
冯海涛/万石康,负责58同城实时计算平台建设。
58同城作为覆盖生活全领域的服务平台,业务覆盖招聘、房产、汽车、金融、二手及本地服务等各个方面。丰富的业务线和庞大的用户数每天产生海量用户数据需要实时化的计算分析,实时计算平台定位于为集团海量数据提供高效、稳定、分布式实时计算的基础服务。本文主要介绍58同城基于Flink打造的一站式实时计算平台Wstream。
和很多互联网公司一样,实时计算在58拥有丰富的场景需求,主要包括以下几类:
实时数据ETL:实时消费Kafka数据进行清洗、转换、结构化处理用于下游计算处理。
实时数仓:实时化数据计算,仓库模型加工和存储。实时分析业务及用户各类指标,让运营更加实时化。
实时监控:对系统和用户行为进行实时检测和分析,如业务指标实时监控,运维线上稳定性监控,金融风控等。
实时分析:特征平台,用户画像,实时个性化推荐等。

在实时计算平台建设过程中,主要是跟进开源社区发展以及实际业务需求,计算框架经历了Storm到Spark Streaming到Flink的发展,同时建设一站式实时计算平台,旨在提升用户实时计算需求开发上线管理监控效率,优化平台管理。
实时计算引擎前期基于Storm和Spark Streaming构建,很多情况下并不能很好的满足业务需求,如商业部门基于Spark Streaming构建的特征平台希望将计算延迟由分钟级降低到秒级,提升用户体验,运维监控平台基于Storm分析公司全量nginx日志对线上业务进行监控,需要秒级甚至毫秒级别的延迟,Storm的吞吐能力成为瓶颈。
同时随着实时需求不断增加,场景更加丰富,在追求任务高吞吐低延迟的基础上,对计算过程中间状态管理,灵活窗口支持,以及exactly once语义保障的诉求越来越多。Apache Flink开源之后,支持高吞吐低延迟的架构设计以及高可用的稳定性,同时拥有实时计算场景一系列特性以及支持实时Sql模型,使我们决定采用 Flink作为新一代实时计算平台的计算引擎。

实时计算平台当前主要基于Storm/Spark Streaming/Flink,集群共计500多台机器,每天处理数据量6000亿+,其中Flink经过近一年的建设,任务占比已经达到50%。
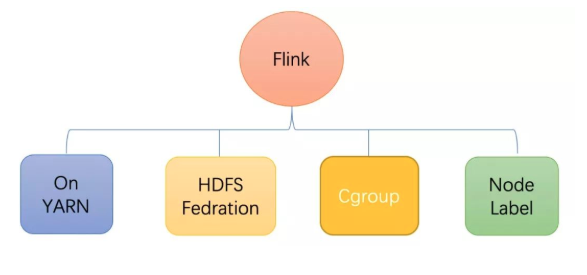
Flink作为实时计算集群,可用性要求远高于离线计算集群。为保障集群可用性,平台主要采用任务隔离以及高可用集群架构保障稳定性。
在应用层面主要基于业务线以及场景进行机器隔离,队列资源分配管理,避免集群抖动造成全局影响。
Flink集群采用了ON YARN模式独立部署,为减少集群维护工作量,底层HDFS利用公司统一HDFS Federation架构下建立独立的namespace,减少Flink任务在checkpoint采用hdfs/rocksdb作为状态存储后端场景下由于hdfs抖动出现频繁异常失败。
在资源隔离层面,引入Node Label机制实现重要任务运行在独立机器,不同计算性质任务运行在合适的机器下,最大化机器资源的利用率。同时在YARN资源隔离基础上增加Cgroup进行物理cpu隔离,减少任务间抢占影响,保障任务运行稳定性。
Wstream是一套基于Apache Flink构建的一站式、高性能实时大数据处理平台。提供SQL化流式数据分析能力,大幅降低数据实时分析门槛,支持通过DDL实现source/sink以及维表,支持UDF/UDAF/UDTF,为用户提供更强大的数据实时处理能力。支持多样式应用构建方式FlinkJar/Stream SQL/Flink-Storm,以满足不同用户的开发需求,同时通过调试,监控,诊断,探查结果等辅助手段完善任务生命周期管理。
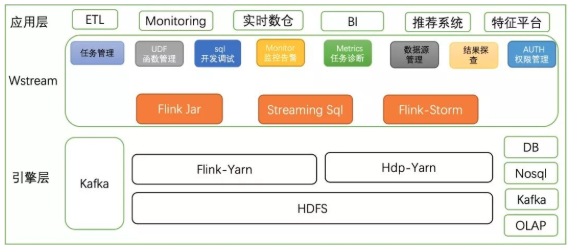
Stream SQL是平台为了打造sql化实时计算能力,减小实时计算开发门槛,基于开源的Flink,对底层sql模块进行扩展实现以下功能:
支持自定义DDL语法(包括源表,输出表,维表)
支持自定义UDF/UDTF/UDAF语法
实现了流与维表的join,双流join
在支持大数据开源组件的同时,也打通了公司主流的实时存储平台。同时为用户提供基于Sql client的cli方式以及在Wstream集成了对实时sql能力的支持,为用户提供在线开发调试sql任务的编辑器,同时支持代码高亮,智能提示,语法校验及运行时校验,尽可能避免用户提交到集群的任务出现异常。
另外也为用户提供了向导化配置方式,解决用户定义table需要了解复杂的参数设置,用户只需关心业务逻辑处理,像开发离线Hive一样使用sql开发实时任务。

在完善Flink平台建设的同时,我们也启动Storm任务迁移Flink计划,旨在提升实时计算平台整体效率,减少机器成本和运维成本。Flink-Storm作为官方提供Flink兼容Storm程序为我们实现无缝迁移提供了可行性,但是作为beta版本,在实际使用过程中存在很多无法满足现实场景的情况,因此我们进行了大量改进,主要包括实现Storm任务on yarn ,迁移之后任务at least once语义保障,兼容Storm的 tick tuple机制等等。
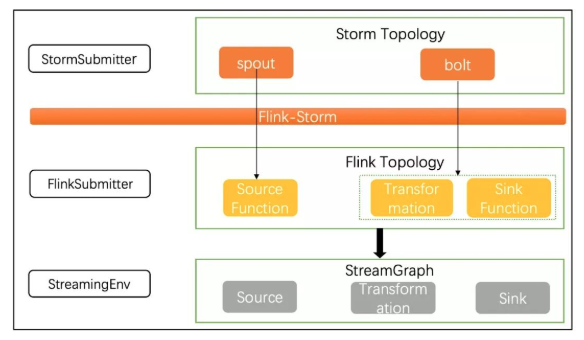
通过对Fink-Storm的优化,在无需用户修改代码的基础上,我们已经顺利完成多个Storm版本集群任务迁移和集群下线,在保障实时性及吞吐量的基础上可以节约计算资源40%以上,同时借助yarn统一管理实时计算平台无需维护多套Storm集群,整体提升了平台资源利用率,减轻平台运维工作量。
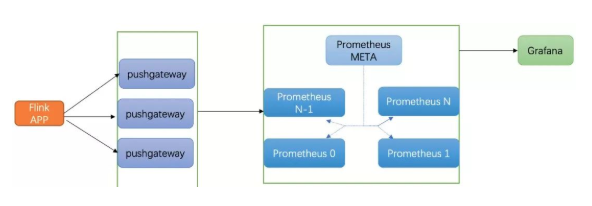
Flink webUI 提供了大量的运行时信息供用户了解任务当前运行状况,但是存在无法获取历史metrics的问题导致用户无法了解任务历史运行状态,因此我们采用了Flink原生支持的Prometheus进行实时指标采集和存储。
Prometheus是一个开源的监控和报警系统,通过pushgateway的方式实时上报metrics,Prometheus集群采用Fedration部署模式,meta节点定时抓取所有子节点指标进行汇总,方便统一数据源提供给Grafana进行可视化以及告警配置。
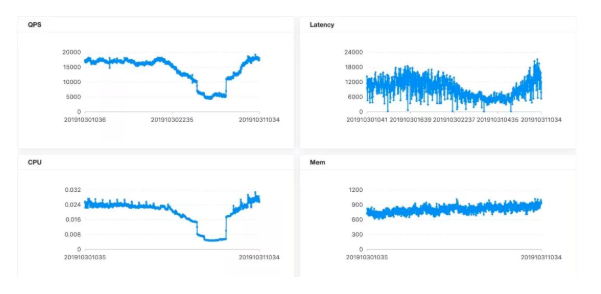
吞吐能力和延迟作为衡量实时任务性能最重要的指标,我们经常需要通过这两个指标来调整任务并发度和资源配置。Flink Metrics提供latencyTrackingInterval参数启用任务延迟跟踪,打开会显著影响集群和任务性能,官方高度建议只在debug下使用。
在实践场景下,Flink任务数据源基本都是Kafka,因此我们采用topic消费堆积作为衡量任务延迟的指标,监控模块实时通过Flink rest获取任务正在消费topic的offset,同时通过Kafka JMX获取对应topic的logsize,采用logsize– offset作为topic的堆积。
Flink作为分布式计算引擎,所有任务会由YARN统一调度到任意的计算节点,因此任务的运行日志会分布在不同的机器,用户定位日志困难。我们通过调整log4j日志框架默认机制,按天切分任务日志,定期清理过期日志,避免异常任务频繁写满磁盘导致计算节点不可用的情况,同时在所有计算节点部署agent 实时采集日志,汇聚写入Kafka,通过日志分发平台实时将数据分发到ES,方便用户进行日志检索和定位问题。
在实际使用过程中,我们也针对业务场景进行了一些优化和扩展,主要包括:
1)Storm任务需要Storm引擎提供ack机制保障消息传递at least once语义,迁移到Flink无法使用ack机制,我们通过定制KafakSpout实现checkpoint相关接口,通过Flink checkpoint机制实现消息传递不丢失。另外Flink-Storm默认只能支持standalone的提交方式,我们通过实现yarn client相关接口增加了storm on yarn的支持。
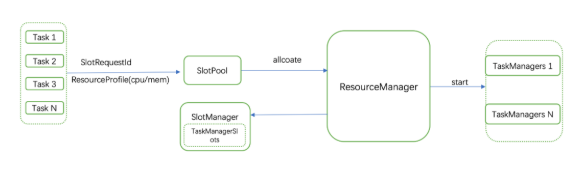
2)Flink 1.6推荐的是一个TaskManager对应一个slot的使用方式,在申请资源的时候根据最大并发度申请对应数量的TaskManger,这样导致的问题就是在任务设置task slots之后需要申请的资源大于实际资源。
我们通过在ResoureManager请求资源管理器SlotManager的时候增加TaskManagerSlot相关信息,用于维护申请到的待分配TaskManager和slot,之后对于SlotRequests请求不是直接申请TaskManager,而是先从SlotManager申请是否有足够slot,没有才会启动新的TaskManger,这样就实现了申请资源等于实际消耗资源,避免任务在资源足够的情况下无法启动。
3)Kafak Connector改造,增加自动换行支持,另外针对08source无法设置client.id,通过将client.id生成机制优化成更有标识意义的id,便于Kafka层面管控。
4)Flink提交任务无法支持第三方依赖jar包和配置文件供TaskManager使用,我们通过修改flink启动脚本,增加相关参数支持外部传输文件,之后在任务启动过程中通过将对应的jar包和文件加入classpath,借助yarn的文件管理机制实现类似spark对应的使用方式,方便用户使用。
5)业务场景存在大量实时写入hdfs需求,Flink 自带BucketingSink默认只支持string和avro格式,我们在此基础上同时支持了LZO及Parquet格式写入,极大提升数据写入性能。
实时计算平台当前正在进行Storm任务迁移Flink集群,目前已经基本完成,大幅提升了平台资源利用率和计算效率。后续将继续调研完善Flink相关能力,推动Flink在更多的实时场景下的应用,包括实时规则引擎,实时机器学习等。
活动推荐
2020年4月17日,北京,Gdevops全球敏捷运维峰会将开启年度首站!重点围绕数据库、智慧运维、Fintech金融科技领域,携手阿里、腾讯、蚂蚁金服、中国银行、平安银行、中邮消费金融、中国农业银行、中国民生银行、中国联通大数据、浙江移动、新炬网络等技术代表,展望云时代下数据库发展趋势、破解运维转型困局。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721