
“大规模Kubernetes集群”主要体现在几十个Kubernetes集群,十万级别的Kubernetes Worker节点。蚂蚁金服使用Operator的模式去运维Kubernetes集群,能便捷、自动化的管理Kubernetes集群生命周期,做到“Kubernetes as a Service”。
此文适合Kubernetes爱好者,Kubernetes架构师,以及PE/SRE阅读。
一、前序知识
此章节简单介绍了Kubernetes集群的架构,主要是面向刚学习Kubernetes的同学,对于熟悉Kubernetes的同学,此章节可以跳过。
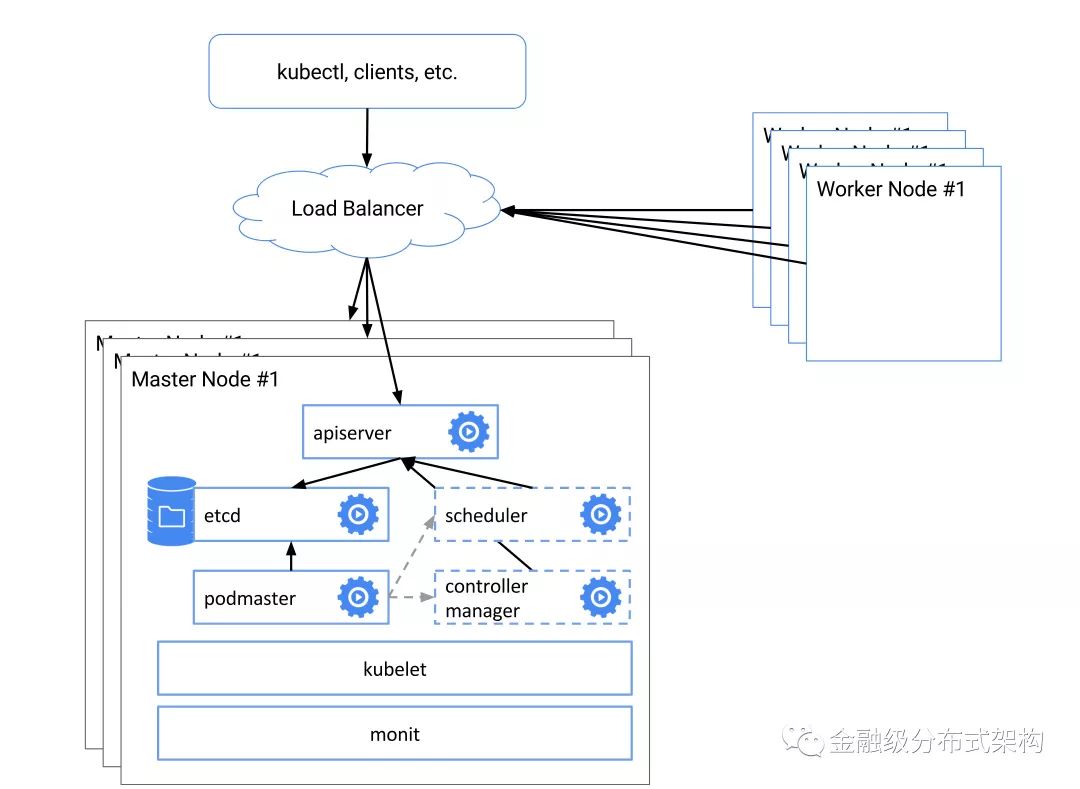
如上图,一个Kubernete集群由Master节点和Worker节点组成。
在一个高可用Kubernetes集群下面,Master节点一般为3台,在它们上面需要运行Kubernetes Master组件。Kubernetes Master组件包括etcd、Apsierver、Scheduler和Controller-Manager。每个Master组件一般都是3个实例,以保证它们的高可用。Master节点使用Static Pod方式启动Master组件,即将每个组件的Pod描述文件放入Master节点的指定目录,Kubelet会在启动时将它们读取,并以Static Pod方式启动。
Kubernetes Worker节点为Kubernetes集群提供调度资源和应用运行环境,即所有的Pod(可以理解为应用的一个个最小化部署单元)都运行在Worker节点上。一个Worker节点将Pod运行上去需要一些on-host软件,包括: kubelet、Runtime Service(docker、pouch等实现方案)、CNI插件等。
我们在这里将用很少的篇幅向刚学习Kubernetes的同学介绍一下Operator。如果期望获得更详细的解读,请参考coreos上关于Operator的介绍。
一个Operator实际上是为了解决某个复杂应用在Kubernetes的自动化部署、恢复。有了Operator,用户只需要向Kubernetes Apiserver提交一个CRD Resource(yaml或者JSON,一个CRD Resource其实就是对应一个应用实例,CRD Resource用于描述这个应用实例的配置),Operator就会根据用户的需求去完成这个应用实例的初始化,在应用某个模块发生故障时,Operator也会做出自动恢复功能。Operator是用代码运维应用最好的实践之一。

比如我们有一个etcd-operator,我们只需要用户根据需求向Kubernetes Apiserer提交如下的CRD Resource,etcd-operator就能初始化完成一个etcd集群:
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdCluster
metadata:
name: xxx-etcd-cluster
spec:
size: 5
其中,上面的Spec.Size=5代表了我们需要一个由5个etcd节点组成的etcd集群。etcd-operator会根据上面的配置,初始化完成etcd集群。相应的,如果你又需要另一个3节点的etcd集群,你只需要提交新的一个Spec.Size=3的CRD Resource即可。
二、背景
在蚂蚁金服,我们面临着需要运维几十个Kubernetes集群,以及十万级别以上的Kubernetes Worker节点的难题。
我们将运维Kubernetes的工作拆分两部分:
运维Kubernetes集群的Master组件(etcd、Apiserver、controller-manager、scheduler等);
运维Kubernetes Worker节点。
我们总结了这两部分运维的难点:
难点1:运维Kubernetes集群Master角色
如何快速新建、下线一个Kubernetes集群(初始化、删除 Master 角色)?由于蚂蚁业务的快速增长,我们随时面临着需要在新机房新建、下线一个 Kubernetes集群;CI和测试也有快速新建、删除一个Kubernetes集群的需求。
如何管理几十个Kubernetes集群Master组件版本。比如我们需要升级某几个Kubernetes集群的Apiserver、Scheduler等组件。
如何自动化处理几十个Kubernetes集群Master组件发生的故障?
如何能获取几十个Kubernetes集群Master组件的统一视图?我们希望有一个统一的接口,一下就能获取每个Kubernetes集群Master角色的版本、状态等信息。
难点2:运维Kubernetes Worker节点
如何快速上线、下线Kubernetes Worker节点?上线时,我们需要保证Kubernetes Worker节点所需要的on-host软件版本、配置正确。
如何升级十万级别的Kubernetes Worker节点上的on-host软件?如我们需要将所有Work节点的docker、cni版本升级到某个版本。
如何优雅的执行灰度发布Kubernetes Worker节点上的软件包?在on-host软件新版本上线前,我们需要对它做小范围的灰度发布,即挑选N台Worker节点发布新版本软件包,执行验证,最后根据验证结果决定是否全规模的发布新版本,或者回滚这个灰度发布。
如何自动化处理十万级别的Kubernetes Worker节点可能出现的on-host软件故障?比如要是docker\kubelet发生panic,我们是否能自动化得处理?
三、实现方案
在实现方案的选择上,我们使用了Kube-on-Kube-Operator和Node-Operator组合的方式来解决上述的难题:
首先,我们需要借助工具,使用Kubernetes官方提供的方案(Static Pod 方式)部署“Kubernetes 元集群”(后面简称元集群)到“元集群”的Master节点上。
然后,我们将Kube-on-Kube-Operator部署到“ Kubernetes元集群”。我们将一个Kubernetes集群所需的一系列Master组件当成一个复杂的应用。当我们需要一个“Kubernetes业务集群”(后面简称业务集群),我们只需要向元集群Apiserver提交用于描述“Kubernetes业务集群”的Cluster CRD Resource (下文会介绍我们如何设计CRD结构),Kube-on-Kube-Operator就为我们准备好了一个可以工作的“Kubernetes 业务集群”(“业务集群”Master组件都已经Ready,需要扩容Worker节点)。
之后我们在“Kubernetes 业务集群”上,部署上Node-Operator。Node-Operator负责Worker节点的生命周期。当我们需要扩容一个Worker节点,我们只需要提交描述Worker节点的元数据(IP、Hostname、机器运维登录方式等)的Machine CRD Resource(下文会介绍我们如何设计CRD结构),Node-Operator就会将Worker节点初始化完成,并成功加入到 “Kubernetes 业务集群”中。
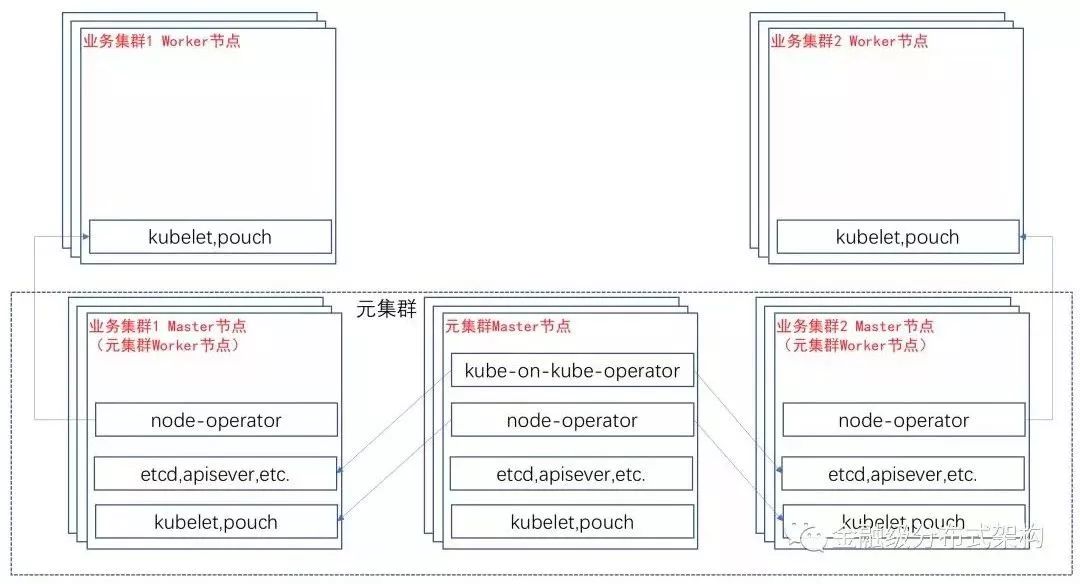
“元集群”只用于管理所有“业务集群”所需的Master组件。“业务集群”是真正提供给业务方运行Pod的Kubernetes集群。也就说,在蚂蚁金服我们只有一个“元集群”, 在这个“元集群”中,我们使用Kube-on-Kube-Operator自动化管理了蚂蚁金服所有的“Kubernetes 业务集群”的Master组件。
当然,“元集群”也会部署Node-Operator,用于“元集群”Worker节点的上下线,“元集群”的Worker节点也是各个“业务集群”的Master节点。
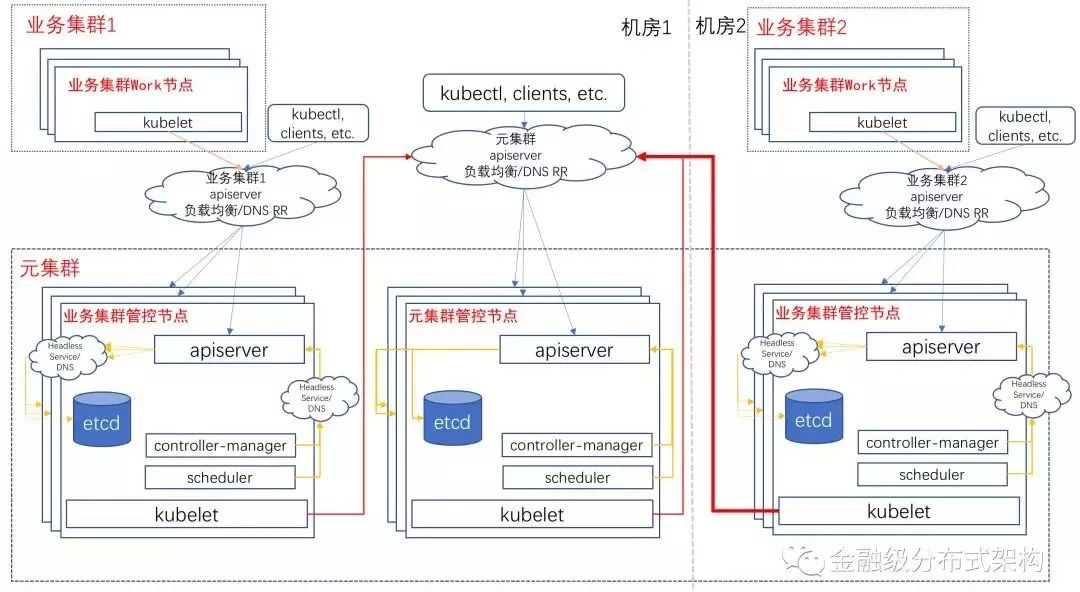
Kube-on-Kube-Operator用于Watch Cluster CRD Resource的变更,将“Cluster”所描述表示的Kubernetes业务集群的所有Master组件达到最终状态。如下图,是“元集群”和它所管理的两个“Kubernetes 业务集群”的最终状态:
Cluster CRD的定义包含如下一些信息:
业务集群名;
业务集群部署模式:分为标准生产和最小化。标准生产提供Master组件都是3个副本的部署,最小化则都是1个副本的部署;
业务集群Master节点NodeSelector,即表示如何在元集群内如何选择业务集群Master节点;
业务集群各Master组件版本、自定义参数等;
业务集群所使用的etcd启动配置,主要涉及etcd data volume的设置,有ClaimTemplate和VolumeSource两种模式:
使用ClaimTemplate模式,即使PVC来初始化etcd volume;
使用VolumeSource模式,即使用VolumeSource所表示的volume来挂载etcd volume;
业务集群Master组件证书过期时间:Master组件所使用kubeconfig中的证书都有过期时间以保证安全性,而Kube-on-Kube-Operator会在证书过期时自动完成滚动证书、Master组件重新加载证书等操作。
业务集群额外用户kubeconfig:即为“额外用户”提供的用户名和组名,签出证书,并生成kubeconfig保存在元集群Secret中供读取。
业务集群状态:这部分信息不需要用户提交,而是由Kube-on-Kube-Operator自动生成,用户反馈这个业务集群的状态,参考Pod.Status 。
一个业务集群的Master组件部署实际是元集群中的一系列Resource组成,即包括Deployment、Secret、Pod、PVC等组合使用。各Master组件所需要的部署Resource如下:
Apiserver:一个Deployment即可,因为Apiserver是无状态应用,副本数和Cluster CRD描述的一致即可。除此之外,需要为Apiserver创建两个Service:
a. 向同个业务集群的其它Master组件提供服务的Service——建议使用元集群内的 Headless Service。
b. 向Kubelet、外部组件提供服务的Service——建议使用机房DNS RR Service (需要自己实现Service Controller)。
etcd:每个etcd实例(标准化部署是3个实例,最小化是1个实例)都建议单独使用Pod + PV + PVC + Headless Service部署。每个etcd实例的peer id为对应的Headless Service域名。当某个etcd实例发生故障时,需要手动删除掉故障对应实例的Pod,Kube-on-Kube-Operator watch到etcd Pod的减少,会重新建立Pod,并执行Remove old member(被删除的 Pod),Add new member(新建的Pod)操作,但是peer id还是保持一致的。
Controller-Manager:一个Deployment即可,因为Controller-Manager是无状态应用。副本数和Cluster CRD描述的一致即可。
Scheduler:一个Deployment即可,因为Scheduler是无状态应用。副本数和Cluster CRD描述的一致即可。
Kube-on-Kube-Operator除了能够部署上述的Master组件之外,还能维护任何扩展组件,如kube-proxy、kube-dns等。只需要用户提供扩展组件部署模板和扩展插件版本,Kube-on-Kube-Operator能渲染出部署Resource,并保持这些部署Resource到最终态。由于篇幅原因,我们这里不再赘述。
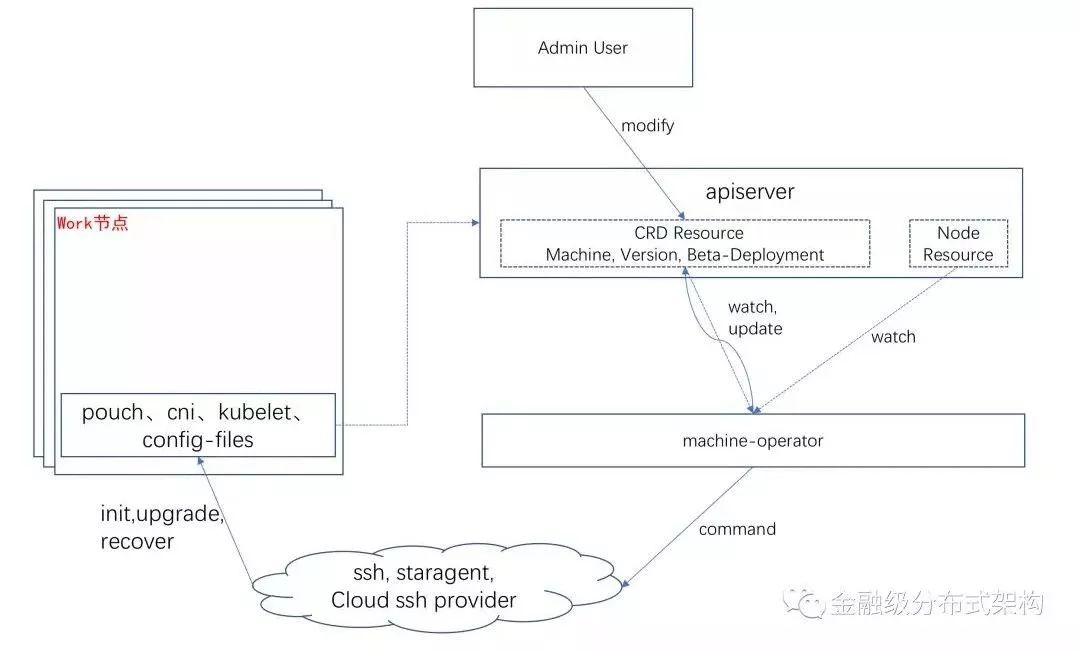
Node-Operator用于Watch Machine CRD Resource的变更,将“Machine”所描述表示的Worker节点上的on-host软件(docker、kubelet、cni)达到最终态,最终能让“Machine”所对应的“Node”在Kubernetes集群中达到“Ready”状态。架构图如下:
Machine CRD的定义包含如下一些信息:
机器元数据:IP、Hostname、IDC 等;
机器运维SSH登录方式和登录秘钥:如最常见的 SSH Key;如果 Machine 是阿里云的ECS,那么登录方式和登录秘钥是阿里云提供的SSH接口和对应的鉴权信息等;
各个on-host软件版本和自定义参数;
Machine状态:这部分信息不需要用户提交,而是由Node-Operator生成,表示这个机器的当前状态,参考Pod.Status 。
Node-Operator用Watch Machine对应Node的状态,当发生一些能处理的Condition(比如kubelet运行中进程消失了)时,Node-Operator会做出恢复处理;Node-Operator会Watch ClusterPackageVersion CRD的变更,这个CRD表示整个Kubernetes集群kubelet、docker等组件的默认版本,Node-Operator会根据ClusterPackageVersion描述的信息,控制各个节点的kubelet、docker等组件的版本;Node-Operator还支持控制某些组件灰度发布到某些节点中,用户只要提交描述这个灰度发布的CRD到Apiserver,Node-Operator会有序的执行灰度发布,并将发布状态反馈到CRD中。由于篇幅原因,我们不再赘述。
四、写在最后
在运维大规模Kubernetes集群的实践中,我们摈弃了传统的模式,使用了Operator模式和面向Apiserver编程。Kubernetes集群的上下线、升级实现了“Kubernetes as a Service”,就像向云厂商买一个服务一样简单。而Worker节点的运维,使用Operator模式能够让我们统一管理元数据,自动化初始化、恢复Worker节点所需组件。
作者:陈俊
来源:金融级分布式架构订阅号(ID:Antfin_SOFA)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721