
纪成,携程数据开发总监,负责金融数据基础组件及平台开发、数仓建设与治理相关的工作。对大数据领域开源技术框架有浓厚兴趣。
一、背景
2017年9月携程金融成立,本着践行金融助力旅行的使命,开始全面开展集团风控和金融业务,需要在携程DC构建统一的金融数据中心,实现多地多机房间的数据融合,满足离线和在线需求;涉及数千张mysql表到离线数仓 、实时数仓、在线缓存的同步工作。由于跨地域、实时性、准确性、完整性要求高,集团内二次开发的DataX(业界常用的离线同步方案)无法支持。以mysql-hive同步为例,DataX通过直连MySQL批量拉取数据,存在以下问题:
性能瓶颈:随着业务规模的增长,离线批量拉取的数据规模越来越大,影响mysql-hive镜像表的产出时间,进而影响数仓下游任务。对于一些需要mysql-hive小时级镜像的场景更加捉襟见肘;
影响线上业务:离线批量拉取数据,可能引起慢查询,影响业务库的线上服务;
无法保证幂等:由于线上库在实时更新,在批量拉取SQL不变的情况下,每次执行可能产生不一样的结果。比如指定了create_time 范围,但一批记录的部分字段(比如支付状态)时刻在变化。也即无法产出一个明确的mysql-hive镜像 , 对于一些对时点要求非常高的场景(比如离线对账) 无法接受;
缺乏对DELETE的支持:业务库做了DELETE操作后,只有整表全量拉取,才能在Hive镜像里体现。
二、方案概述
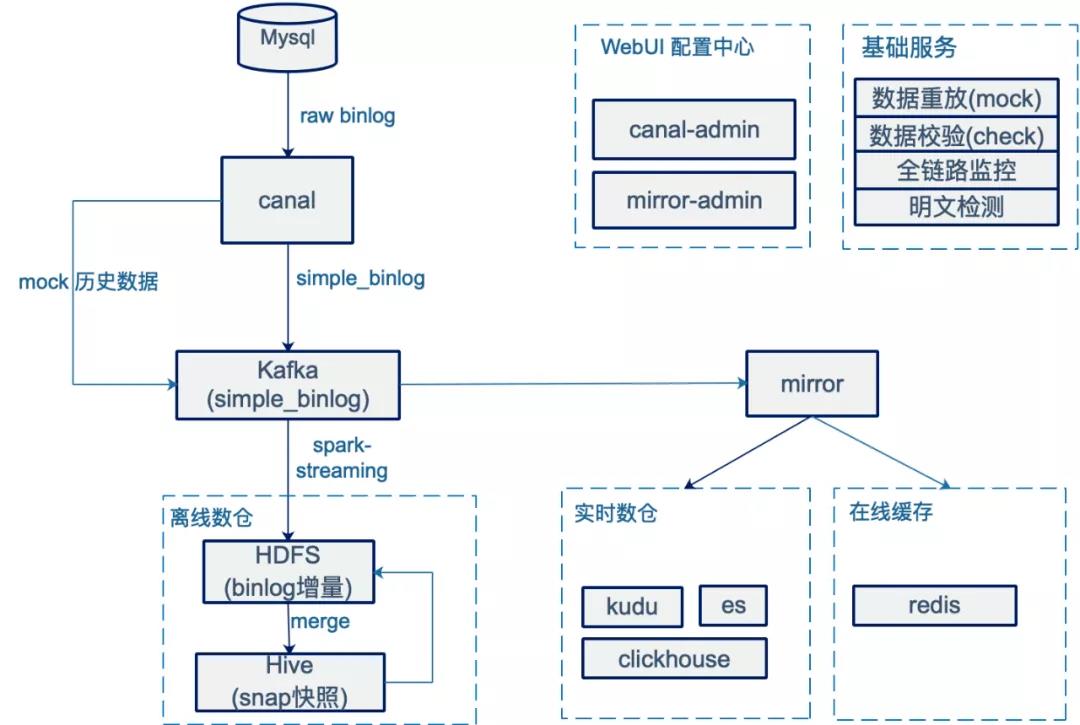
基于上述背景,我们设计了一套基于binlog实时流的数据基础层构建方案,并取得了预期效果。架构如图,各模块简介:
webUI做binlog采集的配置,以及mysql->hive,mysql→实时数仓,mysql→在线缓存的镜像配置工作;
canal负责binlog采集 ,写入kafka ;其中kafka在多地部署,并通过专线实现topic的实时同步;
spark-streaming 负责将binlog写入HDFS;
merge 离线调度的ETL作业,负责将HDFS增量和 snap 合并成新的 snap。
mirror 负责将binlog事件更新到实时数仓、在线缓存;
基础服务:包括历史数据的重放,数据校验,全链路监控,明文检测等功能。
三、详细介绍
本章将以mysql-hive镜像为例,对技术方案做详细介绍。
canal是阿里巴巴开源的Mysql binlog增量订阅和消费组件,在业界有非常广泛的应用,通过实时增量采集binlog ,可以降低对mysql 的压力,细粒度的还原数据的变更过程,我们选型canal 作为binlog采集的基础组件,根据应用场景做了二次开发,其中raw binlog → simple binlog 的消息格式转换是重点。
下面是binlog采集的架构图:
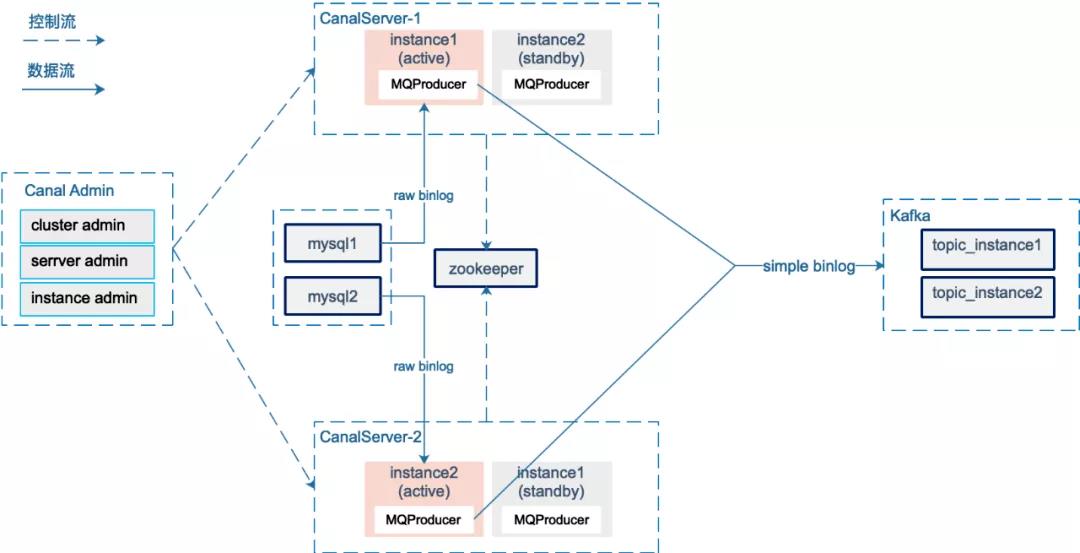
canal 在1.1.4版本引入了canal-admin工程,支持面向WebUI的管理能力;我们采用原生的canal-admin 对binlog采集进行管理 ,采集粒度是 mysql instance级别。
Canal Server会向canalAdmin 拉取所属集群下的所有mysql instance 列表,针对每个mysql instance采集任务,canal server通过在zookeeper创建临时节点的方式实现HA,并通过zookeeper实现binlog position的共享。
canal 1.1.1版本引入MQProducer 原生支持kafka消息投递 , 图中instance active 从mysql 获取实时的增量raw binlog数据,在MQProducer 环节进行raw binlog → simple binlog的消息转换,发送至kafka。我们按照instance 创建了对应的kafka topic,而非每个database 一个topic , 主要考虑到同一个mysql instance 下有多个database,过多的topic (partition) 导致kafka随机IO增加,影响吞吐。发送Kafka时以schemaName+tableName作为partitionKey,结合producer的参数控制,保证同一个表的binlog消息按顺序写入kafka。
参考producer参数控制:
max.in.flight.requests.per.connection=1retries=0acks=all
topic level 的配置:
topic partition 3副本, 且min.insync.replicas=2
从保证数据的顺序性、容灾等方面考虑,我们设计了一个轻量级的SimpleBinlog消息格式:

binlogOffset:全局序列ID,由${timestamp}${seq} 组成,该字段用于全局排序,方便Hive做row_number 取出最新镜像,其中seq是同一个时间戳下自增的数字,长度为6;
executeTime:binlog 的执行时间;
eventType:事件类型:INSERT,UPDATE,DELETE;
schemaName:库名,在后续的spark-streaming,mirror 处理时,可以根据分库的规则,只提取出前缀,比如(ordercenter_001 → ordercenter) 以屏蔽分库问题;
tableName:表名,在后续的spark-streaming,mirror 处理时,可以根据分表规则,只提取出前缀,比如(orderinfo_001 → orderinfo ) 以屏蔽分表问题;
source:用于区分simple binlog的来源,实时采集的binlog 为 BINLOG, 重放的历史数据为 MOCK ;
version:版本;
content:本次变更的内容,INSERT,UPDATE 取afterColumnList,DELETE 取beforeColumnList。
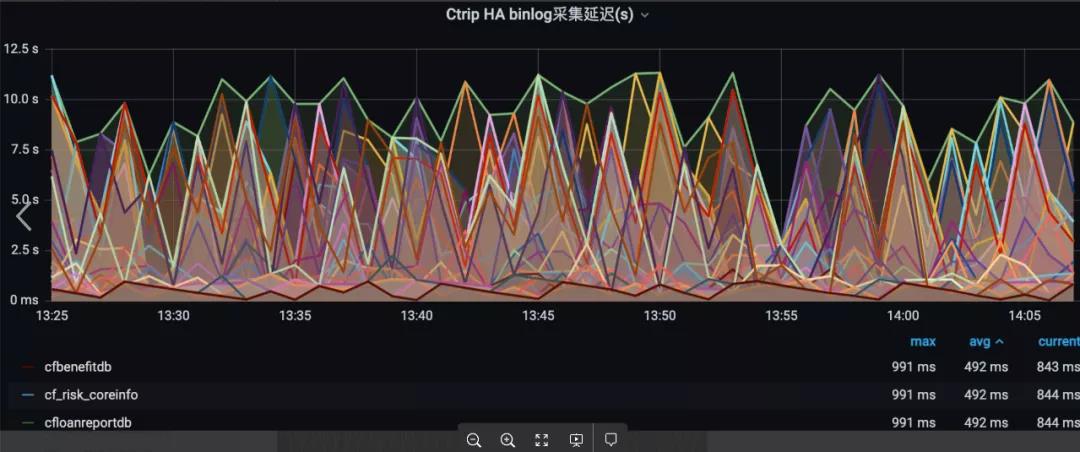
金融当前部署了4组canal 集群,每组2个物理机节点,跨机房DR部署,承担了数百个mysql instance binlog采集工作。Canal server 自带的性能监控基于Prometheus实现,我们通过实现 PrometheusScraper 主动拉取核心指标,推送到集团内部的Watcher监控系统上,配置相关报警,其中各mysql instance 的binlog采集延迟是全链路监控的重要指标。
系统上线初期遇到过canal-server instance脑裂的问题,具体场景是active instance 所在的canal-server ,因网络问题与zookeeper的链接超时,这时候standby instance 会抢占创建临时节点,成为新的active;也就出现了2个active 同时采集并推送binlog的情况。解决办法是active instance 与zookeeper链接超时后,立即自kill,再次发起下一轮抢占。
有两个场景需要我们采集历史数据:
首次做 mysql-hive镜像 ,需要从mysql加载历史数据;
系统故障(丢数等极端情况),需要从mysql恢复数据。
有两种方案:
1)从mysql 批量拉取历史数据,上传到HDFS 。需要考虑批量拉取的数据与 binlog 采集产出的mysql-hive镜像的格式差异,比如去重主键的选择,排序字段的选择等问题。
2)流式方式, 批量从mysql 拉取历史数据,转换为simple binlog消息流写入kafka,同实时采集的simple binlog流复用后续的处理流程。在合并产生mysql-hive镜像表时,需要确保这部分数据不会覆盖实时采集的simple binlog数据。
我们选用了更简单易维护的方案2,并开发了一个binlog-mock 服务,可以根据用户给出的库、表(前缀)以及条件,按批次(比如每次select 10000行)从mysql查询数据,组装成simple_binlog消息发送kafka。
对于mock的历史数据,需要注意:
保证不覆盖后续实时采集的binlog:simple binlog消息里binlogOffset字段用于全局排序,它由${timestamp}+${seq}组成,mock的这部分数据 timestamp 为发起SQL查询的时间戳向前移5分钟,seq为000000;
落到哪个分区:我们根据binlog事件时间(executeTime) 判断数据所属哪个dt分区,mock的这部分数据 executeTime 为用户指定的一个值,默认为${yesterday}。
我们采用spark-streaming 将kafka消息持久化到HDFS,每5分钟一个批次,一个批次的数据处理完成(持久化到HDFS)后再提交consumer offset,保证消息被at-least-once处理;同时也考虑了分库分表问题、数据倾斜问题:
屏蔽分库分表:以订单表为例,mysql数据存储在ordercenter_00 ... ordercenter_99 100个库,每个库下面又有orderinfo_00...orderinfo_99 100张表,库前缀schemaNamePrefix=ordercenter,表前缀tableNamePrefix=orderinfo,统一映射到tableName=${schemaNamePrefix}_${tableNamePrefix}里; 根据binlog executeTime字段生成对应的分区dt,确保同一个库表同一天的数据落到同一个分区目录里: base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt={binlogDt}/binlog-{timestamp}-{rdd.id}
防止数据倾斜: 系统上线初期经常出现数据倾斜问题,排查发现某些时间段个别表由于业务跑批等产生的binlog量特别大,一张表一个批次的数据需要写入同一个HDFS文件,单个HDFS文件的写入速度成为瓶颈。因此增加了一个环节(Step2),过滤出当前批次里的“大表",将这些大表的数据分散写入多个HDFS文件里。
base_path/ods_binlog_source.db/${database_prefix}_${table_prefix}/dt={binlogDt}/binlog-{timestamp}-{rdd.id}-[${randomInt}]

3.4.1 数据就绪检查
spark-streaming作业每5分钟一个批次将kafka simple_binlog消息持久化到HDFS,merge任务是每天执行一次。每天0点15分,开始进行数据就绪检查。我们对消息的全链路进行了监控,包括binlog采集延迟 t1 、kafka同步延迟 t2 、spark-streaming consumer 延迟 t3。假设当前时间为凌晨0点30分,设为t4,若t4>(t1+t2+t3) 说明 T-1日数据已全部落入HDFS,即可执行下游的ETL作业(merge)。
3.4.2 Merge
HDFS上的simple binlog数据就绪后,下一步就是对相应MySQL业务表数据进行还原。以下是Merge的执行流程,步骤如下:
1)加载T-1 分区的simple binlog数据
数据就绪检查通过后,通过 MSCK REPAIR PARTITION 加载T-1分区的simple_binlog数据,注意:这个表是原始的simple binlog数据,并未平铺具体mysql表的字段。如果是首次做mysql-hive镜像,历史数据重放的simple binlog也会落入T-1分区。
2)检查Schema ,并抽取T-1增量
请求mirror后台,获取最新的mysql schema,如果发生了变更则更新mysql-hive镜像表(snap),让下游无感知;同时根据mysql schema 的field列表 、以及"hive主键" 等配置信息,从上述simple_binlog分区抽取出mysql表的T-1日明细数据 (delta)。
3)判断业务库是否发生了归档操作,以决定后续合并时是否忽略DELETE事件。
业务DELETE数据有2种情况:业务修单等引起的正常DELETE,需要同步变更到Hive;业务库归档历史数据产生的DELETE,这类DELETE操作需要忽略掉。
系统上线初期,我们等待业务或DBA通知,然后手工处理,比较繁琐,很多时候会有通知不到位的情况,导致Hive数据缺失历史数据。为了解决这个问题,在Merge之前进行程自动判断,参考规则如下:
业务归档通常是大批量的DELETE(百万+),因此可以设置一个阈值,比如500W或日增量的7倍;
业务归档的时间段通常比较久,比如设置阈值为30天。如果满足了条件1,且删除的这些数据在30天以前,则属于归档产生的DELETE。
4)对增量数据(delta)和当前快照(snap T-2)进行合并去重,得到最新snap T-1。
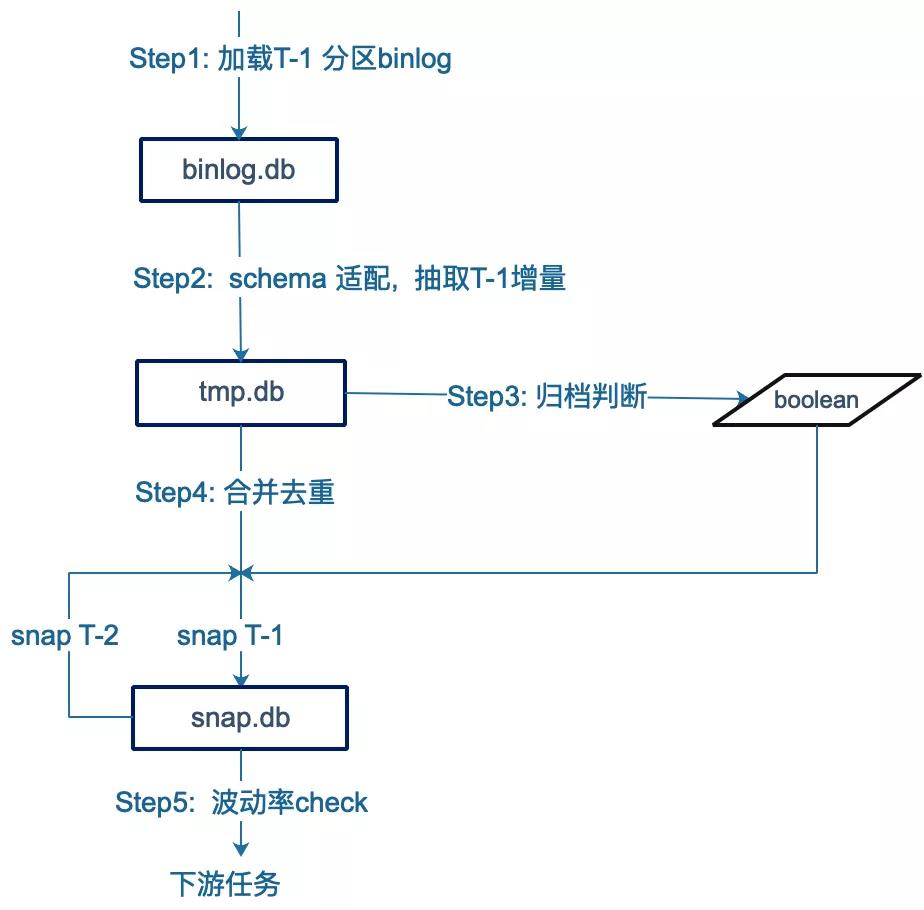
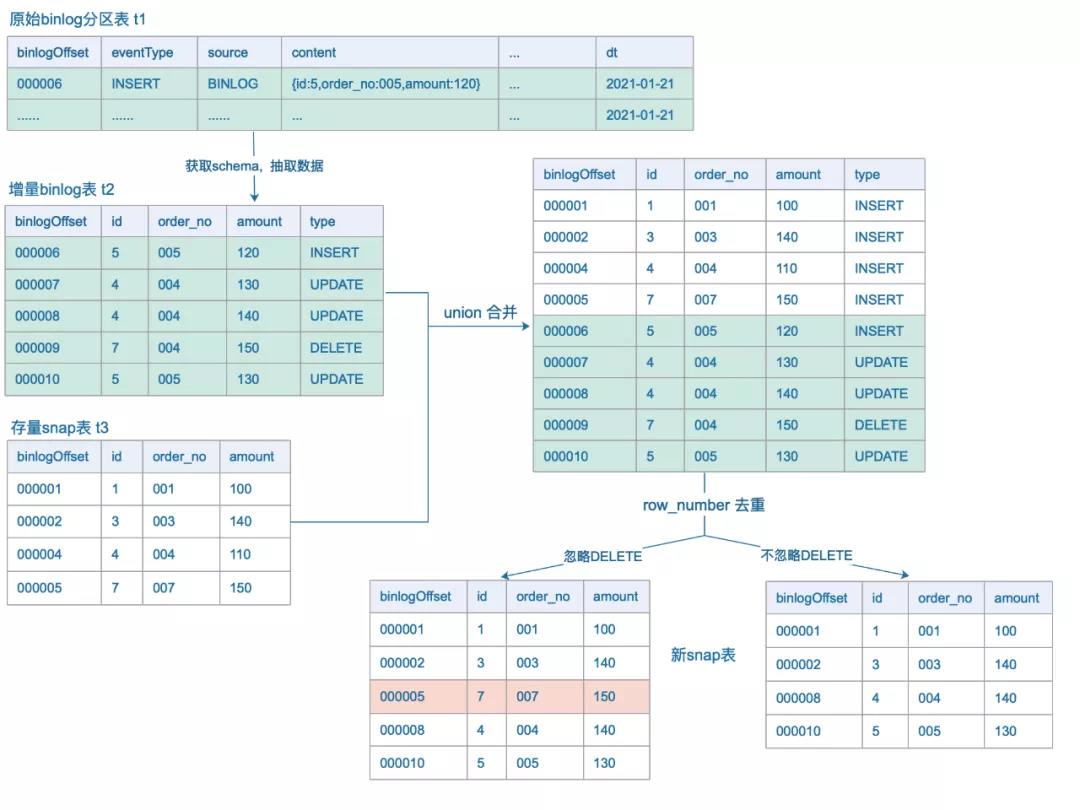
下面通过一个例子说明merge的过程,假设订单order表共有id,order_no,amount三个字段,id是全局唯一建; snap表t3 是mysql-hive镜像,merge过程如图展示。
加载目标(dt=T-1)分区里的simple binlog数据,表格式如t1;
请求mirror后台获取mysql的最新schema,从t1 抽取数据到临时表t2;
snap表t3 与mysql schema进行适配(本例无变更);
对增量表t2、存量snap t3 进行union(对t3自动增加type列,值为INSERT),得到临时表t4;
对t4表按唯一键id进行row_number,分组按binlogOffset降序排序,序号为1的即为最新数据。
3.4.3 check
在数据merge完成后,为了保证mysql-hive镜像表中数据准确性,会对hive表和mysql表进行字段和数据量对比,做好最后一道防线。我们在配置mysql-hive镜像时,会指定一个检查条件,通常是按createTime字段对比7天的数据;mirror后台每天凌晨会预先从mysql 统计出过去7日增量,离线任务通过脚本(http)获取上述数据,和snap表进行校验。实践中遇到一些问题:
1)T-1的binlog落在T分区的情况
check服务根据createTime 生成查询条件去check mysql和Hive数据,由于业务sql里的createTime 和 binlog executeTime 不一致,分别为凌晨时刻的前后1秒,会导致Hive里漏掉这条数据,这种情况可以通过一起加载T日分区的binlog数据,重新merge。
2)业务表迁移,原表停止更新,虽然mysql和hive数据量一致,但已经不符合要求了,这种情况可以通过波动率发现。
3.5 其他
在实践中,可根据需要在binlog采集以及后续的消息流里引入一些数据治理工作。比如:
1)明文检测:binlog采集环节对核心库表数据做实时明文检测,可以避免敏感数据流入数仓;
2)标准化:一些字段的标准化操作,比如id映射、不同密文的映射;
3)元数据:mysql→hive镜像是数仓ODS的核心,可以根据采集配置信息,实现二者映射关系的双向检索,便于数仓溯源。这块是金融元数据管理的重要组成部分。
通过消费binlog实现mysql到实时数仓(kudu、es)、在线缓存(redis)的镜像逻辑相对简单,限于篇幅,本文不再赘述。
四、总结与展望
金融基于binlog的数据基础层构建方案,顺利完成了预期目标:
金融数据中心建设(ODS层):数千张mysql表到携程DC的镜像, 全部T+1 1:30产出;
金融实时数仓建设:金融核心mysql表到kudu的镜像,支持实时分析、分表合并查询等偏实时的运营场景;
金融在线缓存服务:异地多活,缓存近1000G业务数据;支撑整个消金入口、风控业务近100W/min的请求。
该方案已经成为金融在线和离线服务的基石,并在持续扩充使用场景。未来会在自动化配置(整合mirror-admin和canal-admin,实现一键构造)、智能运维(数据check异常的识别与恢复)、元数据管理方面做更多的投入。
本文介绍了携程金融构建大数据基础层的技术方案,着重介绍了binlog采集和mysql-hive镜像的设计,以及实践中遇到的一些问题及解决办法。希望能给大家带来一些参考价值,也欢迎大家一起来交流。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721