
本文根据DBAplus社群第83期线上分享整理而成
贺春旸
普惠金融MySQL专家
《MySQL管理之道》第一版、第二版作者,曾任职于中国移动飞信、机锋安卓市场,拥有丰富的数据库管理经验。
目前致力于MySQL、Linux等开源技术的研究。
感谢大家参与我今天的分享,希望今天大家能有所收获,并能把这项新技术玩起来先。在介绍MaxScale Binlog Server前,我先把我们这边的情况大致阐述下。
公司核心数据库在我15年7月入职第二周,从最原始的MySQL5.5.30社区版全部升级到MariaDB10.0.21企业版,随后面的机房迁移,版本再次升级为MariaDB10.0.26企业版。
那为啥选用这个版本?对于金融p2p公司来说,换数据库就意味着风险,因为库里都是钱,大多都采用保守的方法。而我之前来机锋网(安卓市场)的时候,就已经使用MariaDB10.0.17社区版跑了一年半,当时PV是2000万,数据库总共8台,一主7从,前端PHP做的读写分离,后端用HaProxy做DB的负载均衡,QPS每秒在15000–20000左右,TPS每秒在300–500左右,至今数据库稳定的跑着,未出现一次故障。
有了成功经验,对我换金融数据库版本就有了足够的信心保障,因为金融类的公司并发都远远低于传统互联网公司,事实证明,目前业务稳定跑了1年4个月。
好,再回过头来说下,对接大数据分析部门遇到的痛点以及我们为何上了MaxScale binlog server。我们给大数据那边,是提供一台单独的从库,注意是二级从库,他们通过阿里巴巴开源的canal连接到Slave从库上,然后Slave推送binlog给canal,接收完binlog再推送给kafka消息队列,最终存入HBase里,业务部门通过Hive直接写SQL的方式来实现业务的实时分析,大体的架构就是这样。
注意刚才我提到的二级从库,因我们目前线上的从库一台是Standby仅提供故障切换用的,另一台是提供业务读写分离用的。所以我在从库的下面接了一台二级从库,提供对接canal使用。因爬虫的抓取insert写入量大,从库的SQL_THREAD线程只有commit后才会记本地的binlog里,然后再推送给二级从库。这个时候,由于我们是实时分析,延迟5秒也无法接受,被业务方喷了回来,这TMD就尴尬了。
下面进入正题,本次分享将围绕以下三部分展开:
MariaDB MaxScale的工作原理
MaxScale Binlog服务器主要功能
如何将MaxScale设置为Binlog服务器
生产环境中,大多采用的是一主多从架构,即主库推送三份binlog日志到S1/S2/S3从库上。然而,在这个架构中存在了一些问题,当主库带了过多的从库,势必会增加主库的网络IO压力。而链式复制(多级复制)通常为M---S1---S2/S3,S1是S2/S3的主,主库只需要给S1推送binlog日志即可,S1再推送binlog日志给S2/S3,在这种场景下,缓解了主库的网络IO压力,但其缺点是:S2/S3得到最新的数据,需要再经过一层的复制才到达,期间的延迟比一主多从架构要大。
业界通常的做法是在二级主库上(S1)选择黑洞引擎(BLACKHOLE)降低链式复制(多级复制)的延迟问题。写入BLACKHOLE表的数据并不会记录到磁盘上(本身不保存数据),永远为一个空表,因不会将同步的数据写回到磁盘上,速度远远比INNODB引擎快,它仅仅接收主库推送过来的binlog日志。
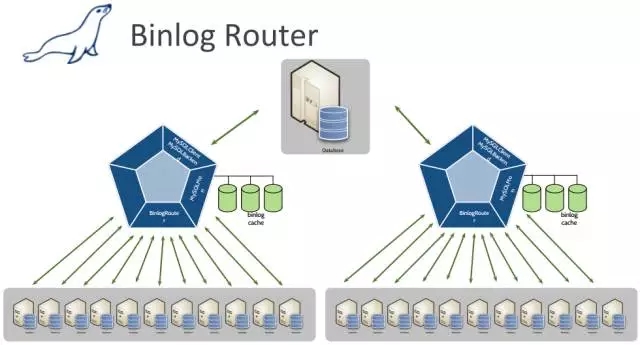
MaxScale对Binlog的收集采用了一个更简单的方法,其工作在主库和从库之间。它不会对binlog进行任何回放操作,自身不保存数据。它把从主库接收的binlog放入本地缓存,并将其推送给从库。这意味着从库总是获得最新的binlog事件,它们与主库写入的binlog事件具有一对一的关系。其延迟主要是添加多台MaxScale带来的额外的网络传输。
充当主库代理的MaxScale具有与主库完全相同的binlog事件,这意味着从库可以在任意一个MaxScale节点之间CHANGE MSATER TO ,无需执行任何特殊处理。MariaDB MaxScale Binlog Server接收器,工作流程类似黑洞引擎(BLACKHOLE)。
Binlog服务器从主库请求和接收Binlog事件。
接收的二进制日志与主库里的二进制日志完全相同,可以理解为MaxScale Binlog每秒rsync主库的binlog事件。
从库可以与MaxScale Binlog做CHANGE MSATER TO同步复制,从而不会对主库网络IO造成过大影响。
使用MaxScale作为binlog代理与使用MaxScale作为应用读写分离的代理非常相似。
基础架构为:M---MaxScale Binlog---S1/S2:
一个主库
两个或更多的从库
一个或两个MaxScale服务器配置了binlog接收器
MaxScale binlog配置
# cat /etc/maxscale.cnf
[maxscale]
threads=24
##根据CPU核数设置
[Replication]
type=service
router=binlogrouter
user=repl
passwd=repl
# 使用主库上的repl复制账号
# 权限:
# GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'repl'@'%' IDENTIFIED BY 'repl';
router_options=server_id=1311,heartbeat=30,binlogdir=/data/binlog,transaction_safety=1,mariadb10-compatibility=1,send_slave_heartbeat=1
# server_id设置maxscale的,记得不能与主和从库重复,要唯一
# heartbeat=30秒,意思为当maxscale在30秒内没有接收到主库推送的binlog日志,发送心跳检查
# binlogdir设置接收binlog的存放路径,目录属性chown -R
maxscale.maxscale /data/binlog
# transaction_safety=1此参数用于启用binlog日志中的不完整事务检测。 当MariaDB MaxScale启动时,如果当前binlog文件已损坏或找到不完整的事务,则可能会出现错误消息。 在正常工作期间,binlog事件不会分配到从库,直到事务已经提交。 默认值为off,设置transaction_safety = on以启用不完全事务检测。
# send_slave_heartbeat=1开启心跳检查
[Replication Listener]
type=listener
service=Replication
protocol=MySQLClient
port=5308
# 后端的从库CHANGE MASTER TO这个端口,默认5308
[CLI]
type=service
router=cli
[CLI Listener]
type=listener
service=CLI
protocol=maxscaled
port=6603
# MaxScale后台管理端口
启动:
# /etc/init.d/maxscale start
使用:
# 连接到MaxScale binlog Server后台
# mysql -h192.168.17.131 -urepl -prepl -P5308
# 就像平常建立主从复制一样,执行下面的命令
MySQL [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.17.128',MASTER_USER='repl',MASTER_PASSWORD='repl',
MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000012',MASTER_LOG_POS=4;
MySQL [(none)]> start slave;
Query OK, 0 rows affected (0.03 sec)
# 注:这里MASTER_LOG_POS必须指定4,否则报错。
# 此外,GTID目前不支持
MySQL [(none)]> set global gtid_slave_pos = '0-17128-37';
ERROR 1064 (42000): You have an error in your SQL syntax; Check the syntax the MaxScale binlog router accepts.
MySQL [(none)]>
MySQL [(none)]> CHANGE MASTER TO
MASTER_HOST='192.168.17.128',MASTER_USER='repl', MASTER_PASSWORD='repl',MASTER_PORT=3306,master_use_gtid ='slave_pos';
ERROR 1234 (42000): option 'master_use_gtid' is not supported
MySQL [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Binlog Dump
Master_Host: 192.168.17.128
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000012
Read_Master_Log_Pos: 365
Relay_Log_File: mysql-bin.000012
Relay_Log_Pos: 365
Relay_Master_Log_File: mysql-bin.000012
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 365
Relay_Log_Space: 365
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 17128
Master_UUID: ca8da868-a63f-11e6-a6d7-000c29379e1f
Master_Info_File: /data/binlog/master.ini
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave running
Master_Retry_Count: 1000
Master_Bind:
Last_IO_Error_TimeStamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position:
1 row in set (0.00 sec)
# 如果你配置有误,清空同步信息即可,执行下面命令
MySQL [(none)]> stop slave;
Query OK, 0 rows affected (0.00 sec)
MySQL [(none)]> reset slave all;
Query OK, 0 rows affected (0.00 sec)
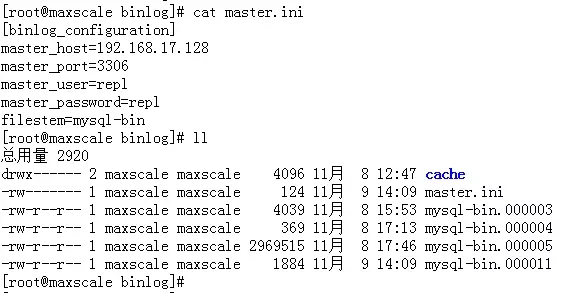
# 这一步成功之后,你会在/data/binlog目录下发现接收过来的binlog日志,如下图所示。
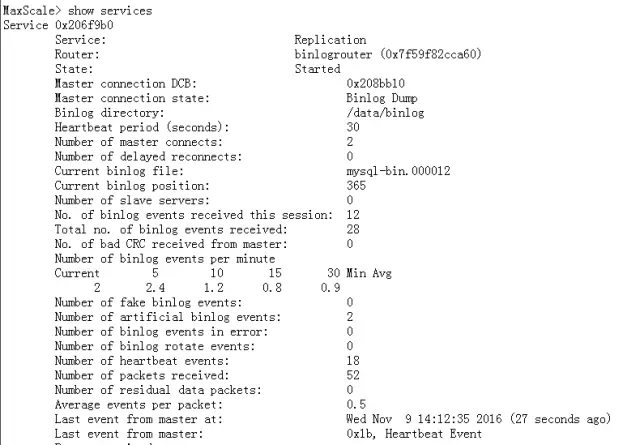
# 登录到MaxScale管理后台,可以看到接收binlog的信息,如下图所示。
# maxadmin -uadmin -pmariadb -P6603
# 在线搭建一个从库与MaxScale Binlog Server同步复制步骤:
主库上导出mysqldump --single-transaction -q -p123456 --master-data=2 -A > all.sql
从库上导入
more all.sql查看同步复制的点
CHANGE MASTER TO MaxScale Binlog Server(端口5308)
参考文献:
https://mariadb.com/kb/en/mariadb-enterprise/mariadb-maxscale-as-a-binlog-server/
视频下载:
为了帮助大家理解,已将演示视频上传至社群百度网盘,点击底部链接即可获取。
Q1:“# 注:这里MASTER_LOG_POS必须指定4 ” 如果运行很久的库,我搭建一个maxscale binlog server 也要指定 MASTER_LOG_POS=4 ?
A1:是的,必须指定为4,从头开始接收,这样是保证binlog日志的完整性。
Q2:贺老师,我有一个运行一段时间的一主N从的架构,我能中间加一个这个binlog server 后,把其他 从库重新指定到这个binlog server 么,有什么需要注意的么?
A2:可以,这个没问题。
Q3:另外如果主库的MASTER_LOG_POS=4 的binlog 已经删除了, 上面也那个指定也是需要指定4不会有问题吗?
A3:binlog server的binlog就是主库上rsync过来的,完全一致。指定的时候,是从4开始的,binlog文件都是从4开始,例如mysql-bin.00001,00002,都是从4开始。
Q4:我有一个运行一段时间的一主N从的架构,架构中加入binlog server 如何解决单点?
A4:binlog server可以部署两台,就是同时拉取两份主库的binlog。
Q5:[maxscale]
threads=24
##根据CPU核数设置
这里能不按CPU核数设置吗?
A5:这个可以,但性能会下降。
Q6:一主多从的架构,中间部署binlog server,在服务器压力大时如何降低或确保slave端的延迟?
A6:我们目前生产是开启了MariaDB的并行复制功能,32核CPU,开启了32个线程。另外可以通过增加内存,调整INNODB_BUFFER_POOL_SIZE解决延迟的问题。另外一点是注意避免主库的大事务,比如更新一个表,总共100万,让开发通过程序,循环更新,每1000条一个事务,直到全部更新完毕。
Q7:贺老师,能给DBA的职业发展给点建议?
A7:不敢当,一个老DBA前辈告诉我的,要多写博客,多做分享。
(承接上一问)
Q8:对准备转行进入数据库的给点建议或者注意事项?
A8:我觉得DBA这个行业,需要谨慎,就跟开车一样,需要时间磨练。另外就是沟通,因为每天都要对接各种开发,给他们提建议。
Q9:新入行的,做运维,开发,实施,有什么区别?
A9:运维开发侧重点不同。
Q10:Oracle 和MySQL 哪个会更长久?
A10:这个我之前面试过20个DBA,有很多是从Oralce转的。目前是MySQL要火一些。
Q11:NoSQL这类数据库前景如何?
A11:是必须会的,Redis和MongoDB。
Q12:MySQL和MariaDB哪个好?MySQL学习中有哪些难点要特别注意的?
A12:这个各有优缺点吧,在生产上之所以选择的mariadb,是看重他的功能更多,性能更好,稳定等因素。另外是从5.5升级到mariadb10.0,不需要进行导出导入了,只需卸载mysql,用mariadb启动即可,很简单。这对数据库上T的来说,轻松不少。
难点就是经常会遇到坑,心理要能承受得住业务方的喷。最最重要的是,高可用得做起来。
Q13:MySQL一个表或数据库中,大概多少记录算是大数据呢(新手问)
A13:之前在电商那会,通常是建议开发2000万行就开始做分表,否则大促的时候,性能非常差。
Q14:请问MariaDB和5.7以上的MySQL对比,优势大么?
A14:MySQL5.7对InnoDB这块加强了不少,但最好是5.7.20以后再上。
Q15:贺老师,我想问一下关于MySQL漏洞打补丁之类的问题。
A15:这个升级的步骤是,先对从库做版本升级,然后凌晨的时候用MHA做下切换,再对原先的主库升级。之前在飞信的时候,经常安全部门找到我们,我就是这样升级的小版本。
(承接上一问)
Q16:就是直接做数据库版本升级?
A16:是的,用新版本启动。
Q17:那数据导入导出一般您是采用哪种方式呢?
A17:推荐用mydumper,是多线程的,速度比单线程的mysqldump快。
Q18:mydumper是不是还不支持设置字符集?
A18:通常数据库都是UTF8的,导出的时候还真没特意指定过。
Q19:MHA能支持一主一备,1+2感觉有点浪费。
A19:这必须的。目前最新版本是0.57,老版本0.56就已经支持。
视频链接:http://pan.baidu.com/s/1eSC5GCa









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721