
目录
一、为什么传统巡检不够用?
二、异常检测:巡检的“第二双眼睛”
三、三大典型应用场景
四、实战经验与调优
五、未来展望
作者介绍
杨赞,去哪儿旅行DBA,负责MySQL、Redis运维和慢查询系统、巡检系统开发。
一、为什么传统巡检不够用?
传统的巡检系统都是基于固定阈值来判定指标是否异常,一般为了防止产生过多的指标异常信息,这种阈值设置的都偏高。虽然这种方式也能发现异常,但是场景过于单一,无法感知指标的动态变化,例如在业务逐渐进入高峰期时,数据库的QPS、负载或者数据体量也都是逐渐升高的,等达到日常的异常阈值再处理,时间上会比较紧张,而如果能提前发现数据库核心指标的变化以及变化幅度,那DBA就能提前介入分析和处理,也减小了因为负载过高或者容量紧张带来的业务异常的可能性。
二、异常检测:巡检的“第二双眼睛”
近年来,机器学习和人工智能技术快速发展为时序监控提供了新思路,机器学习可以从历史数据中找到自身的规律,识别出常规之外的行为。去哪儿网DBA将时序监控数据的异常检测运用到日常巡检中,通过智能分析来发现数据库指标的动态变化异常。
整体思路如下:
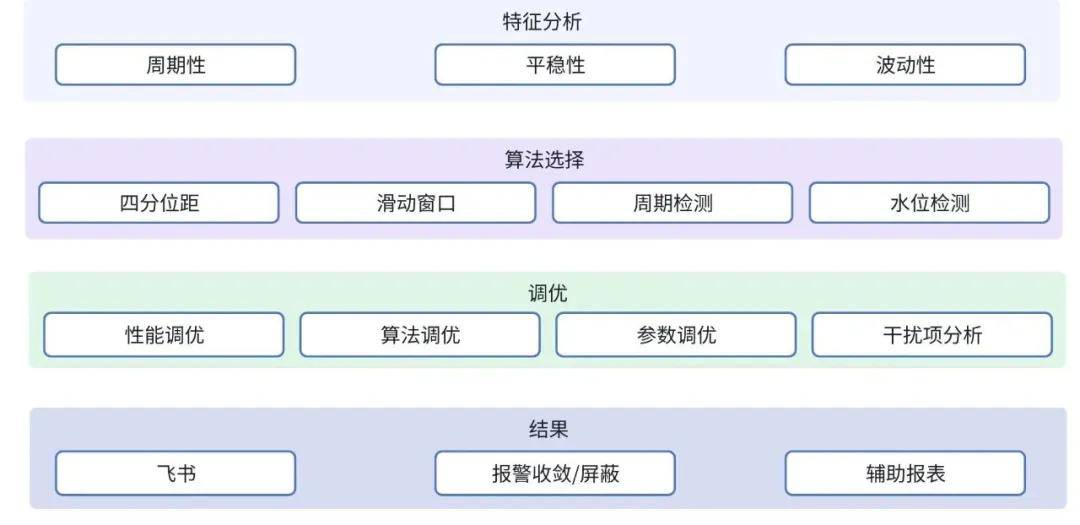
1、特征分析
有些实例的指标具有周期性的变化规律,在周期内可能会出现快速的上涨或下降,这种符合周期性变化的场景不应该算作异常,例如部分Redis内存的使用量会在夜间快速的降低而在早上又快速的上涨,需要把这种具有周期性规律的实例提取出来,进行周期性检测。
而有些实例的指标或许是持续平稳上涨的,如MySQL服务器磁盘使用量一般是平稳增长的,如果短时间内上涨很多,那么就可能有异常。所以第一步我们需要把实例指标的周期性,平稳性等变化特征进行提取。
2、算法选择
根据不同特征需求,使用不同的转换算法或异常检测算法进行处理。通过滑动窗口法将监控数据转换生成新的曲线;通过四分位距法进行异常点的检测;
通过周期检测算法将有周期性规律的指标识别出来并且获得周期长度,检测出不符合周期规律的情况;通过水位检测识别出指标水位突然上升的情况等等。
3、调优
通过算法识别出来的异常点不一定是真实业务场景的异常点,因为异常算法只是从数学的角度进行的检测,即使考虑到历史规律特性,在某些场景下的算法识别的异常点我们并不需要处理,所以最终结果需要通过动态阈值和静态阈值参数相结合。
机器学习可以通过历史数据自动计算出动态阈值,可以通过窗口大小、灵敏度等算法参数影响动态阈值的变化,但有些场景还需要静态阈值给予辅助判断,例如磁盘空间虽然快速上涨,如果使用率还很低,这种场景我们暂时不需要做任何处理,也就不需要把它识别成异常点,所以需要设置一个上边界阈值。
通过一些特定的参数和静态阈值,对不同的指标,不同的集群赋予一些特殊的意义,我们希望最终暴露出来的异常点都是我们需要处理的场景。另外一些已知干扰项,例如节点迁移,改表工单,参数配置不合理等也需要考虑进算法中。
4、报警收敛
为避免同一消息发送很多次,从一个报警第一次发送开始计时,同一个消息在近n个小时只发送一次消息,剩下的报警在原消息的内容上更新,只显示最新的检测内容。另外一个集群的多个实例同时报警收敛为一个消息,一组集群同时报警收敛为一个消息,这样大大减少了报警数量,可以避免由于接收到大量的相同消息而把其它需要关注的消息忽略掉。
三、三大典型应用场景
1、平稳趋势异常检测
MySQL服务器磁盘使用量、服务器内存使用量、Redis内存使用量等绝大部分监控指标的监控曲线特征基本是相同的,也就是正常情况下趋势平稳(平稳上升/下降,或者变化趋势不明显),这类监控指标在底层可以共用一套异常检测逻辑,通过不同的参数来调整各自的特征。上面再封装一层不同的业务检测逻辑进行定制化,减少误报。本章节以MySQL磁盘使用率检测为例进行介绍。
1) 场景分析
MySQL磁盘使用率一般都是均匀上涨的,如下面监控曲线展示,在红框标识的范围之前,使用率变化非常平稳,对于这种场景,如果使用率突然增加可视为异常,如红框范围内的数据:
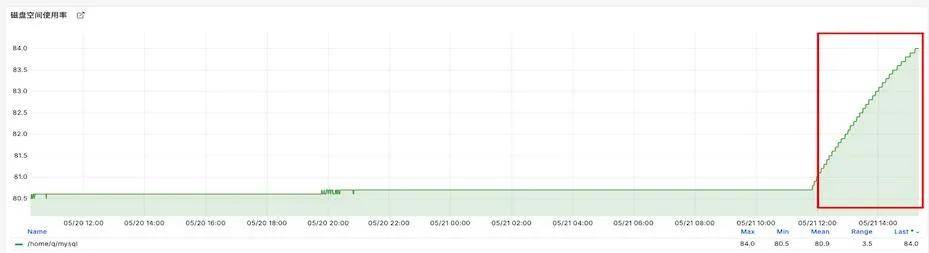
报警信息如下:

2)平稳趋势异常检测实现
平稳趋势异常检测使用的DoubleRollingAggregate算法,是一种窗口检测算法,其主要原理如下:
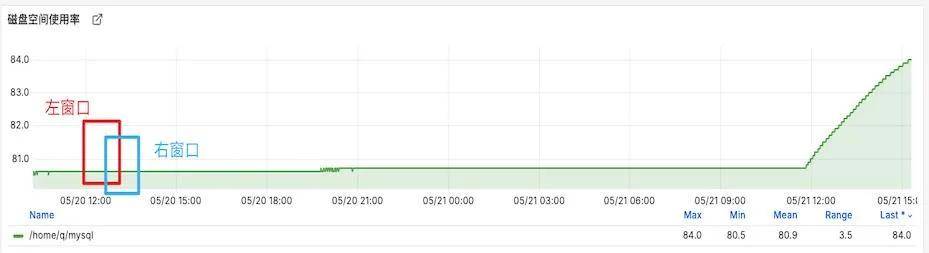
在监控曲线上创建两个滑动窗口,每个窗口覆盖n个监控点(可设置),两个窗口依次从左向右滑动,右窗口的平均值-左窗口的平均值的结果生成一条新的曲线,也可以根据需求计算每个窗口的中位数/最大值/IQR等指标,得到的数据曲线如下:
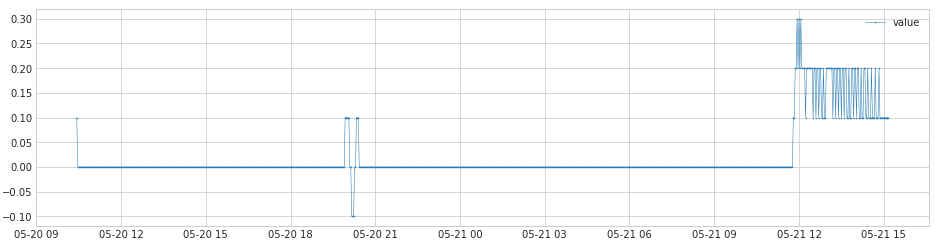
新曲线小于0的点说明是原曲线在下降,新曲线大于0的点说明是原曲线在上升,曲线上绝对值越大,那么变化(上升/下降)的幅度就越大。
可以根据新曲线大于0/小于0的点的个数占总点数的比例,来判断整体趋势上升或下降的程度。
窗口大小可调节,窗口越大,结果越平缓,IQR检测时越能消除噪音,负面影响就是可能漏掉一些异常点。
3)检测调优
根据磁盘增长的特性,检测逻辑如下:
①在磁盘使用率小于设定阈值时检测到有变化异常,但是异常时间范围内有对应实例中的表在执行DDL操作功能,且工单执行时间范围和异常时间范围吻合度较高,则不记为需要关注的异常现象。
②在磁盘使用率小于设定阈值时检测到有变化异常,但是有数据在往其主机上进行迁移,迁移执行时间范围和异常时间范围吻合度较高,则不记为需要关注的异常现象。
有些实例没有设置max_binlog_files参数,只设置了保留7天的binlog,在有归档任务时可能会产生几百G的binlog,导致磁盘异常上涨,这种场景会把这台服务器上的所有实例信息展示出来,包括参数配置,binlog大小等信息,方便快速定位问题。所以在磁盘使用量异常报警消息中增加了一个辅助报表协助DBA定位磁盘使用异常的原因。报表内容如下:
4)稳定性算法延伸
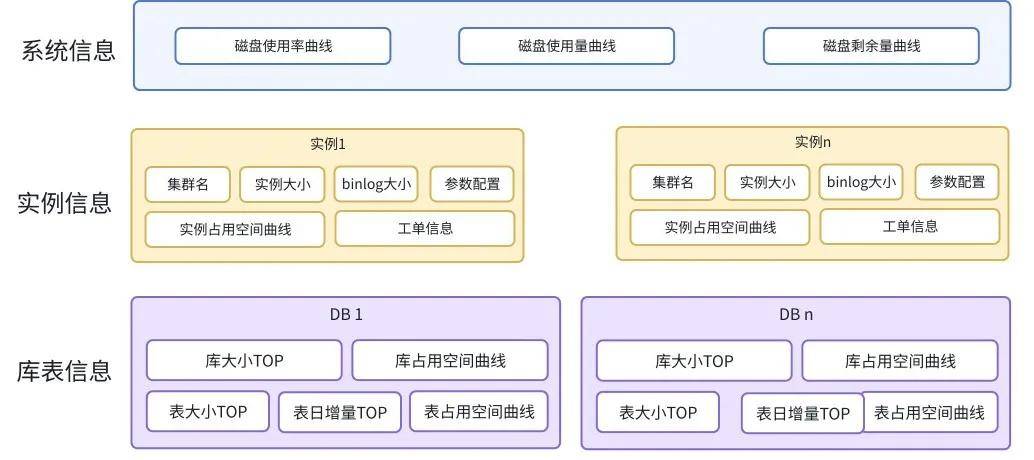
稳定性算法通过调整一些参数就可以检测到长期缓慢增涨的场景,例如下面监控图是MySQL扫描行数的监控图,由于业务新上线了一个sql,随着表数据量增加和执行频率增加,导致实例扫描行数长期缓慢上涨,,在造成严重的慢查询前需要检测出这种异常来。
具体实现如下:
先过滤出近一天最大扫描行数大于设定阈值的实例。对于这种长期增长的检测可以简化为对比每天高峰期时间扫描行数异常变化的检测,取每天高峰时间内的一个监控点,连续取近30天的监控数据,然后对这30个监控点进行平稳性异常检测,如设置窗口大小为5,每个窗口取最大值,计算两个窗口的差,通过判断新曲线正值的比例,即可判断出这种增长异常。
为什么不简单的使用扫描行数大于某个阈值就视为异常呢?首先各个实例对应业务场景不同,阈值的设定无法进行较好的统一,设置较低告警信息太多,设置较高会导致漏报。如果和趋势判断结合,就能弥补固定阈值检测导致的漏报问题,并且可以提前发现风险进行介入处理。
2、周期性变化异常检测
对于实例的QPS,MySQL的扫描行数,Redis内存使用这些指标,有些业务场景下是具有周期性变化规律的。但是最近一段时间突然脱离了周期性的变化范围或幅度,这种异常情况也需要进行识别,本章节以Redis周期性内存使用量异常检测介绍符合周期性变化特征的异常检测。
1) 场景分析
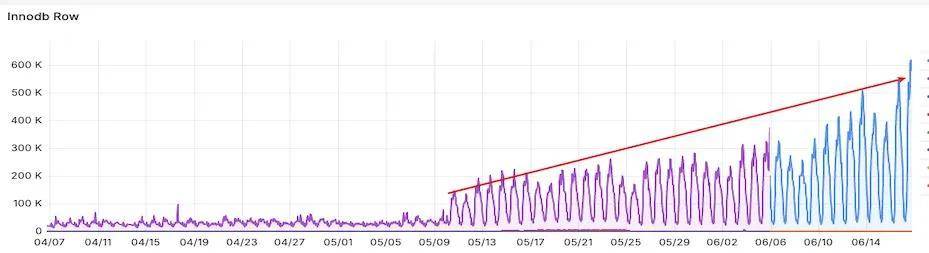
以下是一个Redis实例内存使用率监控数据:

从监控图上可以看出该Redis实例的内存使用有两个明显特点:
对于这种情况我们重点关注的是连续周期的变化趋势是不是一致的,最近的变化和之前的同周期变化有无较大差异,而对于单个周期内的增减变化不予以重点关注。通过周期性异常检测算法检测结果如下,红色的监控点是检测出来的异常点。可以看出最近一个周期的变化量明显高于前面的。
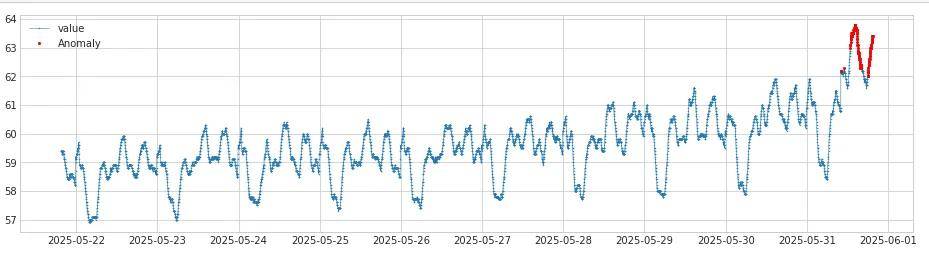
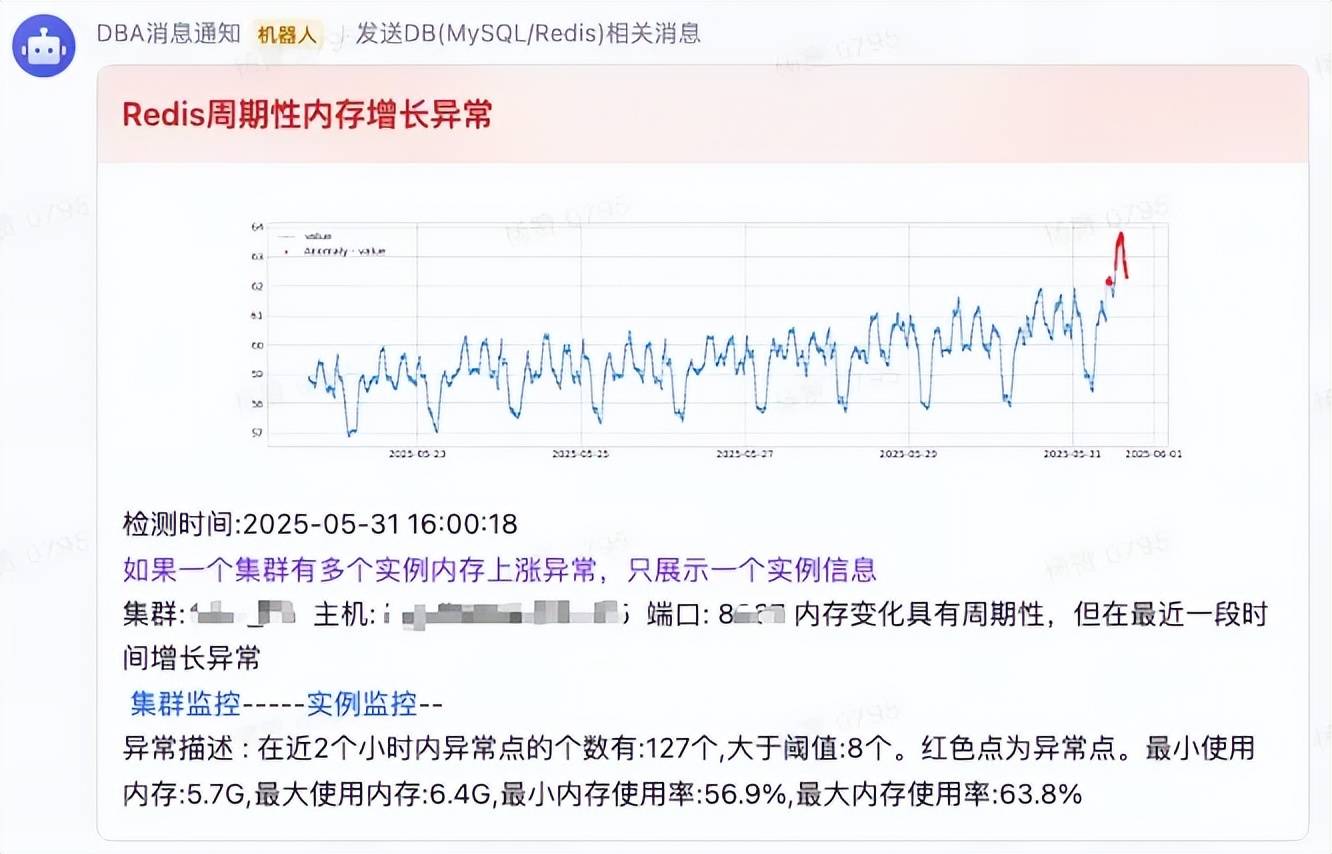
报警消息如下:
2)周期性异常检测算法实现原理
周期性检测通过SeasonalAD算法实现,此算法通过pipenet连接多个数据转换器和异常检测器来检测出异常点,具体流程如下:

a.数据转换器deseasonal_residual: deseasonal_residual通过ClassicSeasonalDecomposition算法去除周期性的规律特性。基于自相关函数(ACF)获取周期长度,经典的周期性分解假设时间序列是由趋势项 (trend)、季节项 (seasonal pattern) 和噪声(即残差) 三部分加和而成的。此步骤通过移动平均计算并移除趋势成分,通过计算去趋势化后序列在多个季节周期上的平均值来提取季节模式,最终返回残差序列。 返回的结果如下:
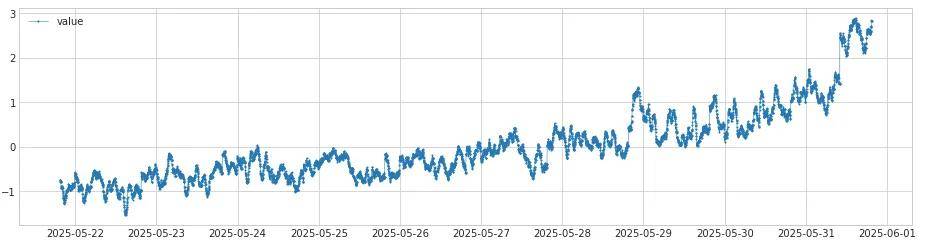
b. 异常分析:异常分析通过由两条检测链路进行检测,然后取两个链路结果交集。
链路1 sin_check:用于检测上升的异常或检测下降的异常,或者都检测,通过参数side设置。例如side = "positive",那么sin_check输出的异常点是所有deseasonal_residual大于0的点,如下:
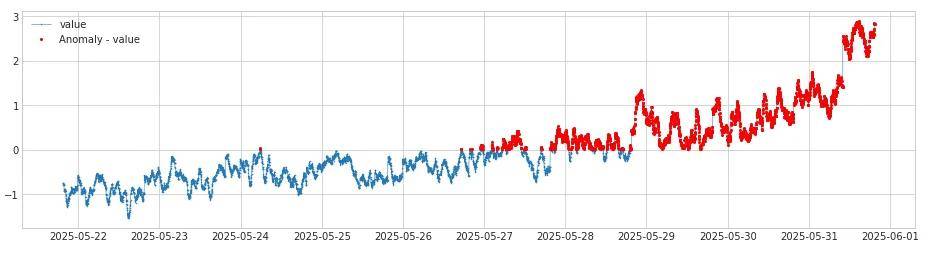
这样再和链路2的iqr_ad求交集后,就只剩下iqr_ad上涨的异常点了。
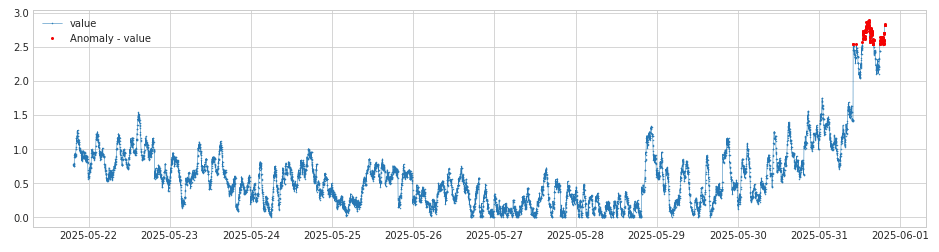
链路2中有两个算法,首先是abs_residual,用于计算deseasonal_residual结果的绝对值,转化为绝对值是为了在使用四分位距法检测异常时便于计算,转化为绝对值后的结果如下:

通过abs_residual转换的结果再通过iqr_ad(InterQuartileRangeAD)的四分位距法计算离群点,检测结果如下,其中红色为离群点(异常点):
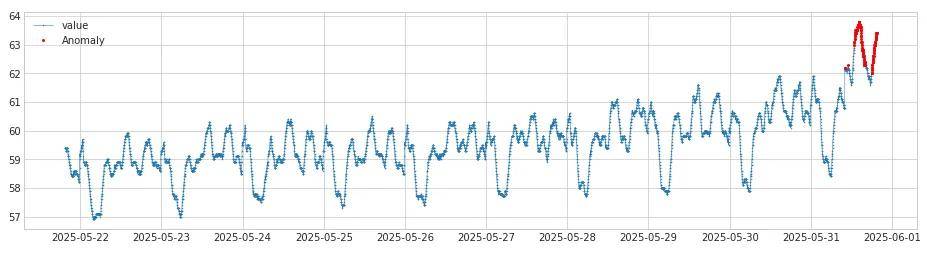
最后将链路1 sign_check检测出来的异常点和链路2 检测出来的异常点求交集,得到最终结果如下,其中红色部分为我们需要关注的异常点:
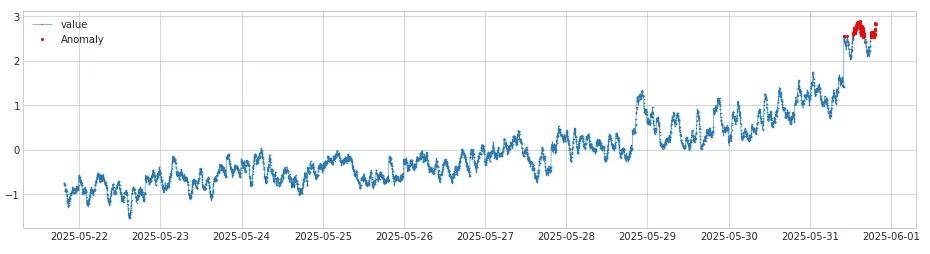
在原始监控图标识出上面检测到的异常点,得到的最终结果如下:
3)检测调优
在使用周期性变化异常检测之前,首先要识别出要检测的指标是否具有周期性变化的规律,通过机器学习模型训练,对近n天的监控数据进行分解周期特征,计算自相关性来获得周期信息。
一般情况下这种周期性规律不会有很大的变化,所以在初始节点将需要进行检测的指标全部遍历检测一遍,然后将符合周期性的集群信息记录到元数据库中,后面再定时更新相关元数据。
在进行周期性变化异常检测时只检测数据库中有相应记录的集群即可。另外对于有周期性变化规律的集群指标,在进行平稳性异常检测时可以很好的进行过滤或者设置特殊的阈值。
在使用周期性变化异常检测时还需要有其他检测标准进行联合判断,否则可能会导致很多无效的异常信息,在满足下列其中一项条件的情况下,对于Redis内存使用量检测,即使周期性变化监测到有异常行为也被视为安全范围内的异常波动,不需要关注和进行消息提醒:
3、突变异常检测
这种情况是指在很短时间范围(瞬时)内,监控指标突然发生较大幅度的变化,下面以MySQL服务器CPU水位变化检测和QPS异常检测为例分别介绍。
1) MySQL服务器CPU水位变化
①场景分析
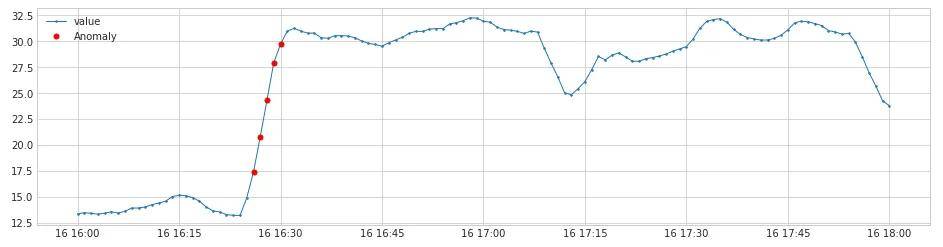
正常情况下,MySQL的CPU水位在20%以下,常规报警阈值设置为50%,在达到报警阈值之前,如果cpu水位突然上涨并持续一段时间,说明业务有不合理的请求,需要关注。 如下面所示的监控曲线,在16:25时间点突然上涨约一倍的量,并一直持续保持在30%的使用率,对于这种瞬时突变的场景应视为异常现象:
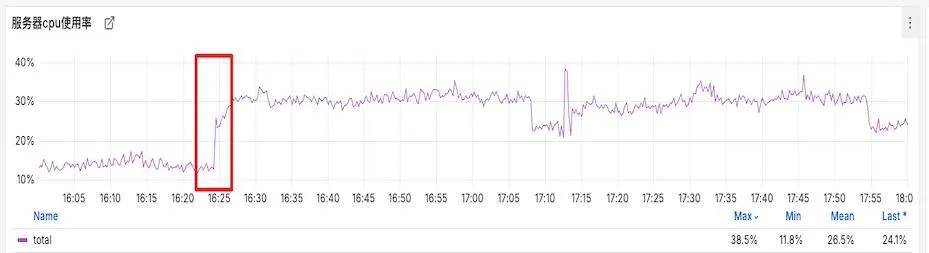
图4-1-1
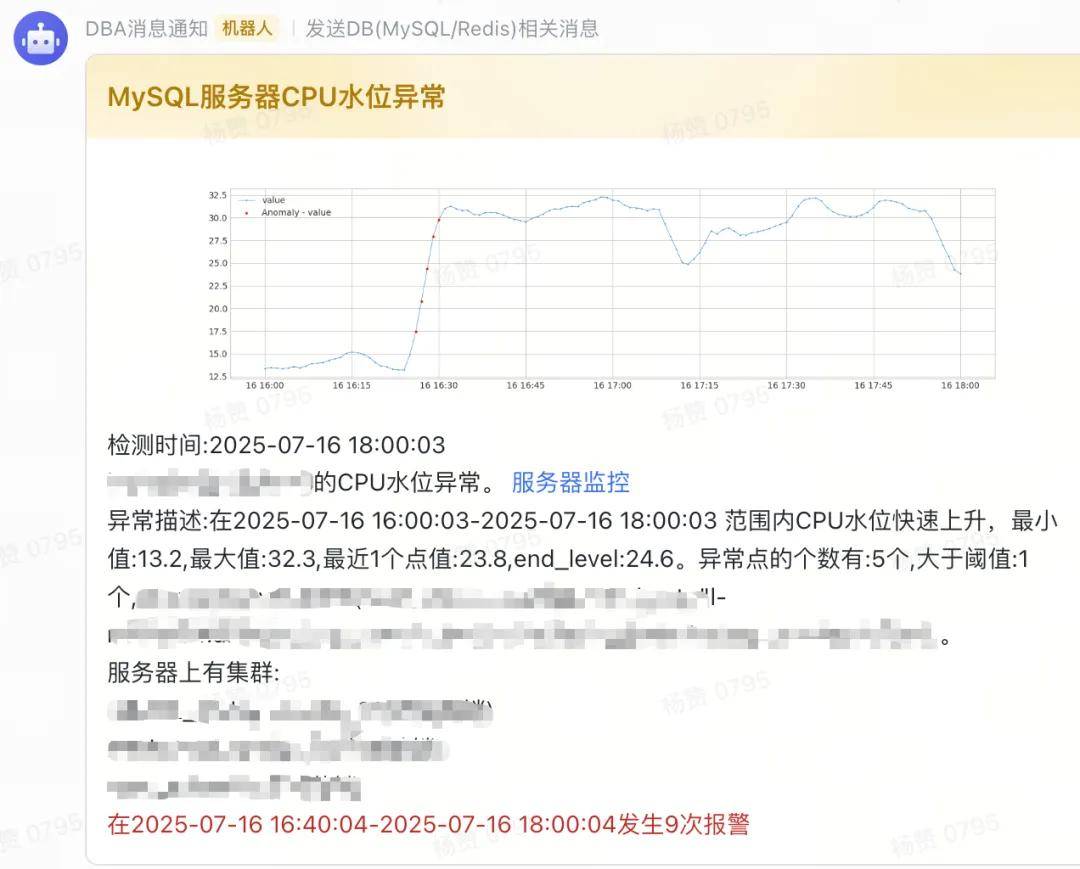
报警信息:
②水位监测实现原理
水位突变检测使用LevelShiftAD检测算法,它使用了多个转换器和检测器,通过pipenet连接起来。
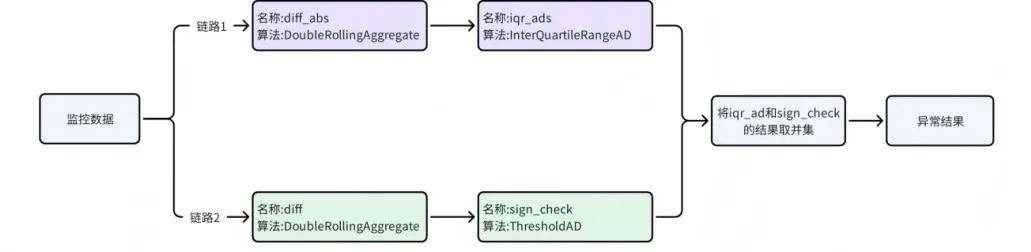
链路1先用DoubleRollingAggregate(diff_abs)算法进行数据转换,同时使用两个滑动窗口从左向右滑动,计算两个滑动窗口的中位数的绝对差值(Absolute difference),产生一组新的时间序列。再通过InterQuartileRangeAD(iqr_ads)四分位距法计算离群点。
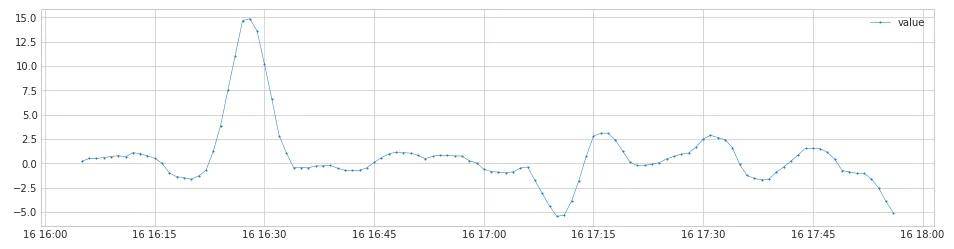
diff_abs将图4-1-1监控数据转换成新的时间序列,形成的曲线结果如下:

将diff_abs转化后的时间序列作为iqr_ads的输入,通过iqr计算出异常点,异常检测之后的图示结果如下,红色点是异常点:
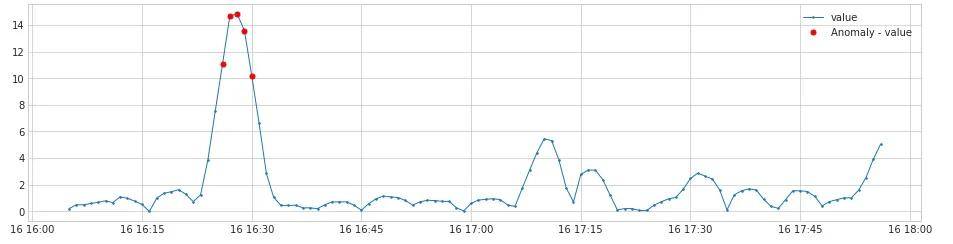
链路2同样先通过DoubleRollingAggregate(diff)算法进行数据转换,不同的是这次是计算的两个窗口中位数的差值,产生另一组新的时间序列,形成的曲线如下。然后再通过ThresholdAD(sign_check)算法检测异常点。
sign_check作用和周期性检测中的sign_check一样,用于区分方向性,这里只检测水位上升,所以所有正数都是异常点。 图示结果如下:
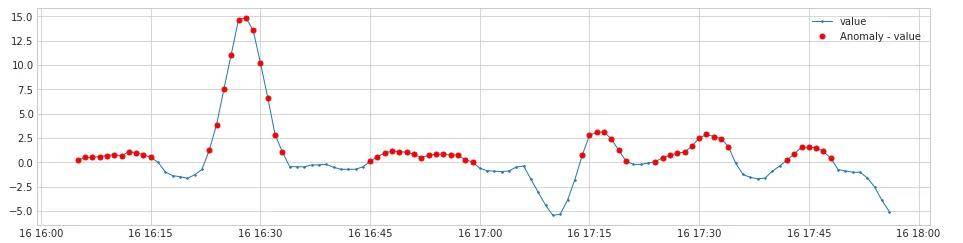
链路1和链路2的检测结果求交集,获得最后的结果,检测出水位突然上升的边缘,图示如下:
③检测调优
通过静态参数过滤掉一些没有必要的报警,例如如果cpu的最大值小于阈值,则不算异常。如果最近几个点的平均值小于阈值,则不算异常,因为已经恢复了,没必要重复报警。一些BI类业务设置高阈值。
2)QPS异常负增长检测
QPS虽然波动很大,但一般都是向上突增,即使有向下的波动其变化幅度也不应该很大。如果一个实例的QPS突然降低到几乎为零,然后又快速恢复,那这种情况是存在异常的。本章节介绍检测QPS掉0的场景。注意这里说的掉0是突然降低到很低的水平,不一定全是0。
① 场景分析
在大事务提交时,由于写binlog耗时长,将Binlog Events写入Binlog文件的过程必须要串行执行,只有一个事务写完了,另外一个事务才能执行,这时可能导致写操作掉0。低版本的MySQL是单线程复制,从节点应用大事务时,也会导致从节点QPS掉0,并伴有主从延迟。如下监控所示,在约16:30时刻QPS突然大幅度降低,然后又快速恢复。
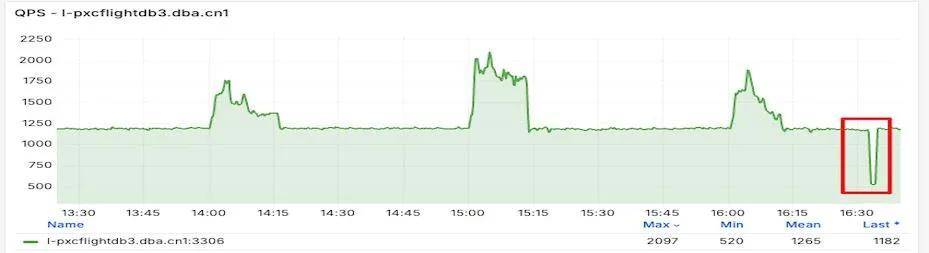
通过异常检测算法检测出来的效果如下(红色点是异常点):
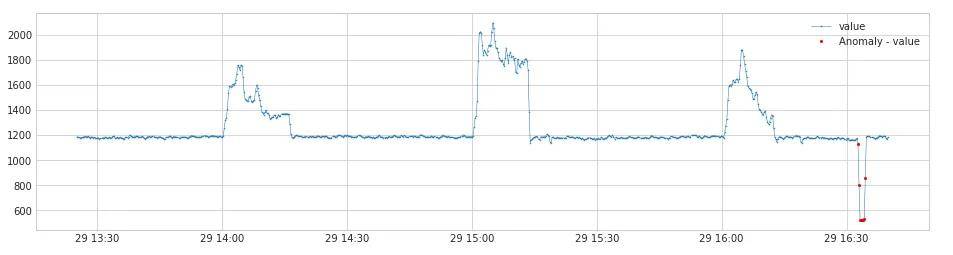
② 算法实现原理
这种指标突然掉0的异常情况使用IQR(Interquartile Range,四分位距)检测可以快速地把异常值筛选出来。IQR是统计学中衡量数据分散程度的指标,特别适合处理非正态分布或存在异常值的数据。通过聚焦数据中间50%的分布范围,规避极端值干扰,是数据分析中稳健的离散度度量工具。
很多异常检测都是把原始数据转换后,通过IQR进行的离群点检测,是一种基本的离群点检测算法。
IQR 描述的是数据集中“中间50%”的数据范围,详细概念如下:
Q1(第1四分位数):排名在前25%位置的数值(例:班级考试第25名的分数)
Q3(第3四分位数):排名在前75%位置的数值(例:班级考试第75名的分数)

若数据超出 [








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721