
本文根据刘昊老师在〖deeplus直播:B站保障业务稳定性的SRE落地实践〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)

一、案例剖析
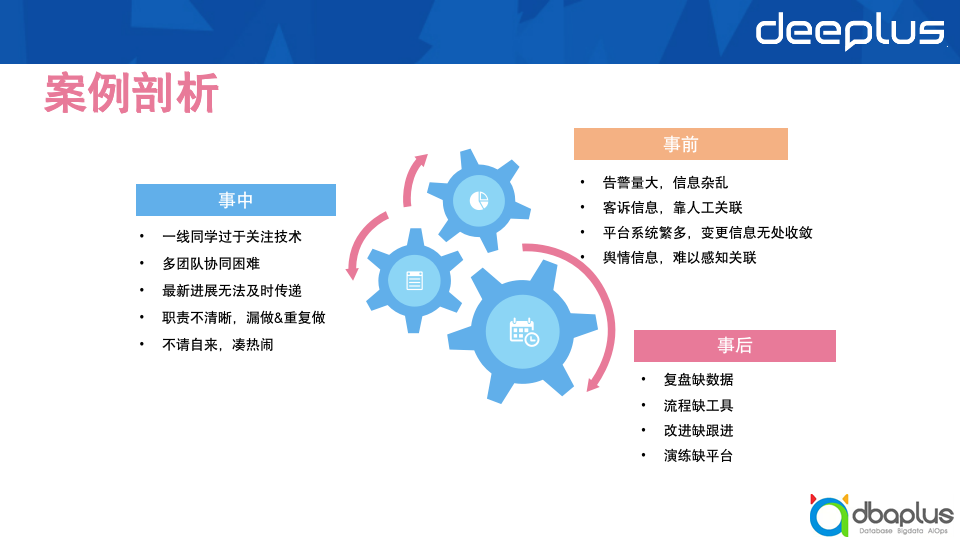
案例一

1)背景
案例二

案例剖析
二、从应急响应看稳定性运营

三、核心运营要素有哪些

做好应急响应工作的核心目标是提升业务的稳定性。在这个过程中,我们核心关注4大要素。核心点是事件,围绕事件有三块抓手,分别是人、流程和工具/平台。
人作为应急响应过程中参与和执行的主体,对其应急的意识和心态有很高要求。特别是在一些重大的故障处理过程中,不能因为压力大或紧张导致错误判断。
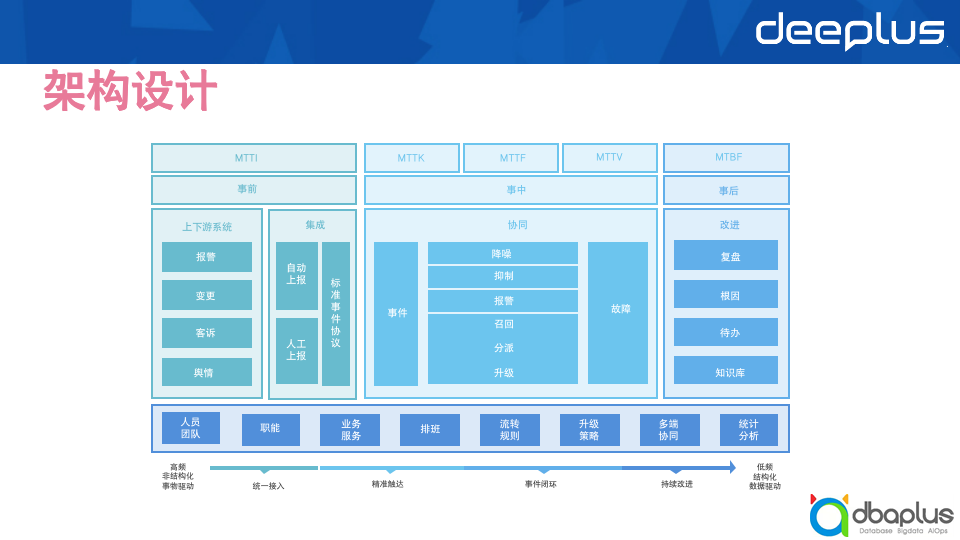
事件
1)生命周期划分
要对故障进行有效运营,就需要先明确故障的生命周期。通过划分故障的生命周期,我们可以针对不同的周期阶段进行精准聚焦,更有目的性地开展稳定性提升工作。
针对故障生命周期的划分有很多种方式,按故障的状态阶段划分,可以分为事前、事中和事后。

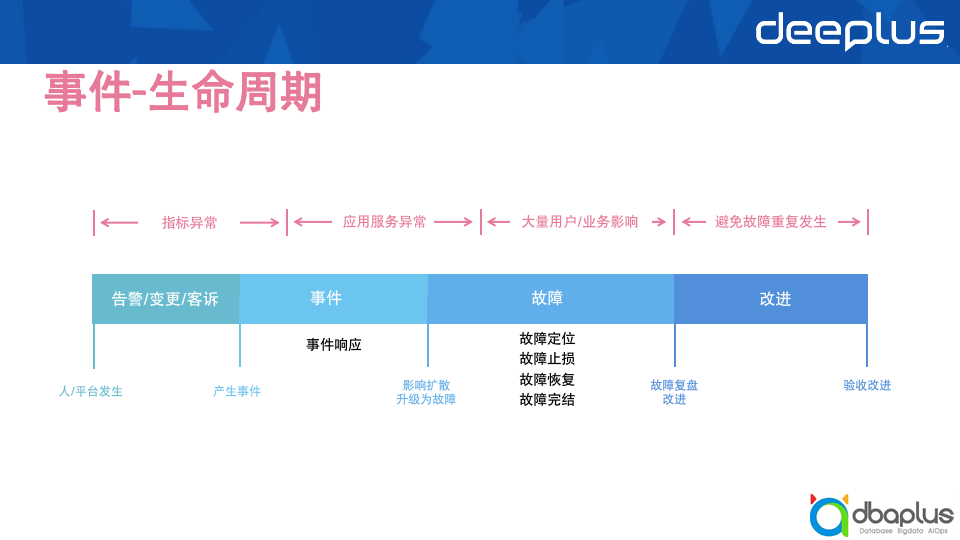

从更科学的角度看,我们知道在运营工作中,度量是很关键的一点。管理学大师彼得·德鲁克曾经说过:“你如果无法度量它,就无法管理它”。有效的度量指标定义,可以帮助我们更好更快地开展运营工作、评估价值成果。上文中我们提到的3个阶段是比较笼统的阶段,接下来我将介绍更加具体和可执行的量化拆分方法。
2)关键节点
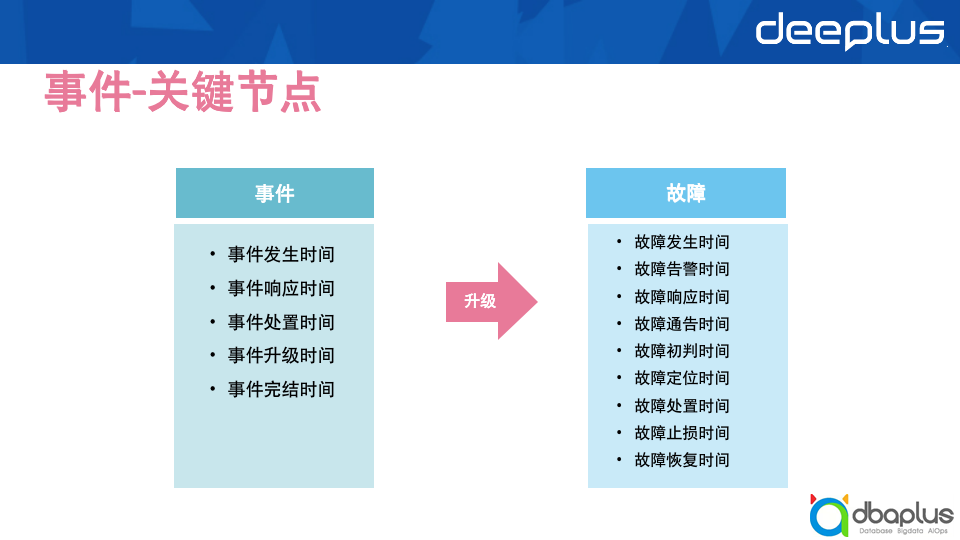
基于阶段度量的指标,我们能够得到一系列的关键时间节点。在不同的阶段形态,事件和故障会存在一些差异。故障因为形态更丰富,所存在的时间节点更多。上图中定下来的时间,均是围绕MTTR进行计算的。主要是为了通过度量事件、故障的处理过程,发现过程中存在的问题点,并对问题点进行精准优化,避免不知道如何切入去提升MTTR的问题,也方便我们对SRE的工作进行侧面考核。
人

人作为事件的一个主体,负责参与事件的响应、升级、处置和消息传播。

流程

平台
四、两个运营载体:OnCall与事件运营中心
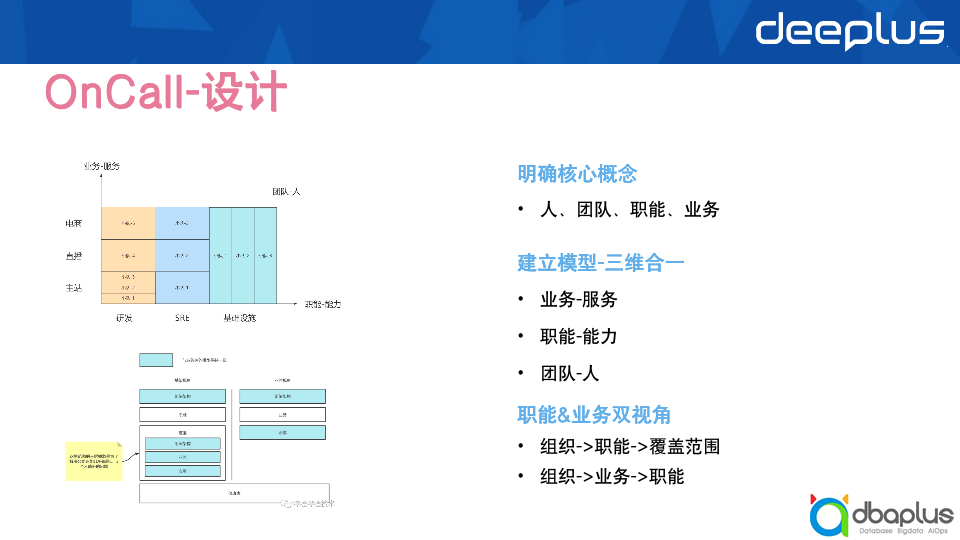
OnCall系统

有问题找不到人

事件运营中心

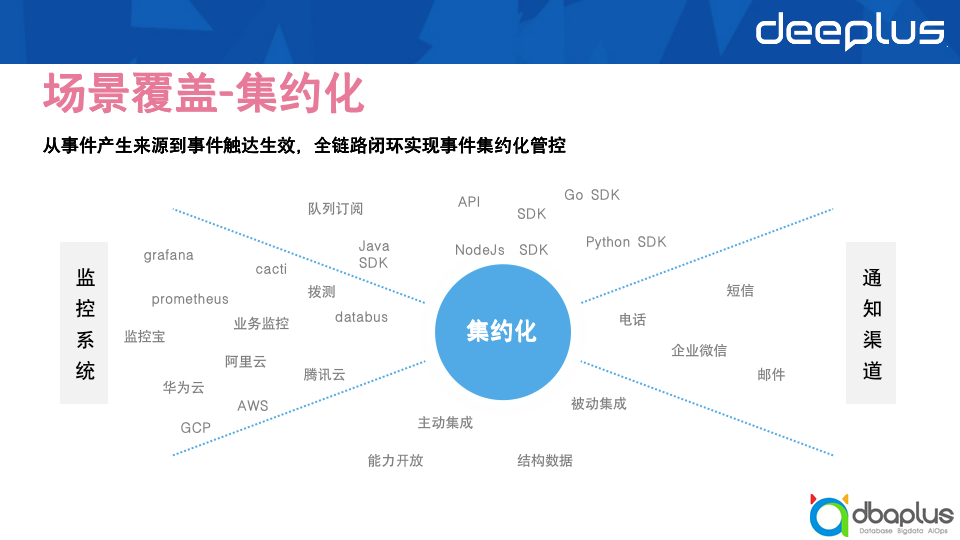

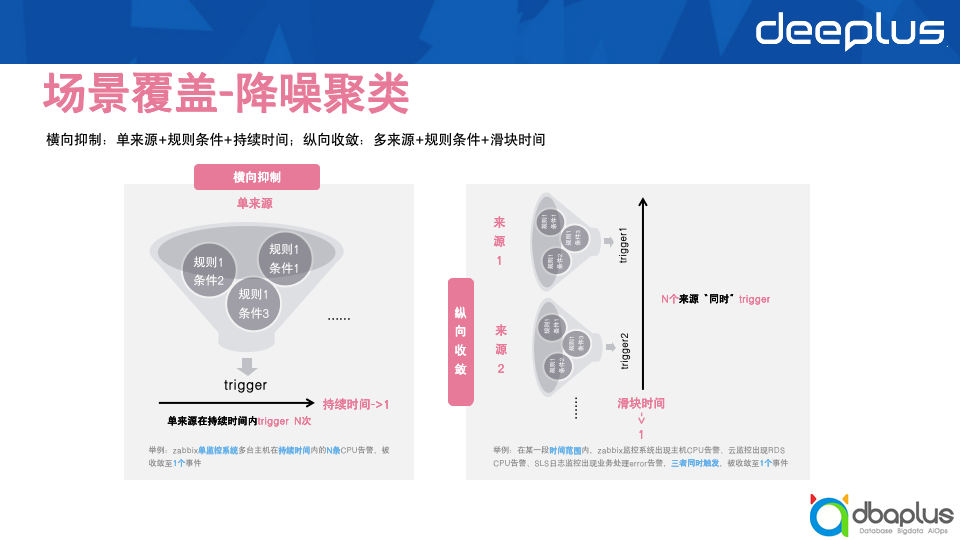

故障响应时,支持了故障的全局应急通告,提供了多种通告渠道,信息实时同步不延误,避免人工同步,漏同步、同步内容缺漏等问题;
故障跟踪阶段,平台可以实时展示最新的故障进展;故障影响面、当下处置情况,各阶段时间等等;
故障结束的复盘阶段,通过定义好的结构化、阶段化的复盘过程,确保复盘过程中,该问的问题不遗漏,该确认的点都确认到;
故障改进阶段,通过对改进项的平台化录入,关联相关责任方、验收方,确保改进的有效执行和落实。

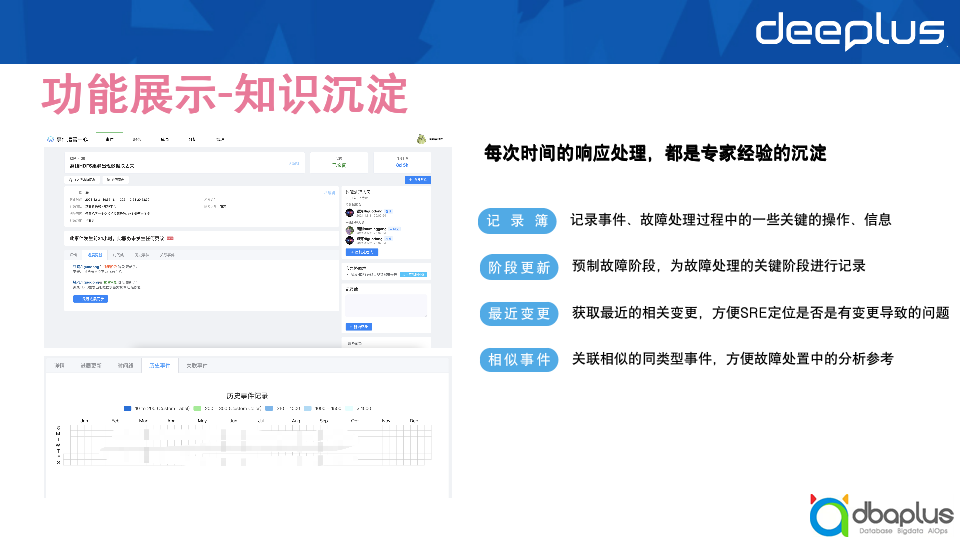

五、挑战与收益
挑战
收益
【腾讯游戏】腾讯游戏SRE工具链建设实践
【网易游戏】网易游戏AIOps探索与实践
【去哪儿网】大规模混沌工程自动演练实践
【浙江移动】“AN”浪潮下数据库智能运维的实践与思考
【平安银行】数据库智能化运维实践之故障自愈
【微众银行】亿级金融系统智能运维的深度实践
【vivo】万级实例规模下的数据库可用性保障实践
【货拉拉】货拉拉智能监控平台的设计与实践
【复旦大学】算法落地探究:如何让智能运维更“智能”
(持续更新……)
点击此处可回看本期直播








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721