
作者介绍
汪涉洋,来自美国视频网站hulu的工程师,毕业于北京理工大学计算机专业,目前从事大数据基础架构方面的工作。个人知乎专栏“大数据SRE的总结”:http://dwz.cn/7ygSgc
过去两年,我的主要工作都在Hadoop这个技术栈中,而最近有幸接触到了Ceph。我觉得这是一件很幸运的事,让我有机会体验另一种大型分布式存储解决方案,可以对比出HDFS与Ceph这两种几乎完全不同的存储系统分别有哪些优缺点、适合哪些场景。
对于分布式存储,尤其是开源的分布式存储,站在一个SRE的角度,我认为主要为商业公司解决了如下几个问题:
可扩展,满足业务增长导致的海量数据存储需求;
比商用存储便宜,大幅降低成本;
稳定,可以驾驭,好运维。
总之目标就是:又好用,又便宜,还稳定。但现实似乎并没有这么美好……
本文将从这三个我认为的根本价值出发,分析我运维Ceph的体会,同时对比中心化的分布式存储系统,比如HDFS,横向说一说。
Ceph声称可以无限扩展,因为它基于CRUSH算法,没有中心节点。 而事实上,Ceph确实可以无限扩展,但Ceph的无限扩展的过程,并不完全美好。
首先梳理一下Ceph的写入流程。Ceph的新对象写入对象,需要经过PG这一层预先定义好的定额Hash分片,然后PG,再经过一次集群所有物理机器硬盘OSD构成的Hash,落到物理磁盘。
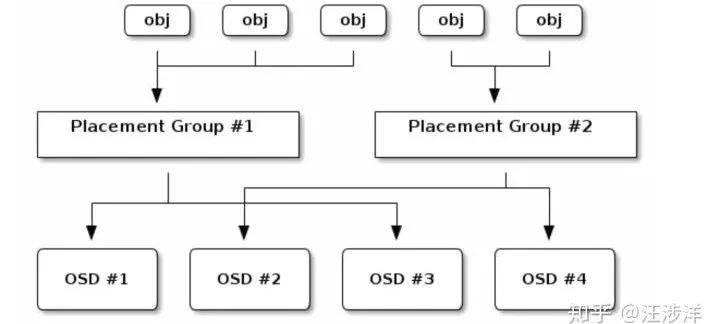
因此,Ceph的所有对象,是先被pre-hash到了一个固定数量的桶(PG)当中,然后根据集群的整体物理架构crushmap,选择落在具体的机器磁盘上。
这对扩容有什么影响呢?
我给扩容粒度的定义是:一次可以扩容多少台机器。
Ceph在实践中,扩容受“容错域”制约,一次只能扩一个“容错域”。
容错域就是:副本隔离级别,即同一个replica的数据,放在不同的磁盘/机器/Rack/机房。
容错域这个概念,在很多存储方案里都有,包括HDFS。为什么Ceph会受影响呢?因为Ceph没有中心化的元数据结点,导致数据放置策略受之影响。
数据放置策略,即一份数据replica,放在哪台机器,哪块硬盘。
中心化的,比如HDFS,会记录每一个文件,下面每一个数据块的存放位置。这个位置是不会经常变动的,只有在1.文件新创建;2.balancer重平衡;3.有硬盘坏了,中心节点针对损坏硬件上的数据重新放置时才会改变。
而Ceph,因为去中心化,导致容纳数据的PG的位置,会根据crushmap的变化而变化。 来了新的机器、硬盘,就要为一些受影响的PG计算新的位置。 基于一致性哈希的技术,在扩容时也要面临同样的问题。
因此,Ceph扩容需要PG们调整。正因为这个调整,导致Ceph受“容错域”制约。
例如:有一个PG,是3副本,Ceph集群有一个配置是PG要向外提供正常服务,至少有2个完整的副本。而当这个数据pool的容错域是host时,同时扩容2台机器,一些PG就有可能把3副本中的2个都映射到2台新机器上去。而这2个副本都是新副本,都没有完整的最新数据。剩下的一个副本,无法满足老机器至少有完整的2副本的要求,也就不能提供正常读写服务了。
这就会导致这个PG里的所有对象,停止对外服务。
作为admin,当然可以把配置降低,把数据pool的min_size下降为1。但这种配置,即使在正常情况下,因为磁盘故障,都有可能丢失数据,因此一般不会这样设置。
那在扩容时,一次只扩容一台机器时,是不是就安全了呢?
这样就能保证所有PG都至少在老机器有2个完整的副本了。可是,即使是扩容一台机器,也还要面临扩容时老机器中有硬盘坏掉,导致PG的完整副本又下降为1的极端情况发生。
虽然PG有可能不能服务,但数据的持久性是没有问题的。国内AT的云,服务可靠性都没有做得特别高,做到像持久性那样3个9、4个9。虽然我不确定这两朵大云里的对象存储是不是使用的Ceph,但只要是基于类似CRUSH算法,或者一致性哈希等类似的去中心化技术实现的对象存储,应该都会面对部分数据暂时不可服务的情况。
我们抛开最极端的情况,即假设在扩容时,以一个“容错域”加入机器时,暂时没有磁盘损坏。那么有没有办法可以提升扩容粒度呢?
办法是,在开始规划Ceph集群时,设定好更大层次的“容错域”,比如Rack。 可以是真实的Rack,即使没有也可以是逻辑的Rack。这样扩容时,可以扩一个逻辑“容错域”,就可以打破扩一台机器的限制,扩一整个Rack,至少有好几台机器。
Tips:这里我没有讲为什么扩容粒度小是个不好的事。其实在很多公司,数据的日均增长量是很有可能大于一台机器的存储容量的。这就会造成扩容速度赶不上写入速度的尴尬局面。这对于开始没有设计好,图快速deploy而架设的集群,在后期是一个不小的伤害。
Ceph是根据crushmap去放置PG的物理位置的,倘若在扩容进行了一半时,又有硬盘坏掉了,那Ceph的crushmap就会改变,Ceph又会重新进行PG的re-hash,很多PG的位置又会重新计算。如果运气比较差,很可能一台机器的扩容进度被迫进行了很久才回到稳定的状态。
这个crushmap改变导致的Ceph重平衡,不单单在扩容时,几乎在任何时候,对一个大的存储集群都有些头疼。在建立一个新集群时,硬盘都比较新,因此故障率并不高。但是在运行了2-3年的大存储集群,坏盘真的是一个稀松平常的事情,1000台规模的集群一天坏个2-3块盘很正常。crushmap经常变动,对Ceph内部不稳定,影响真的很大。随之而来,可能是整体IO的下降(磁盘IO被反复的rebalance占满),甚至是某些数据暂时不可用。
所以总的来说,Ceph的扩容是有那么一丁点不痛快的。Ceph确实提供了无限的扩展能力,但扩容过程并不平滑,也不完全可控。crushmap的设计,达到了很好的去中心化效果,但也给集群大了之后的不稳定埋下了一个坑。
而对比中心化元数据的HDFS,在扩容时几乎无限制,你可以撒欢地扩容。老数据的搬迁,重平衡都会由单独的job来处理,处理也很高效。它采用了满节点和空节点两两配对的方式,从老节点移动足够的数据,填满新机器即可。中心化元数据在扩容&重平衡时,反而变成了一个优点。
如上文的Ceph数据写入流程图所示,Ceph对象的最小放置单位是PG,PG又会被放在硬盘上,PG理论上肯定是越大越好。因为这样数据的分片随机性更好,更能掩盖伪随机造成的单块盘容量偏差过大问题。但PG数量在现实中不是越大越好的,它要受限于硬件,如CPU、内存、网络。 因此我们在规划PG数时,不会盲目调大,一般社区也是建议200pg / osd。
假设我们现在有10台机器,每台一块硬盘一共10块盘,有1024个PG,PG都是单副本,那么每个盘会存100个PG。此时这个设置非常健康,但当我们集群扩容到1000台机器,每台硬盘就只放一个PG了,这会导致伪随机造成的不平衡现象放大。因此,admin就要面临调整PG数量,这就带来了问题。
调PG,基本也就意味着整个集群会进入一种严重不正常的状态。几乎50%的对象,涉及到调整后的PG都需要重新放置物理位置,这会引起服务质量的严重下降。
虽然调整PG不是一个经常性的事件,但在一个大型存储,随着发展,不可避免会经历这个大考。
问题在于,集群可靠利用率。
集群可靠利用率,即整个集群在容量达到某个水平时不可对外服务,或者说不能保持高可用的服务。
打个比方,我们的手机闪存/电脑硬盘,是不是到99%了还能正常工作? 当然,因为是本地存储嘛。对于云解决方案,也天然就没有这个问题了。
对于商用存储解决方案,比如EMC的Isilon分布式文件系统,存储容量达到甚至98-99%,仍能对外提供服务。
对于HDFS,在95%以下,存储也能很好地对外提供服务。跑在HDFS上的Hadoop Job,会因为没办法写入本地而挂掉。
而对于Ceph,在这一块表现得并不好。根据经验,在集群整体使用率达到70%后,就有可能进入不稳定的状态。
这是为什么呢?问题在于,去中心化带来的tradeoff。
Ceph是去中心化的分布式解决方案,对象的元数据是分布在各台物理机上的。因此所有对象,是被“伪随机”地分配到各个磁盘上的。伪随机不能保证所有磁盘的完全均匀分配,不能降低很多大对象同时落在一块盘上的概率(我理解加入一层PG,又使PG多replica,是可以让磁盘的方差变小的),因此总有一些磁盘的使用率会高出均值。
在集群整体使用率不高时,都没有问题。而在使用率达到70%后,就需要管理员介入了。因为方差大的盘,很有可能会触及95%这条红线。admin开始调低容量过高磁盘的reweight,但如果在这一批磁盘被调整reweight没有结束时,又有一些磁盘被写满了,那管理员就必须被迫在Ceph没有达到稳定状态前,又一次reweight过高的磁盘。 这就导致了crushmap的再一次变更,从而导致Ceph离稳定状态越来越远。而此时扩容又不及时的话,更是雪上加霜。
而且之前的crushmap的中间状态,也会导致一些PG迁移了一半,这些“不完整的”PG并不会被马上删除,这给本来就紧张的磁盘空间又加重了负担。
有同学可能会好奇,一块磁盘满了,Ceph为什么就不可用了。Ceph还真的就是这样设计的,因为Ceph没法保证新的对象是否落在空盘而不落在满盘,所以Ceph选择在有盘满了时,就拒绝服务。
在我咨询了一些同事和业界同行后,基本上大家的Ceph集群都是在达到50%使用率时,就要开始准备扩容了。这其实是挺不省钱的,因为必须空置一大批机器的存储资源。并且未来集群的规模越大,空置效应就会放得越大,意味着浪费的钱/电费越多。
而很多传统的中心化的分布式存储系统,由于写入时可以由主控节点选择相对空闲的机器进行写入,因此不会存在某些磁盘满了,导致整个集群不可写入的问题。也正是如此,才可以做到整体写入到95%了,仍然保持可用性。
我没有真正核算过这种效应带来的成本waste,但至少看上去是有点不够完美的。
打个比方,当我预估有50pb的存储时,需要300台物理机了,我居然要提前采购好另外200-300台物理机,还不能马上用上,还要插上电。
因此Ceph也并不一定会很便宜,去中心化的分布式存储也并没有那么美好。
但中心化的危害,似乎又是没有争议的问题(单点问题、中心节点扩展性问题等等 ),因此分布式里真的没有银弹,只有tradeoff。
还有一种办法,就是Ceph的集群按整个pool来扩容,一个pool满了,就不扩容了,开新的pool,新的对象只准写新的pool,老的pool的对象可以删除,可以读取。 这乍看之下是一个很棒的解决方案,但仔细想想,这和HDFS的federation,和MySQL的分库分表,做前端的大Hash,似乎没有区别。
这也就谈不上是“无限扩容”了,而且还需要写一个前面的路由层。
这个稳定好运维,基本就看团队的硬实力了。对开源软件是否熟悉,是否有经验,真的会有很大不同。
同时,这还受开源社区文档质量的影响。Ceph的开源社区还是不错的,Red Hat收购并主导了Ceph之后,重新整理了Red Hat版本的Ceph文档,我认为读起来逻辑感更强。
在公司内积累自己的运维文档也很关键。一个新手很可能会犯很多错误,导致事故发生。但对于公司,踩了一次的坑,就尽量不要再踩第二次了。这对公司的技术积累管理、技术文档管理、核心人才流失管理,都产生了一些挑战。
我在Ceph运维中,曾遇到一个棘手的问题。即Ceph集群达到了80%后,经常有磁盘变满,然后管理员就要介入,调低过高磁盘的reweight。而在这台磁盘使用量没降下来之前,又有更多的磁盘被写满了,管理员就又要介入,又调整reweight,Ceph至此就再也没有进入过稳定状态了,管理员还必须时时刻刻盯着集群。这导致了极大的运维投入,所以像这种事情一定要避免,这对运维人员的士气是很大的伤害。
那么,是否应该在早期进行容量预警,启动采购流程呢?
可是这样做,又回到了资源浪费的问题上。
此外,Ceph的对象是没有last_access_time这种元数据的,因此Ceph对象的冷/热之分,需要二次开发,做额外的工作。集群大了之后,如何清理垃圾数据、如何归档冷数据,也带来了不小的挑战。
1、Ceph确实有无限扩容的能力,但需要良好的初始规划,扩容过程也并不完美。中心化造就了扩容的上限是单台master结点的物理极限,造就了无限扩容的理论基础,但实际扩容时,服务质量会受严重制约。
2、Ceph有些浪费硬件,成本核算时要考虑更多。
3、Ceph本身的去中心化设计牺牲了不少元数据,比如lastacesstime,这给未来数据治理带来了压力,也需要更强的团队来运维和二次开发。积累运维经验,积累运维团队,是驾驭好开源分布式存储的核心。对手随着时间越来越强大,应对的运维团队也需要越来越好,才能让生产关系匹配生产力的要求。
4、技术本身没有绝对的好坏,不同的技术是用来解决不同问题的。但在场景下,技术是有好坏的。因为在场景下,你有了立场,就有了亟待解决的问题的优先级,也就一定能按优先级选择出最适合你的技术。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721