
本文根据DBAplus社群第84期线上分享整理而成
赵钢
当当网资深DBA
OCP 9i认证专家,十年以上Oracle及Linux/HP-UX技术经验。
曾负责管理电信通讯话单数据库、中国移动短信营销数据库、足彩福彩支付数据库、多语种博客社区数据库。
各位好,今天我的主题是 《DB运维的四个现代化》 ,看标题就能明白,是关于DBA自动化运维平台的事情。
主要是分享下我在当当想到做到的一些事情,很多都是兄弟们一起努力的结果, 这篇文章也是对我们工作进行一次总结,整个平台的实现方法并没有用到什么高大上的框架,有亮点的地方我会着重说明,当然,有兴趣了解的同学,直接提问就好。
本次分享将分为以下三部分进行:
解密DB管理四大现代化
实例分析实践痛点
从信息展现开始一步步解决
一DB管理四大现代化
首先先聊下DB在项目中的地位:

99%的软件,处理的数据最终是需要落地
从人员结构来说,DBA支持公司多项目
数据要安全,数据要及时,权限要收口
于是,DBA的工作经常成为项目进展的瓶颈。
然而,在错综复杂的电商环境中, 数据库又独具特色。一提到电商: 自然想到,双11,秒杀,大促等等, 于是下面3个特点也就不言而喻。

在当当网,我们的DB规模是这样的,数据截止到2016年3月,而现在又在增长……T_T
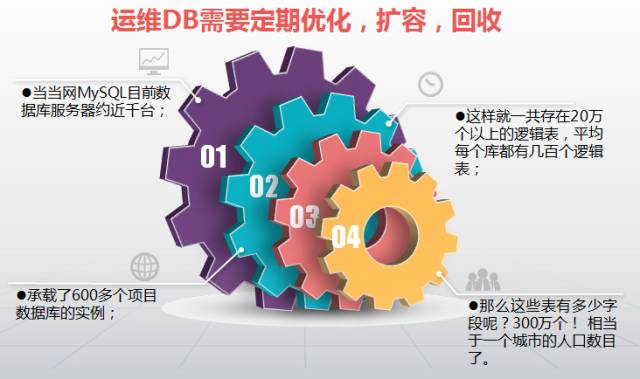
因此就会有这样的工作需求:
商品单品项目组、新来的开发同学,需要了解单品项目的表设计结构;
购物车项目管理的同学需要同步最新数据,检查项目运行效果;
订单项目的同学需要检查实时数据,监控订单量(授权给radar监控数据源);
测试的同学需要检查回归测试的数据效果。
二实例分析实践痛点
商品分类项目程序出现了bug,导致分类错误, 最有效的办法莫过于:DB中需要修改几条数据。
项目扩容,需要部署从库,项目迁移,需要切换到从库;
硬件故障,需要切换;
所有项目大大小小 500+个DB实例 (ノ゚⊿゚)ノ So,不理想的状态下, 以上工作×500倍;
DBA负责按工单导出数据,工单多了就放开查询权限,
人员流动(←_←),于是一堆不明权限,数据安全无法保证。
于是,DBA们也在思考,和开发项目拼人肉数目,肯定不切实际,我们需要自动化的平台。
根据以上问题,我们做了几个选择:
哪些信息是可以共享给开发部门的。
哪些操作DBA可以自动,符合标准的进行。
用什么方法尽可能保证数据的实时准确性
用下图来回答:
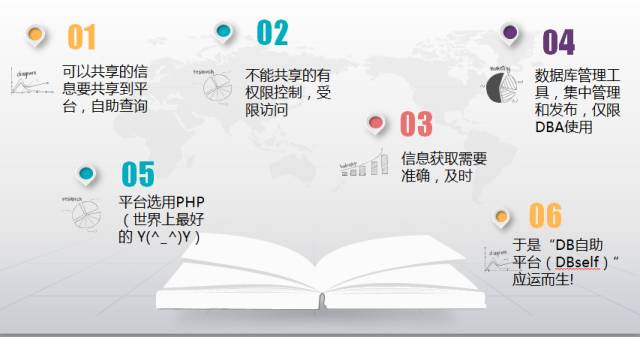
平台主要分为:信息收集展现,DBA管理工具两大部分。
数据库的元数据可以被全体技术部乃至业务部访问。但数据细节,只能有限访问(权限申请需要经过审批)这些只读的访问,一次授权,即可自助进行。
对于数据库管理(部署,备份,恢复),DBA也要编写脚本,按标准进行。后面会尽量详细介绍。
三从信息展现开始一步步解决
1、信息收集展现
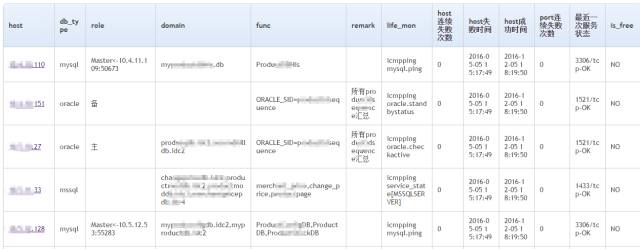
先说明下,关于数据库元数据的展现:
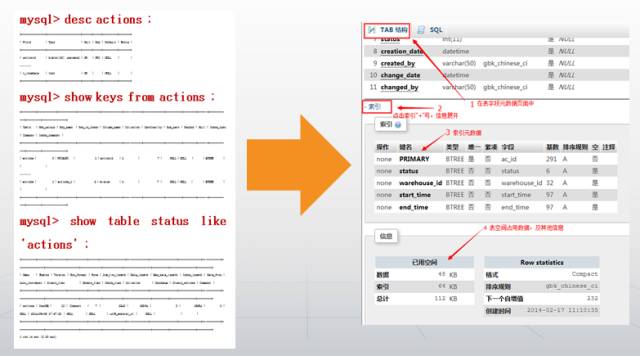
上图可见,借用phpmyadmin工具(右图),对于元数据的展现还是很完美的。完全可以替代左图的命令行模式。
当然,这里的phpmyadmin是经过修剪功能的版本,去掉了诸多管理,展示数据细节的部分。
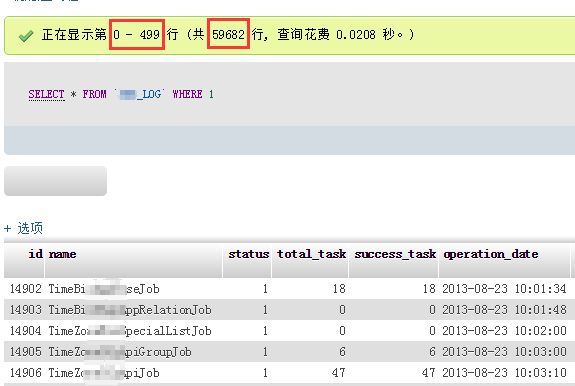
对于申请过权限的用户,才可以访问到受限的数据细节。
同时对于数据本身,也进行了限制性修改 ,仅能访问 500行的数据:
对于元数据也进行了抓取和归档(主要用shell+python定时执行 实现),这样做有几个好处:
1、便于在整个公司项目范围内,宏观的、快速的、模糊的查找想要的元数据。
2、基于元数据的定期归档,可得出数据空间变化的规律。
例如我们平台的如下功能:


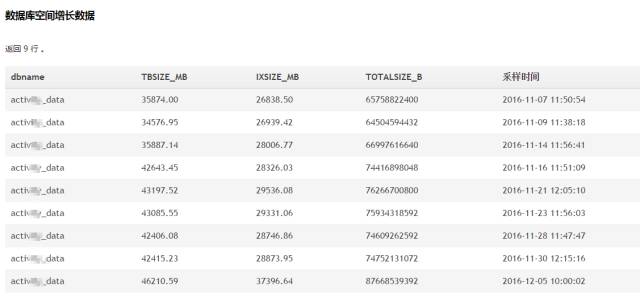
3、还可以对元数据进行统计,迅速得出那些是我们急需调优的目标(需水平拆分的大表,需垂直拆分的宽表,需要删除的重复索引,需要扩容的autoid等等)。
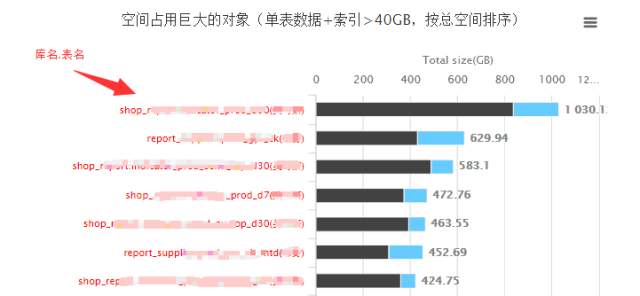
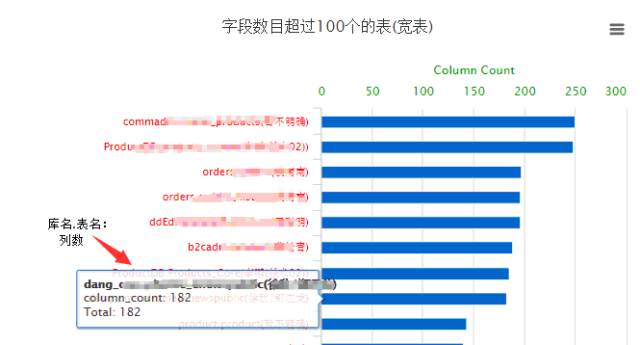
例如,我们平台的如下功能:

展示出来就是这样(图表展示我采用highchart,MySQL只负责用SQL吐数据,展示的活,就交给highchart 了):
4、管理服务器列表,对于所有服务器的固定端口(数据库端口)进行扫描,及登陆测试,获取库名,角色(主or从),等信息。
对于性能和监控数据,采用同样的方法进行抓取和分析,(数据源取自zabbix监控数据库)
这样做的好处是:
看出近期那些性能指标频繁报警,需要扩容,需要调优
那些服务器是重载,那些却过分规划即使大促也是轻载。

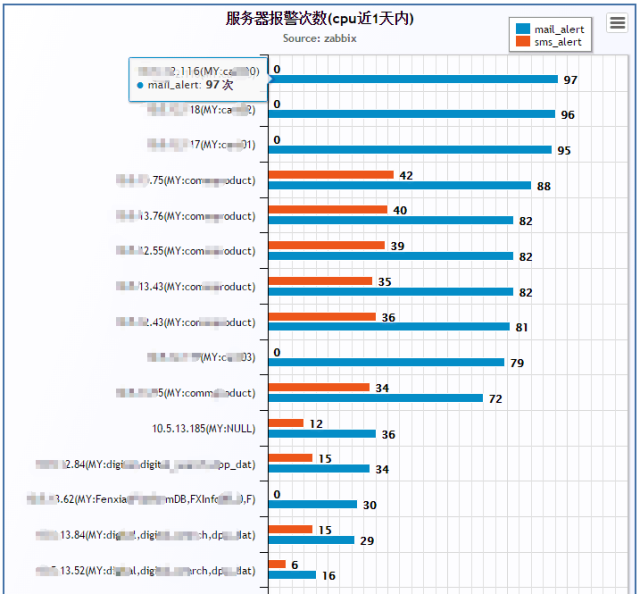
(上图屏蔽的主要是一些ip和库名信息.)
2、DBA管理工具
这部分我们也在进行中,目前DB的安装/部署的基本已经实现脚本化,主要包括下面的脚本。
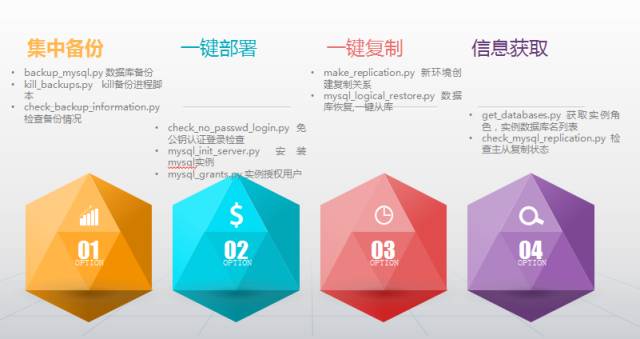
下面是部分脚本的功能说明:
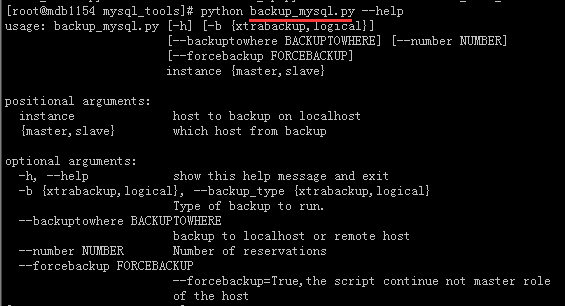
该脚本的主要功能:
根据标准初始化完成的系统,自动安装相关软件包,备份时部署在集群的从库,且无域名的从库优先,
关于备份空间的判断,先根据数据量估算本次备份所需空间,如果备份空间满足,则备份到该从库的本地,如果不满足则集中备份到大空间服务器。
备份会保留多个备份周期的备份集. 如空间吃紧,备份前,则会优先删除日期靠前的备份集。

该脚本的主要功能:
初始化MySQL时候生成环境检查
根据内存大小动态计算buffer pool大小以及随机值server-id
innoDB_buffer_pool_size=内存*80%
server-id=[IP点分十进的后两段]+三个随机数
公共用户权限导入以及导入后验证
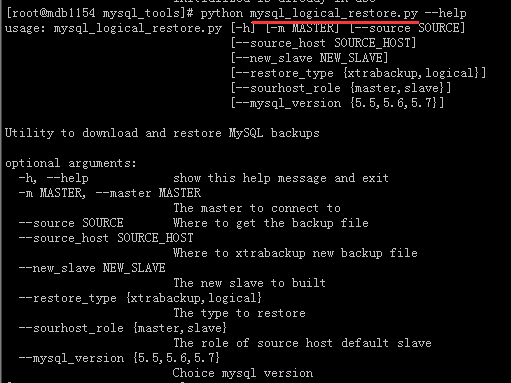
该脚本的主要功能:
从备份文件{logical,xtrabackup}恢复一个实例;
从一个从库直接{logical,xtrabackup}建立一个从库;
从一个主库直接{logical,xtrabackup}建立一个从库。
对于日常比较频繁执行的DML语句,通常处于开发部门修改数据解决线上bug的问题,我们采用了inception的部分功能,结合已经收集到的服务器列表.,只需指定将SQL即可,平台会自动送到该库指向的主库上执行DML语句。
采用inception的功能主要是对SQL的审核功能,例如,如果该SQL的影响行数超限,则终止执行。
平台则对SQL执行进行历史记录。
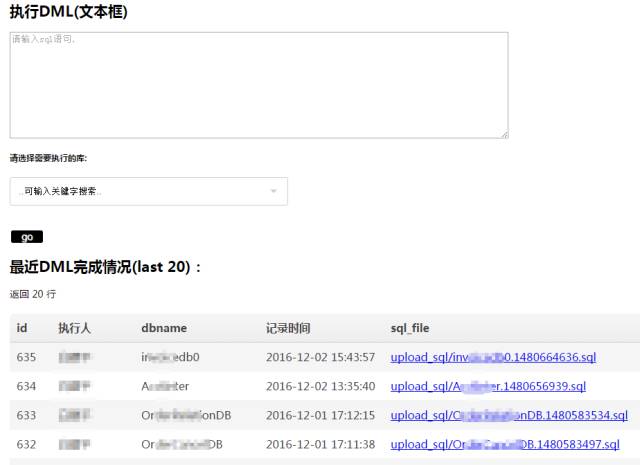
DBA管理工具这边也在逐步完成对上述管理脚本的平台化。
我的分享基本就是这些, 关于平台及工具的代码,我们也在逐步做脱敏工作,争取形成一个可以开源出来的产品, 希望对大家有些启发,也希望抛砖引玉。
Q1:目前的高可用是用什么方案?
A1:我们预期用MHA,目前还未有这方面的架构。
Q2:你们是如何进行跨机房的管理的?slave的延迟如何保证在业务可忍受的范围内的?
A2:slave延迟的问题主要从开发方面分解大事务解决。跨机房方面我们目前也尽量避免跨机房的主从架构搭建。
Q3:如何设计MySQL架构来满足如抢购类的高并发的业务?
A3:大促、秒杀业务这些方面,主要靠提前压测,并观察性能瓶颈,扩容和回收也是以性能(cpu,网络连接,磁盘)为依据来进行。
Q4:目前应对大促,秒杀业务,数据库层面扩容缩容,能否给出一些建议。
A4:这方面需要时间来改进,我们目前还很不完善,其实很多功能也是当当架构特色来设计的。即使开源也是为内部版本控制考虑。所以还未有这份精力配合。
Q5:如果要分库分表,推进这些东西开发会配合吗?
A5:我们架构部有这方面的中间价,叫sharding-JDBC,可以关注下github上的项目。
Q6:MySQL一个表最多存多少记录算大数据?有哪些合适的分表方式?
A6:存多少不重要,关键要看怎么使用它,是读多,写多,还是改多,对于一般的系统,最起码把读写分离开吧。
Q7:请问你们在线上如何解决DDL和批量delete or update 100万级的数据的?
A7:DDL是靠pt-online-schema-change工具,百万级的delete也是靠这个工具分配进行的。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721