条语句让其产生衍生表就可以通过。如下:
UPDATE t1 a, (SELECT MAX(c2) as m_c2 FROM t1) as b SET a.c1=a.c1+1 WHERE a.c2=b.m_c2;
同理看下DELETE删除操作:
案例:
DROP TABLE t1;
CREATE TABLE t1 (c1 INT, c2 INT);
DELETE FROM t1 WHERE c1 IN (SELECT b.c1 FROM t1 b WHERE b.c2=0);
在5.7和8.0上执行,同样会直接抛出错误:
ERROR 1093 (HY000): You can't specify target table 'a' for update in FROM clause
参考:https://jira.mariadb.org/browse/MDEV-12137
Percona Server for MySQL 5.7.23-23于2018年9月12日发布,基于MySQL 5.7.23,包含其中所的bug修复,Percona Server for MySQL 5.7.23-2是目前5.7系列的最新稳定版本。更新如下:
参数max_binlog_files不再建议使用,建议使用binlog_space_limit代替。该参数与relay-log-space-limit一致,主要作用于relay log;两个参数有相同的语义用法。
从5.7.23-23开始,在Innodb系统表空间和并行写缓冲区可以实现加密数据。该特征被命名为ALPHA quality。一个新的变量innodb_sys_tablespace_encrypt,被用来加密系统表空间。并行双写缓冲区文件的加密是由变量innodb_parallel_dblwr_encrypt控制的,这两个参数默认都是关闭的。
rocksdb_update_cf_options将原来的告警信息和错误信息打印至系统错误日志改为在客户端返回。
rocksdb_number_stat_computers 和 rocksdb_rate_limit_delay_millis这两个参数已经废弃。
同时,MyRocks新加入了一些新的参数。
rocksdb_rows_filtered用来显示在MyRocks表中被TTL过滤掉的行数。
rocksdb_bulk_load_allow_sk用来添加使用批量加载特性的辅助索引。
更多信息可以参考:
https://www.percona.com/blog/2018/09/12/percona-server-for-mysql-5-7-23-23-is-now-available/
RocksDB 5.15.10发布了,RocksDB是一个来自Facebook的可嵌入的支持持久化的key-value存储系统,也可作为C/S模式下的存储数据库。RocksDB基于LevelD构建。
更新内容如下:
Bug Fixes:
修复RocksDB Java构建和测试。
发布公告:
https://github.com/facebook/rocksdb/releases/tag/v5.15.10
RocksDB的详细介绍:
https://www.oschina.net/p/rocksdb
在微软Ignite 2018大会上,微软发布全新SQL Server 2019公开预览版。DBMS的承诺是,企业将能够在一个产品中同时管理其关系数据库及其非关系数据库。微软表示,它改进了PolyBase,使其具有更多数据源的连接器,包括“Azure SQL数据仓库、Azure Cosmos DB、Mongo DB、Oracle和Teradata”。
一、版本更新
1、重大增强
增加JIT功能;
并行计算能力提升,hash join性能提升10倍以上,支持create index、create table as、create mview as等并行;
支持自治事务;
新增带默认值的字段,无需rewrite table,瞬间完成;
分区表新增hash分区支持。
2、tpc-c 1000W 103万tpmC

3、tpc-h 10G 160秒,200G 39分钟
二、插件动态
1、citus发布7.5
citus是PostgreSQL的一款sharding插件,目前国内苏宁、铁总、探探有较大量的使用。
https://github.com/citusdata/citus
2、postgis发布2.5 rc1
PostGIS是专业的时空数据库插件,在测绘、航天、气象、地震、国土资源、地图等时空专业领域应用广泛。同时在互联网行业也得到了对GIS有性能、功能深度要求的客户青睐,比如共享出行、外卖等客户。
http://postgis.net/
3、timescale发布1.0 rc1
timescale是PostgreSQL的一款时序数据库插件,在IoT行业中有非常好的应用。github star数目前有5000多,是一个非常火爆的插件。
https://github.com/timescale/timescaledb
三、衍生开源产品动态
1、agensgraph发布1.3.2版本
agensgraph是兼容PostgreSQL、opencypher的专业图数据库,适合图式关系的管理。
https://github.com/bitnine-oss/agensgraph
2、gpdb发布5.11
gpdb是兼容PostgreSQL的mpp数据库,适合OLAP场景。近两年,gpdb一直在追赶PostgreSQL的社区版本,预计很快会追上10的PostgreSQL,在TP方面的性能也会得到显著提升。
https://github.com/greenplum-db/gpdb
3、antdb发布3.2
antdb是以Postgres-XC为基础开发的一款PostgreSQL sharding数据库,亚信主导开发,开源,目前主要服务于亚信自有客户。
https://github.com/ADBSQL/AntDB
一、Greenplum 5.11介绍
Pivotal的Greenplum是基于MPP架构的数据库产品,它可以满足下一代大数据仓库和大规模的分析任务的需求。通过自动对数据进行分区以及多节点并行执行查询等方式,它使一个包含上百节点的数据库集群运行起来就像单机版本的传统数据库一样简单可靠,同时提供了几十倍甚至上百倍的性能提升。
除了传统的SQL,Greenplum还支持MapReduce,文本索引,存储过程等很多分析工具,所支持的数据量可以从上百GB到几百TB。5.11.0是小版本升级,包含了新功能及bug修复,具体介绍如下:
新增特性
gpbackup/gprestore支持增量备份和恢复
Gpbackup/gprestore工具支持对AO表生成增量备份,并对其进行恢复。当为分区表时,只有变化的分区数据会被备份和恢复。
gpbackup/gprestore支持新的插件
从5.11.0开始,gpbackup/gprestore正式支持了如下插件:
DD Boost 存储插件:通过–plugin-config参数可以指定将数据备份到Dell EMC Data Domain存储方案上,或者从其上面恢复数据。
S3存储插件:通过–plugin-config参数可以指定将数据备份到Amazon的S3存储方案上,或者从其上面恢复数据。
--plugin-config参数不再依赖–single-data-file或者–metadata-only参数。
NoSQL家族
MongoDB旨在通过以下技术基础,满足现代应用程序需求:
文档数据模型——向您展示数据处理的最佳方式。
分布式系统设计——让您可以智能地将数据放在您想要的位置。
统一的体验,带给您在任何地方运行的自由——让您的工作可根据未来需求进行拓展,并避免出现被供应商锁定的情况。
MongoDB 4.0是MongoDB发展进程中的重要里程碑。该版本建立在上述核心技术基础之上,助力企业从此告别会阻碍企业发展速度的传统关系数据库、以及NoSQL数据库的高昂成本和复杂操作。MongoDB 4.0让您能够在单一现代化数据平台上对企业应用进行标准化。具体如下:
全新亮点:MongoDB Server 4.0和工具
支持多文档ACID事务:通过实施快照隔离,提供一致的数据视图,以及全部成功或全部失败的执行,以保持数据的完整性。现在,使用MongoDB解决各种用例都变得更加容易。
类型转换:让您可以在数据库中本地运行复杂的转换,为BI和机器学习准备数据,同时消除昂贵、缓慢而又脆弱的ETL进程。
经过改进的分片平衡器:将数据迁移速度提高了40%,这是由于集群会根据动态工作负载进行弹性扩展和收缩。
聚合管道构建器:助力开发人员和数据分析人员构建、优化和部署用于转换、聚合和分析MongoDB数据的复杂处理管道,所有这些工作全部在简单直观的MongoDB Compass图形用户界面中进行。
MongoDB Charts(测试版)是一种新的本机工具,让您可以创建和共享MongoDB数据的图表,而无需将数据转移到其他系统或第三方工具。这是实时了解操作数据最快捷、最简单的方式。
2018年8月31日,Neo4j发布了新版本 3.4.7,在性能和已有特性方面有了很大提升和增强,并增加了一些期待已久的新特性,此处列举一些3.4版本的重点特性:
实现了字符串类型属性的本地索引,因此对建立了索引的字符串属性,节点写入速度现在比现有字符串索引快5倍。
新的内核API简化了内部指令。
新支持的节点数据类型:日期/时间和3D地理空间数据,可针对时间或空间的搜索优化Cypher查询。Cypher查询可以使用3D地理空间的搜索,包括纬度和经度坐标、径向距离、高度或深度。
实现的各种效率改进(包括本机索引)将在整体上使事务执行消耗更少的内存。
内部测试表明,Cypher运行时间比Neo4j 3.3(Community Edition)快20%。
Neo4j 3.5版本即将发布,将为下一代人工智能和机器学习系统提供动力。
ArangoDB 3.3.16发布了,ArangoDB是一个原生的多模型数据库,具有灵活的文档、图形和键值数据模型。使用方便的SQL查询语言或JavaScript扩展构建高性能应用程序。
更新内容可以查看更新日志和提交记录了解:
更新日志
https://github.com/arangodb/arangodb/blob/devel/CHANGELOG
提交记录
https://github.com/arangodb/arangodb/compare/v3.3.16...devel
ArangoDB 的详细介绍:
https://www.oschina.net/p/arangodb
NewSQL家族
TiDB是一款定位于在线事务处理/在线分析处理(HTAP: Hybrid Transactional/Analytical Processing)的融合型数据库产品。除了底层的RocksDB存储引擎之外,分布式SQL层、分布式KV存储引擎(TiKV)完全自主设计和研发。
TiDB完全开源,兼容MySQL协议和语法,可以简单理解为一个可以无限水平扩展的MySQL,并且提供分布式事务、跨节点JOIN、吞吐和存储容量水平扩展、故障自恢复、高可用等优异的特性;对业务没有任何侵入性,简化开发,利于维护和平滑迁移。
TiDB 2.1 RC2 Release
2018年9月14日,TiDB发布2.1 RC2版。相比2.1 RC1版本,该版本对系统稳定性、优化器、统计信息以及执行引擎做了很多改进。
SQL优化器:
新版Planner设计方案#7543
提升常量传播优化规则#7276
增强Range的计算逻辑使其能够同时处理多个`IN`或者等值条件#7577
修复当Range为空时,`TableScan`的估算结果不正确的问题#7583
为`UPDATE`语句支持`PointGet`算子#7586
CockroachDB于10月30号即将发布2.1版本,主要有如下特性:
相比2.0版本,TPCC性能有30%的提升;
支持CBO(cost-based optimizer)优化器,AP性能显著提升;
支持任意时间点的备份恢复;
UI功能增强,可以显示查看用户SQL的统计情况;
支持CDC特性,保证数据变更实时同步至Kafka;
支持用户数据透明加密;
即将发布CockroachDB云服务。
大数据生态圈
8月9日,Hadoop发布3.1.1版本,这是Hadoop 3.1分支的第一个稳定的版本,修复并改进了自3.1.0版本以来的总共435个bug与功能。
1、对于计算框架Yarn
新版本的Yarn的服务框架对长期运行的本地服务,提供更好的api与支持。简而言之,它作为一个容器编排平台,用于管理YARN上的容器化服务。 它支持YARN中的docker容器和传统的基于进程的容器。具体体现在:
YARN-6223. Yarn支持GPU的调度与隔离(Docker和非Docker容器)
YARN-5983. Yarn支持FPGA的调度与隔离(Docker和非Docker容器)
YARN-6592. 在YARN中支持更能提升资源使用的放置约束。 这些约束对于应用程序的性能和弹性至关重要,尤其是那些包含长期运行容器,例如离线计算服务,机器学习和流式计算服务。在同一机架上调度有关联的任务(相似性约束)可以降低网络成本,在机器之间分配任务(反亲和约束)以便降低资源干扰,或者限定特定节点组的任务数量(基数约束)以在两者之间取得平衡。 放置的策略现在影响面也是弹性化的。例如,放置在同一群集升级域中的机器将同时脱机。
YARN-5881. 支持管理员为队列指定具体数目的资源(比如具体的内存数量、vcore 核数、GPU 等),而不是提供基于百分比的值,这让管理员能够更好地控制给定队列配置所需的资源。
YARN-7117. 容量调度器:在进行队列映射的时候,支持自动的创建叶队列。
2、对于存储框架HDFS
提供了允许将存储在HDFS之外的数据映射到HDFS,并从HDFS进行寻址。这是一种异构存储,通过向DataNode中引入新的存储类型 PROVIDED来实现。
可以通过访问如下网址了解更详细的版本变更内容:
http://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-common/release/3.1.1/RELEASENOTES.3.1.1.html
ElasticSearch 6.4.1已发布,Elasticsearch是一个分布式的RESTful风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为ElasticStack的核心,它集中存储你的数据,帮助你发现意料之中以及意料之外的情况。
这是一个很小的修复版本,解决了以下问题:
Elasticsearch can once again start if any shards on the node have been rolled over. #33394
下载地址:
https://www.elastic.co/downloads
2018年8月15日,Apache HAWQ正式结束孵化并毕业为Apache顶级项目。
2018年9月21日,Apache HAWQ社区发布了毕业后的第一个正式版本, Apache HAWQ 2.4.0.0。其中值得关注的新特性有:
增加了全新的向量化执行引擎,通过对元组进行批量操作来提升计算效率,经测试开启向量化执行后聚集操作效率可提高2-8倍。
增加了Bloom Filter功能:HAWQ在执行Hash Join时为参与Join的build表创建一个Bloom Filter,在扫描probe表时用Bloom Filter过滤掉大量数据,减少参与probe阶段的数据量,从而提升Hash Join的效率。
HAWQ PXF新增了一个Ignite database插件: PXF可以通过Ignite原生的REST API进行读写操作。
详细发布文档见:
https://cwiki.apache.org/confluence/display/HAWQ/Apache+HAWQ+2.4.0.0+Release
2018年9月18日,Druid发布了0.12.3版本,包含了来自6位贡献者的多项稳定性提升以及Bug修复,主要的改进如下:
更加稳定的Kafka Indexing Service;
查询Bug修复。
1、更加稳定的Kafka Indexing Serivce
0.12.3修复了Kafka Indexing Service在某些场景下会错误地删除已经发布了的Segment的严重问题,同时还修复了两个空指针异常的问题。
2、查询bug修复
0.12.3优化了groupby查询的内存配置减少了堆内内存的使用,该项共享来自美团的高大月。在这个版本中同时包含了Topn和GroupBy查询中数值类型维度的使用outputType的多个Bug修复,以及多个Druid SQL的Bug修复:
修复TIMESTAMP类型的精度问题
修复AND、OR只支持两个参数的问题
在Filter中消除无用的布尔类型的CAST
SQL支持先排序然后再projection
JDBC增加BOOLEAN类型
修复了Timeseries和TopN查询中的post aggregation在执行计划中丢失的问题
在子查询中支持复杂aggregation(例如HyperUnique)
国产数据库概览
2018年7月1日,K-DB发布集群数据库版本。其特点如下:
1、K-DB集群数据库采用全新的高性能DB Server、超高速网络Infiniband、智能型Storage Server三层架构,具备了专注处理海量数据存储和大批量实时数据处理的能力。
2、K-DB集群数据库支持Function Offloading,其Storage Server不仅具有磁盘的I/O功能,还承担部分数据库业务,如过滤 (Filtering) 或投影 (Projection) ,从而大幅提高数据库的性能。
3、支持存储数据映射 (Storage Data Map) 功能,大幅提高磁盘使用率。磁盘内的数据统计值被访问过一次后,访问记录会保存在内存中,再次访问该磁盘时,可以减少不必要的磁盘读取。
4、支持Flash Cashing功能,可利用闪存设备 (Flash Device) 进行I/O缓存分层 (Cache Tiering)。如果硬件中有闪存设备的话,可以利用它进行I/O分层,即闪存设备用作I/O缓存。在OLTP环境下,反应速度极快。如果用户愿意,闪存设备还可以像普通HDD一样使用。
5、支持InfiniBand接口,提供高带宽、高性能网络访问能力。K-DB集群数据库默认使用InfiniBand。InfiniBand以高带宽著称,与Fiber channel构成的SAN相比,高于其数百倍。
6、支持应用RDMA协议,缩短通信延迟时间。K-DB集群数据库默认使用RDMA协议交换节点间的数据,由此大幅缩短通信延迟时间,降低CPU使用率。
以下是从分布式架构、数据可用性、可运维性、兼容性、性价比五个方面对OceanBase 2.0版本的主要产品特性及技术革新的解读:
1、业务透明的分布式系统
支持全局一致性快照:Global Timestamp Service实现外部一致性,打造业务透明的分布式架构;
支持全局索引:有效支持分区表的多维度查询,数据库原生的表和索引数据一致性保证;
负载均衡:同样的硬件资源、更高的TPS/QPS、更短响应时间索引实时生效。
2、数据持续可用
索引实时生效:索引生效和每日合并解耦,及时满足业务对新索引的需求;
支持闪回查询:快速查询数据历史版本,有效应对人为误操作;
支持在线分区分裂:将单分区数据打散到多个节点,有效解决业务发展带来的扩展性问题。
3、可运维性增强
支持DB Replay功能:真实业务流量回放,为系统升级保驾护航;服务全链路压测,保障“大促”丝般顺滑体验;
支持在线升级:平滑升级、可灰度、可回滚;
新版本云管控平台OCP 2.0发布:更少资源占用、更少外部依赖、更好用。
4、性价比提升
OLTP场景性能较1.4版本提升50%以上,存储成本下降30%。
5、兼容性提升
支持MySQL / Oracle 双兼容模式;
第一款支持存储过程的原生分布式数据库。
9月7日,SequoiaDB 3.0对MySQL兼容的机构以及兼容工具SequoiaSQL正式向社区开源。
SequoiaSQL此前是SequoiaDB数据库的SQL解析模块,在经过1.0~3.0的发展,SequoiaSQL组件也实现了PostgreSQL、MySQL的兼容。
MySQL的分布式改造目前也是包括互联网行业在内的多个行业的一个共性需求,因此巨杉也决定将SequoiaSQL组件开源,一方面是将这一个MySQL的分布式方案和工具提供给业界和社区,解决更多应用中实际的数据库痛点;另一方面,也希望项目的开源,可以让社区参与到项目中,未来可以一同实现工具的通用化。
项目目前已经实现MySQL、PostgreSQL的支持,在未来,还会实现MairaDB的兼容支持,并且实现更多存储引擎的兼容对接。
SequoiaDB 3.0目前在MySQL兼容上,主要也是采取“SQL-存储分离“的架构。
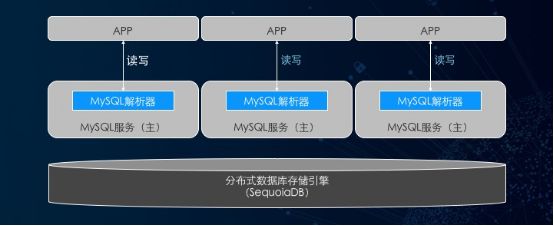
SequoiaDB 3.0 MySQL 兼容架构
SequoiaDB 3.0使用了MySQL数据库原生的SQL解析器,天然支持MySQL协议并可以做到100%语法兼容。在该架构中,MySQL协议解析层作为SQL解析和分发的角色,直接面对应用程序,每一个MySQL服务的接入节点都是一个独立支持读写操作的MySQL进程。而数据存储和管理层,则完全由巨杉数据库的分布式数据库引擎实现。简单来说,SequoiaDB 3.0作为MySQL的InnoDB替换引擎,在天然支持MySQL的全部语法和功能的同时,提供了数据库存储层弹性扩张的能力。
开源项目地址:github.com/sequoiadb/sequoiasql-mysql
本期新内容:云数据库
TDSQL简介腾讯分布式数据库(Tencent Distributed SQL)是由腾讯打造的一款高可用、强一致性、高性能的分布式数据库产品。目前广泛应用于腾讯集团及腾讯云客户,为超过500+金融政企客户提供数据库服务,覆盖金融、政务、新零售、游戏等多个行业。
一、RocksDB
TDSQL提供稳定、可靠的RocksDB存储引擎。RocksDB 是一种基于LSM树的存储引擎,其数据压缩率领先InnoDB引擎,极大节省数据库使用成本,对写入性能也有较大提升,适合物联网、日志等“写多读少”,且对容量比较敏感的业务场景。
1、解决RocksDB在某些场景下宕机重启回放事务的bug和索引查询的bug,解决RocksDB在分布式架构下相关的bug:
事务回放写锁改读锁;
修复使用utf8_binary,索引数据被截断的问题。
2、实现trace log功能:
跟踪事务的执行流程,用于监控和性能分析。
3、实现write prepared机制:
优化大事务的内存,提前释放事务的内存;
支持分布式事务。
二、TDSpark
TDSpark是TDSQL推出的为了解决用户复杂OLAP需求的解决方案。借助Spark平台本身的优势,同时融合TDSQL分布式集群的优势,为用户一站式解决HTAP需求。
1、深度整合了Spark Catalyst引擎, 使Spark能够高效的读取TDSQL中的数据,以支持OLAP分析类请求;
2、兼容MySQL协议。
三、智能DBA“扁鹊系统”
智能DBA“扁鹊系统”基于自身的规则策略库,专注于定位、分析数据库故障以及SQL性能问题,并利用机器学习手段不断积累DBA成熟经验,服务于云上企业。
四、冷备系统优化
TDSQL提供对误删除的实例通过回档恢复功能从冷备系统恢复到删除前实例状态,减少业务不可用时间,提高系统可维护性。回档恢复时,采用贪心算法进行资源快速匹配,重设资源调度策略,优化回档空间。
五、读写分离优化
TDSQL提供多种读写分离模式,将用户的读请求转发给合适的备DB(系统提供多种选择备机的策略),降低主DB的负载,提高系统的读写性能。优化开启全局读写分离策略时,对于事务的处理策略:事务SQL不进行读写分离。
六、T-TDSQL全时态数据库系统
基于TDSQL的T-TDSQL全时态数据库系统发布正式版,更新关注的新特性有:
提供有效时间时态、事务时间时态功能支持,有效支持合同管理、履历管理、数据分析等业务的应用;
提供数据的全生命周期管理(数据全时态生命周期,数据生命状态包括当前态、过渡态、历史态。传统的数据库只包含当前态数据);
在数据库内核层支持增量数据抽取、增量数据计算功能,替代传统的ETL模式;
在数据库内核层支持互联网等业务金融对帐服务,有效提高对帐的精度和准确度,并高效核对总账、精准核对每一笔细账;
高效的数据闪回功能(准备提交MySQL官方社区),DBA不用再担心误删除数据库而仓皇跑路;
具备数据重演、多维度分析的潜能,赋予数据更多、更大的价值。
2018年9月20日,MyNewSQL领域的RadonDB云数据库发布1.0.1版本。
RadonDB是一款基于MySQL研发的新一代分布式关系型数据库(MyNewSQL)。向用户提供具备金融级高可用、强一致、超大容量的数据库服务,高度兼容MySQL语法,自动水平分表,智能化扩容。
RadonDB具有以下特性:
自动水平分表;
数据多副本,率先使用GTID并行复制+Raft一致性协议确保副本间数据强一致、零丢失;
主副本故障自动秒级切换,实现自动化运维,无需人工干预;
存储副本使用MySQL存储,稳定可靠的存储能力与强大的计算能力并存;
提供分布式事务能力,保证跨节点操作的数据一致性;
同时支持OLTP(高并发事务需求)和OLAP(复杂分析需求);
高度兼容MySQL语法,数据可快速导入、导出,简单易用。
本次发布的v1.0.1版本是RadonDB的一个小版本, 主要对监控进行了改善:支持用户级连接监控、后端信息、各种操作统计信息、慢查询等各种维度监控,时序数据库Prometheus存储监控和性能指标信息,用Grafana作为可视化组件展示。
RadonDB已全部开源在github, 包含两大核心组件:
Radon
负责接收SQL请求并生成分布式执行计划, 把请求路由到相关的MySQL副本。
https://github.com/radondb/radon
Xenon
使用GTID并行复制+Raft一致性协议实现的MySQL高可用集群管理工具。
https://github.com/radondb/xenon
推出dbaplus Newsletter的想法
dbaplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、时间序列、大数据生态圈、国产数据库、云数据库等版块。
我们不以商业宣传为目的,不接受任何商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎大家监督指正。
至于Newsletter发布的周期,目前计划是每三个月左右会做一次跟进,下期计划时间是2019年1月14日~1月25日,如果有相关的信息提供请发送至邮箱:newsletter@dbaplus.cn
感谢名单
最后要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后。

欢迎提供Newsletter信息,
发送至邮箱:newsletter@dbaplus.cn
Github地址:
https://github.com/dbaplus/DBAplus_Newsletter
欢迎技术文章投稿,
发送至邮箱:editor@dbaplus.cn
往期回顾:








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721