
李连勇,2019年3月加入去哪儿网,现负责国内机票交易团队,此前在多家知名电商从事后端架构工作,涉及商品,订单,支付等核心系统,对高并发高性能系统有大量优化实践经验。
我们在去哪儿交易拦截可视化项目中,落地了自动化根因分析(RCA Root Cause Analysis)方案,实现了秒级根因分析准确率95%以上,以及常见业务分析场景小时级接入,极大地提升了业务分析效率,获得业务方广泛认可。本文通过项目的前因后果介绍,结合业界方案,向大家分享我们一路的思考和成果。
一、背景
机票核心指标“交易拦截率”反映用户在购买环节的顺畅度,一旦出现问题,直接影响用户支付转化,对业务影响极大。同时,拦截率问题错误原因较多,参考支付环节业务错误码共280多个,日常90多个有量,又叠加航程类型,产品类型,航司,舱位等10几个业务属性,主要维度叉乘后理论上多达5600w种错误集合,出现问题后需要在短时间内定位出根因问题,对团队考验极大。
拦截率问题按紧急程度主要分两类:
指标恶化后的日常分析。日常分析经历几轮优化都会总结出一些经验,但每次人员迭代都要重新熟悉,往往前一个月都在梳理监控,分析数据,效率极低
故障报警。故障报警更是一下子几十个人分别从各种系统里查蛛丝马迹,极度依赖人员经验。
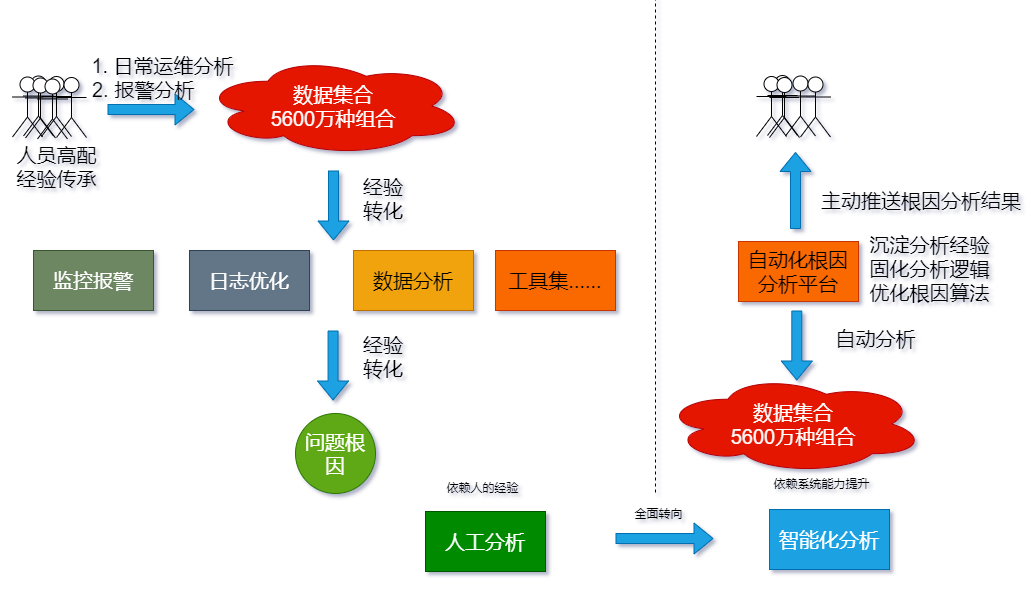
为了保证拦截率问题排查效率,我们做了很多尝试和努力,主要集中在三个方面:
人员高配
经验传承
支撑工具迭代
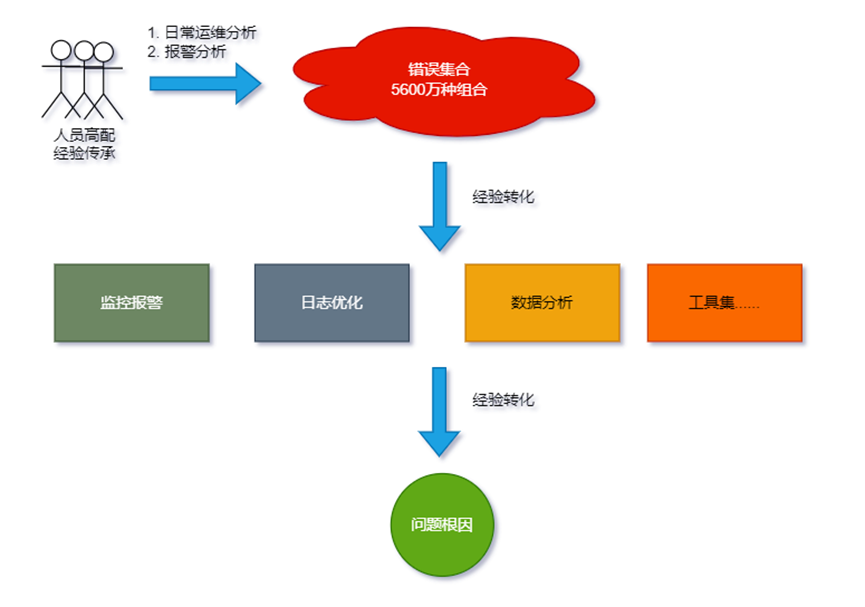
如上图所示, 通过以上措施,拦截率排查效率得到了明显改善,但仍然面临一些严峻挑战:
排查效率不稳定
依赖经验,不同人排查效率差别大,并且一旦工具集没有覆盖这种错误情况,排查成本大幅增长。
团队长期压力较大
P0级报警,分秒必争,同时问题复杂,排查工具较多,对人的要求非常高,一旦关键人员不在或者排查思路有误,排查效率就得不到保证,长期下来造成团队压力较大,非常不利于团队成长。
经验传承周期长
即使优秀人员面对这么多错误种类和工具,理清思路也需要较长时间,尤其对新人的挫败感较重。
工具扩展性差,维护成本高
监控,日志,分析策略无法满足不断变化的业务场景,业务变动后这些工具如果不及时更新,新场景错误case难以较快排查。
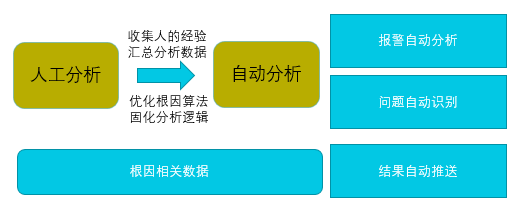
基于以上问题,借助数字化方法论,希望把过去的经验固化成系统能力,把对人的高要求转化成系统能力提升,最终实现业务可视化和根因分析自动化。
二、系统调研
根因分析自动化如何落地是业界通用难点,主要体现在对实施难度,准确性和时效性的高要求上,比较主流的解决方案包括依赖机器学习的降维归类和依赖算法的启发性搜索,依赖机器学习往往需要依赖大量数据,且复杂性较高,所以本项目选择了算法方向。
这方面比较好的方案包括Adtributor,Recursive Adtributor,iDice,HotSpot,Squeeze等,这些方案都是基于预测+搜索剪枝原理的通用方案,算法偏学术也比较复杂,对复杂场景中分析数据的要求,分析经验的提炼基本没有涉及,而这两点对项目落地至关重要。
调研主要关注的两个要点:
分析数据必须包含根因信息,如何做到?
以往积累的人工分析经验如何提取和系统化?
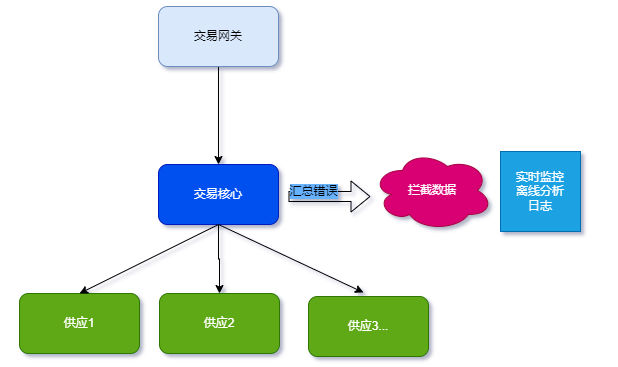
如上图,交易核心系统汇总了主要拦截数据,主要包含两点意思:
交易核心系统包含主要的拦截逻辑判断。
下游系统把错误根因传输到了交易核心系统,由交易核心系统控制拦截构建。
这两点很重要,这两点决定了交易核心系统推送的拦截数据可以包含根因信息,接下就分析如何包含。
针对根因信息我们希望知道的是:哪个维度出现了什么问题导致的?
拆解一下:
哪个维度:对应业务属性,比如产品,航司,航线,端等
什么问题:反应系统拦截逻辑及错误原因,可以用合适的错误码表达
得出根因分析数据=业务属性+系统错误码
根因确定的标准:找到哪个细粒维度在故障前后波动最大最相关?
细粒维度:业务属性+错误码的多维度组合
故障前后:两个时间段
波动最大最相关:哪个细粒维度的同比差值最大,这个分析经验得出的算法相对其他通用算法,大大简化了算法难度。
对比业界相对简单的Adtributor算法,波动最大最相关它用了两个指标:
解释力(Explanatory power),用来反应该维度对整体异常的相关性 ,计算相对简单。
惊奇度(Surprise) ,用来反应该维度自身的波动性,计算相对复杂
整体算法更重维度波动性大小(惊奇度),但在业务实际场景中更加注重维度相关性(解释力),举个例子解释一下:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
按上边表格,CZ航司变化幅度50%,按JS散度计算更有惊奇度,Adtributor算法会把根因归到CZ,如果用我们归纳的差值占比计算MU才是最大因素,从实际业务中,这也是符合逻辑的。
对分析经验梳理总结一下,基于数据特点和历史经验,我们放弃了维度波动性,只用相关性解释根因,大大简化了算法难度。
三、方案
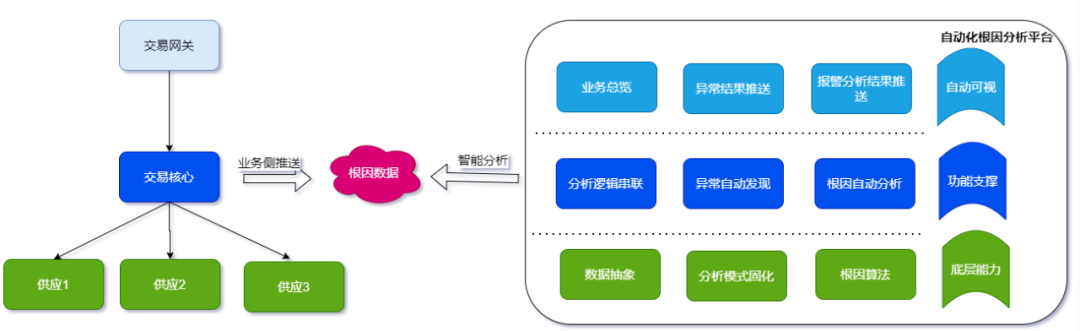
根因数据=业务属性+系统错误码
拦截数据要确定包含最底层的根因数据,这点通过逐层透传适配就能做到,另外为了错误码的易理解性,我们对错误码进行了一些设计:
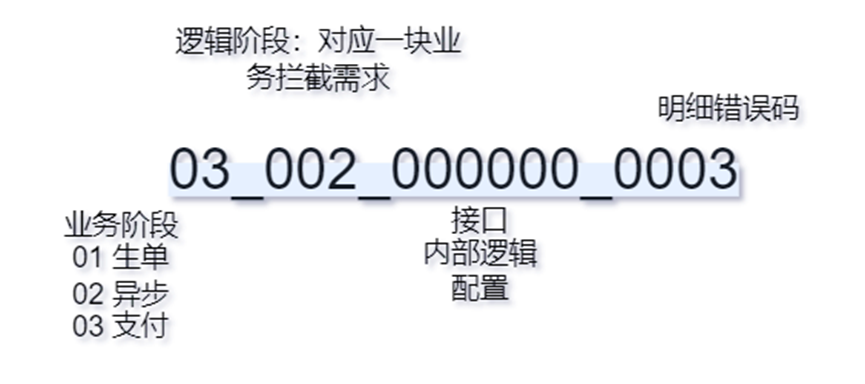
通过以上设计有如下好处:
配合后续的错误码文案对应,可以让人很容易理解根因分析结果;
便于进行逻辑降维,比如某接口出问题错误码较多时,可以直接定位到接口问题;
便于整合监控,日志等信息;
配合代码层面设计,很容易兼容后续逻辑扩展。
实施逻辑汇总如下:
自动化根因分析= 根因数据+根因算法+分析逻辑
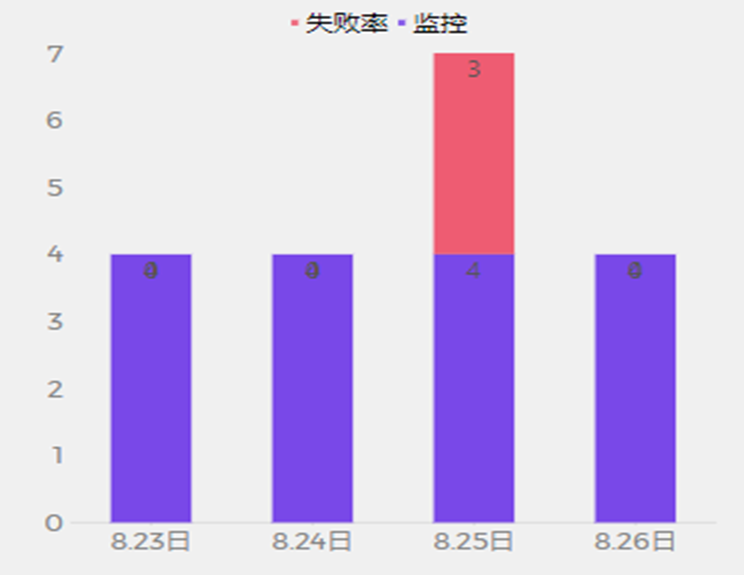
找到哪个细粒维度在故障前后波动最大最相关?
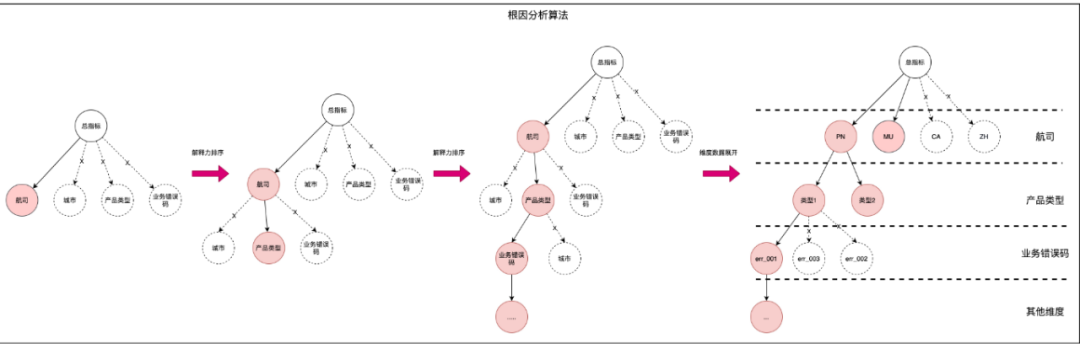
整体思想和HotSpot算法类似,衡量指标对比Adtributor 算法,放弃了波动性这个因素,只用差值大小来表达相关性,并且针对通过率数据特点做了几点假设来简化算法:
1)默认未来时间点总量不变,即假设预测值=故障前的值,并且统一率和量的算法,错误率归因因为总量不变就变成了错误量归因。
2)出现问题一般是一种问题而不是一系列根因问题,实际业务是这样,实践中可以支持多个问题同时出现,主要看差值占比是否在阀值以上,而这个阀值因为问题不会太多往往较大,便于搜索剪枝。
3)存量部分没有占比过大的维度,而增量部分占比大,这样差值占比这种简单算法就可以满足业务需求
这样其实就把问题简化成25号的红色部分占比最大的细粒维度是哪个?
1)根因分析的效率优化
根因分析过程中需要查询多种不同维度组合的数据。查询次数多,导致整体根因分析执行时长特别长,5分钟左右才能分析完成,不能满足报警快速自动根因的要求
2)优化手段
①降低查询数据量。在查询时对数据做聚合,只查需要用到的维度的数据;时间敏感的把选定时间段缩小,只要保证不影响根因结论即可。
②依赖数据一次性加载。根因分析执行前,统计需要用到的数据维度。一次查询需要用到的数据
③通过calcite组件实现内存数据的sql化查询。在根因分析的过程中通过动态拼接sql查询内存数据,完成不同维度数据的多次查询
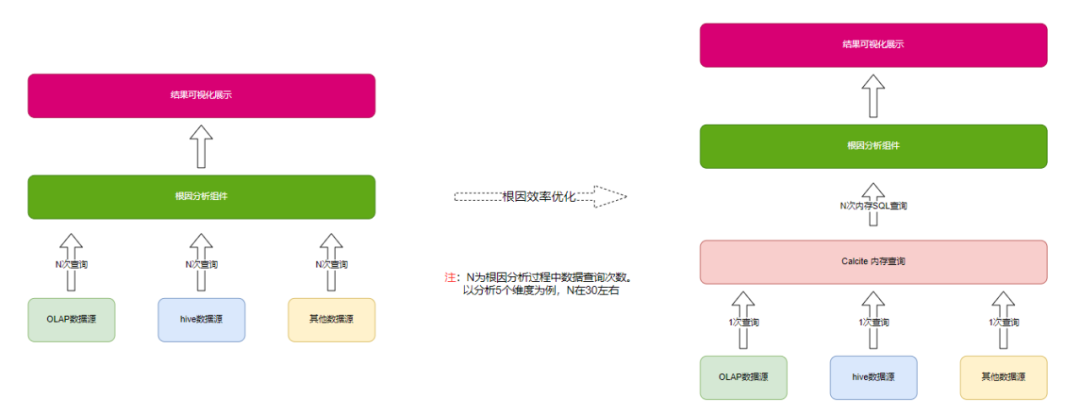
优化后报警类根因分析时长从平均5分钟提升到10s以内,完全满足了业务需要。
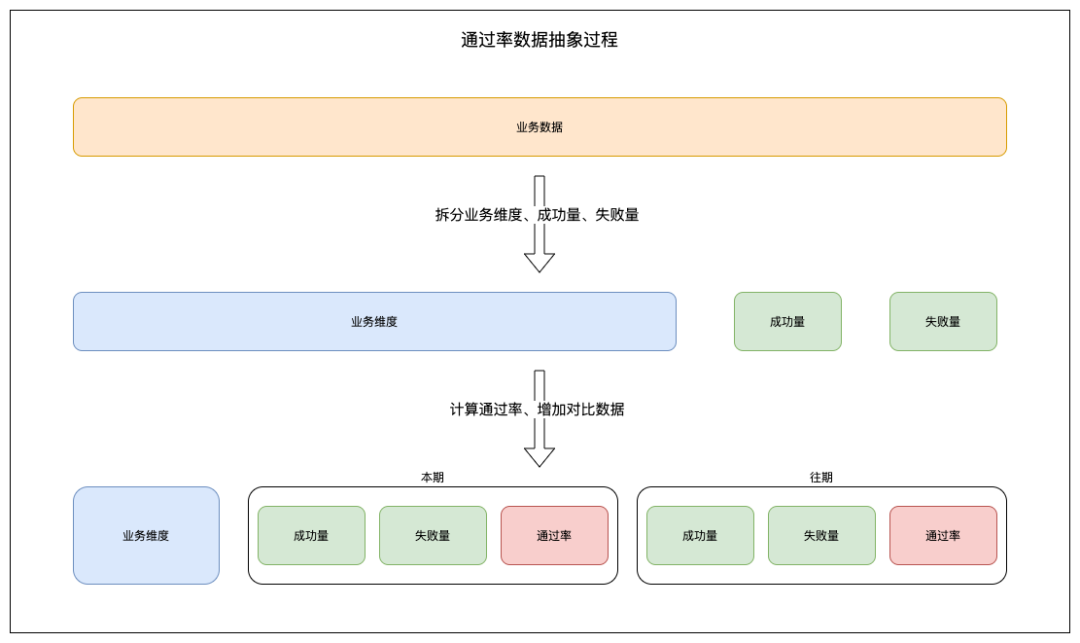
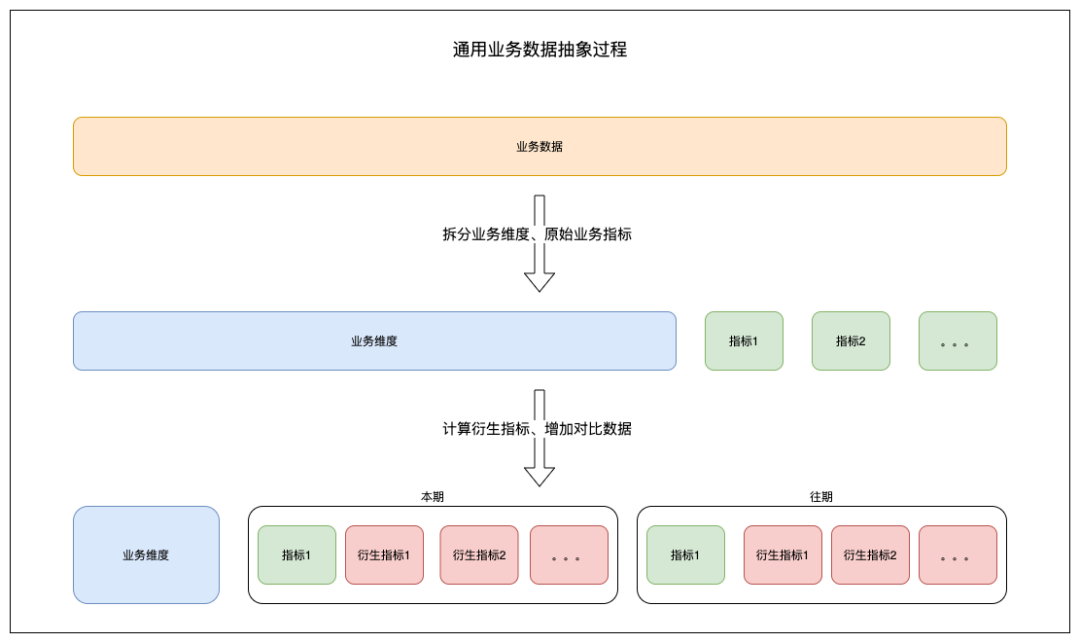
业务维度举例:航司、城市、产品类型、区域 等等
业务指标举例:成功量、失败量、通过率等等
通过率抽象使用场景:机票交易通过率等,成功失败条件明确的业务分析场景
通用业务抽象使用场景:订单多维度占比分析等,自定义多个指标的分析场景
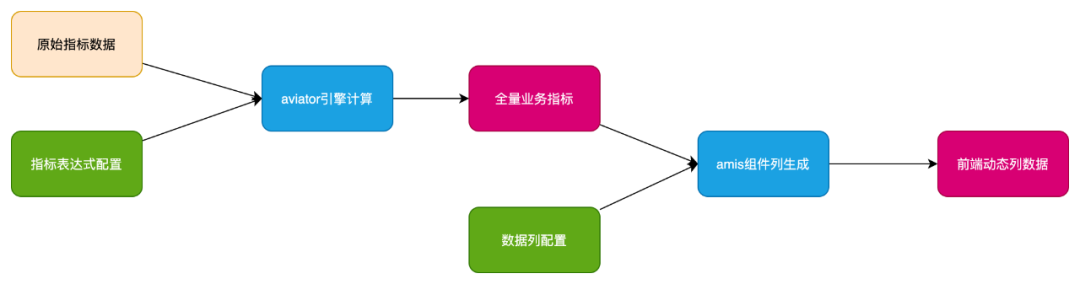
aviator:表达式引擎,结合指标配置计算衍生指标
amis:前端低代码平台,结合业务配置进行前端信息的动态展示
通过以上设计,新接入一个业务场景,只需要2小时左右的配置时间就具备了完全的根因分析能力,包括总览,查询分析,根因分析,自动问题识别及报警等功能。
1)报警后会自动触发报警根因分析,并把分析结果推送给业务方
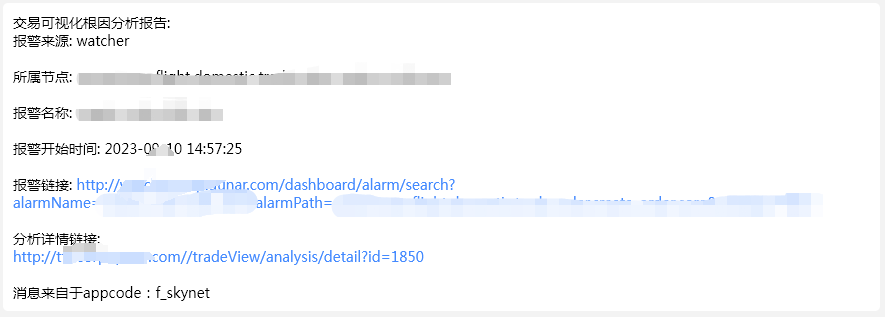
2)分析结果展示页面:
会直接把根因结果展示给业务方,并提供必要的验证功能,包括case查找,人工分析页面,趋势查看等功能。
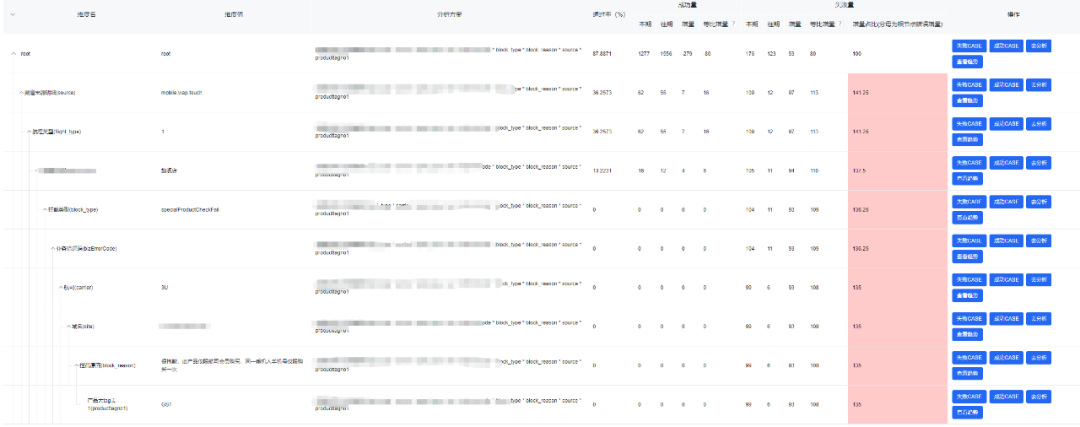
四、实施效果
通过率问题排查全面转向自动化,整合了大部分的分析工具,覆盖了主要的分析场景,包括报警自动分析和问题自动识别。
1、通过率问题排查效率提升80%,报警自动根因分析1分钟内准确率95%以上
2、抽象通用接入场景,机票最核心业务指标分析已陆续接入使用,排查效率均大幅提升
3、平台平均1000+次个性化分析,全年预计人效提升1500pd。
4、通过率等核心指标分析接入后分析更加便捷智能,有力支撑业务指标屡创历史新高。
五、面向未来-能力提炼
依赖数据决策深入人心,但如何提升决策效率,更进一步如何实现自动化决策呢?基于上述方案我们提炼出数据分析进阶三部曲:

以上从左及右依次执行,便能够不断提升分析效率,最终走向分析能力智能化自动化,后续在多个项目里运用该方法论均取得不错效果。
传统分析方式更关注对单个维度数据分析的便利性,倾向于提供一个个孤立的过程指标供业务方使用,该项目更关注的是最终结论的自动化分析体系建设,主要依赖沉淀分析经验把过程指标整合,优化分析算法把分析结果更智能地呈现。
参考资料
https://zhuanlan.zhihu.com/p/490229751
https://zhuanlan.zhihu.com/p/345569713
https://zhuanlan.zhihu.com/p/344900818
https://tech.meituan.com/2019/02/28/root-clause-analysis.html
https://blog.csdn.net/weixin_35834894/article/details/95181483
calcite文档:https://calcite.apache.org/
aviator文档:https://www.yuque.com/boyan-avfmj/aviatorscript








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721