
2016年1月28日,Google Deepmind在Nature上发文宣布其人工智能围棋系统AlphaGo历史性的战胜人类的职业围棋选手!这条重磅新闻无疑引起了围棋界和人工智能界的广泛关注!3月份AlphaGo对阵李世石的比赛更将引起全人类的目光!
是什么使围棋算法产生了质的飞跃?要知道,在之前最好的围棋程序也只能达到业余人类棋手的水平。是真的人工智能产生了吗?
对于大多数人来说,大家都知道1997年的“深蓝”计算机战胜了人类的国际象棋冠军卡斯帕罗夫,但是大家都不会认为“深蓝”真正拥有了人工智能,道理非常简单:国际象棋(当然围棋也是)每一步都是可见的,在一个确定性的棋局下,仅有有限个走法。这有限个走法中必然有一个最优的。一个基本的想法就是对棋局进行预测,遍历每一种走法直到一方胜出,然后回退计算每一个可能赢的概率,最后使用概率最高的作为最优的走法。“深蓝”就做了这么件事,暴力穷举所有的步子,然后找最优!赢了人类,但没有智能,因为整个算法完全就是人工设计的一个算法,根本看不到智能在哪里。
显然围棋理论上也可以暴力破解,但是问题就在于围棋的可走的步子太多了,以至于目前的计算性能根本做不到暴力破解。这也就是为什么围棋是挡在人工智能面前的一个重大挑战。
1、要使围棋程序战胜人类顶尖高手,只有依靠真正的人工智能!
对围棋有了解的朋友都知道下围棋需要对整个棋局有直观的理解,这就是围棋困难的地方。除非计算机真正理解了棋局,才有可能有大局观,才有可能下出真正的好棋!
那么,问题来了:
AlphaGo 有真正的人工智能吗?
我的回答:
AlphaGo有真人工智能,虽然还不完美!
那么
AlphaGo的真人工智能在哪里?
我的回答:
就在深度神经网络之中
一切的答案都在Google Deepmind在Nature上发表的文章:
Mastering the Game of Go with Deep Neural Networks and Tree Search论文链接
本文将分析AlphaGo的这篇Nature文章,去解密真人工智能的奥秘!
AlphaGo的”大脑“是怎样的
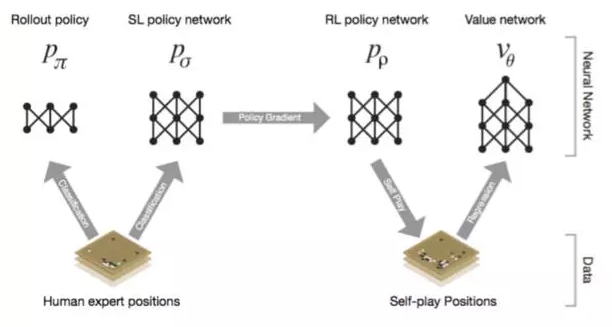
深度神经网络是AlphaGo的”大脑“,我们先把它当做一个黑匣子,有输入端,也有输出端,中间具体怎么处理先不考虑。那么AlphaGo的”大脑“实际上分成了四大部分:
Rollout Policy 快速感知”脑“:用于快速的感知围棋的盘面,获取较优的下棋选择,类似于人观察盘面获得的第一反应,准确度不高
SL Policy Network 深度模仿”脑“:通过人类6-9段高手的棋局来进行模仿学习得到的脑区。这个深度模仿“脑”能够根据盘面产生类似人类棋手的走法。
RL Policy Network 自学成长“脑”:以深度模仿“脑”为基础,通过不断的与之前的“自己”训练提高下棋的水平。
Value Network 全局分析“脑”:利用自学成长“脑”学习对整个盘面的赢面判断,实现从全局分析整个棋局。
所以,AlphaGo的“大脑”实际上有四个脑区,每个脑区的功能不一样,但对比一下发现这些能力基本对于人类棋手下棋所需的不同思维,既包含局部的计算,也包含全局的分析。其中的Policy Network用于具体每一步棋的优劣判断,而Value Network则对整个棋局进行形势的判断。

而且很重要的是,AlphaGo提升棋力首先是依靠模仿,也就是基于深度模仿“脑”来进行自我水平的提升。这和人类的学习方式其实是一模一样的。一开始都是模仿别人的下法,然后慢慢的产生自己的下法。
那么这些不同的脑区的性能如何呢?
快速感知“脑”对下棋选择的判断对比人类高手的下棋选择只有24.2%的正确率
深度模仿“脑”对下棋选择的判断对比人类高手的下棋选择只有57.0%的正确率,也就是使用深度模仿“脑”,本身就有一半以上的几率选择和人类高手一样的走法。
自学成长“脑”在经过不断的自学改进之后,与深度模仿“脑”进行比赛,竟然达到80%的胜利。这本质上说明了通过自我学习,在下棋水平上取得了巨大的提升。
全局分析“脑”使用自学成长“脑”学习训练后,对全局局势的判断均方差在0.22~0.23之间。也就是有大约80%的概率对局面的形势判断是对的。这是AlphaGo能够达到职业棋手水准的关键所在。
从上面的分析可以看到AlphaGo的不同“脑区”的强大。具体每个大脑是怎么学习的在之后的小节分析,我们先来看看有了这些训练好的大脑之后AlphaGo是如何下棋的。
在分析AlphaGo是如何下棋之前,我们先来看看一下人类棋手会怎么下棋:
Step 1:分析判断全局的形势
Step 2:分析判断局部的棋局找到几个可能的落子点
Step 3:预测接下来几步的棋局变化,判断并选择最佳的落子点。
那么,AlphaGo在拥有强大的神经网络”大脑“的基础上采用蒙特卡洛树搜索来获取最佳的落子点,本质上和人类的做法是接近的。

首先是采用蒙特卡洛树搜索的基本思想,其实很简单:
多次模拟未来的棋局,然后选择在模拟中选择次数最多的走法
AlphaGo具体的下棋基本思想如下(忽略掉一些技术细节比如拓展叶节点):
Step 1:基于深度模仿“脑” 来预测未来的下一步走法,直到L步。
Step 2:结合两种方式来对未来到L的走势进行评估,一个是使用全局分析“脑”进行评估,判断赢面,一个是使用快速感知“脑”做进一步的预测直到比赛结束得到模拟的结果。综合两者对预测到未来L步走法进行评估。
Step 3:评估完,将评估结果作为当前棋局下的下一步走法的估值。即给一开始给出的下一步走法根据未来的走向进行评估。
Step 4 :结合下一步走法的估值和深度模仿脑进行再一次的模拟,如果出现同样的走法,则对走法的估值取平均(蒙特卡洛的思想在这里)
反复循环上面的步骤到n次。然后选择选择次数最多的走法作为下一步。
说的有点复杂,简单的讲就是综合全局和具体走法的计算分析,对下一步棋进行模拟,找到最佳的下一步。对步子的选择,既要依赖于全局分析“脑”的判断,也需要深度模仿“脑”的判断。
分析到这里,大家就可以理解为什么在AlphaGo与Fan Hui的比赛中,有一些AlphaGo的落子并不仅仅考虑局部的战术,也考虑了整体的战略。
知道了AlphaGo的具体下棋方法之后,我们会明白让AlphaGo棋力如此之强的还是在于AlphaGo的几个深度神经网络上。
所以,让我们看看AlphaGo的大脑是怎么学习来的。
AlphaGo的学习依赖于深度学习Deep Learning和增强学习Reinforcement Learning,合起来就是Deep Reinforcement Learning。这实际上当前人工智能界最前沿的研究方向。
关于深度学习和增强学习,本文不做详细的介绍。深度神经网络是由巨量的参数形成的一个多层的神经网络,输入某一种类型的数据,输出某一种特定的结果,根据输出的误差,计算并更新神经网络的参数,从而减少误差,从而使得利用神经网络,特定的输入可以得到特定想要的结果。
以深度模拟“脑”为例。这个实际上是一个12层的神经网络。输入主要是整个棋盘的19*19的信息(比如黑棋的信息,白棋的信息,空着的信息,还有其他一些和围棋规则有关的信息一共48种)。输出要求是下一步的落子。那么Google Deepmind拥有3000万个落子的数据,这就是训练集,根据输出的误差就可以进行神经网络的训练。训练结束达到57%的正确率。也就是说输入一个棋盘的棋局状态,输出的落子有一半以上选择了和人类高手一样的落子方式。从某种意义上讲,就是这个神经网络领悟了棋局,从而能够得到和人类高手一样的落子方法。
换另一个角度看会觉得AlphaGo很可怕,因为这个神经网络本来是用在计算机视觉上的。神经网络的输入是棋盘,就类似为AlphaGo是看着棋盘学习的。
接下来的自学成长“脑”采用深度增强学习(deep reinforcement learning)来更新深度神经网络的参数。通过反复和过去的“自己”下棋来获得数据,通过输赢来判断好坏,根据好坏结果计算策略梯度,从而更新参数。通过反复的自学,我们看到自学成长“脑”可以80%胜率战胜深度模仿“脑”,说明了这种学习的成功,进一步说明自学成长“脑”自己产生了新的下棋方法,形成了自己的一套更强的下棋风格。
说到这,大家可以看到真人工智能来源于神经网络,具体神经网络的参数为什么能够表现出智能恐怕无人知晓?智能到底是什么还需要等待答案。
深度神经网络是人工智能的黎明!
下面简单介绍一下蒙特卡罗算法和拉斯维加斯算法的区别
蒙特卡罗算法并不是一种算法的名称,而是对一类随机算法的特性的概括。媒体说“蒙特卡罗算法打败武宫正树”,这个说法就好比说“我被一只脊椎动物咬了”,是比较火星的。实际上是ZEN的算法具有蒙特卡罗特性,或者说它的算法属于一种蒙特卡罗算法。
那么“蒙特卡罗”是一种什么特性呢?我们知道,既然是随机算法,在采样不全时,通常不能保证找到最优解,只能说是尽量找。那么根据怎么个“尽量”法儿,我们我们把随机算法分成两类:
蒙特卡罗算法:采样越多,越近似最优解;
拉斯维加斯算法:采样越多,越有机会找到最优解;
举个例子,假如筐里有100个苹果,让我每次闭眼拿1个,挑出最大的。于是我随机拿1个,再随机拿1个跟它比,留下大的,再随机拿1个……我每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但我除非拿100次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找好的,但不保证是最好的。
而拉斯维加斯算法,则是另一种情况。假如有一把锁,给我100把钥匙,只有1把是对的。于是我每次随机拿1把钥匙去试,打不开就再换1把。我试的次数越多,打开(最优解)的机会就越大,但在打开之前,那些错的钥匙都是没有用的。这个试钥匙的算法,就是拉斯维加斯的——尽量找最好的,但不保证能找到。
所以你看,这两个词并不深奥,它只是概括了随机算法的特性,算法本身可能复杂,也可能简单。这两个词本身是两座著名赌城,因为赌博中体现了许多随机算法,所以借过来命名。
这两类随机算法之间的选择,往往受到问题的局限。如果问题要求在有限采样内,必须给出一个解,但不要求是最优解,那就要用蒙特卡罗算法。反之,如果问题要求必须给出最优解,但对采样没有限制,那就要用拉斯维加斯算法。
机器下棋的算法本质都是搜索树,围棋难在它的树宽可以达到好几百(国际象棋只有几十)。在有限时间内要遍历这么宽的树,就只能牺牲深度(俗称“往后看几步”),但围棋又是依赖远见的游戏,甚至不仅是看“几步”的问题。所以,要想保证搜索深度,就只能放弃遍历,改为随机采样——这就是为什么在没有MCTS(蒙特卡罗搜树)类的方法之前,机器围棋的水平几乎是笑话。而采用了MCTS方法后,搜索深度就大大增加了。
以上为知乎精选。
博主授权转载
来源:CSDN/songrotek的专栏
链接:blog.csdn.net/songrotek
全球敏捷运维峰会【杭州站】

2016 年4月16日,与你相约杭州,来一场敏捷与运维的美丽邂逅!DBA+社群联合三墩IT人开启全球敏捷运维峰会第一站:杭州站!峰会力邀来自互联网与传统企 业的资深专家,各路大咖齐聚,汇聚500+行业精英,聚焦架构、敏捷、运维三大主线,开启一场专属于IT人的年度之约!
专家阵容:或行业资深派、或著书力作派、或传统转型派、或一线实战派,总有一款是你喜欢!
绝对干货:聚焦架构、敏捷、运维三大主线,共讨传统企业在技术转型过程中的实践与困境、互联网企业在前沿技术方面的应用与心得、技术服务型企业在新老技术之间如何切换与落地,拒绝无营养的广告,绝对干货,精彩不容错过!
连接联动:汇聚社群数百顶级专家人脉,携数万社群成员声势,联合数十家媒体单位,共同打造一场连接敏捷与运维圈子的年度之约!
门票:免费!(限时限额)
VIP票:199元(限3月20日前)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721