
作者介绍
贺春旸,普惠金融MySQL专家,《MySQL管理之道》第一版、第二版作者。曾任职于中国移动飞信、机锋安卓市场,拥有丰富的数据库管理经验。目前致力于MySQL、Linux等开源技术的研究。
相信大家在对接BI数据报表部门有很深刻的体验,高大上的复杂SQL关联JOIN十几张表在InnoDB里跑起来,会让你酸爽到死。它的出现正是解决这个问题,DBA能不能轻松愉快地玩耍,就要靠它了,“神州行我看行”。
通过本文,会让大家都可以动手玩起来。我们的口号:接地气!
MariaDB ColumnStore是在MariaDB 10.1基础上移植了InfiniDB 4.6.2构建的大规模并行,高性能,压缩,分布式开源列式存储引擎,类似收费产品Infobright。它设计用于大数据离线分析,用来抗衡Hadoop 。官方自称MariaDB ColumnStore是数据仓库的未来,ColumnStore允许存储更多的数据并更快地分析它。
你可以使用标准SQL语句进行查询,支持目前流行的sqlyog/navicat客户端工具连接,对业务方使用没有任何的不便,并且你不需要创建任何索引,不需要修改业务方的复杂SQL(自身就支持复杂的关联查询、聚合、存储过程和用户定义的函数),你唯一要做的就是把数据导入到ColumnStore里,就没你事了。这对一家没有Hadoop工程师的公司来说,MariaDB ColumnStore会是一个更好的替代产品。
MariaDB ColumnStore是一种专为分布式大规模并行处理(MPP)设计的列式存储引擎。它由三个组件组成,协同工作。
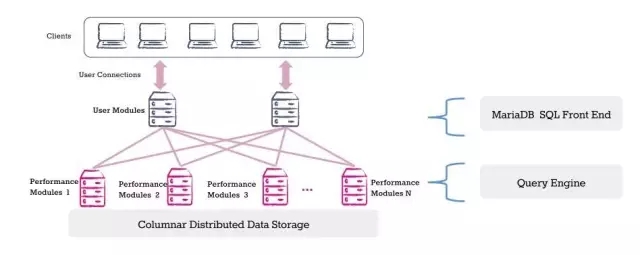
在官方给出的架构图中,我们可以看到分为三个组件构成:UM、PM、数据存储层。
用户模块(UM):
用户模块管理和控制终端用户查询的操作,它维护每个查询的状态,向一个或多个性能模块发出请求以代为执行SQL查询工作,最后,用户模块汇集来自各个参与的性能模块的所有查询结果,以形成返回给用户的完整的查询结果集。
性能模块(PM):
性能模块负责存储,检索和管理数据,处理对查询操作的块请求,并将其传递回用户模块以完成查询请求。性能模块将获取的数据缓存在其内存中计算。MPP是通过允许用户配置尽可能多的性能模块,以实现更高的处理能力。
存储:
MariaDB ColumnStore对于存储系统极为灵活。当在内部运行时,它可以使用本地存储或共享存储(例如SAN)来存储数据。在Amazon EC2环境中,它可以使用临时或弹性块存储(EBS)卷。当无共享部署需要数据冗余时,它被构建为与GlusterFS和Apache Hadoop分布式文件系统(HDFS)集成。
一句话总结:用户模块(UM)将客户端发出的SQL请求进行分配,分配到后端性能模块(PM),PM进行数据查询分析,将处理的结果返回给UM,UM再把PM分析的结果进行聚合,最后返回给客户端最终的查询结果。
我们这里采用2台um、2台pm跑一组集群,操作系统Centos6.8,MariaDB ColumnStore最新GA版本1.0.6。
# cat /etc/hosts
|
192.168.17.133 um1 192.168.17.134 um2 192.168.17.135 pm1 192.168.17.136 pm2 |
1、公私钥认证,打通SSH无密码(um1/2、pm1/2均执行如下)
|
# ssh-keygen # ssh-copy-id '-p 22 root@192.168.17.133' # ssh-copy-id '-p 22 root@192.168.17.134' # ssh-copy-id '-p 22 root@192.168.17.135' # ssh-copy-id '-p 22 root@192.168.17.136' (注:如果你的ssh端口不是22,修改-p 22为你自己的定义的端口) |
2、关闭IPTABLES防火墙/关闭SELINUX
|
# /etc/init.d/iptables stop # cat /etc/selinux/config SELINUX=disabled SELINUXTYPE=targeted # chkconfig iptables off # chkconfig --list | grep iptables iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off |
3、关闭文件系统访问时间和更改磁盘IO算法
|
# cat /etc/fstab UUID=683a6e67-567c-498a-a06a-c65f8f290080 /data xfs defaults,noatime,nobarrier 1 2 #cat /etc/rc.local echo "deadline" > /sys/block/sdb/queue/scheduler |
4、优化Linux系统内核
|
# cat /etc/sysctl.conf # 将如下参数加到最后 # increase TCP max buffer size net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 # increase Linux autotuning TCP buffer limits # min, default, and max number of bytes to use net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 # don't cache ssthresh from previous connection net.ipv4.tcp_no_metrics_save = 1 # recommended to increase this for 1000 BT or higher net.core.netdev_max_backlog = 2500 # for 10 GigE, use this net.core.netdev_max_backlog = 30000 fs.file-max=65535 net.ipv4.ip_local_port_range = 1025 65000 net.ipv4.tcp_tw_reuse = 1 vm.swappiness = 1 |
5、调整文件描述符ulimit为65535
|
# cat /etc/security/limits.conf * soft nofile 65535 * hard nofile 65535 * soft nproc 65535 * hard nproc 65535 # cat /etc/security/limits.d/90-nproc.conf * soft nproc 65535 * hard nproc 65535 |
6、关闭NUMA
|
# cat /etc/grub.conf title CentOS 6 (2.6.32-642.el6.x86_64) root (hd0,0) kernel /vmlinuz-2.6.32-642.el6.x86_64 ro root=UUID=98f9a4a6-f596-42e6-bffa-98a42b32145d rd_NO_LUKS KEYBOARDTYPE=pc KEYTABLE=us rd_NO_MD crashkernel=auto.UTF-8 rd_NO_LVM rd_NO_DM rhgb quiet numa=off initrd /initramfs-2.6.32-642.el6.x86_64.img |
7、安装jemalloc内存管理器
|
# yum -y install jemalloc* |
8、重启服务器
|
# reboot |
1、安装boost软件包
|
# yum -y install boost* # yum -y groupinstall "Development Tools" # yum -y install cmake # cd /root/ # wget http://sourceforge.net/projects/boost/files/boost/1.55.0/boost_1_55_0.tar.gz # tar zxvf boost_1_55_0.tar.gz # cd boost_1_55_0 # ./bootstrap.sh --with-libraries=atomic,date_time,exception,filesystem,iostreams,locale,program_options,regex,signals,system,test,thread,timer,log --prefix=/usr # ./b2 install |
2、安装Perl依赖包
|
# yum -y install expect perl perl-DBI openssl zlib perl-DBD-MySQL |
3、安装配置MariaDB ColumnStore
我们这里选用的是二进制安装包
|
# cd /root/ # wget https://downloads.mariadb.com/enterprise/dapw-ktc5/mariadb-columnstore/1.0.6/centos/x86_64/6/mariadb-columnstore-1.0.6-1-centos6.x86_64.bin.tar.gz # tar zxvf mariadb-columnstore-1.0.6-1-centos6.x86_64.bin.tar.gz -C /usr/local/ |
执行下面的命令进行配置
|
/usr/local/mariadb/columnstore/bin/postConfigure |
后面的步骤,请大家仔细参考我的安装截图。

我们选择multi集群的方式,填写2回车。
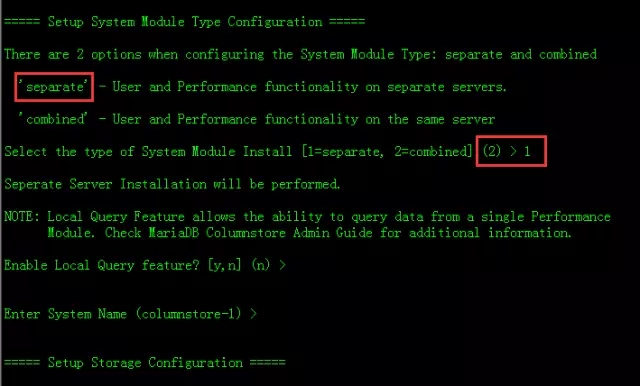
我们选择separate,在单独的机器上部署um和pm,这里输入1回车。
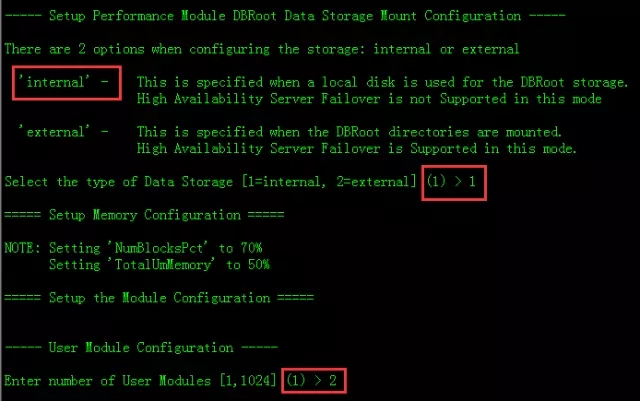
由于我没有共享存储环境,这里我选择本地存储数据,输入1回车。
um节点数,我们这里是2台,输入2回车。
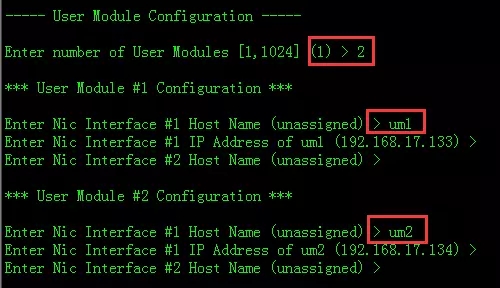
输入主机名um1回车,再输入um2回车。
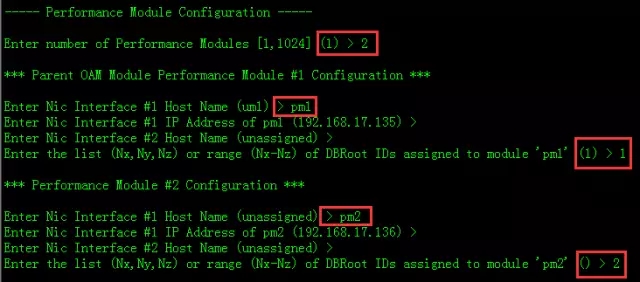
pm节点数,我们这里是2台,输入2回车。
输入主机名pm1回车,再输入pm2回车。
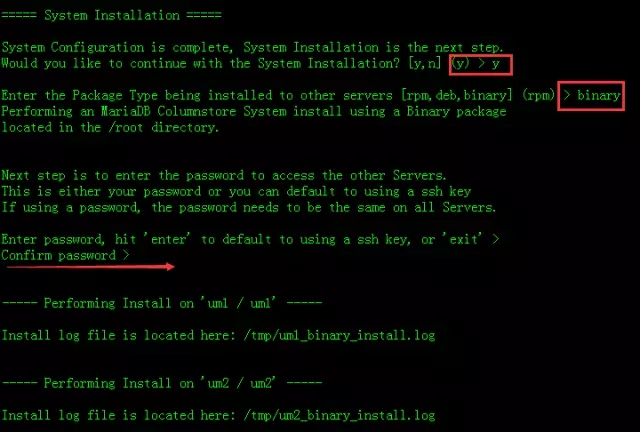
输入y回车安装,然后输入binary,因我们安装是采用的二进制安装包,之后让我们输入其他机器的密码,注意所有机器的root密码要一致,默认是使用ssh-key认证。
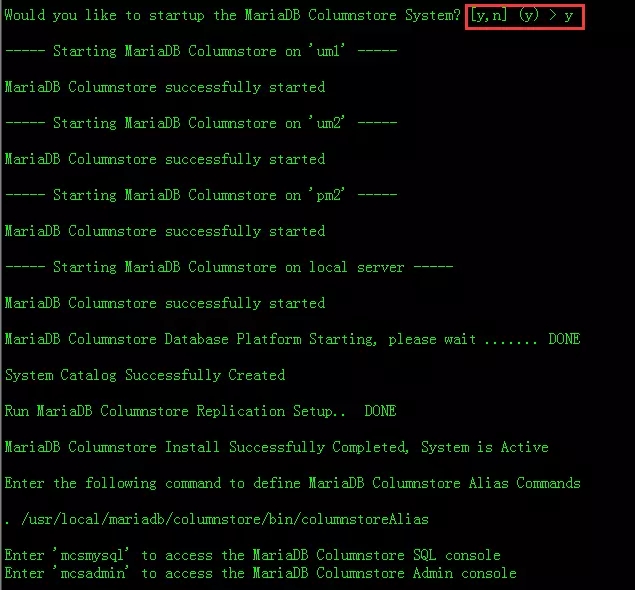
经过漫长的等待,我们输入y开始启动系统,至此启动完毕。
输入命令mcsadmin进入管理后台,输入getSystemStatus可以看到节点信息。
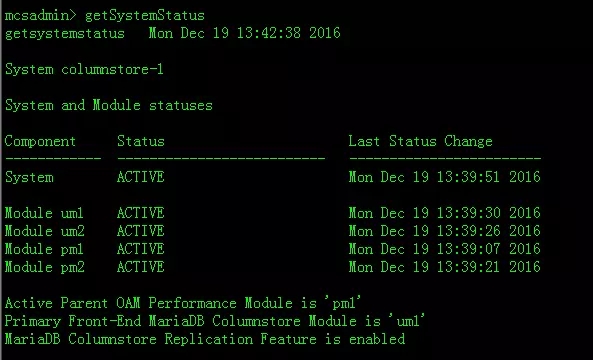
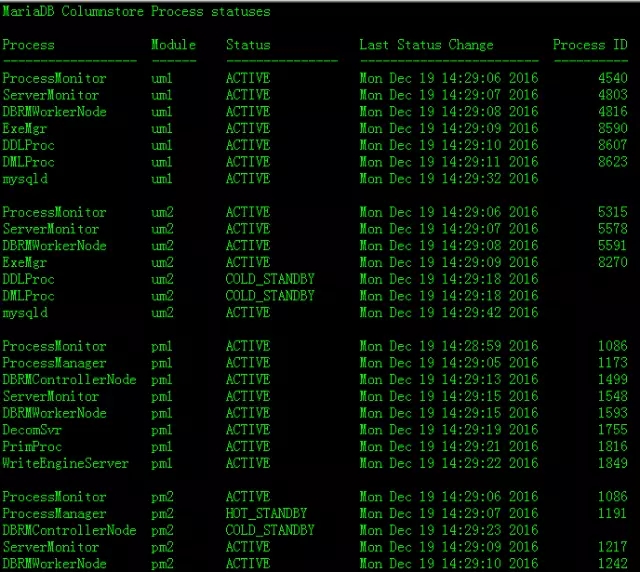
um1是主节点,um2是备节点,pm1是主节点,pm2是备节点。
在实际生产环境中,部署更多的pm节点会带来性能的提升。
MySQL节点的数据是通过主从复制传输的,登录um1或um2机器上输入mcsmysql命令登陆,输入show slave status\G确定哪台机器是主库。
它其实就是命令的别名,cat /root/.bashrc查看
|
alias mcsmysql='/usr/local/mariadb/columnstore/mysql/bin/mysql --defaults-file=/usr/local/mariadb/columnstore/mysql/my.cnf -u root' alias ma=/usr/local/mariadb/columnstore/bin/mcsadmin alias mcsadmin=/usr/local/mariadb/columnstore/bin/mcsadmin alias home='cd /usr/local/mariadb/columnstore' alias log='cd /var/log/mariadb/columnstore/' alias core='cd /var/log/mariadb/columnstore/corefiles' alias tmsg='tail -f /var/log/messages' alias tdebug='tail -f /var/log/mariadb/columnstore/debug.log' alias tinfo='tail -f /var/log/mariadb/columnstore/info.log' alias dbrm='cd /usr/local/mariadb/columnstore/data1/systemFiles/dbrm' alias module='cat /usr/local/mariadb/columnstore/local/module' |
我们这里以sysbench生成的sbtest表为例,表结构如下:
|
CREATE TABLE `sbtest` ( `id` int(10) unsigned NOT NULL, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) DEFAULT '', `pad` char(60) NOT NULL DEFAULT '' ) ENGINE=Columnstore DEFAULT CHARSET=utf8; |
注:不支持主键和索引,数据类型不支持text和timestamp字段类型。
数据导入
由于是离线分析,不支持与前端MySQL的主从复制,需要手工把MySQL/Percona/MariaDB的数据导出,命令:
|
select * from sbtest into outfile '/tmp/sbtest.txt' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n'; #FIELDS TERMINATED BY ',' --字段的结束符 #OPTIONALLY ENCLOSED BY '"' --字符串的分割符 #LINES TERMINATED BY '\n' --行的结束符 |
导入有两种方法:
一种是通过load命令导入
|
load data infile '/tmp/sbtest.txt' into table sbtest FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n'; |
另一种官方推荐自带的cpimport命令导入。
cpimport是一种高速批量加载实用程序,可以快速高效地将数据导入ColumnStore引擎。
|
/usr/local/mariadb/columnstore/bin/cpimport test sbtest /root/tmp/sbtest.txt -E '"' -s ',' #test是数据库 #sbtest是表 #-E是字符串的分割符 #-s是字段的结束符 |

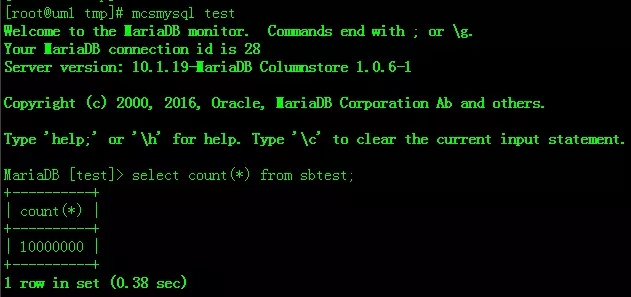
入上图所示,代表已经导入成功。
然后你就可以使用SQL查询分析了,如下图所示:
配置文件/usr/local/mariadb/columnstore/etc/Columnstore.xml
# 设置为PM主机的物理内存70%,用来缓存数据到内存
# 设置为UM主机的物理内存50%,用来对PM分析的结果进行聚合
1、这是在生产服务器InnoDB_Buffer_Pool50G内存跑的,耗时4小时7分。
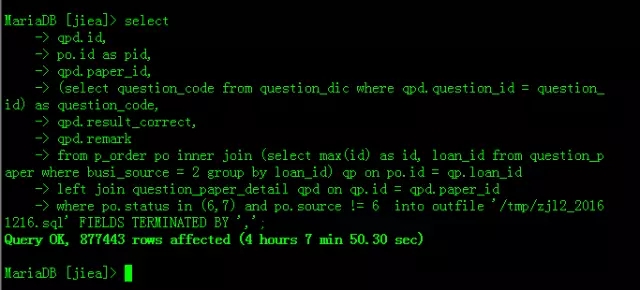
当然这个SQL是有优化空间的,但会浪费DBA过多的精力与时间,业务方不等人,时间就是金钱。
2、下面是在Columnstore,我的笔记本vmware虚拟机1G内存跑的,耗时4.66秒。
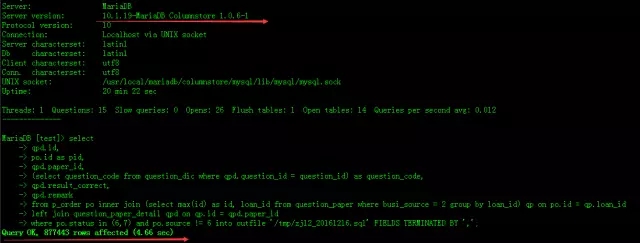
大家可以用生产的复杂SQL跑一跑,来体验一下。
如何动态增加一个PM节点?
由于个人精力有限,更多的技术研究,请大家共同协助。谢谢阅读。
参考文献:








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721