
孙君意,百度资深工程师,目前负责超级链的架构设计,对区块链的账本、事务模型有深入研究。在百度期间负责过万亿级网页链接库实时存储,Feed统一内容池、垂搜多版本数据库等项目。
首先我们来思考一个问题,区块链和数据库在哪些维度上有共性,我自己有一个简单的定义,我认为区块链和数据库都是数据管理技术,数据管理并不高深,我们用一个Excel就可以进行。我们在项目实施过程中会被客户问到一个问题,为什么这个项目非得用区块链,因为区块链难以篡改,比如说有密码的支撑,比较方便实现多方共享。但是这些是不是足以说这个项目就可以用区块链,我认为如果在应用层做很多间接改造也可以实现大部分功能,但是其中有一部分很难实现,就是在参与管理数据的多方存在不信任的场景下,这种场景下是很难用传统数据库解决的。除非多方之间选出大家都公信的“盟主”,让它来管理这个数据库,这个时候业务用数据库就可以做,否则的话是行不通的。
我认为区块链的革命性就是实现了可信的数据管理,有两个方面,第一个是存储的可信;第二个是数据处理过程的可信。通过区块链的共识算法实现了在去中心的网络环境下成百上千个节点维护一致性的数据副本。并且,数据的变更都是公开透明和可审计的,每个节点都会验证,不管是密码验证还是合约执行结果的验证,都会在各个节点执行。
网络规模越大,公信力越强,事实上人们也愿意为可信带来的溢价买单。一个简单的例子,如果现在在亚马逊的RDS存储1GB的数据,成本大概是每月0.25美元,但是同样如果存在以太坊上,大概需要三万两千个ETH,有7200多个节点分布式地在全球存储其副本。区块链通过共识算法和智能合约,在实践层面真正实现了可信的数据管理,这是具有革命性的。
另外一方面,很多人也看到区块链有很多的局限性,出现了一些悲观的看法,比如认为区块链都是更慢的数据库,链式哈希不新鲜,Git中早就有了;绝大多数场景用数据库就够了, 不是刚需——Nice to Have , Not musthave,但是我认为这种看法是错误的。
我总结一下区块链适用的场景有三点:
数据的变更历史需要透明、可审计的应用场景;
数据的处理过程需要按照多方约定并公示后的规则来执行的场景;
数据的副本需要维护在多个不完全互信节点的场景。
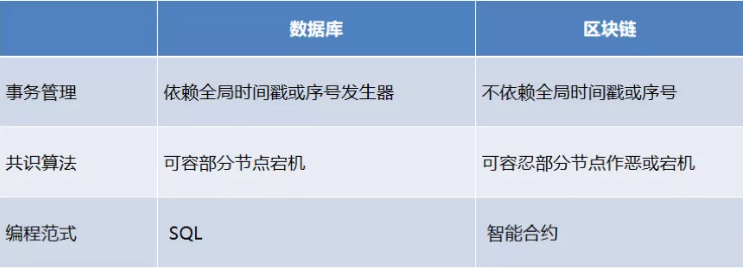
本次分享内容会从三个关键的技术维度去对比:事务管理、共识算法和编程范式。从事务管理角度来看,区块链真的很慢吗?其实并不慢。为了性能,大多数数据库的默认事务隔离级别较弱,而NUS最新研究表明:当Isolation Level设置为最高级别(SERIALIZABLE)情况下,主流分布式数据库的性能和HyperLedger Fabric是一个数量级的(400 TPS左右),单一的这种场景下,传统数据库和区块链相比并没有性能上的绝对优势。
再一个我们来看一下如何实现多版本并发控制,数据库一般有全局时间戳或者序号生成器,每个事务也有自己的序号,可以通过让事务只能读到序号比它序号小的数据版本实现不同事务的隔离。
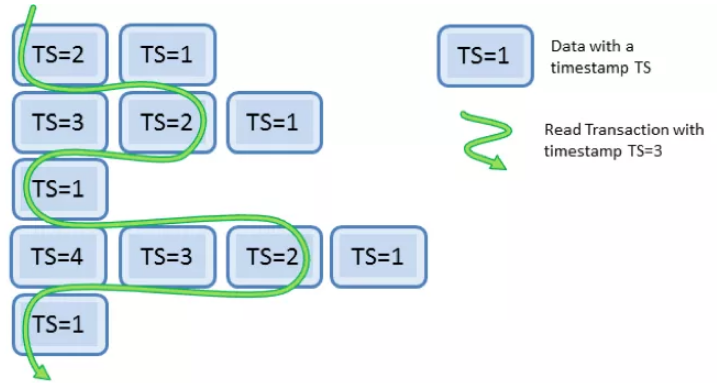
由于要实现去中心化,区块链一般没有全局序号,而是通过显式的Reference关系表达事务之间的“顺序”。比如:比特币中,交易的Input指向了其他交易,表达了一种“Happen Before”的语意,HyperLedger Fabric中,事务需要申明自己的“读写集”,其中,读集的版本是通过(区块高度, 块内序号)二元组引用。
在我们超级链里面的事务模型是XuperModel,它是基于经典的UTXO模型演化而来,经典的UTXO模型只能描述转账场景,而XuperModel创新之处在于可以描述更加通用的数据变更。
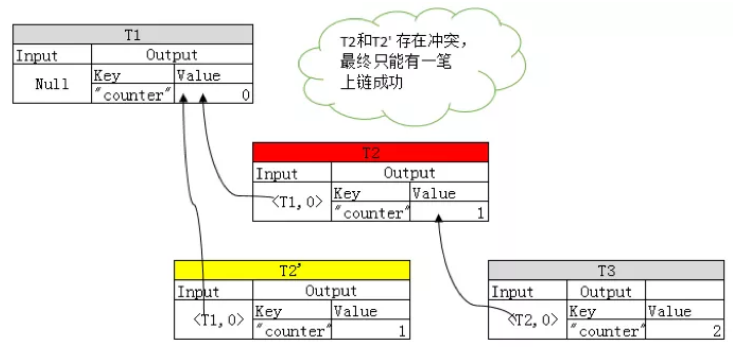
举个例子,这里有个“计数器”合约,调用一次,Counter变量就会加一。从上图可以看到,每个事务的Input字段有个哈希指针指向其依赖的其他事务的Output。也就是说,事务的Input描述了它读取的变量的旧版本,而Output体现了事务一旦成功后会赋予变量的新值。图中,T2和T2’这两个事务是冲突的,因为他们的Input引用了相同的变量的旧版本,但是输出是赋值同一个变量。最终,T2和T2’只能有一笔上链,另外一笔会回滚。
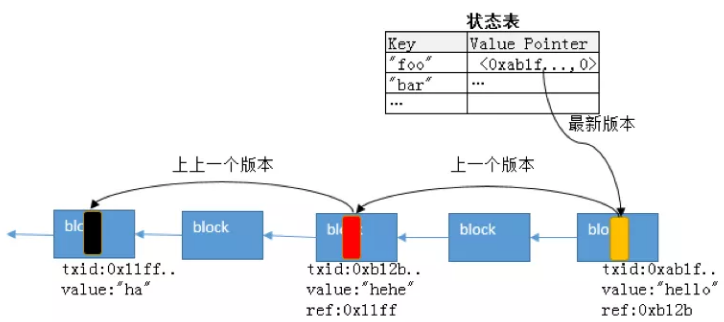
再一个,超级链底层的数据多版本机制实现也与数据库不同。数据库的一般做法是将逻辑Key+版本号拼接成物理Key,但是这个方式只能保留有限个版本,一旦版本太多,就会导致区间查询迭代很慢,因为要Scan大量无用的老版本。超级链用了一种链式哈希的多版本接口,在状态树中Key对应的Value只是哈希指针,指向账本中事务的Output字段,要回溯之前的老版本也只需要通过事务的Input指针再往前回溯。当需要回滚事务或区块的时候,产生的IO开销也极低。
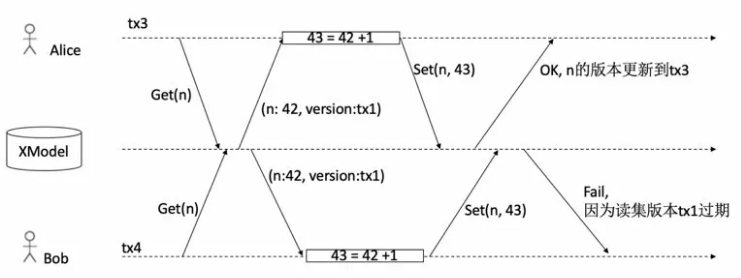
这里再举一个简单的例子,还是刚才那个“计数器”场景。假设Alice和Bob几乎同时发起合约调用。合约执行到Get调用,得到同样的值是42,版本也一样是tx1。然后加一计算得到43,再分别进行Set提交,Alice先提交的就可以将值更新到43,版本更新到tx3,而对于Bob,虽然运算过程是对的,但是最终提交时候的版本已经过期了,因为其依赖的版本等于tx1而现在最新的版本是tx3,所以就会失败。
我们再看一下共识算法的详细对比,说到共识算法不得不提一下FLP原理,原论文发表于1982年,大概是说:在异步网络下,多个节点中就算只有一个错误节点,也无法找到确定性的算法保证同时满足safety和liveness。这个FLP给大家提供了分布式系统设计的理论指导,而实践中,数据库的共识更多的是牺牲了liveness而确保saftey,比如raft。相反地,区块链尤其是公链则是牺牲了safety而优先保证liveness比如,比特币的交易如果是刚刚上链,那是有一定概率因为分叉被回滚掉的,不够safety,但是好处是整个系统一直可以提交交易,就算有分叉,最终会通过最长链原则达到一致性。
上面的表格详细对比了数据库&区块链在容错、选主方式、日志复制、安全和活性等方面的差异,并且区分了公链和联盟链。
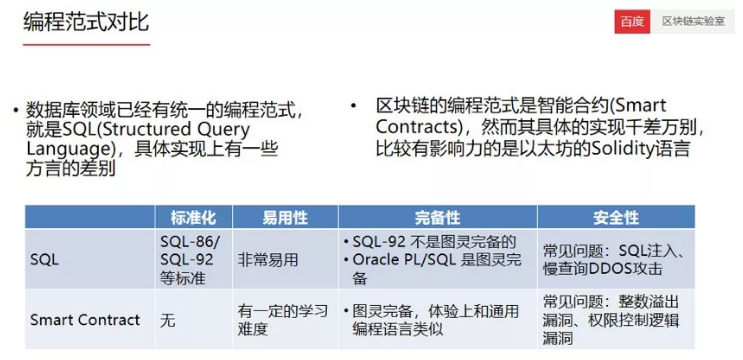
下面看一下编程范式对比。数据库领域已经有统一的编程范式,就是SQL(Structured QueryLanguage),具体实现上有一些方言的差别。区块链的编程范式是智能合约(Smart Contracts),然而其具体的实现千差万别,比较有影响力的是以太坊的Solidity语言。

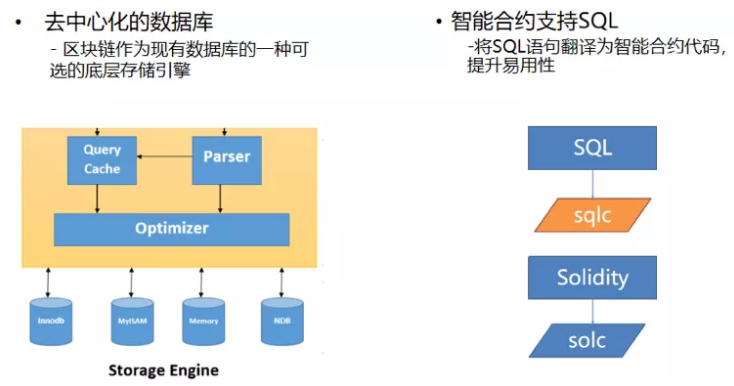
最后来做一下两者未来融合展望。我认为区块链和数据库有融合的契机,我写出来了两种可能,有一种是把区块链作为引擎接入到数据库中,相当于从底层改造存储引擎实现去中心化的数据库。另外一个方向,区块链借鉴一下数据库好的东西,比如像SQL,将SQL语句翻译为智能合约代码。百度超级链已在推进数据库与区块链技术的融合,在合约层面支持了Table,后续计划在Table接口之上再引入SQL引擎,使得用户大部分情况下可用SQL语句写智能合约,提升系统易用性。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721