
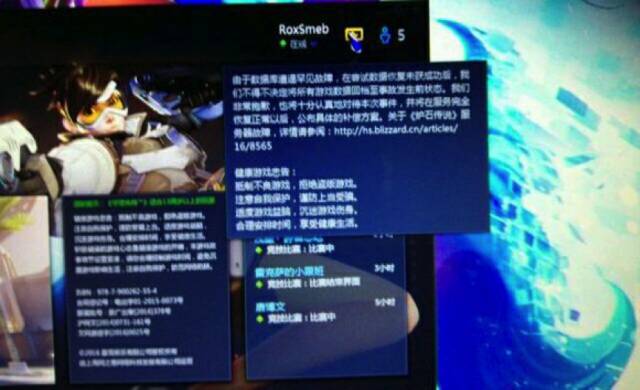
看到我这标题,千万别以为我是故意为了吸引你的眼球,而是官方这么说的哦:
这里用到个词—“回档”,今天第一次听说,最开始不理解啥意思,接着恍然大悟,不就是Oracle 9i开始提供的新特性Flashback么!
你的朋友圈是不是也被刷屏了
昨天大概6点左右开始,我的朋友圈被刷屏了。

结合贴吧的一些留言,简单回顾下大体过程:
1月14日15:20开始,数据库由于供电异常中断,数据损坏。
接着数据库带病工作2天。
1月16日凌晨开始进行修复维护。
1月17日下午,维护时间超过30小时,数据“修复”失败,丢失数据超过30%,接着发出上述故障公告。
接着在多玩网站,一位自称曾是“天下3”的维护者透露:
“你们以为数据都在服务器里? 服务器只有硬件而已,硬盘数据13年-16年都是用的DELL的磁盘阵列服务器,而且是双机热备+异地容灾,我这台数据丢了,我另一台会有克隆的相同的数据。就算广州整个机房炸了,我上海机房异地也会有一台克隆的数据。
所以数据丢了,数据丢了30%什么,大家就不要信了。
我在做天下3运维的时候也遇到过N种问题,不过都被总监、经理他们这些人带着解决了。
可以说,就算来个10岁的小朋友,会动电脑鼠标看得懂字,按照流程都不会出问题。一个团队4个人,一个经理, 5个人同时犯错?怎么可能因为操作失误就丢30%数据?”
同时,另一位网友号称是内部消息,说是服务器人为操作失误。
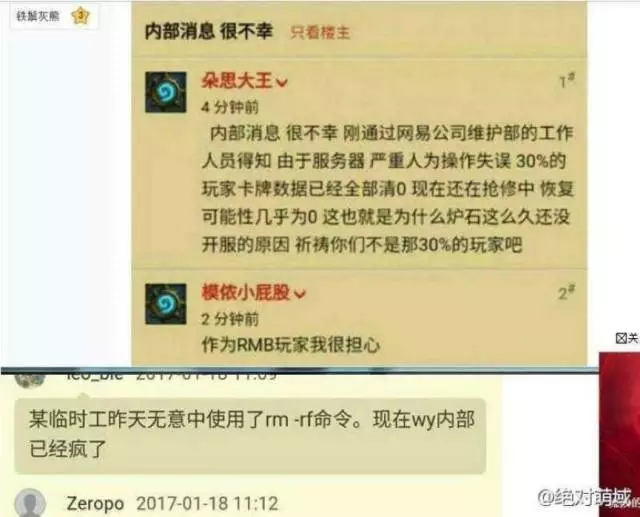
嗯。其实你肯定看不到真实原因了,我只是在告诉你架构和维护的基本知识。
我们从几个不同的角度来解读这个问题。
老杨是运维界的老司机,而据了解涉及的库可能是Oracle,我们来看看从这个角度来分析,问题可能在哪些地方。
同时有双机热备+异地容灾,当然还应该有备份(哦,公告里说,备份数据也损坏了!),数据还是丢了30%,这又中了墨菲定律!
那么这个架构的问题在哪里?
从我的经验来看,这本身的架构有问题:
备份几乎应该是假的!別懵,难道你家的所有数据库最近3个月做过恢复演练么?没有做过,就有可能是假的!书到用时方恨少,数据要恢复时方恨没有做演练!
双机热备(或者是RAC)+异地容灾,对于一个想当然的情况来说,是可以的。但是,在16年的Salesforce文章《Salesforce数据库故障丢失5小时数据,仅仅是个案?》中我就提过,你还是图样图森破了。你至少应该再搭建个DG,延时应用。如果你真做了就不可能丢失30%数据!
其次,公告中说,是由于机房掉电导致的故障。说得非常合理,我们经常遇到这样的故障。犹记得,14年初,某运营商春节前夕,机房掉电,存储拉不起来,主机起不来,数据库起不来…..但是,但是,但是,因为有我们,整个故障零数据丢失,连夜调配专家把系统给修好了,天亮睁开眼睛,对于广大吃瓜群众来说,是无感知的。
绝大部分的供电突然中断,导致的数据库故障,都是相对容易能解决的。极端情况下,可能要丢一部分数据,但绝不至于30%。
那么,唯一的可能原因,就是人为误操作了!
我在贴吧看到,这个故障的影响,貌似没那么大,大多数是说这几天打了多少关,充了几百块钱……
炉石传说这样的数据库架构,在银行、在运营商、在保险公司,并不少见。但是,如果这样的30%数据丢失,在任何一个这样的公司里,恐怕不只是DBA、运维负责人会没有年终奖,公司总裁都得下课吧!
而建荣猜测这个数据库是MySQL的,会从游戏架构和基本的备份恢复对问题做一些解读,仅供参考,当然反思的更多是问题所带给我们的启示。
首先专门下载这个游戏看了下,它分为PC版,IPhone和Android版,换句话说,是端游(PC版下载需要250MB左右)和手游并存的情况。可以间接说明这款游戏还是蛮火爆的。

对很多游戏来说,都会存在大体如下的架构模式,图片引用自《腾讯互娱架构师谈游戏服务器缓存系统怎么造》。
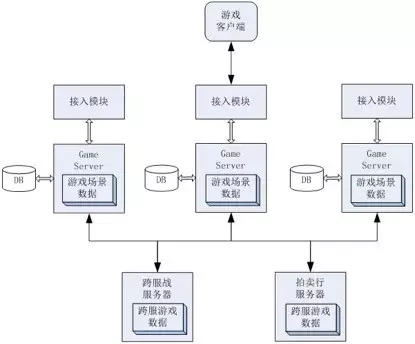
上面的方式表明在游戏中存在着大量的GS(Game Server),玩家的数据是存放在GS中的,比如你去玩游戏时,登录的某个服,可能就是在某个具体的GS上,而各个GS之间的信息一般是不会共享的,而且基本上表结构信息是相同的,所以也就直接实现了分库分表的方式,这种方式采用MySQL就是一件很自然的事情。而接入模块和更多的账号,充值信息等,可能会有大平台或者是相对独立的数据库。
所以描述中说的30%的数据,要不就是某个服的数据丢失,或者是丢失了指定时间点的数据库日志,估且按照30%来算。而且再说一句,那就是游戏里的cache其实做得已经很不错了,宕机的时间不是很长,其实对于数据库来说影响不是很大,因为玩家的数据都在缓存里,如果耽误太长时间,数据落盘的时候才会有直接影响。
有一点需要说明,其实运维行业是很难杜绝丢数据的,不管你接受还是反对。
我听过很多行业的运维同仁达成的一个基本观点就是丢数据是可以接受的,但是数据不能乱,数据丢了可以补啊,但是乱了,这个复杂度就会提高几个量级。因为是个虚拟的世界,这个场景相对特殊一些,所以游戏行业里有一种说法就是回档,把所有的数据恢复到一个指定的时间点,而给玩家一些补偿。这个过程会给游戏运营来说,相对也会好一些,毕竟一个爆款的游戏每个小时的流水是相当不错的,你说让长达几十个小时去恢复,换做谁都不可以接受。说句实在的,有些核心业务宕机个把小时都要被骂得狗血淋头,几十个小时,那肯定是有一些更复杂的原因。
对于数据恢复,我听过很多Oracle数据恢复场景,数据库是直接无法Open了,无法Open就意味着完全不可用,一个基本要求就是把数据库至少拉起来,而数据恢复是在这个基础之上的事情,至于是不是零数据丢失,这个就不太肯定了。而MySQL是没有这种状态的严格标示的,所以恢复也是在这个基准之上。哪一类场景比较麻烦呢,那就是人为错误,误删数据等。这个恢复起来非常复杂,而且退一步说,哪怕数据现在修复了,你能肯定数据100%没问题?所以从运营和稳定安全的角度来说,其实出现这种故障,如果增量恢复有问题,应急策略还是更倾向于回档。
游戏行业相对来说还是挺激进的,很多游戏都会大规模开始部署云服务(云服务器或者RDS),如果大家用过一些云厂商的RDS就会知道,连从库都不用搭建了,所以备份恢复的事情是肯定不需要自己操心的,一旦出了问题,恢复是相对来说较为容易的事情,而如果有了问题,那背锅侠也不是运营方而是云厂商了。而如果使用云服务器,除非有什么特殊的场景,否则还不如直接用RDS方便和实惠。而这里就会有一个折中,那就是性能和网络,还有安全,所以有些对于性能要求高的游戏可能会更侧重于高配的服务器,或者高配的RDS。从这个案例的描述来看,感觉不像是使用了云服务。
这里我想到几个不是逻辑的逻辑,有时候是糊弄自己,有时候是被糊弄。做运维其实心里也苦。
数据量太大,所以不做备份。数据重要吗,很重要,那为什么没备份?
系统也很稳定,要备库干什么,就是个摆设,多浪费,缩减一下预算吧。
服务器现在已经过保了,得换一台新机器了。那现在服务器不是好好的吗?
即使你的数据库架构有问题,也过了年后再说吧!
但你至少得在春节前做好这几件事:
对你的系统做一次深入的大排查。
及时修正排查到的隐患。
抓紧完成核心系统恢复演练。(非核心的估计来不及了。真出问题,你就认了吧!)
封网!不必要的变更,统统禁止。
不要存在侥幸心理,墨菲定律就在我们身边。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721