
ArgoCD、KEDA、Crossplane 这些工具并非什么黑魔法,它们的核心都是CRD。一旦你理解了这一点,看待Kubernetes的视角将彻底被改变。

一、你已经用了很多年,却从未真正了解
大多数Kubernetes工程师每天都在使用CRD,但真正理解其原理与设计的人寥寥无几。
打开你的终端,运行以下命令:
kubectl 获取 crds
现在暂停一下。
向下滚动。
观察显示了多少行内容。
数百行?
没错,这里有一个扎心的事实:
你用Kubernetes很多年了,却根本不了解它是如何实现自身拓展的。
这些:
Argo CD的Application
KEDA的ScaledObject
Crossplane资源
cert-manager的Certificate
它们本质上都是同一个东西:自定义资源定义(CRD)
二、让你真正 “悟透” K8s的那个瞬间
大多数人以为Kubernetes只是:
Pod
部署
服务
然而,这只是表面现象。
底层的真相是:
Kubernetes不是一个平台,而是一种语言。
那CRD是什么?
CRD让你给这门语言添加新词汇。
好好想想:
你不是在“扩展”Kubernetes,你是在教它新的名词。例如:
DatabaseCluster
MLModel
TenantConfig
一旦定义完成,它们就变成:
一级API对象
可通过kubectl查询
存储在etcd中
采用RBAC进行安全保护
像原生资源一样被监控
你的构想,就此成为Kubernetes本身的一部分。
为什么这一点能颠覆一切?
大多数教程都忽略了这一点:
CRD不只是一项功能,它是整个云原生生态的基石。
你欣赏的每一款成熟的Kubernetes工具,都构建在它之上。
不是插件,不是黑科技。
仅仅是......一些新的名词而已。
三、从零开始创建一个CRD
我们来创建一个真实的例子:
DatabaseCluster,用于管理PostgreSQL或云数据库的抽象概念。
只需要关注以下3个核心点:
group
name
version
apiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinitionmetadata:name: databaseclusters.infra.example.com # 必须为:<复数>.<组>spec:group: infra.example.com # 您的 API 组(例如 apps、batch、networking.k8s.io)scope: Namespaced # 或者:集群名称:复数: databaseclusters # kubectl get databaseclusters单数: databasecluster # kubectl get databasecluster my-dbkind: DatabaseCluster # 用于 YAML 清单shortNames:- dbc # kubectl get dbcversions:- name: v1alpha1serving: true # 此版本处于活动状态并接受请求storage: true # 此版本用于 etcd 中的持久化schema:openAPIV3Schema:type: objectproperties:spec:type: objectproperties: {} # 我们将在下一步中填写status:type: objectproperties: {}
分析一下其中的关键决策:
这一行代码:
名称: databaseclusters.infra.example.com
这不仅仅是一个名字。
这是一个API端点。
Kubernetes刚刚创建了:
/apis/infra.example.com/v1alpha1/databaseclusters
无需重启,无需安装插件,无需重建服务器。
你刚刚扩展了Kubernetes API。
范围:命名空间级(Namespaced) VS 集群级 (Cluster)
命名空间:资源位于命名空间内,绝大多数CRD属于此类。
集群:全局资源,用于集群级概念,例如 cert-manager 的 ClusterIssuer或基于角色的访问控制 (RBAC)中的ClusterRole。
服务(served)VS存储 (storage)
served: true:该版本对外提供API服务。
storage: true:该版本数据持久化存储到etcd,有且仅有一个版本可设为storage: true。
这种分离是实现安全多版本CRD的关键:可以同时提供v1 和 v1alpha1版本的API服务,但只存一份v1到etcd中。
注意:不做版本控制直接改schema会破坏现有资源。
四、CRD本身不执行任何操作
很多人在这里搞混。
必须明确:CRD只定义意图,不执行任何动作。
它不会:
创建Pod
供应数据库
扩缩工作负载
一句话总结:
CRD = 词汇
Operator = 动作
如果没有控制器,执行以下命令:
kubectl get dbc
只会查到一堆静静躺在那儿的对象。
就这么一直等着,什么也不会发生。
五、构建生产级 DatabaseCluster CRD
让我们使其达到生产级别。
定义:
必填字段
校验规则
枚举
默认值
# database-cluster-crd.yamlapiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinitionmetadata:name: databaseclusters.infra.example.comannotations:controller-gen.kubebuilder.io/version: v0.14.0spec:group: infra.example.comscope: Namespacednames:plural: databaseclusterssingular: databaseclusterkind: DatabaseClustershortNames:- dbcversions:- name: v1alpha1serve: truestorage: true# 启用状态子资源(对运维人员至关重要)subresources:status: {}# kubectl get dbc 输出中显示的自定义列additionalPrinterColumns:- name: Replicastype: integerjsonPath: .spec.replicas- name: Regiontype: stringjsonPath: .spec.region- name: Phasetype: stringjsonPath: .status.phase- name: Agetype: datejsonPath: .metadata.creationTimestampschema:openAPIV3Schema:type: objectproperties:spec:type: objectrequired: [ "engine" , "replicas" , "region" ]properties:engine:type: stringenum: [ "postgres" , "mysql" , "mariadb" ]description: "要使用的数据库引擎"replicas:type: integerminimum: 1maximum: 9description: "数据库副本数"region:type: stringdescription: "AWS 区域或数据中心位置"storageGB:type: integerminimum: 10default: 20description: "存储大小(GB)"version:type: stringdescription: "数据库引擎版本(例如,PostgreSQL 的 '16.2')"status:type: objectproperties:phase:type: 字符串描述: “当前生命周期阶段:待处理、配置中、就绪、失败”端点:类型: 字符串描述: “集群就绪后的连接端点”条件:类型: 数组项:类型: 对象属性:类型:字符串 状态:类型: 字符串lastTransitionTime:类型: 字符串格式: 日期时间原因:类型: 字符串消息:类型: 字符串
六、为什么Schema至关重要
没有schema:Kubernetes几乎可以接受任何格式。
有schema:Kubernetes变成第一道防线。
无效的配置根本触及不了Operator。
将其应用到集群:
kubectl apply -f database-cluster-crd.yaml# 验证是否已注册kubectl get crd databaseclusters.infra.example.com# 创建于# databaseclusters.infra.example.com 2026-03-31T16:00:00Z
应用此配置之后,Kubernetes会立即注册新API端点,无需重启。
七、创建第一个自定义资源
现在CRD已经存在,你可以创建它的实例,就像创建任何其他Kubernetes对象一样:
# my-postgres.yamlapiVersion: infra.example.com/v1alpha1kind: DatabaseClustermetadata:name: production-postgresnamespace: databasesspec:engine: postgresreplicas: 3region: ap-south-1version: "16.2"
应用与操作:
kubectl apply -f my -postgres.yaml# 像操作任何原生资源一样操作它kubectl get dbc -n databases# NAME REPLICAS REGION PHASE AGE# production-postgres 3 ap-south-1 <none> 10skubectl describe dbc production-postgres -n databaseskubectl delete dbc production-postgres -n databases
你不再只是简单使用Kubernetes,而是在塑造它的API体系。
此时Phase列为 <none>,因为没有控制器更新状态。
注意:仅有CRD而没有控制器,是没有任何作用的。
八、CRD如何融入Kubernetes架构
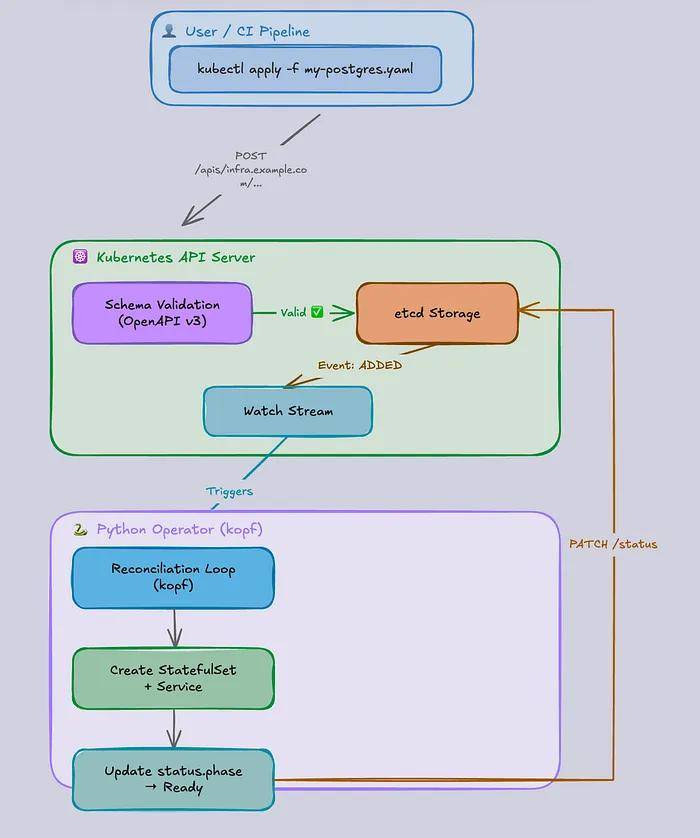
此图展示了CRD在Kubernetes架构中的完整生命周期:
应用DatabaseCluster YAML
API server 按 OpenAPI schema 校验
存入etcd
一个controller监视它
controller让实际状态匹配你的期望状态
Kubernetes 并非在执行 YAML,它是在调和你的意图。
一旦你理解了这一点……
其它一切:operators、controllers、自动化等等,都变得显而易见了。
九、为什么 status 子资源如此重要
这一点能区分新手与平台工程师。
添加:
subresources:status: {}
现在,神奇的事情发生了。
如果没有它:任何人都能覆盖系统状态
有了它:只有Operator能修改实际状态
想想看:
spec:用户定义期望状态
status:Operator上报真实状态
并且Kubernetes在API层强制执行这种分离。
这不是惯例,而是架构层面的强制性规定。
在你的Python operator中,将像这样更新status :
只有操作员才能写入 /status — 用户无法覆盖此设置。patch.status[ 'phase' ] = 'Ready'patch.status[ 'endpoint' ] = f"postgres. {name} .svc.cluster.local:5432"
status包含两种类型的信息:
1)简单字段(实际是什么?)
这些字段回答:“当前状态是什么?”
2)条件数组(健康状况如何?)
这些条件回答:“一切正常吗?当前情况如何?”
一个condition就像指示每个方面的交通信号灯。
十、通过Python与CRD交互
先来了解如何使用官方kubernetes Python client与自定义资源进行交互。这一方法适用于脚本编写、CI流水线以及数据迁移任务。
from kubernetes import client, configconfig.load_kube_config()dyn_client = client.ApiClient()custom_api = client.CustomObjectsApi(dyn_client)GROUP = "infra.example.com"VERSION = "v1alpha1"PLURAL = "databaseclusters"NAMESPACE = "databases"clusters = custom_api.list_namespaced_custom_object(group=GROUP,version=VERSION,namespace=NAMESPACE,plural=PLURAL)for cluster in clusters[ "items" ]:name = cluster[ "metadata" ][ "name" ]phase = cluster.get( "status" , {}).get( "phase" , "Unknown" )replicas = cluster[ "spec" ][ "replicas" ]print(f "{name}: phase={phase}, replicas={replicas}" )new_cluster = {"apiVersion" : f "{GROUP}/{VERSION}" ,"kind" : "DatabaseCluster" ,"metadata" : { "name" : "staging-mysql" , "namespace" : NAMESPACE},"spec" : {"engine" : "mysql" ,"replicas" : 1,"region" : "ap-south-1" ,"storageGB" : 20,"version" : "8.0"}}custom_api.create_namespaced_custom_object(group=GROUP,version=VERSION,namespace=NAMESPACE,plural=PLURAL,body=new_cluster)print( "已创建 staging-mysql 数据库集群" )(通常仅由操作员执行)status_patch = { "status" : { "phase" : "Provisioning" }}custom_api.patch_namespaced_custom_object_status(group=GROUP,version=VERSION,namespace=NAMESPACE,plural=PLURAL,name= "staging-mysql" ,body=status_patch)
这是原始的API交互层。
十一、隐藏的仪表盘技巧
添加:
additionalPrinterColumns:
现在运行:
kubectl get dbc
输出示例:
名称 副本数 区域 阶段 时间production-postgres 3 ap-south-1 就绪 2天staging-mysql 1 ap-south-1 配置中 5个月
你刚刚把kubectl变成了一个仪表盘。
无需UI和额外工具,考的仅仅只是巧妙的API设计。
十二、导致系统崩溃的常见错误
在构建自己的CRD之前,请避免以下情况:
没有 schema → 会接收无效或错误的输入数据
没有 status 子资源 → 用户可覆盖系统状态
破坏性修schema 变更 → 破坏现有资源
忘记写 Operator → 不会执行任何实际操作
大多数CRD问题不是Kubernetes本身的问题,而是API设计问题。
十三、你真正学到了什么
让我们把视角拉远一些。
这篇文章讲的不仅仅是YAML,而是了解Kubernetes的演进方式。
你学到了:
工具的实际构建方式
API的扩展方式
平台的设计方式
更重要的是:
你不再只是Kubernetes用户,而是开始像平台工程师一样思考。
十四、接下来会讲什么
目前,你的CRD仍然存在一个缺陷。
任何人都可以这样操作:
副本数:0
而Kubernetes会照单全收。
在API服务器内部运行的验证规则:
不需要webhooks,不需要额外的服务。
仅仅只是靠API层面的强制约束。
十五、最后,还有一个问题
假设你要创建一个系统,让用户可以通过声明式的方式定义数据库备份。他们不用写脚本,而是编写YAML文件即可。
用户想要输入的内容如下:
apiVersion: backup.example.com/v1kind: DatabaseBackupmetadata:name: my-postgres-dailyspec:database: "postgres-prod"schedule: "0 2 * * *" # 每天凌晨 2 点执行 retention: 7 # 保留 7 个备份
请思考:
我希望备份按指定的计划执行
我希望保留指定数量的备份
还可以补充什么?
当前实际存在多少个备份?
上一次备份是什么时候?
上一次备份是成功还是失败?
还有哪些信息值得跟踪?
备份存储位置(S3、GCS、本地存储)?
备份类型(全量、增量)?
成功或者失败通知?
其它内容?
更多运维领域不容错过的热点探讨:
OpenClaw浪潮下的智能体应用可观测体系构建
从AIOps到Agentic AIOps的战略转型
多Agent协作及统一管理实践
金融级全栈信创化与云原生实践路径
……
都能在XCOPS智能运维管理人年会-广州站上看到生产级实战案例、找到可参考可落地的方式方法。扫描下方二维码可了解大会详情及报名↓









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721