
企业所处发展阶段不同,对支付系统的定位和架构也不尽相同。整体上来说,我们可以把一个公司的支付系统发展分为三个阶段:
支付系统:支付作为一个(封闭)的、独立的应用系统,为各系统提供支付功能支持。一般来说,这个系统仅限于为公司内部的业务提供支付支持,并且和业务紧密耦合。
支付服务:支付作为一个开发的系统,为公司内外部系统、各种业务提供支付服务。支付服务本身应该是和具体的业务解耦合的。
支付平台:支付作为一个可扩展的平台, 公司内外部的用户可以在此基础上定制开发自己的服务。
这个划分有点勉强。简单说,支付系统是仅供内部使用的,支付服务是支持公司内外部来调用的,支付平台是可以在服务的基础上定制各种场景支持的。
区分两个概念:支付和交易。支付是交易的一部分。一个简单的交易过程包括:客户下订单,客户完成支付,商家接收订单,商家出货。这里仅考虑下订单的流程。从软件工程的角度, 我们首先需要明确下几个参与者。
电商系统,指提供在线购物服务的系统。用户在这个系统中完成交易。
支付系统,可以是电商系统的一个模块,或者是个独立的系统。这是本文的主角,用来完成支付过程。
用户,在电商系统中败家的那位。如果使用银行卡做交易,那也被称为持卡人。
用户使用银行卡交易时,发行这个银行卡的机构称为发卡行,或者发卡机构。
商家也需要一张卡,就是大家在淘宝开网店的时候要登记的银行卡,最终需要把用户给的钱打到这张卡上。
和发卡机构相对应的,大家听到最多的是收单机构。如支付宝,微信等第三方支付公司,介绍业务的时候总少不了互联网收单的工作。它们把用户订单收起来,找发卡行要钱,就有了收单业务。
主演都有了,下面就是如何演出支付这场大戏了。正常的流程应该是这样:
1、用户提交订单到电商系统,电商系统对订单进行检验,无问题则调起支付接口执行支付。注意这里支付接口是在服务器端调起的。一般支付接口很少从客户端直接调起。为了安全,支付接口一般要求用HTTPS来访问,并对接口做签名。关于支付接口的设计,我将另起博文介绍。
2、支付系统检查参数有效性,特别是签名的有效性。
3、根据用户选择的支付方式,以及系统支付路由设置,选择合适的收单机构。这里涉及三个概念,支付方式,支付路由。这又是一个槽点。简单说,用户可以选择各种银行卡支付,比如宁波银行卡,但是你的支付系统没有对接宁波银行,那对这种卡,可以选择你接入的,支持这个卡的收单机构来执行支付,如用微信或者支付宝等等第三方支付,或者银联支付等系统支持的方式来执行。这就是支付路由,根据用户提供的银行卡来选择合适的收单机构去执行支付。常用支付方式还包括第三方支付,如微信支付宝等,这种情况下就不需要支付路由了。
4、调用收单接口执行支付。这是支付系统的核心。每个公司的收单接口都不一样,接入一两个收单机构还好,接入的多了,如何统一这些接口,就是一个设计难点。
5、支付成功,收单机构把钱打到商户的账户上了。 商家就准备发货了。 怎么发货,不是本文的重点。 这里关注的要点是, 商家能收到多少钱? 比如100块钱的商品,用户支付了100块钱(运费、打折等另算),这100块钱,还要刨去电商系统的佣金、支付通道的手续费,才能最终落到商家手里。
这是个Happy流程,一切看起来都很美好,但实际上步步都是坑,一旦有地方考虑不周全,轻者掉单频发,重者接口被盗刷,损失惨重。
如何避免攻击者修改支付接口参数, 比如100块钱的东西,改成10块钱?
调用收单接口来执行最终实际支付时,如果支付失败了,比如卡上没钱了,怎么办?
收单接口把账户上的钱扣走了,但是通知支付系统的时候出错了(比如网络闪断,或者支付系统重启了),支付系统不知道这笔交易已经达成了,怎么处理?
还有好多问题……
和钱打交道,在任何公司,都跑不掉财务部门。 那财务部门会关注哪些内容? 当然,最重要的是账务信息。 所有的交易都要记账,按要求公司都需要定期做审计,每一笔帐都不能出错。这当然不能等到审计的时候再去核对,而是每天都需要对账,确保所有的交易支出相抵,也就是所说的把账给平了。 这就有三种情况: 电商系统和商家对账;电商系统和支付系统对账;支付系统和收单机构对账。作为支付系统,我们仅关注后两者的情况。
从软件开发角度, 还有一些非功能性需求需要实现:
性能: 特别是秒杀的时候,如何满足高频率的支付需求?
可靠性:不用说,系统能达到几个9,是衡量软件设计功力的重要指标。 99%是基础, 99.999%是目标,更多的9那就是神了。
易用性:支付中多一个步骤,就会流失至少2%的用户。 产品经理都在削尖脑袋想想怎么让用户赶紧掏钱。
可扩展性: 近年来支付业务创新产品多,一元购、红包、打赏等,还有各种的支付场景。 怎么能够快速满足产品经理的需求,尽快上线来抢占市场,可扩展性对支付系统设计也是一个挑战。
可伸缩性:为了支持公司业务,搞一些促销活动是必须的。 那促销带来的爆发流量,最佳应对方法就是加机器了。 平时流量低,用不了那么多机器,该释放的就释放掉了, 给公司省点钱。
所以支付的坑还不少,我们先看看互联网的头牌们是如何设计支付系统的? 先看看某团的:
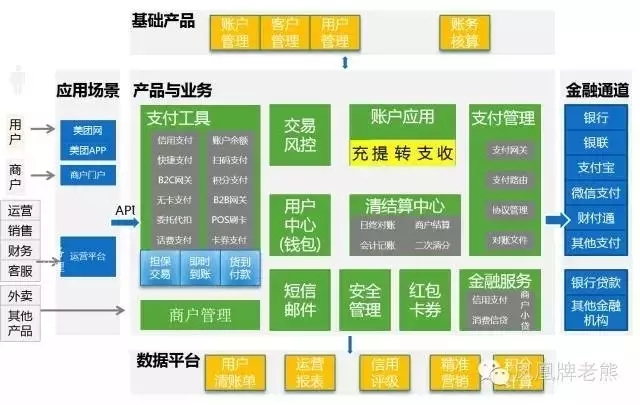
再看某Q旅游公司的:
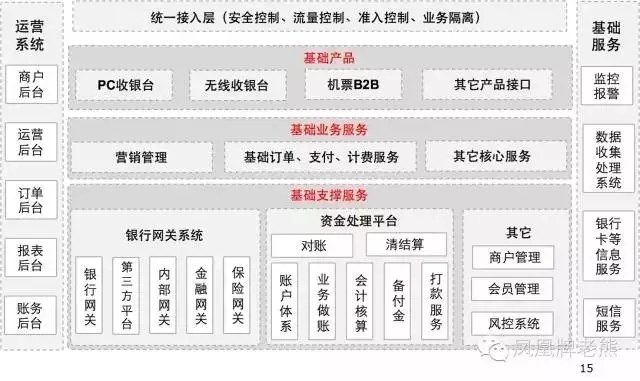
对比下某东金融的:
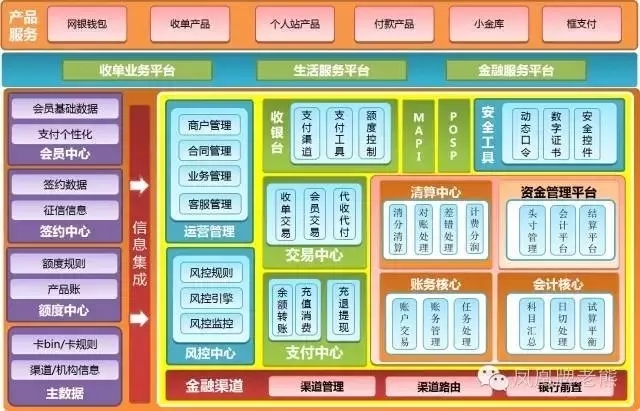
最后看看业界最强的某金服金融的:
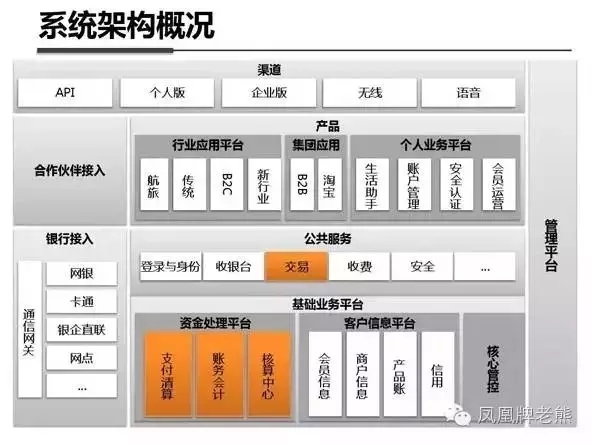
整体上来说, 从分层的角度,支付系统和普通的业务系统并没有本质的区别,也是应用、服务、接口、引擎、存储等分层。 在应用层,支付系统一般会提供如下子系统:
支付应用和产品(应用层): 这是针对各端(PC Web端、android、IOS)的应用和产品。 为各个业务系统提供收银台支持,同时支付作为一个独立的模块,可以提供诸如银行卡管理、理财、零钱、虚拟币管理、交易记录查阅、卡券等功能;
支付运营系统(应用层): 支付系统从安全的角度来说,有一个重要的要求是,懂代码的不碰线上,管运营的不碰代码。这对运营系统的要求就很高,要求基本上所有线上的问题,都可以通过运营系统来解决。
支付BI系统(应用层): 支付中产生大量的数据,对这些数据进行分析, 有助于公司老板们了解运营状况,进行决策支持。
风控系统(应用层):这是合规要求的风险控制、反洗钱合规等。
信用信息管理系统(应用层):用来支持对信用算法做配置,对用户的信用信息做管理。
其他各层功能:
支付服务层:为上述各端系统提供API。这些API也可以提供给业务系统直接使用。
接口层:和各相关系统对接的接口,其中最重要的是和支付渠道对接的支付网关。
引擎层: 包括统计分析、风控、反洗钱、信用评估等在后台运行的各个系统。
存储层: 各种持久化的数据库支持。
这其实也是普通互联网应用系统架构,没有什么特别之处。比如微服务如何体现,如何满足性能需求等,在这个视图中无法体现出来。这只是个软件角度的高层视图,后续我们对各个主要模块进行分解,从分解视图中可以知道如何满足非功能性需求。
关于监控,在各个技术网站,几乎都是一搜一大把。几个大的互联网公司,也都有开发自己的监控系统。 关于这方面也有不少分享。 这里介绍针对支付系统的监控和报警,但大部分内容,应该来说,对其他系统也是通用的 。
现在基本上Zabbix成为监控的标配了。 一个常规的Zabbix监控实现, 是在被监控的机器上部署Zabbix Agent,从日志中收集所需要的数据,分析出监控指标,发送到zabbix服务器上。!zabbix监控这种方式要求每个机器上部署Zabbix客户端,并配置数据收集脚本。Zabbix的部署可以作为必装软件随操作系统一起安装。
先说相对比较简单的系统监控,一般系统监控关注如下指标:
CPU负载
内存使用率
磁盘使用率
网络带宽占用
这些指标在Zabbix agent中会提供默认实现,通过简单配置即可激活。装机时可以考虑统一配置这些监控。
JMX提供了关于JVM的大部分核心信息,启动时设置参数,支持远程访问JMX,之后即可通过接入JMX来实时读取JVM的CPU、内存等信息。Zabbix也支持通过JMX来获取信息。
服务监控主要指接口的状态监控。 服务监控关注如下指标:
QPS:每秒请求数 对于使用容器的系统,包括Apache Tomcat,Resin,JBoss等,可以从Access Log中采集到每个接口的QPS。没输出Access Log的系统,考虑通过Annotation来规范输出访问计数。当然,这个指标还可以细分为 每秒成功请求数、失败请求数、总请求数等。
请求响应时间:在服务器端监控每个接口的响应时间。简单做法是在方法执行前后打时间戳计算,对于HTTP请求,也可以从access log中获取接口执行时间。当然也可以用annotation来实现统一的执行时间监控。
执行异常数:指程序运行过程中发生的未捕获处理的异常,一般是对场景考虑不周导致的异常发生,比如空指针、错误参数、数据访问等的异常。 这些异常一旦发现,需要修复代码逻辑。 异常在应用日志中一般都会把错误堆栈打印出来。
数据库是大部分应用的核心和瓶颈,对其监控尤其必要。监控可以 在应用侧执行,也可以在数据库服务器上做。前者通过应用代码中打印日志来实现,或者直接override 链接池中相关方法来统一输出日志。在数据库服务器上执行监控,需要根据数据库的特点分别设计方案。以MySQL为例,可以通过监控其bin log来获取执行的sql语句以及执行时间。使用Alibaba Canal 来对接MySQL的BinLog, 接收到BinLog消息后,解析消息数据,可以获取请求的SQL、参数、执行时间、错误代码等信息。
数据库监控重点关注如下指标:
每秒请求数
慢查询处理数
SQL语句执行时间
调用链监控指在微服务系统中,跟踪一个请求从发起到返回,在各个相关系统中的调用情况。 调用链监控是跨系统的监控,需要在请求发起时分配一个可以唯一识别本次调用请求(或者成为事务)的ID,这个ID会被分发到每个调用上。之后在调用日志中输出该ID。当所有日志都汇总起来后,可以从日志中分析本次调用的流程。 对于HTTP/HTTPS请求,可以考虑将ID放到Header里面,这样不会影响接口逻辑。
业务监控是一个复杂的话题。这里以支付为例,说明业务监控的架构和实现。
支付业务监控
每个支付通道监控包括如下内容:
支付通道接口请求数: 如果一段时间内接口请求环比大幅度下降,可能是该接口出现问题了。
支付通道接口请求失败数,即调用接口失败的数量。
支付通道接口请求延迟。
支付通道支付失败率。每个通道支付有一定的失败率,如果给定时间内突然有超过这个失败率的情况出现,则可能是通道出现问题了。
支付通道同步、异步调用次数。
支付接口,如支付、提现、退款、签约、订阅等,监控如下内容:
总金额,如果总金额有大的波动,则有洗钱的可能
每笔平均金额
支付成功率
监控架构
实际上对一个业务来说,大部分系统监控的指标是类似的,而按照这种方式,每个指标在各个被监控系统中还需要单独写脚本实现,工作量大。针对这种情况,可以采用日志集中监控的方式来处理。 考虑到日志最终都需要归并到一个日志仓库中,这个仓库可以有很多用途,特别是日常维护中的日志查询工作。多数指标可以在日志上完成计算的。 借助这个系统,也可以完成监控: !zabbix 监控。
日志通过Apache Flume来收集,通过Apache Kafka来汇总,一般最后日志都归档到Elastic中。 统计分析工作也可以基于Elastic来做,但这个不推荐。 使用Apache Spark 的 Streaming组件来接入Apache Kafka 完成监控指标的提取和计算,将结果推送到Zabbix服务器上,就可以实现可扩展的监控。
这个架构的优势在于:
监控脚本的跨系统使用。 指定日志规范后, 只要按照这个规范编制的日志,都可以纳入监控,无需额外配置。
服务重新部署时无须考虑监控脚本的部署,所有监控直接生效。
难点在于,提炼一套通用的日志规范,考虑如何通过Spark来分析日志。
日志收集
Flume和logstash都可以用于日志收集,从实际使用来看,两者在性能上并无太大差异。flume是java系统,logstash是ruby系统。使用中都会涉及到对系统的扩展,这就看那个语言你能hold住了。
日志数据流
Flume和Logstash都支持日志直接入库,即写入HDFS,Elastic等,有必要中间加一层Kafka吗?太有必要了,日志直接入库,以后分析就限制于这个库里面了。接入Kafka后,对于需要日志数据的应用,可以在kafka上做准实时数据流分析,并将结果保存到需要的数据库中。
日志分析
Streaming分析,可以走Spark,也可以用Storm,甚至直接接入kafka做单机处理。这取决于日志数据规模了。Spark streaming是推荐的,社区活跃度高,又集成了多种算法。
日志系统与日志框架
Java主流的日志系统有log4j,JULlogback等,日志框架有apache commons logging,slf等,关于这些系统的历史掌故恩怨情仇八卦趣事,网上有不少资料,这里不详细介绍。
日志系统选型
最好的编程语言是PHP还是Java? 同样的,也有争论:最好的日志框架是slf还是commons-logging?最好的日志系统是Log4j还是Logback?在使用上,它们的API和使用方式大体类似,slf有模版支持,但这也不是关键需求。而性能方面,从我们测试用例中也没有发现哪个系统或框架有明显优势。对性能有决定性影响的是使用方式。
日志高能预警
根据我们的测试,在高并发系统中,关于日志,有如下结论:
Log4j与logback在高并发下性能上并无太多差异,不用太纠结使用哪个API,.影响性能的是日志内容的写法和数据量。
输出类名和行号会严重影响性能,这需要使用到性能不佳的反射机制。执行频率高,性能要求高的代码,禁用反射,禁用new操作。
高峰期系统出错,如果打印错误堆栈,那绝对是雪上加霜,理由同上。
多线程时输出日志,写锁是影响性能的关键因素。缓解写锁的措施,首选加大日志写入缓冲区,其次是异步打印。异步对性能有提升,但不显著。写锁出问题的一个现象是CPU跑满。
日志分级本身无太大意义。
经平台及作者同意授权转载
来源:凤凰牌老熊 订阅号(id:shamphone)
作者:凤凰牌老熊








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721