
整体架构
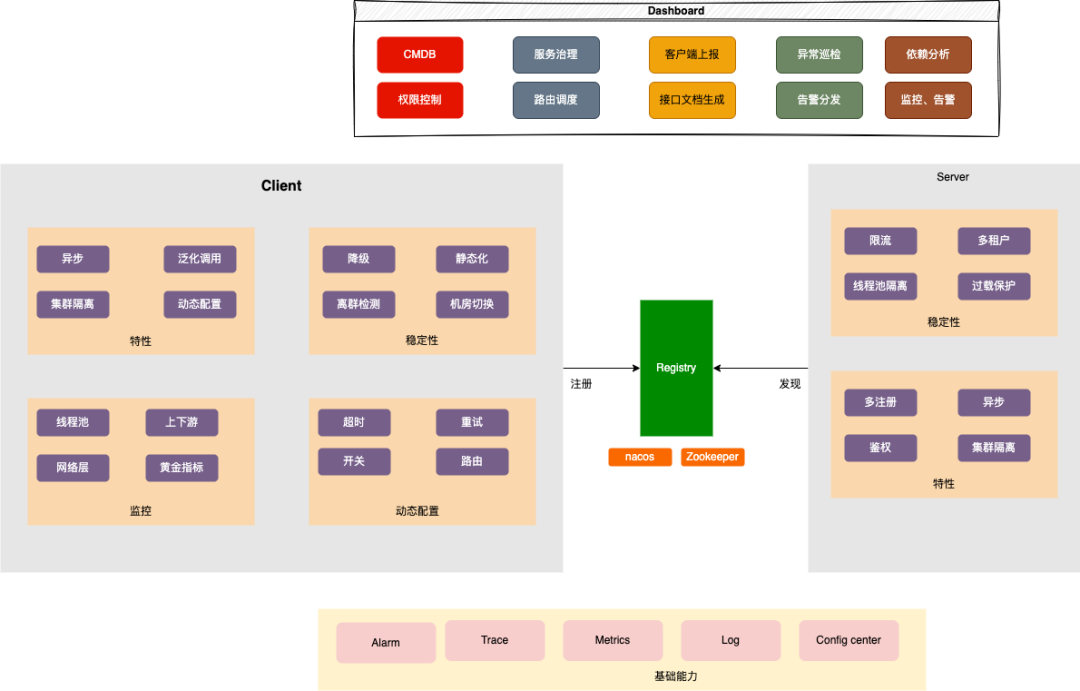
架构图
由传统的单体应用迁移到微服务后,应用被拆分、部署到了独立的节点、集群,进程内的函数调用不再适用于分布式场景,于是RPC框架应运而生,但同样的也引入了一系列新的问题:
服务发现:consumer如何快速发现provider所有的节点?provider下线后如何快速将通知下发到consumer。
连接管理:单连接还是连接池?网络抖动后如何重连、自愈?
面向云原生:容器化部署后,节点异常、宕机常态化,如何快速感知异常节点并快速熔断。
重试:请求异常、超时应当选择怎样的重试策略合适?
稳定性是一个非常复杂的话题,从故障的角度来看,可以分为以下几个阶段:
故障前:这个阶段主要是预防,例如在问题上升为故障前,通过自动化测试、流程规范管控、监控报警、等手段快速发现。
故障中:这个阶段主要是发现、恢复和定位故障。需要快速发现系统出现的故障,及时采取措施进行恢复,并准确定位故障原因,最大化降低对用户的影响。
故障后:这个阶段主要对故障发生的原因进行分析和总结,找出不足之处并采取措施进行改进,思考通过标准化、流程化、自动化的手段,避免同样的故障二次出现。
在后续的行文中,我们将从这几个方面来探讨稳定性的话题。
故障前
You can't manage what you can't measure.
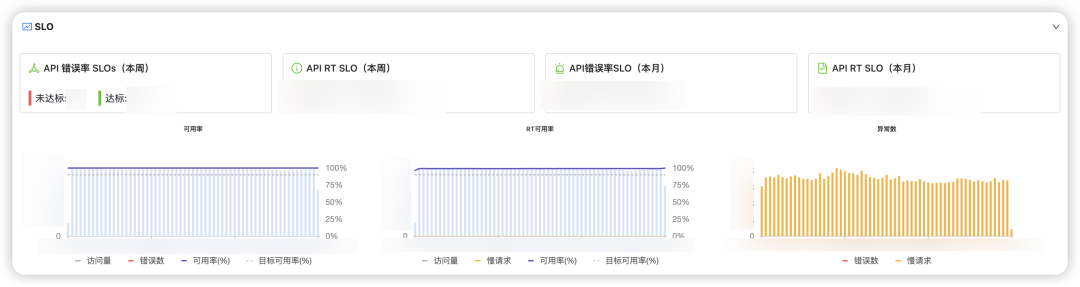 SLO
SLO
就RPC而言,音乐内部有N套平台可以用于故障的发现、预警,例如异常日志、核心指标(线程池、CPU、内存、GC等)、自动化用例等。太多的指标会导致我们忽视真正核心的问题;而选择过少的指标,例如只有异常日志告警,会导致故障无法被及时发现。我们需要站在用户的角度思考问题,当用户使用一个系统是时候更关注的是哪些指标?例如CPU使用率达到80%是一个现象,我们更希望知道对用户的影响是什么,接口可用率下降还是RT升高?
SLO是什么?
SLO是指服务等级的目标值或范围值,通常用于衡量服务健康状况。SLO提供了一种标准化的方式来描述、衡量和监控微服务应用程序的性能、质量和可靠性。SLO为应用开发和平台团队、运维团队提供了一个共享的质量基准,可作为衡量服务水平质量以及持续改进的参考。示例如下:
90%的RPC请求能够在200ms以内完成
99%的请求返回的code为200
对于RPC这种在线服务的场景来说,例如歌曲播放、查看评论、会员充值等场景,相对来说我们会更关注接口的成功率、延迟等核心指标,即接口能正常响应用户的请求吗?花了多久?因此前期我们选择了成功率、RT来作为SLO的数据源,并重分利用了SLO平台提供的监控、告警等能力,有效实现了对接口可用性的度量,当SLO出现波动时,开发需要及时介入排查。
早期版本打印的日志非常混乱,大部分异常缺少说明,导致用户无从下手。因此我们针对日志进行了一系列治理措施。
链路串联:将日志和trace打通,当业务排查问题时,通过traceId即可将上下游所有应用关联在一起,并快速跳转到APM平台。
异步适配:RPC和单体应用时代不同,天生就具备了异步的特性,请求发出后,consumer等待,而当provider处理完成之后,框架内部根据requestId关联到对应的请求,并将结果返回。过程中会存在很多线程池切换,例如业务现场、IO线程、worker线程等,而线程池的切换可能会导致traceId丢失,从而影响问题的排查。因此我们针对内部所有的异步、线程切换等进行了统一的治理,有效避免类似问题的发生。
梳理&完善核心链路日志
日志标准化,例如统一前缀、模块,错误码等信息,从而能够根据接口、ip等信息快速匹配到相关异常日志。
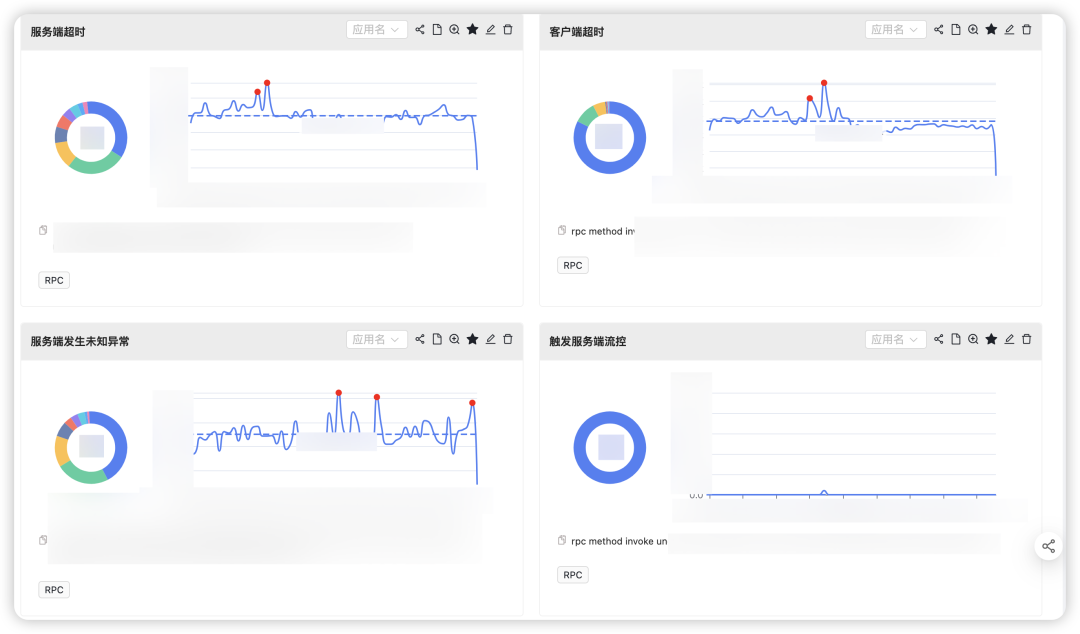
当前告警机制更多偏向应用、资源维度,例如应用的异常日志超出配置的阈值、线程池队列堆积等,而RPC作为中心化的组件,一旦出现问题爆炸半径往往不太可控。因此我们在思考如何能够快速发现框架层的问题。
对于RPC来说,组件能的问题往往都会通过异常日志体现,例如超时、接口熔断、限流、服务上下线、未知异常等,因此我们通过梳理出所有的logger以及异常日志,并基于此构建了以RPC为中心的异常大盘。并提供了应用维度的topN计算、离群点检测、日志采样等丰富的能力,从而能够协助中心化负责人快速发现问题、确定受影响应用、并通过日志采样等功能进一步根因定位。
故障中
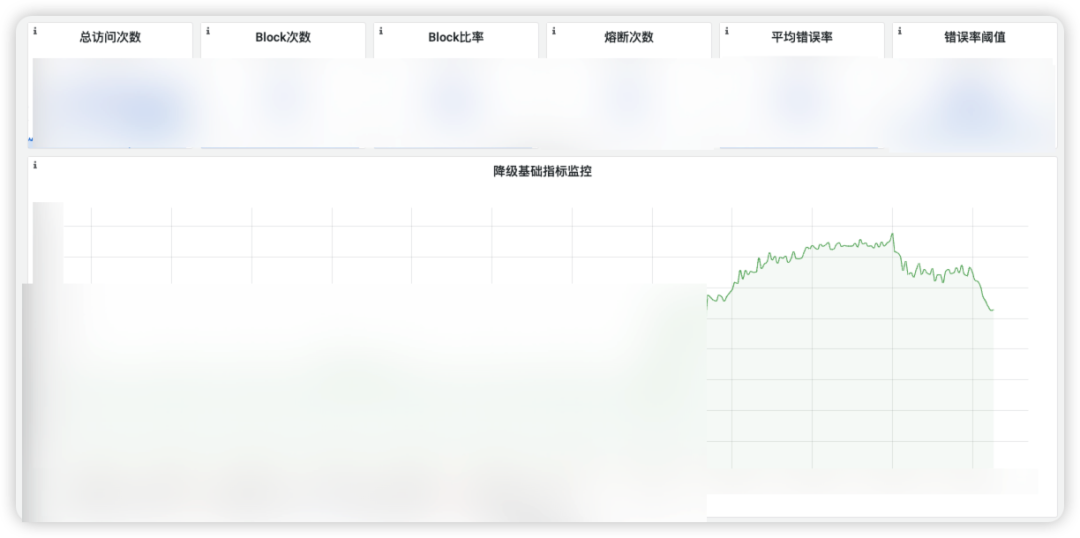
降级
降级平台目前在音乐内部广泛使用,当前已有数千应用接入,通过与降级平台的打通联动,RPC提供了丰富的降级能力:
模板规则:用户无需触动配置,当错误率查出一定阈值时,自动触发降级
支持丰富的兜底策略,例如fallback方法调用、固定值,并与缓存平台打通,支持故障时返回缓存中的数据
监控告警:具备丰富的指标监控以及告警能力,对于BFF等类网关应用,支持支持将告警分发给对应的接口负责人
动态调整:降级规则支持秒级动态调整与下发,应用无需重启、发布
便捷:无需主动接入,平台配置后动态生效
 限流
限流
通过接入内部的限流平台,提升应用对于异常流量的应对能力,并支持丰富的限流策略:
单机、并发限流
分布式限流
参数限流
高频限流等
离群检测
在分布式系统中,宕机是常态时间,而站在服务消费者的层面来说,如果不能及时检测到服务提供者中的异常节点,并快速剔除,将会影响服务的可用性(SLO),进而导致客诉。因此组件层面提供了离群节点检测与剔除能力,当个别节点错误率不符合预期时会将该节点剔除,在指定时间窗口内不再将流量分配到该节点,并在探活成功后,将该节点重新加入服务列表中。
若所有的接口都路由到同一个线程池,那么这些接口变会资源争抢的风险,接口A的RT抖动,会导致接口B的吞吐下降,因此对于一些核心的业务,我们希望能够进行线程池的隔离。因此我们对RPC框架的线程池使用进行了梳理之后,提供了丰富的隔离能力:
产品:支持不同的产品配置路由到各自单独的集群,例如云音乐、直播等不同的APP路由到各自独立的集群、线程池,从而实现更好的隔离
应用、接口、方法:支持各个粒度的隔离
区分普通请求、重试请求:例如将重试请求放到单独的线程池中,避免阻塞正常流量
针对超时、堆积等场景,在执行业务逻辑前、执行业务逻辑后进行多层超时判断,例如超时配置为100ms,而provider在收到请求时会进行一次计算,若此时耗时已经大于100ms,则直接返回超时异常,而无需调用业务接口,从而有效避免无效请求。同时结合客户端、服务端提供的异步能力,更进一步减少线程资源的使用。
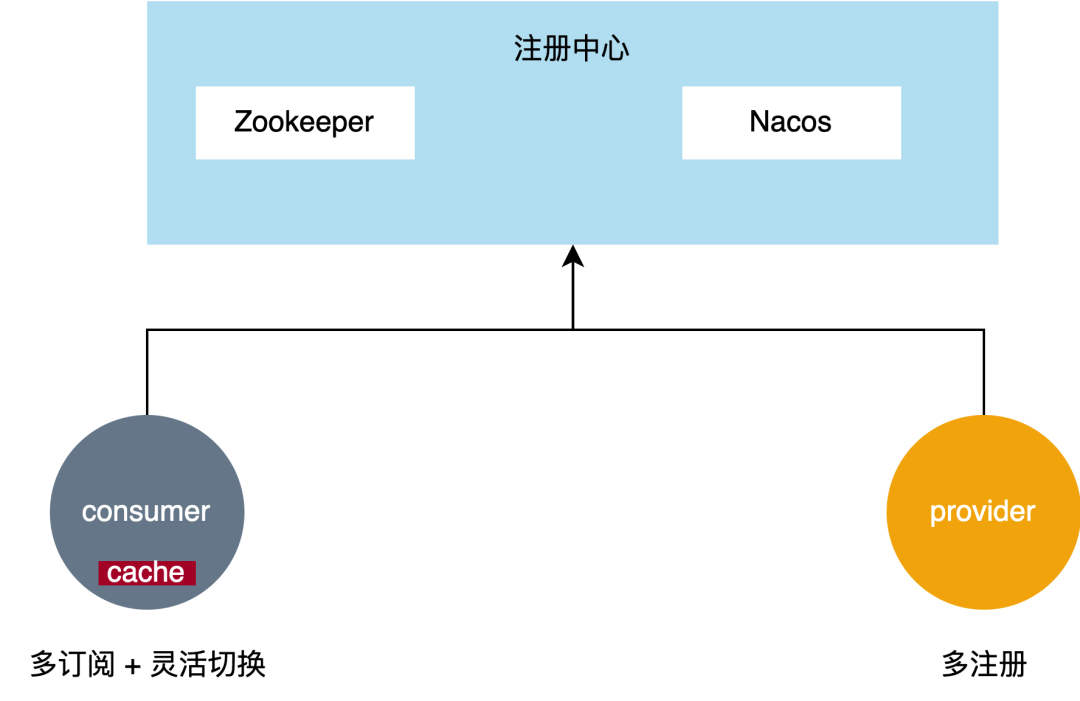 多注册
多注册
对于RPC框架来说最核心的依赖便是注册中心,当前云音乐内部使用Zookeeper作为主要的注册中心,而在之前的版本中对于Zookeeper是强依赖,导致Zookeeper一旦抖动或发生网络异常,provider便会大量下线,导致客户端路由不到正确的节点,影响整体的可用性。
从一致性的角度出发,Zookeeper底层基于Zab的类Paxos协议实现,更注重的是CP,即一致性,因此各种大数据、中间件都会利用Zookeeper来进行元数据、配置的管理。而对于注册中心的场景来说,对于一致性的要求并没有那么高,举个例子,服务提供者有一个节点OOM宕机,没有调用下线接口从Zookeeper中摘除,因此客户端会认为该节点没有下线,仍会保留在路由表中,如果仍将流量达到该节点,那么必然会导致请求失败,但RPC框架通常会具备探活能力,此时下游节点OOM宕机,网络链接断开不可用会直接被节点剔除,对可用率没有任何影响。我们发现对于注册中心来说,底层存储大多数时候只需最终一致即可,不需要这么强的一致性。以这个思路出发,我们对RPC框架进行了一系列专项改造:
配置、重试策略调优,例如sessionTimeout调整到30s,那么网络抖动只要在30s以内,由于session不会过期,provider也不会触发批量下线,对于服务的可用性几乎没有影响。这个参数需要结合实际的应用场景调整。
事件监听优化,区分sessionId,若sessionId未变化,说明session未过期,此时provider不需要重新注册。在服务规模较大时,能够减少大量无用的写入操作。
配置化:重试、超时等参数可动态配置,并将连接串统一管理,节点扩容下线业务无需感知
当服务下线时,将该节点的元数据暂存到缓存中,并支持根据容量、过期时间等策略进行清理。当发生Zookeeper大规模故障时,支持从回收站中将已下线节点重新添加到路由表中。
这里需要注意的是,容器化部署后,节点的ip可能会被其他应用复用、回收站中的节点已经真实下线,因此不能无脑回收,需要对节点进行探活、异常节点检测,从而能够快速将离群节点剔除,最小化对于可用率的影响。
区别于dubbo、Nacos的推空保护,平台支持手动以及自动化的降级,当监控集群检测到Zookeeper服务端异常时,例如无法正常建立链接、写入失败等,则会根据配置自动打开注册中心的回收站机制,从而有效应对注册中心变更(扩容、修改配置)、网络分区等情况。
在新版本中,我们完善了RPC框架的多注册能力,支持将Nacos作为备,并支持动态调整,例如开关打开后,provider会同时往Zookeeper、Nacos注册,而客户端也支持了多订阅能力,并支持丰富的路由策略,例如优先从Nacos读、若Nacos不存在可用节点,从Zookeeper读取作为兜底。
同时由于平台默认支持了Zookeeper、Nacos的多注册能力,我们在启动时对Zookeeper、Nacos做了强弱依赖的管理,例如当进行Zookeeper扩容、迁移操作时,支持将Zookeeper作为弱依赖,即Zookeeper连接、注册、订阅失败不影响应用启动,框架底层会异步重试,从而更进一步降低RPC对于注册中心的依赖。
故障后

经验库
区别于业务异常,RPC组件内部的代码相对稳定,不会频繁变动,因此问题的定位、排查通常具备一定的套路。因此通过日常的答疑、故障定位等逐步积累了组件的经验库。例如当发生指定异常时,平台自动根据异常、堆栈等信息匹配到对应的经验库,进一步优化用户看到异常后无法自助处理的问题。
总结
RPC作为一个微服务框架来说,稳定性、性能是最基本的要素,需要我们持续地打磨、治理,同时我们需要思考在当前云原生、降本增效的大背景下,如何能够更好的支撑未来的架构,并给开发者提供更好的使用体验。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721