
创业之初,我们往往会为了快速迭代出产品,而选择最简单的技术架构,比如LAMP架构,SSH三层架构。这些架构可以适应初期业务的快速发展。
但是,随着业务变得越来越复杂,我们会发现这些架构越来越难支撑业务的发展,出现一个类中写好几千行代码,一个方法中到处都是if else语句,如果中间遇到主程序猿离职,后面介入的程序员几乎无法理解这些代码,到最后,产品越来越难迭代,只能推翻重做。
如果我们在创业初始就以一种适应性较强的架构去写代码,后面就会少走很多弯路。下面的文章是我自己总结出来的一套架构,经过实践,适应性还算不错。
二、通用架构实现
总的来说我的通用架构还是以三层架构为基础进行演变的,在经典的三层架构中,最上层的是controller,中间是service,下层是dao。
在我的架构中,最上层是网关层,controller只是网关的一种,中间是业务层,service只是业务层的入口,最下层是基础层,dao只是基础层中的数据存储组件。
网关层本质上是对不同的网络协议的请求进行处理,比如HTTP协议,TCP协议,当然,也可以对其他协议进行处理。具体见下图:
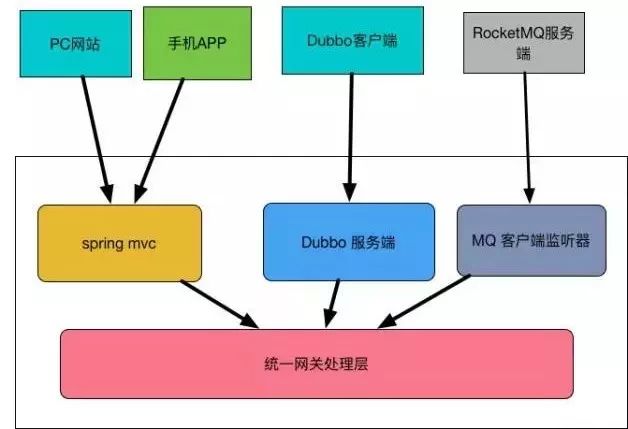
HTTP请求
一般来自PC端和APP端的请求都是基于HTTP协议的,对于处理HTTP请求的方案,业内已经非常成熟了。
首先,Tomcat容器本身已经把HTTP请求处理的复杂性封装掉了;
其次,Spring MVC对请求处理提供了RESTful风格的编码方式,大大降低了开发的复杂度。
我们要做的就是对controller按照业务领域划分,比如按照订单、会员去划分大的领域,里面的各种方法就是这个领域内的操作。
这里的controller就是统一网关处理层,对于每个controller的方法只做三件事:
第一,将请求参数解析出来并组装成内部参数;
第二调用下层服务执行业务逻辑;
第三组装返回结果,对于异常情况,需要记录异常堆栈日志并转换错误码,堆栈信息不要暴露到调用方。
TCP请求
对于处理TCP请求的方案,业内也已经很成熟了,比如Netty。但是,TCP请求毕竟太底层,我们往往会基于TCP协议去开发自己的协议。
另外,很多分布式框架都是基于TCP协议的,比如RPC框架Dubbo,消息框架RocketMQ等等。从单机系统到分布式系统,无非就是网关层多了处理TCP请求的逻辑,理论上底层的业务是无需感知自己到底是出于单机环境还是分布式环境,网关层的作用就是要屏蔽这种不同外部调用源的细节。
在Dubbo服务端中,我们需要实现远程接口,并对远程服务调用进行内部的转发,转发的逻辑也很简单,首先是解析参数并组装内部参数,然后调用业务层的接口执行业务逻辑,最后组装返回结果,对于异常处理也需要在这里做掉,防止异常暴露给外部应用。
小结
网关层本质是对协议进行处理,同时将业务逻辑收敛到网关层,而不是暴露给外部。当内部业务逻辑进行重构的时候,外部调用方就不需要感知这些变化,当外部调用源增加时,内部业务逻辑不需要感知这种变化,从而将外部调用方和内部业务逻辑进行了解耦。
业务层是一个系统,无论是单机系统还是分布式系统群中的某个业务系统,业务层都是承载业务流程和规则的地方。业务层从外到内包含三层:第一层是业务服务,第二层是业务流程,第三层是业务组件。具体如下图:
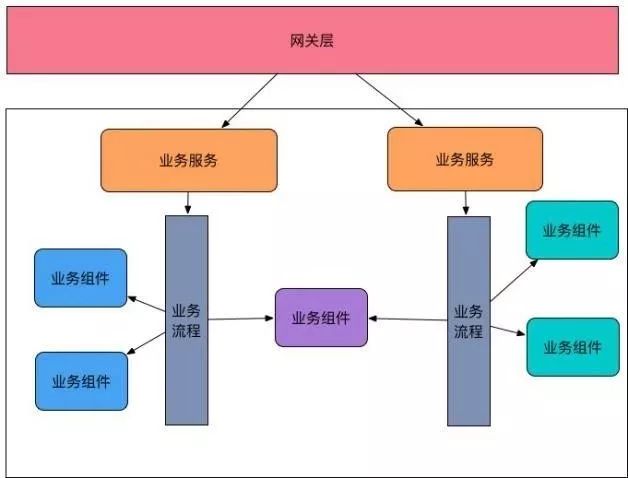
1)业务服务
业务服务是业务层对外的统一门面,它由三方面组成:业务接口、入参、出参。
业务接口
一个业务接口代表一个领域的业务服务,比如订单域的业务服务就由接口Order Service表示,会员域的业务服务就由接口Member Service表示。
接口可以按照执行性质分为读接口和写接口,比如Order Read Service和Order Write Service。读写分离的好处是可以对集群进行读写分组,从而管理流量,当然,单机系统读写分离意义不是太大。
领域内的操作则以业务接口中的方法的形式体现,比如订单域有下单create Order,取消订单cancel Order等等操作。对于这些操作,尽量设计出有业务含义的方法,而不是增删改查,当然,对于一些简单的业务,也只能增删改查。
入参
接下来,是入参的设计。入参对于读方法,比较简单,不做讨论。对于写方法,我们将入参设计成有层次的数据模型。
首先需要设计出公共的数据模型,比如订单数据模型,商家数据模型,商品数据模型等,然后将这些数据模型和一些特定业务下的个性数据结合,组成Request对象,这个request对象按照不同业务操作不同而不同,对应的返回结果就是response,它也是随着不同业务返回的参数不同。
举个例子,拿下餐饮订单来说,首先,我们应该识别出这些业务流程中一些比较基础的数据模型,比如餐饮领域的菜品、桌位等,这些模型之所以说是基础模型,是因为,不管下什么餐饮订单,菜品和桌位肯定是逃不了的,它们是可以被复用的!
因此,我们分别为这些基础模型设计相对于的DO(Domian Object):Dish DO(菜品)、Board DO(桌位)等等,接下来,我们为下餐饮订单设计一个请求对象Dish Order Create Request其中Dish Order Create Request内部包含了Dish DO和Board DO,另外会包含一些特定的属性,比如人数啊,折扣啊等等。
这样一来就能做到通用和灵活兼顾,Dish Order Create Request代表的个性化的灵活的业务入参,而Dish DO和Board DO等则代表了不易变化的基础模型。
出参
最后,是出参的设计。
对于写方法,一般出参比较简单。
对于读方法,出参往往是一个结构与层次比较复杂的组合对象。
比如查询一个订单,这个订单有订单基本信息,还有商品信息,收货人地址信息等。在设计出参的时候,结构上要设计成组合对象,但是真正查询的时候,通过查询选择器,去查询不同的组合对象。比如查询选择器设置商品查询为true,地址查询为false,那么这次查询出的订单就只包含商品,而不包含地址。
2)业务流程
业务流程其实就是对业务规则的解释,只是这种解释使用代码去实现的,我们要做的其实就是准确翻译这些业务规则,并维护好这些业务规则。
业务流程中可以大致分为三种动作节点:
组装参数节点;
规则判断节点;
执行动作节点。其中每个动作节点都是一些业务代码的片段。
举个例子,下餐饮订单,我们第一步就是将上层传入的参数组装出一个基础的Dish Order DO(组装参数节点),然后按照特定的规则去填充这个Dish Order DO(规则判断节点),然后就是调用DAO去创建Dish Order DO(执行动作节点)。
业务流程是最容易变化的地方,要想维护好业务流程并不容易,总的思想是将大的业务流程拆分成小的业务流程,抽出每个业务流程中共有的代码片段,变成可维护的业务组件。
3)业务组件
基础组件
业务组件其实是将一些内聚的可复用的代码片段进行封装。和业务流程中的三种业务节点相对应,业务组件也分为三种:组装参数组件、规则判断组件、动作执行业务组件。
业务组件的抽象往往是对业务有了深刻理解之后才进行的,盲目地进行业务组件的抽象,往往到头来白忙活。
能力
对业务组件进行进一步抽象,可以得到能力。业务能力是具有一定复用性的组件的组合,比如发短信能力=组装短信参数组件+发短信组件。
对于发短信能力,可以被不同的业务流程复用,比如订单下单成功发短信,支付成功发短信,逻辑都是相似的,只有内容不同。
能力是一种粒度比较大的组件,粒度越大,往往复用性就越小,对能力的抽取,也是基于对特定业务深刻的理解,没有一劳永逸的银弹。
更高纬度的抽象
经过本人的实践,对于互联网这样的需求变化极快的场景,更高纬度的组件抽象往往性价比很低,不建议大家去做。
基础层包含两个部分,第一是接口定义,第二是技术组件。
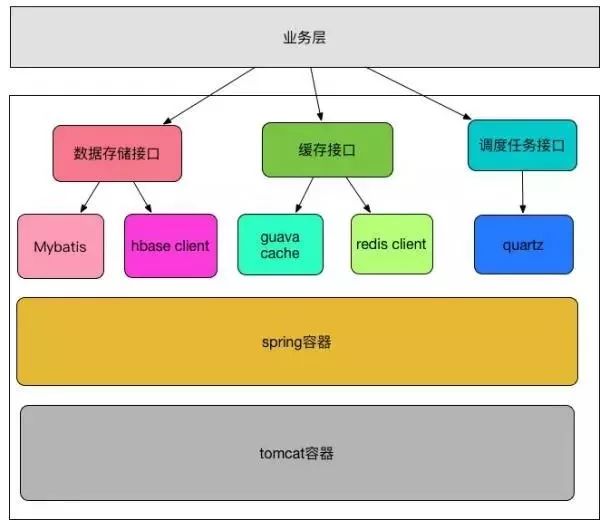
1)接口定义
接口定义是按照不同的技术框架,同时结合业务需要,设计出合理的接口,对于业务组件来说,它们只会感知技术接口,而不会去感知技术实现,我们也不应该将具体的技术细节向上暴露,这也就是所谓的面向接口编程。
技术接口往往是业务与技术之间的桥梁,接口本身是含有业务含义的,最常见的就是DAO接口,我们设计DAO接口的时候,不会设计成Insert、Update、Query这样业务无关的接口,而是设计成Insert User,Update User By Id等等和业务相关的接口。
同样的道理,设计缓存接口的时候,也不能设计成put、get这样的接口,而应该设计成cache User,deprecate User这样的接口。
2)技术组件
单机系统的技术组件一般来说分两种,一种是通用的技术组件,比如:数据存储、缓存、消息和调度任务、事务、锁。一种是基础设施,比如Spring容器,Tomcat容器。下面稍微谈谈通用技术组件。
数据存储
数据存储包括关系型数据库、非关系型数据库以及文件存储系统。
关系型数据库,比如MySQL,适合存放绝大部分业务数据。
非关系型数据库,比如HBase,可以存放历史日志,也可以对历史的MySQL数据进行归档。文件存储系统,一般都是基于Linux文件系统,比如图片、HTML文件等等,也有基于HDFS的,用于大数据分析。
缓存
缓存按响应时间分,可以分为纳秒级缓存,毫秒级缓存和百毫秒级缓存。
纳秒级缓存就是一般的基于本地内存的缓存,比如Encache;
毫秒级缓存一般是集中式的内存缓存,比如Memcache,由于访问时远程调用,因此响应时间会延长到几毫秒;
百毫秒级缓存一般是集中式可持久化的缓存,比如Redis,由于存在远程访问以及缓存击穿导致的读取持久化记录,它的响应时间会更长些,到几十甚至上百毫秒。单机系统一般用本地内存缓存就够了,当缓存被击穿的时候,直接访问数据库。
消息和调度任务
消息和调度任务本质都是一种异步化的手段,区别在于消息无法控制异步的时间,而调度任务可以。
一般,消息发送出去后,监听消息的系统会立即收到消息,从而立即触发业务逻辑的执行,而调度任务则会按照调度规则,一次或者多次的执行业务逻辑。
单机系统中消息和调度任务用到的比较少,在做日志监控的时候可能会用到消息,在进行数据报表统计的时候可能会用到调度任务。
事务
事务本质都是基于数据库去实现的,单机系统的事务就是依赖数据库的事务,我们可以使用spring-tx的事务模板进行事务操作,在业务逻辑开发中,一定要把握事务的大小,建议把业务比较紧密的一堆数据库操作放在一个事务里,不要随意的为每个方法都开启事务。
锁
单机系统中主要用到两种锁:乐观锁和悲观锁。
乐观锁依靠在数据库的业务表加版本字段来实现,每次更新都会去判断版本是否变化,如果变化则需要重试,这种锁的粒度比较小。
悲观锁是基于JDK的Lock接口的,对一个业务流程进行加锁和释放锁的操作,锁的粒度比较粗。
三、总结
以上是我经过很长一段时间的实践后摸索出来的业务技术架构,自认为还算通用,而且能够在一定程度上支撑易变的业务。
当然这套架构肯定不是银弹,不可能解决所有业务场景,所以最终还是需要围绕到具体的场景加以借鉴。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721